
本文永久链接 – https://tonybai.com/2021/06/28/understand-go-execution-tracer-by-example
Netflix(奈飞公司)的性能架构师Brendan Gregg在其《BPF Performance Tools》一书中对tracing、sampling等概念做了细致描述,以帮助开发人员理解这些概念,并基于这些概念对性能优化辅助工具进行分类,明确它们的适用场合。这里引用部分内容如下:
采样工具(Sampling tools)采用一个测量的子集来描绘目标的粗略情况;这也被称为创建一个profile或profiling(剖析)。profiling工具对运行中的代码采用基于定时器的采样。其缺点是,采样只能提供一个关于目标的粗略的图像,并且可能会遗漏事件。
追踪(tracing)是基于事件的记录,一旦开启跟踪,跟踪工具便能够记录所有原始事件和事件元数据。
在Go工具链中,go tool pprof(与runtime/pprof或net/http/pprof联合使用)便是一个基于采样(sampling)的性能剖析(profiing)辅助工具。它基于定时器对运行的go程序进行各种采样,包括诸如CPU时间、内存分配等方面。但go pprof也具有上面所说的基于采样的工具的不足,那就是采样的频度不足导致的精确性问题,在Go运行时内部,CPU分析使用操作系统计时器来定期(每秒约100次,即10ms一次)中断执行。在每个中断(也称为样本)上,它同时收集当时的调用堆栈。当为了实现更高频度采样时(比如微秒级别的采样),目前的go profile无法支持(为此uber工程师提了一个名为pprof++的高精度、更精确并支持硬件监控的提案)。
Go语言同样也提供了基于追踪(tracing)策略的工具,一旦开启trace,Go应用中发生的所有特定事件(event)便会被记录下来,并支持将其保存在文件中以备后续分析,这个工具由谷歌工程师Dmitry Vyukov提出设计方案并实现,并在Go 1.5版本发布时加入Go工具链,这个工具被称为Go Execution Tracer,中文直译就是Go执行跟踪器。

相对于go pprof,Go Execution Tracer的使用相对少一些,但在特定场景下,Go Execution Tracer能发挥出巨大作用,能帮助gopher找出go应用中隐藏较深的疑难杂症。在这篇文章中,我们就来系统地了解一下Go Execution Tracer(以下简称为Tracer)。
1. Go Execution Tracer究竟能做什么?
我们日常使用最多的go性能剖析工具是pprof(go tool pprof),通过定时采样并结合Go标准库中的runtime/pprof或net/http/pprof包,pprof可以帮助我们挖掘出被剖析目标中的“热点”,比如:哪些行代码消耗CPU较多、哪些行代码分配内存较多、哪些代码被阻塞的时间较长等。但是有些时候这些基于定时器采样的数据还不够,我们还需要更多关于Go应用中各个goroutine的执行情况的更为详细的信息。在Dmitry Vyukov最初的设计中,他希望Tracer能为Go开发者提供至少如下的关于goroutine执行情况的信息:
- 与goroutine调度有关的事件信息:goroutine的创建、启动和结束;goroutine在同步原语(包括mutex、channel收发操作)上的阻塞与解锁。
- 与网络有关的事件:goroutine在网络I/O上的阻塞和解锁;
- 与系统调用有关的事件:goroutine进入系统调用与从系统调用返回;
- 与垃圾回收器有关的事件:GC的开始/停止,并发标记、清扫的开始/停止。
有了这些事件信息,我们可以从P(goroutine调度器概念中的processor)和G(goroutine调度器概念中的goroutine)的视角完整的看到每个P和每个G在Tracer开启期间的全部“所作所为”。而开发人员正是通过对Tracer输出数据中的每个P和G的行为分析并结合详细的event数据来辅助问题诊断的。
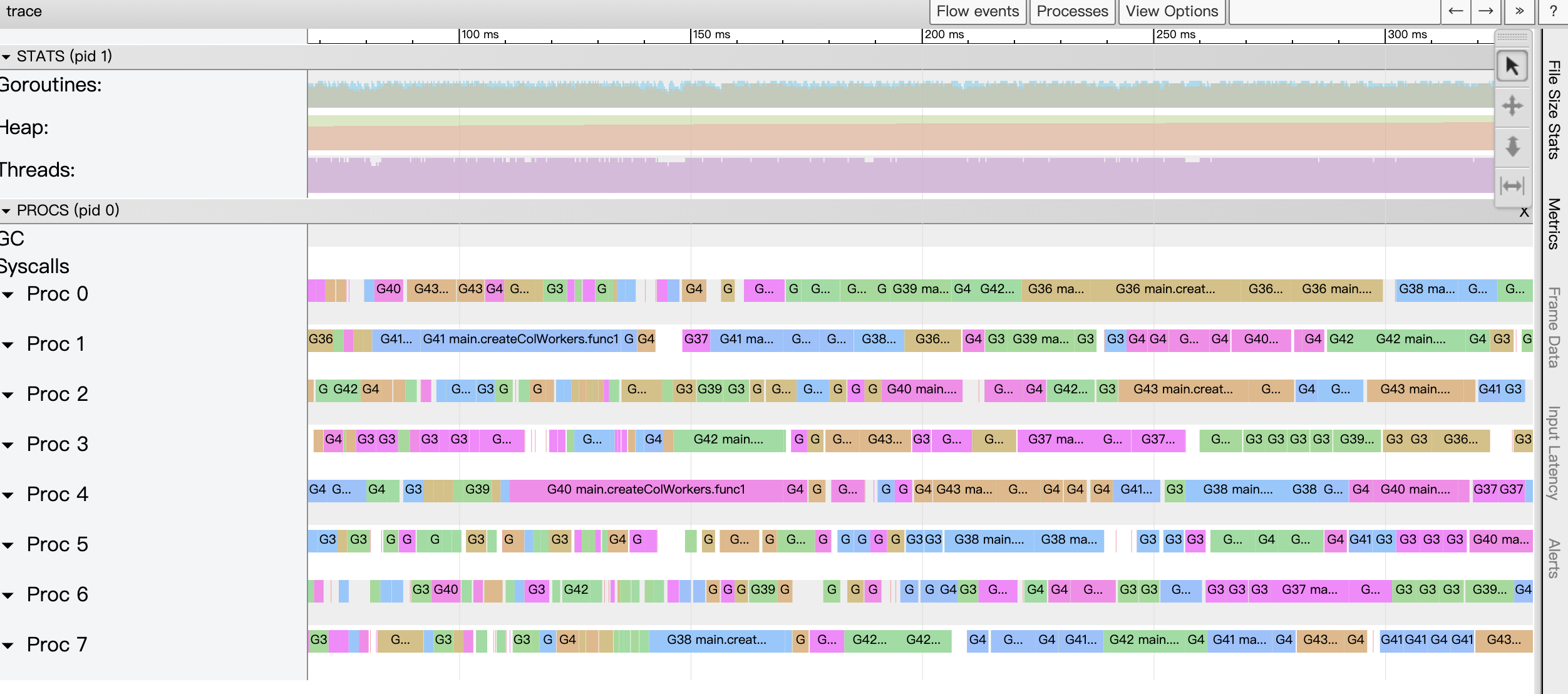
图3:通过go tool trace以图形化形式查看P和G的行为和事件
另外与pprof基于系统定时器支持10ms频度的采样不同,Tracer为每个event打的时间戳都精确到纳秒(nanosecond)级精度,在查看Tracer数据时,我们可以通过缩放的方式查看不同时间精度下各个P和G呈现的特征,并可以在纳秒精度上查看发生事件的详细信息。
前面说过,Tracer是基于事件而不是定时采样的,因此与定时采样相比,Tracer开启带来的开销是很大的,是肉眼感觉得到的那种影响(输出到文件中的数据体量也要比pprof的采样数据文件多出很多)。在最初设计稿中,Dmitry Vyukov给出的估计是性能下降35%,但实际上可能要比这略好一些,但我们一般也不会在生产环境持续开启Tracer。
大致了解Tracer的运行原理与辅助诊断机制,那么Tracer究竟适合诊断哪些问题呢?Tracer作者Dmitry Vyukov在Tracer设计文档中提到了三点,在实际应用中,Tracer主要也是用于辅助诊断这三个场景下的具体问题的:
- 并行执行程度不足的问题:比如没有充分利用多核资源等;
- 因GC导致的延迟较大的问题;
- Goroutine执行情况分析,尝试发现goroutine因各种阻塞(锁竞争、系统调用、调度、辅助GC)而导致的有效运行时间较短或延迟的问题。
Go Tracer从Go 1.5版本加入Go工具链,之后演化不大,这里简单梳理一下Go 1.5到Go 1.16版本Go Tracer的演化历程:
-
Go 1.5版本在go工具链中加入Go Execution Tracer支持,并在runtime、runtime/trace和net/http/pprof包中加入开启和关闭Trace的API函数;
-
Go 1.7版本中,Go 1.5中引入的“go tool trace”命令在各方面都得到了改进,包括:
- 与过去的版本相比,收集Tracer数据的效率明显提高。在这个版本中,收集跟踪数据的一般执行时间开销约为25%;而在过去的版本中,这至少是400%;
- 新版跟踪文件中包含了文件和行号信息,使它成为自解释的,这样原始可执行文件在运行跟踪工具时(go tool trace)时变得可有可无。
- go tool trace工具支持将大的tracer数据文件进行分割,以避免触及浏览器的viewer的限制。
- 追踪文件的格式在这个版本中有所改变,但仍然可以读取早期版本的追踪文件。
- net/http/pprof包中增加Trace handler以支持在/debug/pprof/trace上处理Trace请求。
-
Go 1.8版本中,go tool trace增加一个-pprof的标志位,支持将tracer数据转换为pprof格式兼容的数据:
$go tool trace -pprof=TYPE trace.out > TYPE.pprof
同时,在trace查看视图中,GC事件展示更为清晰,GC活动在其自己的单独的行上显示,并且辅助GC的goroutine也会被标记上其在GC过程中的角色。
- Go 1.9版本中runtime/trace包支持显示GC标记辅助事件,这些事件表明当一个应用程序的goroutine因为分配速度过快而被迫辅助垃圾收集。”sweep”事件现在包含了为分配寻找空闲空间的整个过程,而不是仅记录被sweep的每个单独跨度。这减少了追踪分配量大的程序时的分配延迟。sweep事件支持显示有多少字节被sweep,有多少字节被真正回收。
- Go 1.11版本在runtime/trace包中支持用户自定义应用层事件,包括:user task和user region。一旦定义,这些事件就可以和原生事件一样在go tool trace中以图形化的方式展示出来。
- Go 1.12版本中,go tool trace支持绘制Minimum mutator utilization的曲线,这些对于分析垃圾收集器对应用程序延迟和吞吐量的影响很有用。
2. 为Go应用添加Tracer
Go为在Go应用中添加Tracer提供了三种方法,我们逐一看一下。
1) 手工通过runtime/trace包在Go应用中开启和关闭Tracer
无论使用哪一种方法,runtime/trace包都是基础与核心。我们可以直接使用runtime/trace包提供的API在Go应用中手工开启和关闭Tracer:
package main
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
// 下面是业务代码
... ...
}
上面代码中,我们通过trace.Start开启Tracer,并在程序结束时通过trace.Stop停止Tracer,Tracer收集到的数据输出到os.Stdout(标准输出)上,我们可以将其重定向到一个文件中保存,我们亦可以向trace.Start传入一个文件的句柄,让Tracer将数据直接写到文件中,就像下面这样:
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
// 下面是业务代码
... ...
}
从代码来看,Tracer是支持动态开启的,但要注意的是每次开启都要对应一个独立的文件。如果多次开启后将数据(续)写入同一文件,那么go tool trace在读取该文件时会报类似如下错误:
$go tool trace trace.out
2021/06/23 05:50:01 Parsing trace...
failed to parse trace: unknown event type 50 at offset 0x73c
2) 通过net/http/pprof提供基于http进行数据传输的Tracer服务
如果一个Go应用通过net/http/pprof包提供对pprof采样的支持,那么我们就可以像获取cpu或heap profile数据那样,通过/debug/pprof/trace端点来开启Tracer并获取Tracer数据:
$wget -O trace.out http://localhost:6060/debug/pprof/trace?seconds=5
net/http/pprof包中的Trace函数负责处理发向/debug/pprof/trace端点的http请求,见下面代码:
// $GOROOT/src/net/http/pprof/pprof.go
func Trace(w http.ResponseWriter, r *http.Request) {
w.Header().Set("X-Content-Type-Options", "nosniff")
sec, err := strconv.ParseFloat(r.FormValue("seconds"), 64)
if sec <= 0 || err != nil {
sec = 1
}
if durationExceedsWriteTimeout(r, sec) {
serveError(w, http.StatusBadRequest, "profile duration exceeds server's WriteTimeout")
return
}
// Set Content Type assuming trace.Start will work,
// because if it does it starts writing.
w.Header().Set("Content-Type", "application/octet-stream")
w.Header().Set("Content-Disposition", `attachment; filename="trace"`)
if err := trace.Start(w); err != nil {
// trace.Start failed, so no writes yet.
serveError(w, http.StatusInternalServerError,
fmt.Sprintf("Could not enable tracing: %s", err))
return
}
sleep(r, time.Duration(sec*float64(time.Second)))
trace.Stop()
}
我们看到在该处理函数中,函数开启了Tracer:trace.Start,并直接将w作为io.Writer的实现者传给了trace.Start函数,接下来Tracer采集的数据便会源源不断地通过http应答发回客户端,处理完后,Trace函数关闭了Tracer。
我们看到通过这种方式实现的动态开关Tracer是相对理想的一种方式,生产环境可以采用这种方式,这样可以将Tracer带来的开销限制在最小范围。
3) 通过go test -trace获取Tracer数据
如果要在测试执行时开启Tracer,我们可以通过go test -trace来实现:
$go test -trace trace.out ./...
命令执行结束后,trace.out中便存储了测试执行过程中的Tracer数据,后续我们可以用go tool trace对其进行展示和分析。
3. Tracer数据分析
有了Tracer输出的数据后,我们接下来便可以使用go tool trace工具对存储Tracer数据的文件进行分析了:
$go tool trace trace.out
go tool trace会解析并验证Tracer输出的数据文件,如果数据无误,它接下来会在默认浏览器中建立新的页面并加载和渲染这些数据,如下图所示:
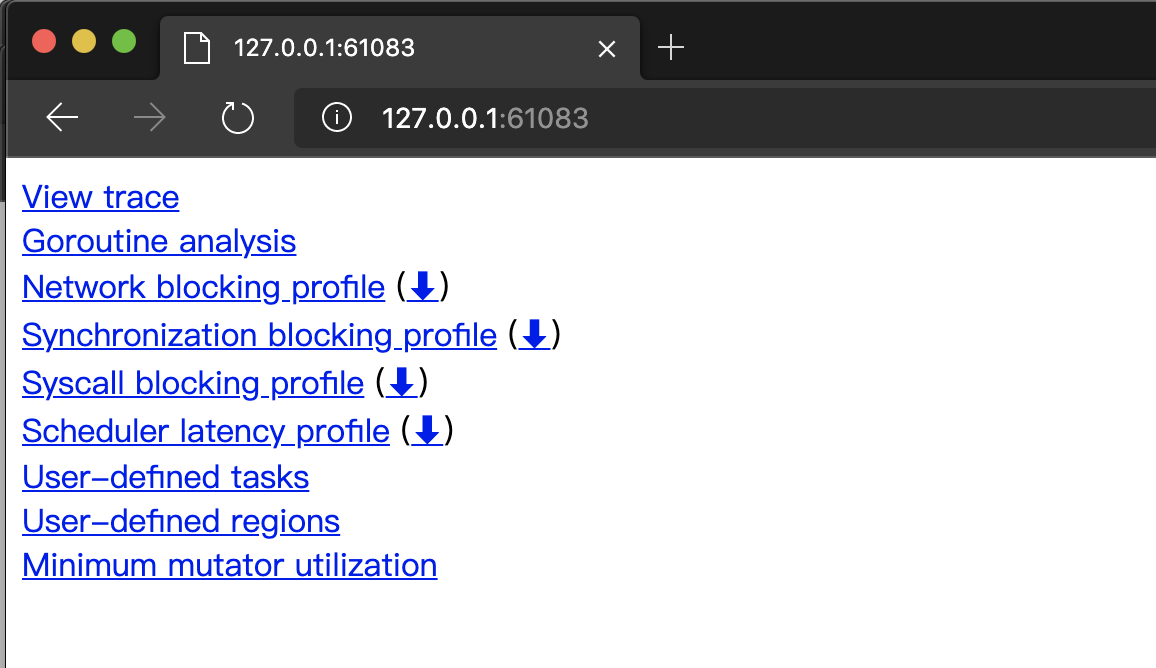
图4:go tool trace打开的Tracer数据分析首页
我们看到首页显示了多个数据分析的超链接,每个链接将打开一个分析视图,其中:
- View trace:以图形页面的形式渲染和展示tracer的数据(见上面的图3),这也是我们最为关注/最常用的功能;
- Goroutine analysis:以表的形式记录执行同一个函数的多个goroutine的各项trace数据,下图5中的表格记录的是同执行main.createColWorkers.func1的8个goroutine的各项数据:

图5:Goroutine analysis的各个子页面
- Network blocking profile:用pprof profile形式的调用关系图展示网络I/O阻塞的情况
- Synchronization blocking profile:用pprof profile形式的调用关系图展示同步阻塞耗时情况
- Syscall blocking profile:用pprof profile形式的调用关系图展示系统调用阻塞耗时情况
- Scheduler latency profile:用pprof profile形式的调用关系图展示调度器延迟情况
- User-defined tasks和User-defined regions:用户自定义trace的task和region
- Minimum mutator utilization:分析GC对应用延迟和吞吐影响情况的曲线图
通常我们最为关注的是View trace和Goroutine analysis,下面将详细说说这两项的用法。
目前关于Go Execution Tracer的官方文档资料十分稀缺,尤其是对go tool trace分析tracer数据过程中的各个视图的资料更是少之又少,网上能看到的也多是第三方在使用go tool trace过程中积累的“经验资料”。
1) View trace
点击“View trace”进入Tracer数据分析视图,见下图6:
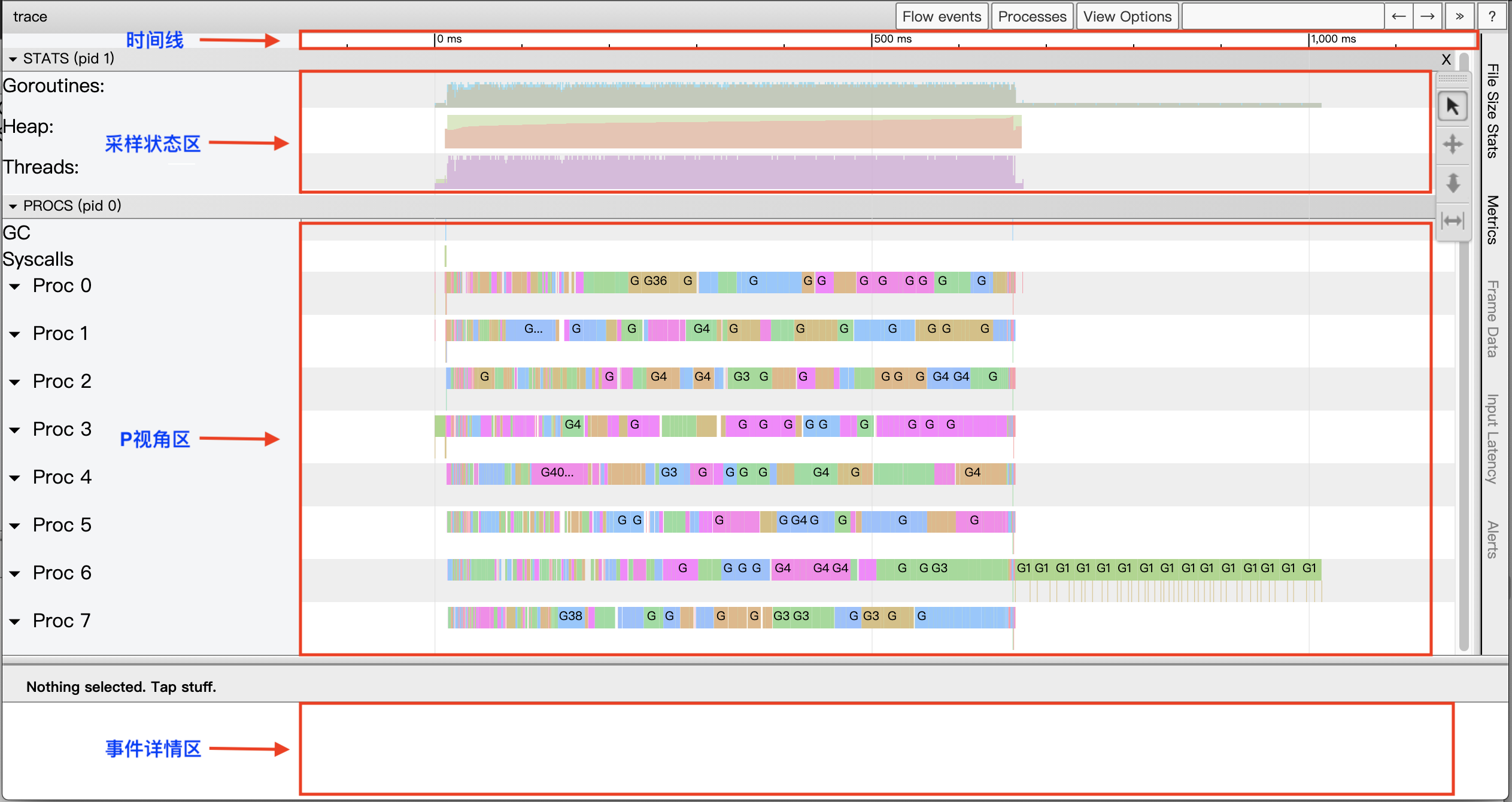
图6:View trace视图
View trace视图是基于google的trace-viewer实现的,其大体上可分为四个区域:
- 时间线(timeline)
时间线为View trace提供了时间参照系,View trace的时间线始于Tracer开启时,各个区域记录的事件的时间都是基于时间线的起始时间的相对时间。
时间线的时间精度最高为纳秒,但View trace视图支持自由缩放时间线的时间标尺,我们可以在秒、毫秒的“宏观尺度”查看全局,就像上面图6中那样;我们亦可以将时间标尺缩放到微秒、纳秒的“微观尺度”来查看某一个极短暂事件的细节:
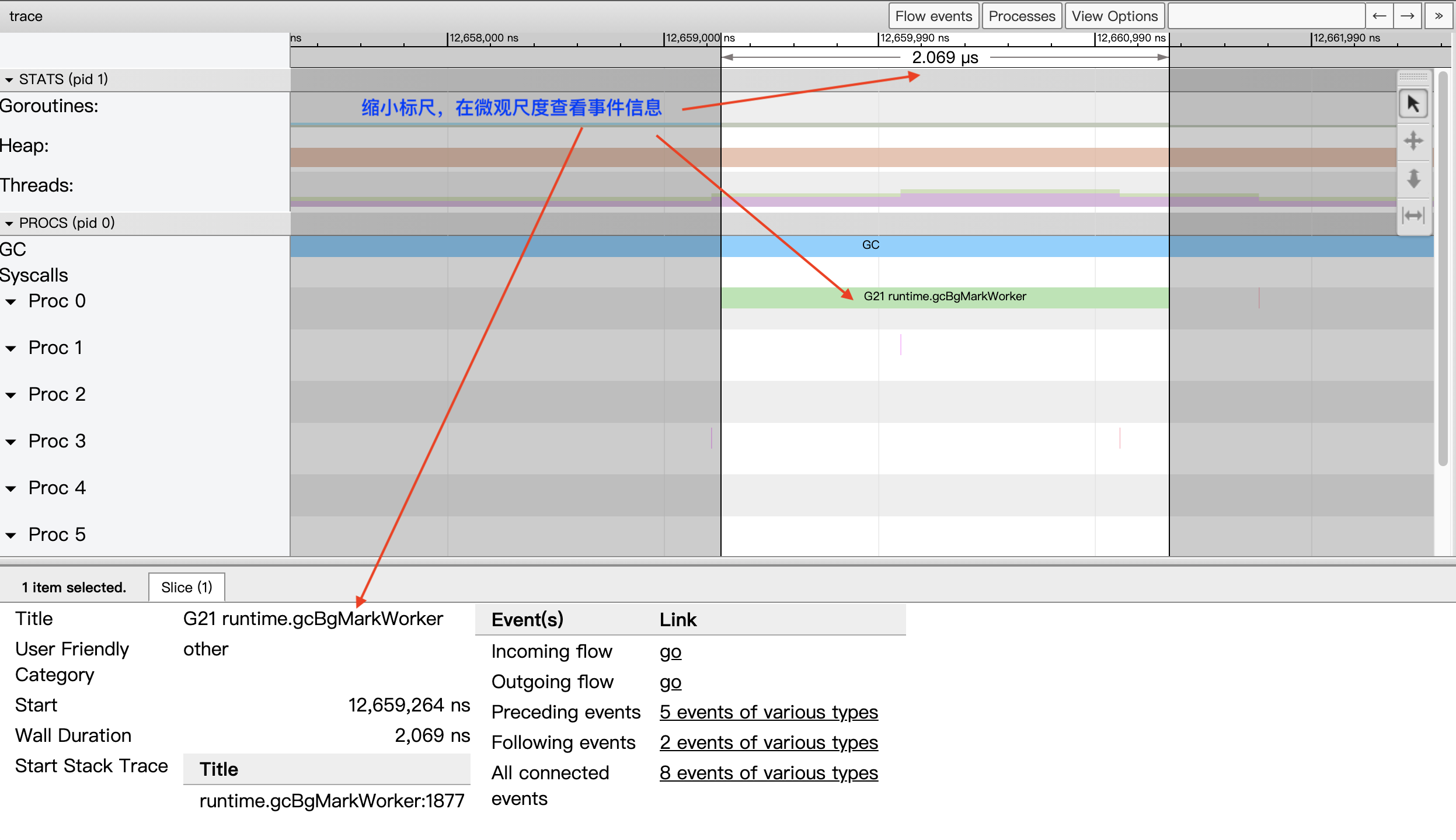
图7:在微秒的微观尺度查看短暂事件
如果Tracer跟踪时间较长,trace.out文件较大,go tool trace会将View trace按时间段进行划分,避免触碰到trace-viewer的限制:

图8:View trace按时间段划分
View trace使用快捷键来缩放时间线标尺:w键用于放大(从秒向纳秒缩放),s键用于缩小标尺(从纳秒向秒缩放)。我们同样可以通过快捷键在时间线上左右移动:s键用于左移,d键用于右移。如果你记不住这些快捷键,可以点击View trace视图右上角的问号?按钮,浏览器将弹出View trace操作帮助对话框:
图9:View trace帮助对话框
View trace视图的所有快捷操作方式都可以在这里查询到。
- 采样状态区(STATS)
这个区内展示了三个指标:Goroutines、Heap和Threads,某个时间点上的这三个指标的数据是这个时间点上的状态快照采样:
Goroutines:某一时间点上应用中启动的goroutine的数量,当我们点击某个时间点上的goroutines采样状态区域时(我们可以用快捷键m来准确标记出那个时间点),事件详情区会显示当前的goroutines指标采样状态:
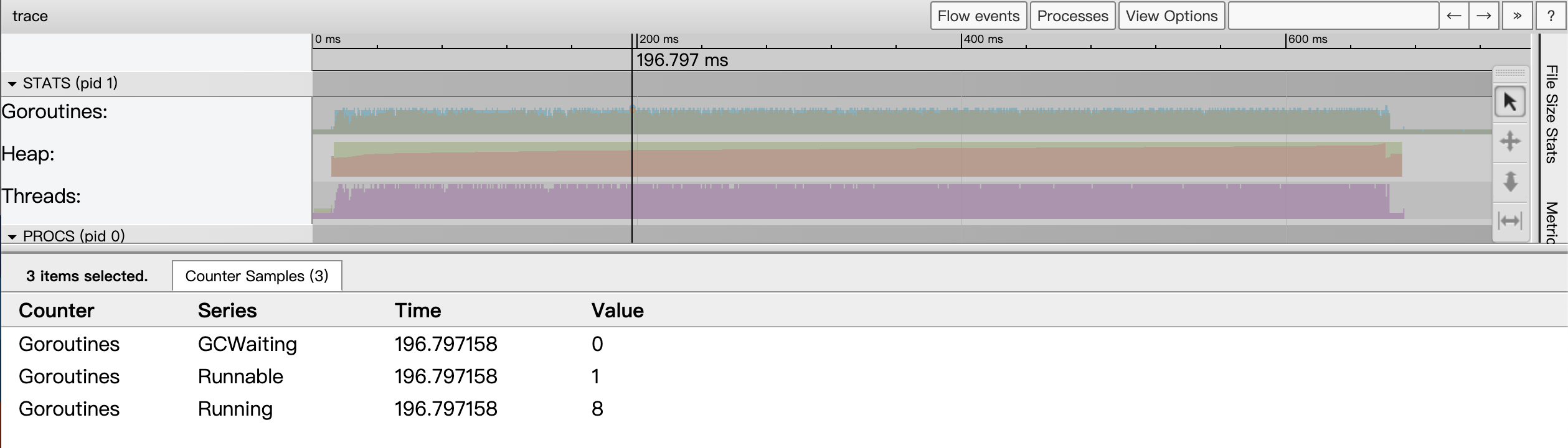
图10:某一个时间点上的goroutines指标采样状态
从上图我们看到,那个时间点上共有9个goroutine,8个正在运行,另外1个准备就绪,等待着被调度。处于GCWaiting状态的goroutine数量为0。
而Heap指标则显示了某个时间点上Go应用heap分配情况(包括已经分配的Allocated和下一次GC的目标值NextGC):
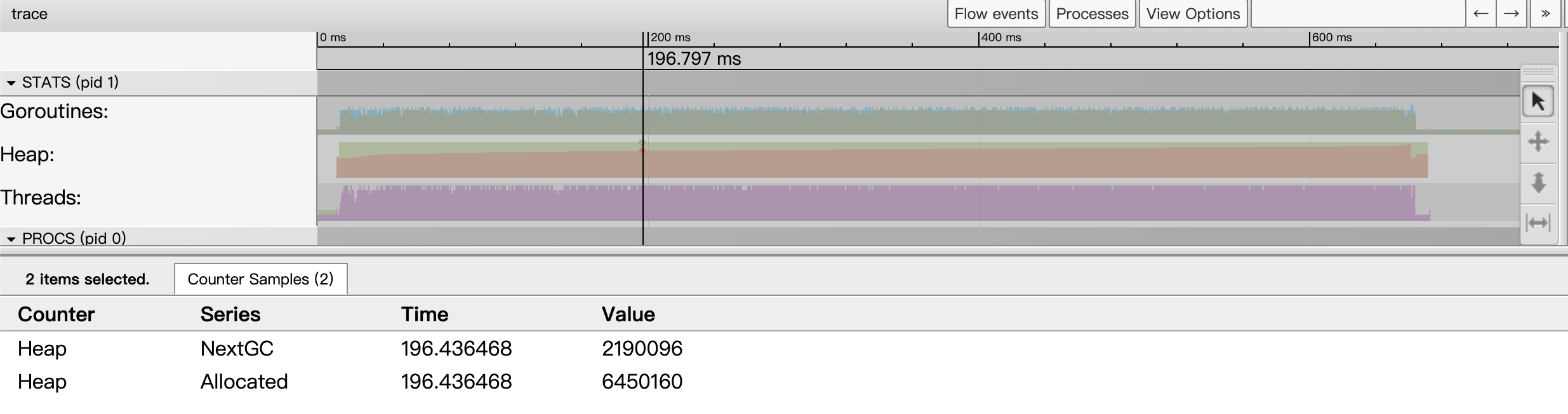
图11:某一个时间点上的heap指标采样状态
Threads指标显示了某个时间点上Go应用启动的线程数量情况,事件详情区将显示处于InSyscall(整阻塞在系统调用上)和Running两个状态的线程数量情况:
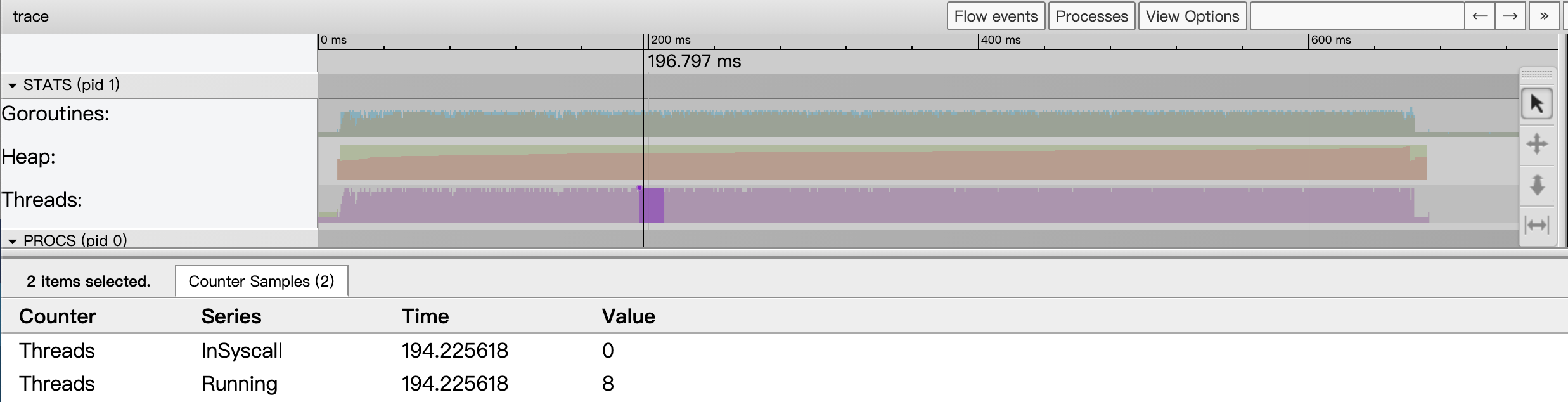
图12:某一个时间点上的threads指标采样状态
连续的采样数据按时间线排列就描绘出了各个指标的变化趋势情况。
- P视角区(PROCS)
这里将View trace视图中最大的一块区域称为“P视角区”。这是因为在这个区域,我们能看到Go应用中每个P(Goroutine调度概念中的P)上发生的所有事件,包括:EventProcStart、EventProcStop、EventGoStart、EventGoStop、EventGoPreempt、Goroutine辅助GC的各种事件以及Goroutine的GC阻塞(STW)、系统调用阻塞、网络阻塞以及同步原语阻塞(mutex)等事件。除了每个P上发生的事件,我们还可以看到以单独行显示的GC过程中的所有事件。
另外我们看到每个Proc对应的条带都有两行,上面一行表示的是运行在该P上的Goroutine的主事件,而第二行则是一些其他事件,比如系统调用、运行时事件等,或是goroutine代表运行时完成的一些任务,比如代表GC进行并行标记。下图13展示了每个Proc的条带:

图13:每个Proc对应的条带都有两行
我们放大图像,看看Proc对应的条带的细节:
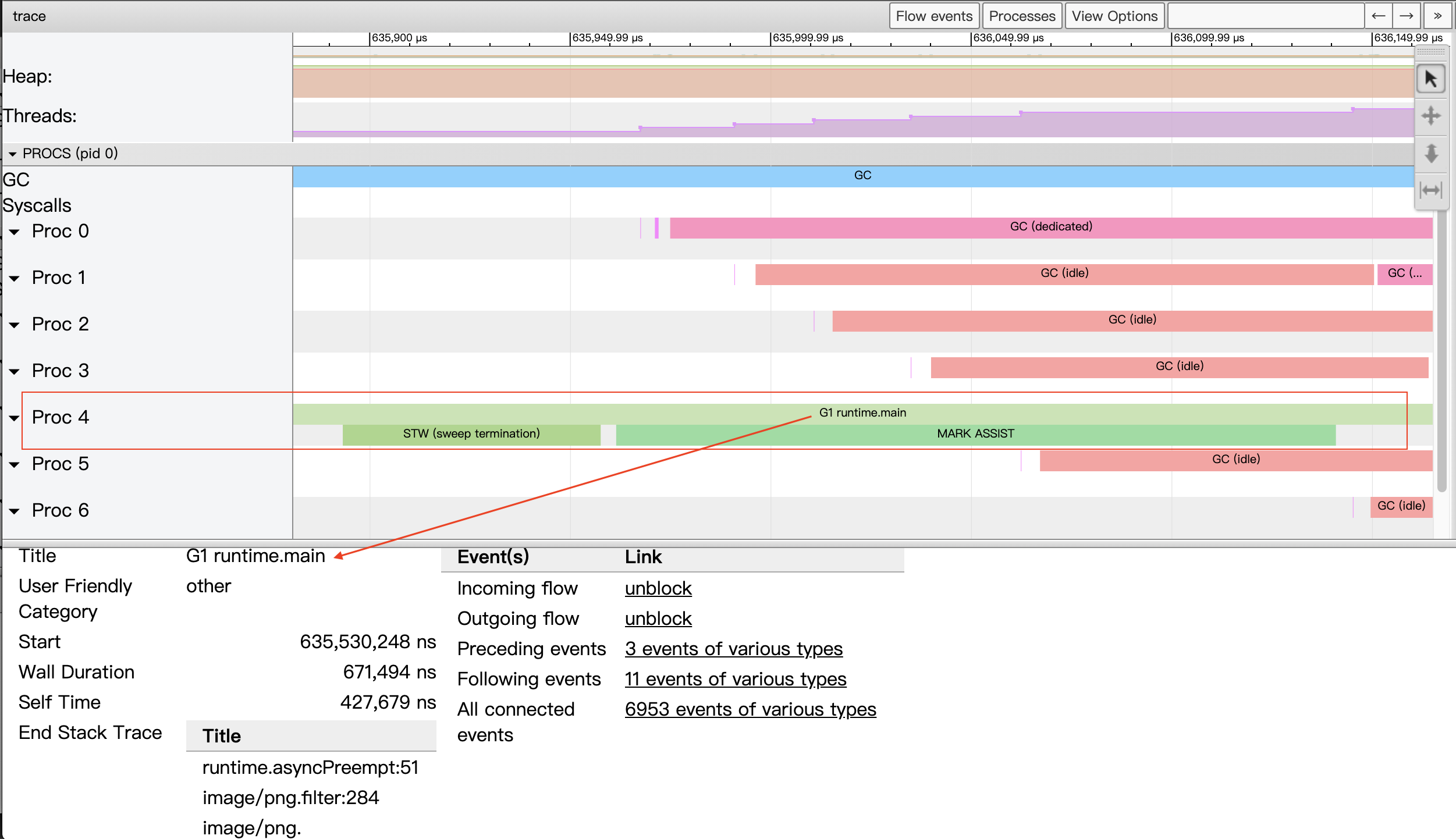
图14:每个Proc对应的条带细节
我们以上图中的proc4中的一段条带为例,这里包含三个事件。在条带的两行中的第一行的事件表示的是G1这个goroutine被调度到P4上进行运行,当我们选中该事件后,我们在事件详情区可以看到关于该事件的详细信息:
- Title:事件的可读名称;
- Start:事件的开始时间,相对于时间线上的起始时间;
- Wall Duration:这个事件的持续时间,这里表示的是G1在P4上此次持续执行的时间;
- Start Stack Trace:当P4开始执行G1时G1的调用栈;
- End Stack Trace:当P4结束执行G1时G1的调用栈;从上面End Stack Trace栈顶的函数为runtime.asyncPreempt来看,该Goroutine G1是被强行抢占了,这样P4才结束了其运行;
- Incoming flow:触发P4执行G1的事件;
- Outgoing flow:触发G1结束在P4上执行的事件;
- Preceding events:与G1这个goroutine相关的之前的所有的事件;
- Follwing events:与G1这个goroutine相关的之后的所有的事件
- All connected:与G1这个goroutine相关的所有事件。
proc4条带的第二行按顺序先后发生了两个事件,一个是stw,即GC暂停所有goroutine执行;另外一个是让G1这个goroutine辅助执行GC过程的并发标记(可能是G1分配内存较多较快,GC选择让其交出部分算力做gc标记)。
通过上面描述,我们可以看到通过P视角区我们可以可视化地显示整个程序(每个Proc)在程序执行的时间线上的全部情况,尤其是按时间线顺序显示每个P上运行的各个goroutine(每个goroutine都有唯一独立的颜色)相关的事件的细节。
P视角区显式的各个事件间存在关联关系,我们可以通过视图上方的”flow events”按钮打开关联事件流,这样在图中我们就能看到某个事件的前后关联事件关系了(如下图15):
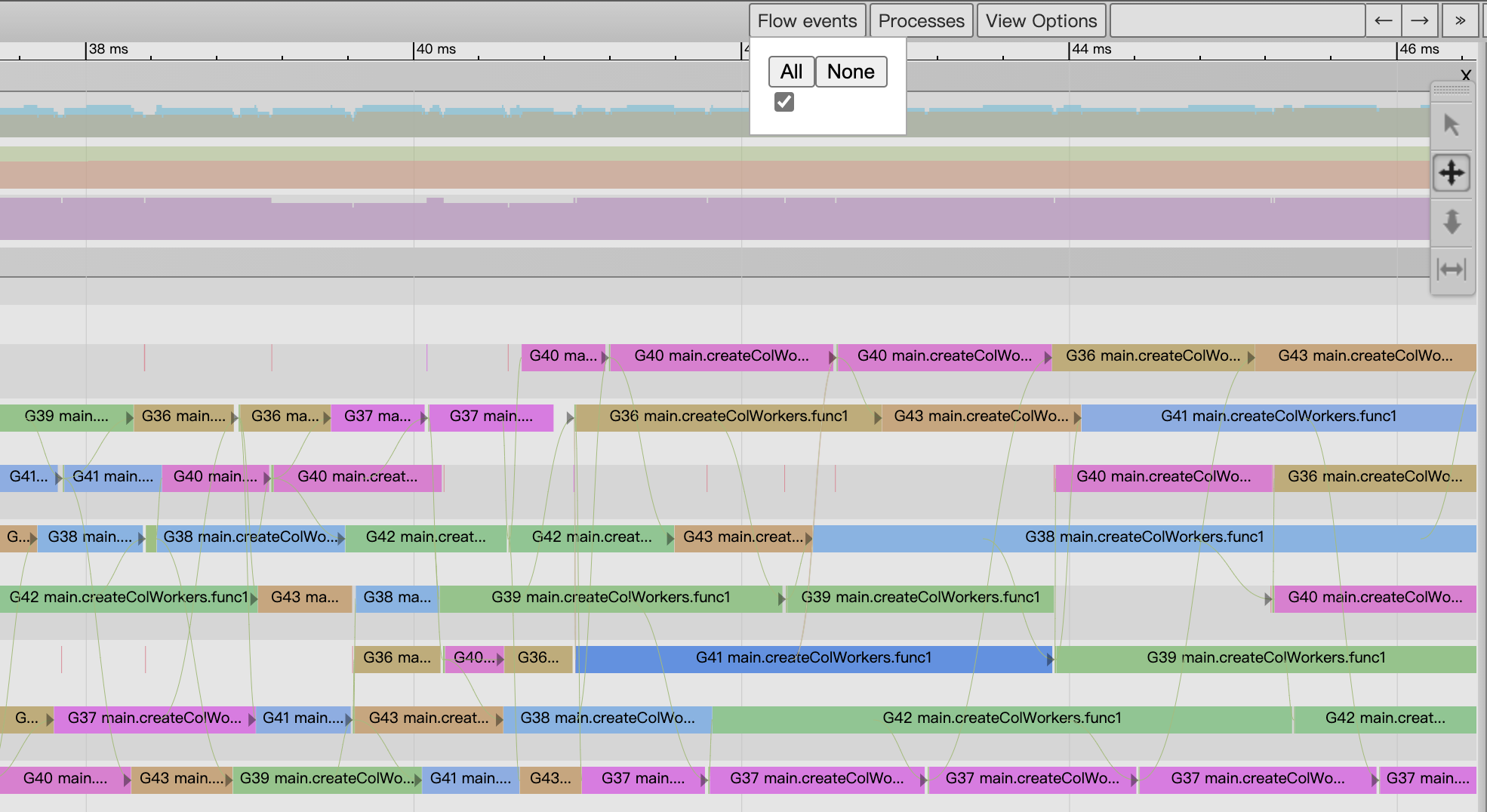
图15:关联事件流
- 事件详情区
View trace视图的最下方为“事件详情区”,当我们点选某个事件后,关于该事件的详细信息便会在这个区域显示出来,就像上面图14那样。
在宏观尺度上,每个P条带的第二行的事件因为持续事件较短而多呈现为一条竖线,我们点选这些事件不是很容易。点选这些事件的方法,要么将图像放大,要么通过左箭头或右箭头两个键盘键顺序选取,选取后可以通过m键显式标记出这个事件(再次敲击m键取消标记)。
2) Goroutine analysis
就像前面图5中展示的Goroutine analysis的各个子页面那样,Goroutine analysis为我们提供了从G视角看Go应用执行的图景。
点击图5中位于表第一列中的任一个Goroutine id,我们将进入Go视角视图:
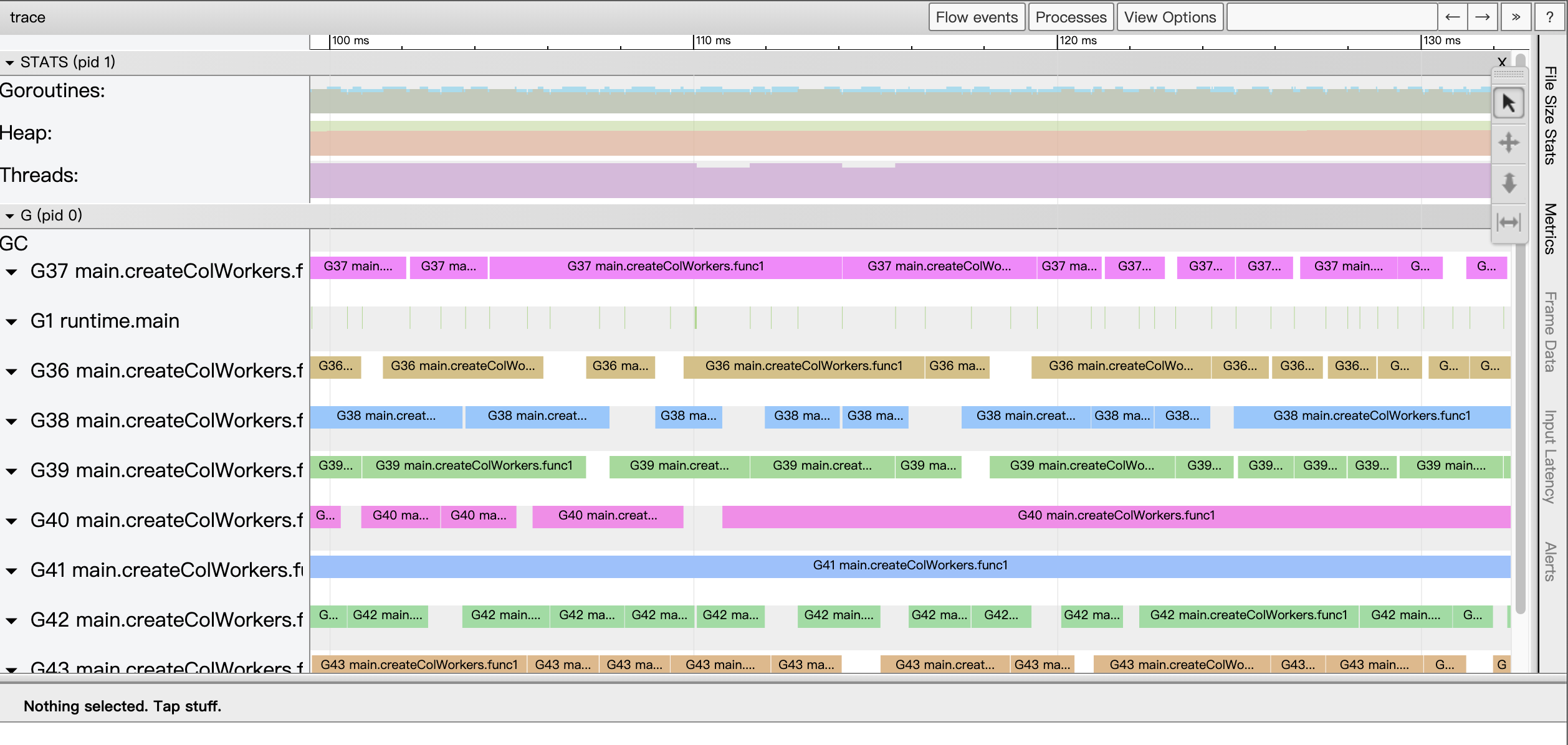
图16:Goroutine analysis提供的G视角视图
我们看到与View trace不同,这次页面中最广阔的区域提供的G视角视图,而不再是P视角视图。在这个视图中,每个G都会对应一个单独的条带(和P视角视图一样,每个条带都有两行),通过这一条带我们可以按时间线看到这个G的全部执行情况。通常我们仅需在goroutine analysis的表格页面找出执行最快和最慢的两个goroutine,在Go视角视图中沿着时间线对它们进行对比,以试图找出执行慢的goroutine究竟出了什么问题。
4. 实例理解
下面用一个实例理解一下Go Execution Tracer帮我们解决问题的过程。编写这样的例子不易,恰之前Francesc Campoy在其justforfun专栏中曾举过一个可用于Tracer的不错的例子,这里借用一下^_^。
Francesc Campoy举的是一个生成分形图片的例子,第一版代码如下:
// main.go
package main
import (
"image"
"image/color"
"image/png"
"log"
"os"
"runtime/trace"
)
const (
output = "out.png"
width = 2048
height = 2048
numWorkers = 8
)
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
f, err := os.Create(output)
if err != nil {
log.Fatal(err)
}
img := createSeq(width, height)
if err = png.Encode(f, img); err != nil {
log.Fatal(err)
}
}
// createSeq fills one pixel at a time.
func createSeq(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
return m
}
// pixel returns the color of a Mandelbrot fractal at the given point.
func pixel(i, j, width, height int) color.Color {
// Play with this constant to increase the complexity of the fractal.
// In the justforfunc.com video this was set to 4.
const complexity = 1024
xi := norm(i, width, -1.0, 2)
yi := norm(j, height, -1, 1)
const maxI = 1000
x, y := 0., 0.
for i := 0; (x*x+y*y < complexity) && i < maxI; i++ {
x, y = x*x-y*y+xi, 2*x*y+yi
}
return color.Gray{uint8(x)}
}
func norm(x, total int, min, max float64) float64 {
return (max-min)*float64(x)/float64(total) - max
}
这一版代码通过pixel函数算出待输出图片中的每个像素值,这版代码即便不用pprof也基本能定位出来程序热点在pixel这个关键路径上的函数上,更精确的位置是pixel中的那个循环。那么如何优化呢?pprof已经没招了,我们用Tracer来看看:
$go build main.go
$./main > seq.trace
$go tool trace seq.trace
go tool trace展示的View trace视图如下:
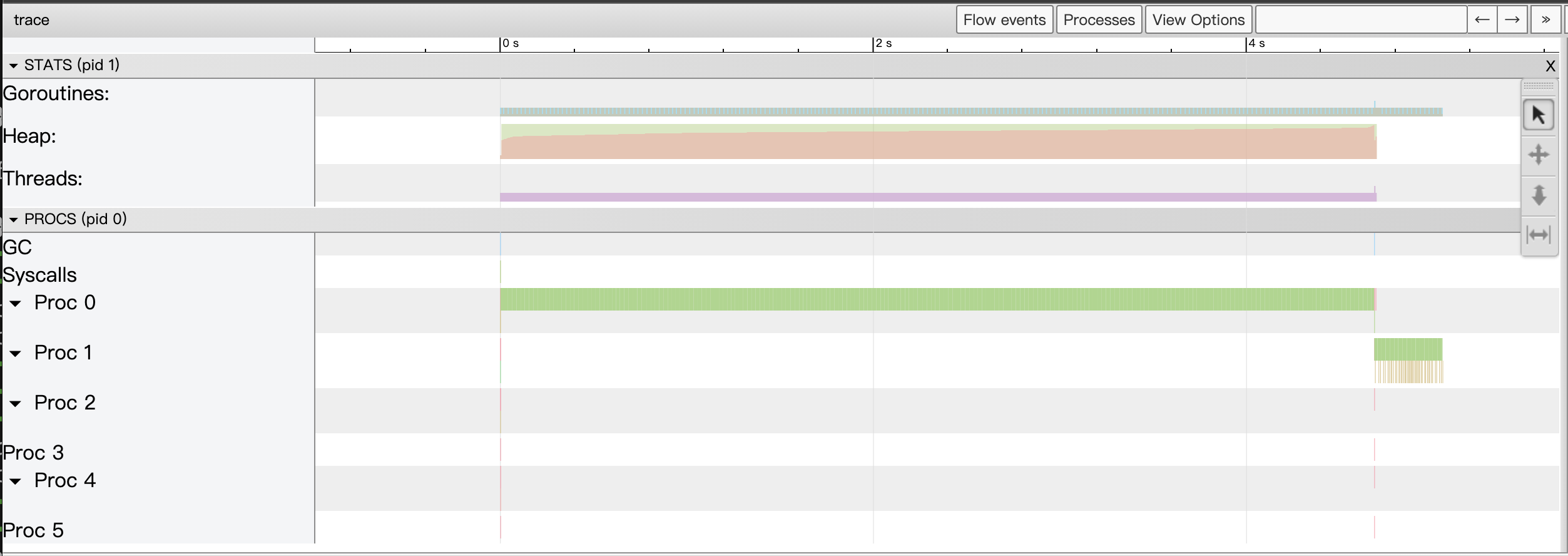
图17:示例第一版代码的View trace视图
通过上面View trace视图,我们一眼便可以看到这一版程序仅利用了机器上多个cpu core中的一个core,其余的cpu core处于空闲状态。
之后作者给出极端的并发方案,即每个像素点计算都对应启动一个新goroutine(用下面的createPixcel替换上面main.go中的createSeq):
func createPixel(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var w sync.WaitGroup
w.Add(width * height)
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
go func(i, j int) {
m.Set(i, j, pixel(i, j, width, height))
w.Done()
}(i, j)
}
}
w.Wait()
return m
}
这一版的程序执行性能的确有提升,并且充分利用了cpu,查看其Tracer数据(由于这一版的Tracer数据文件pixel.trace较大,需要一段时间的等待)如下:
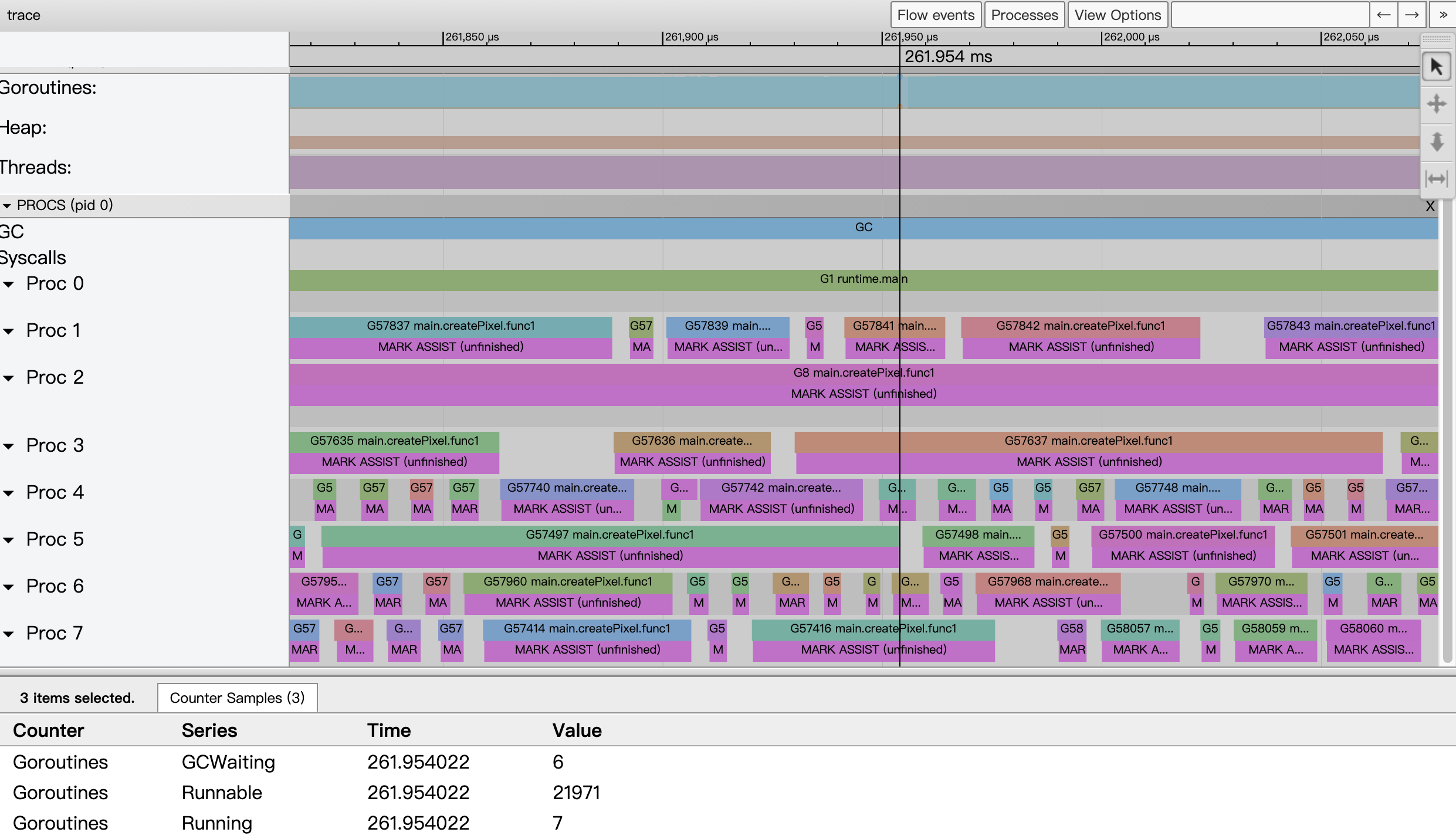
图18:示例第二版代码的View trace视图
以261.954ms附近的事件数据为例,我们看到系统的8个cpu core都满负荷运转,但从goroutine的状态采集数据看到,仅有7个goroutine处于运行状态,而有21971个goroutine正在等待被调度,这给go运行时的调度带去很大压力;另外由于这一版代码创建了2048×2048个goroutine(400多w个),导致内存分配频繁,给GC造成很大压力,从视图上来看,每个Goroutine似乎都在辅助GC做并行标记。由此可见,我们不能创建这么多goroutine,于是作者又给出了第三版代码,仅创建2048个goroutine,每个goroutine负责一列像素的生成(用下面createCol替换createPixel):
// createCol creates one goroutine per column.
func createCol(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var w sync.WaitGroup
w.Add(width)
for i := 0; i < width; i++ {
go func(i int) {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
w.Done()
}(i)
}
w.Wait()
return m
}
这一版代码的效果十分理想!性能提升近5倍。还可以再优化么?于是作者又实现了一版基于Worker并发模式的代码:
// createWorkers creates numWorkers workers and uses a channel to pass each pixel.
func createWorkers(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
type px struct{ x, y int }
c := make(chan px)
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
w.Done()
}()
}
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
c <- px{i, j}
}
}
close(c)
w.Wait()
return m
}
作者的机器是8核主机,于是它预创建了8个worker goroutine,主goroutine通过一个channel c向各个goroutine派发工作。但作者并没有看到预期的性能,其性能还不如每个像素一个goroutine的版本。查看Tracer情况如下(这一版代码的Tracer数据更多,解析和加载时间更长):
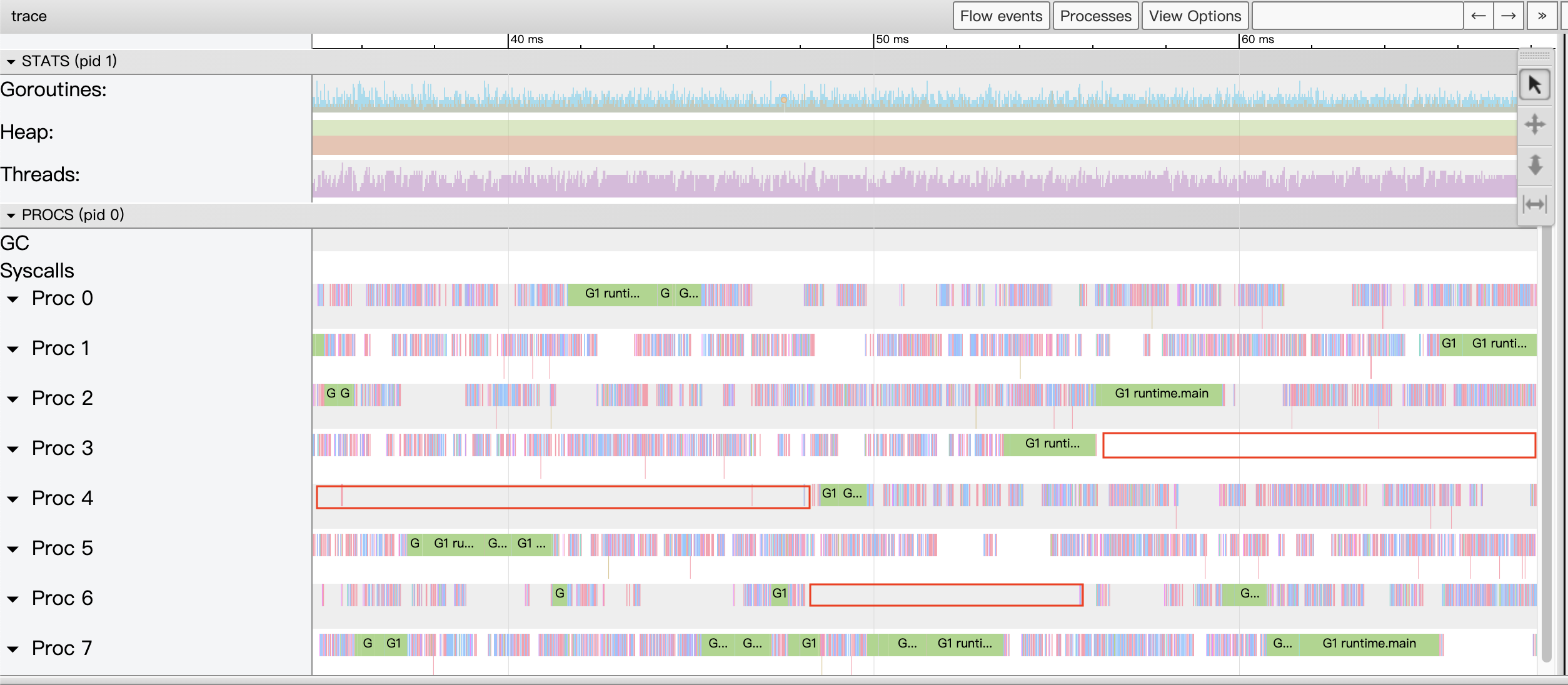
图19:示例第四版代码的View trace视图
我们看到适当放大后的View trace视图,我们看到了很多大段的Proc暂停以及不计其数的小段暂停,显然goroutine发生阻塞了,我们接下来通过Synchronization blocking profile查看究竟在哪里阻塞时间最长:

图20:示例第四版代码的Synchronization blocking profile
我们看到在channel接收上所有goroutine一共等待了近60s。从这版代码来看,main goroutine要进行近400多w次发送,而其他8个worker goroutine都得耐心阻塞在channel接收上等待,这样的结构显然不够优化,即便将channel换成带缓冲的也依然不够理想。
作者想到了createCol的思路,即不将每个像素点作为一个task发给worker,而是将一个列作为一个工作单元发送给worker,每个worker完成一个列像素的计算,这样我们来到了最终版代码(使用下面的createColWorkersBuffered替换createWorkers):
func createColWorkersBuffered(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
c := make(chan int, width)
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for i := range c {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
w.Done()
}()
}
for i := 0; i < width; i++ {
c <- i
}
close(c)
w.Wait()
return m
}
这版代码的确是所有版本中性能最好的,其Tracer的View trace视图如下:
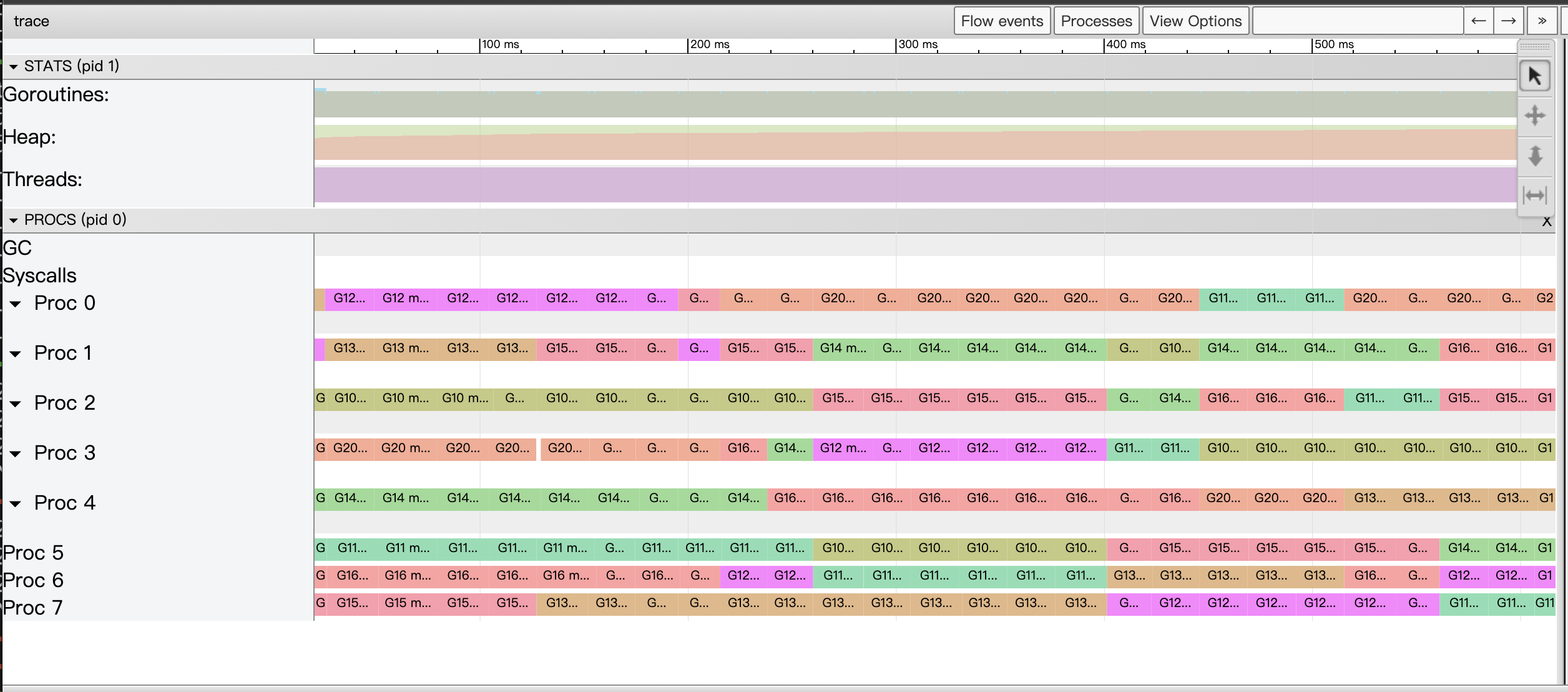
图21:示例最终版代码View trace视图
这几乎就是一幅完美的View trace视图!
5. 小结
Go Execution Tracer不是银弹,它不能帮你解决Go程序中的所有问题。通常对Go应用做性能分析时,我们都会使用pprof先找热点,等消除热点后,再用Go Execution Tracer通盘查看整个Go应用中goroutine的执行情况,通过View trace或Goroutine analysis找出“诡异点”并进行细致分析。
Go应用的并行性、延迟、goroutine阻塞等方面问题是Go Execution Tracer擅长的“主战场”。
6. 参考资料
- 《Go Execution Tracer设计文档》 – https://docs.google.com/document/d/1CvAClvFfyA5R-PhYUmn5OOQtYMH4h6I0nSsKchNAySU/preview
- Go应用诊断 – https://tip.golang.org/doc/diagnostics#execution-tracer
- 《Go tool trace介绍》 – https://about.sourcegraph.com/go/an-introduction-to-go-tool-trace-rhys-hiltner/
- 《Go execution tracer》 – https://blog.gopheracademy.com/advent-2017/go-execution-tracer/
- 《go tool trace》- https://making.pusher.com/go-tool-trace/
“Gopher部落”知识星球正式转正(从试运营星球变成了正式星球)!“gopher部落”旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!部落目前虽小,但持续力很强。在2021年上半年,部落将策划两个专题系列分享,并且是部落独享哦:
- Go技术书籍的书摘和读书体会系列
- Go与eBPF系列
欢迎大家加入!
Go技术专栏“改善Go语⾔编程质量的50个有效实践”正在慕课网火热热销中!本专栏主要满足广大gopher关于Go语言进阶的需求,围绕如何写出地道且高质量Go代码给出50条有效实践建议,上线后收到一致好评!欢迎大家订
阅!

我的网课“Kubernetes实战:高可用集群搭建、配置、运维与应用”在慕课网热卖中,欢迎小伙伴们订阅学习!

我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 微信公众号:iamtonybai
- 博客:tonybai.com
- github: https://github.com/bigwhite
- “Gopher部落”知识星球:https://public.zsxq.com/groups/51284458844544
微信赞赏:

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。