
本文永久链接 – https://tonybai.com/2022/08/22/some-changes-in-go-1-19
我们知道Go团队在2015年重新规定了团队发布版本的节奏,将Go大版本的发布频率确定为每年两次,发布窗口定为每年的2月与8月。而实现自举的Go 1.5版本是这一个节奏下发布的第一个版本。一般来说,Go团队都会在这两个窗口的中间位置发布版本,不过这几年也有意外,比如承载着泛型落地责任的Go 1.18版本就延迟了一个月发布。
就在我们以为Go 1.19版本不会很快发布的时候,美国时间2022年8月2日,Go核心团队正式发布了Go 1.19版本,这个时间不仅在发布窗口内而且相对于惯例还提前了。为什么呢?很简单,Go 1.19是一个“小”版本,当然这里的“小”是相对于Go 1.18那样的“大”而言的。Go 1.19版本开发周期仅有2个月左右(3~5月初),这样Go团队压缩了添加到Go 1.19版本中的feature数量。
不过尽管如此,Go 1.19中依然有几个值得我们重点关注的变化点,在这篇文章中我就和大家一起来看一下。
一. 综述
在6月份(那时Go 1.19版本已经Freeze),我曾写过一篇《Go 1.19新特性前瞻》,简要介绍了当时基本确定的Go 1.19版本的一些新特性,现在来看,和Go 1.19版本正式版差别不大。
- 泛型方面
考虑到Go 1.18泛型刚刚落地,Go 1.18版本中的泛型并不是完全版。但Go 1.19版本也没有急于实现泛型设计文档)中那些尚未实现的功能特性,而是将主要精力放在了修复Go 1.18中发现的泛型实现问题上了,目的是夯实Go泛型的底座,为Go 1.20以及后续版本实现完全版泛型奠定基础(详细内容可查看《Go 1.19新特性前瞻》一文)。
- 其他语法方面
无,无,无!重要的事情说三遍。
这样,Go 1.19依旧保持了Go1兼容性承诺。
- 正式在linux上支持龙芯架构(GOOS=linux, GOARCH=loong64)
这一点不得不提,因为这一变化都是国内龙芯团队贡献的。不过目前龙芯支持的linux kernel版本最低也是5.19,意味着龙芯在老版本linux上还无法使用Go。
- go env支持CGO_CFLAGS, CGO_CPPFLAGS, CGO_CXXFLAGS, CGO_FFLAGS, CGO_LDFLAGS和GOGCCFLAGS
当你想设置全局的而非包级的CGO构建选项时,可以通过这些新加入的CGO相关环境变量进行,这样就可以避免在每个使用Cgo的Go源文件中使用cgo指示符来分别设置了。
目前这些用于CGO的go环境变量的默认值如下(以我的macos上的默认值为例):
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
GOGCCFLAGS="-fPIC -arch x86_64 -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/cz/sbj5kg2d3m3c6j650z0qfm800000gn/T/go-build1672298076=/tmp/go-build -gno-record-gcc-switches -fno-common"
其他更具体的变化就不赘述了,大家可以移步《Go 1.19新特性前瞻》看看。
下面我们重点说说Go 1.19中的两个重要变化:新版Go内存模型文档与Go运行时引入Soft memory limit。
二. 修订Go内存模型文档
记得当年初学Go的时候,所有Go官方文档中最难懂的一篇就属Go内存模型文档(如下图)这一篇了,相信很多gopher在初看这篇文档时一定有着和我相似的赶脚^_^。
图:老版Go内存模型文档
注:查看老版Go内存模型文档的方法:godoc -http=:6060 -goroot /Users/tonybai/.bin/go1.18.3,其中godoc已经不随着go安装包分发了,需要你单独安装,命令为:go install golang.org/x/tools/cmd/godoc。
那么,老版内存模型文档说的是啥呢?为什么要修订?搞清这两个问题,我们就大致知道新版内存模型文档的意义了。 我们先来看看什么是编程语言的内存模型。
1. 什么是内存模型?
提到内存模型,我们要从著名计算机科学家,2013年图灵奖得主Leslie Lamport在1979发表的名为《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》的论文说起。
在这篇文章中,Lamport给出了多处理器计算机在共享内存的情况下并发程序正确运行的条件,即多处理器要满足顺序一致性(sequentially consistent)。
文中提到:一个高速运行的处理器不一定按照程序指定的顺序(代码顺序)执行。如果一个处理器的执行结果(可能是乱序执行)与按照程序指定的顺序(代码顺序)执行的结果一致,那么说这个处理器是有序的(sequential)。
而对于一个共享内存的多处理器而言,只有满足下面条件,才能被认定是满足顺序一致性的,即具备保证并发程序正确运行的条件:
- 任何一次执行的结果,都和所有处理器的操作按照某个顺序执行的结果一致;
- 在“某个顺序执行”中单独看每个处理器,每个处理器也都是按照程序指定的顺序(代码顺序)执行的。
顺序一致性就是一个典型的共享内存、多处理器的内存模型,这个模型保证了所有的内存访问都是以原子方式和按程序顺序进行的。下面是一个共享内存的顺序一致性的抽象机器模型示意图,图来自于《A Tutorial Introduction to the ARM and POWER Relaxed Memory Models》 :
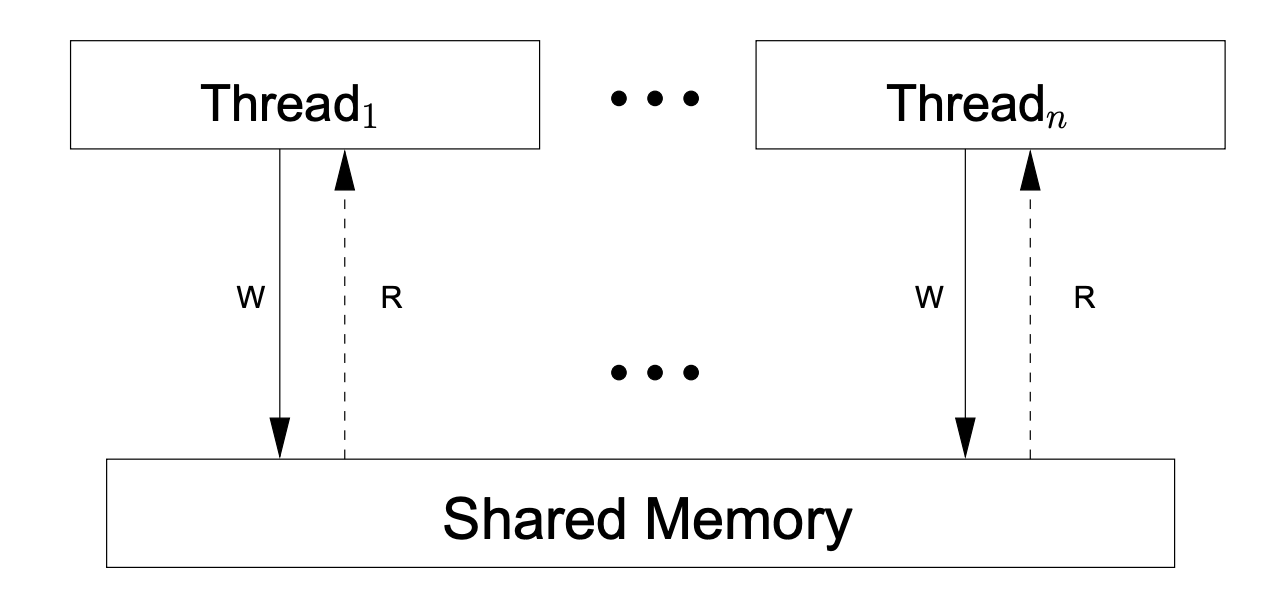
根据顺序一致性,上面图中的抽象机器具有下面特点:
- 没有本地的重新排序:每个硬件线程按照程序指定的顺序执行指令,完成每条指令(包括对共享内存的任何读或写)后再开始下一条。
- 每条写入指令对所有线程(包括进行写入的线程)都是同时可见的。
从程序员角度来看,顺序一致性的内存模型是再理想不过了。所有读写操作直面内存,没有缓存,一个处理器(或硬件线程)写入内存的值,其他处理器(或硬件线程)便可以观察到。借助硬件提供的顺序一致性(SC),我们可以实现“所写即所得”。
但是这样的机器真的存在吗?并没有,至少在量产的机器中并没有。为什么呢?因为顺序一致性不利于硬件和软件的性能优化。真实世界的共享内存的多处理器计算机的常见机器模型是这样的,也称为Total Store Ordering,TSO模型(图来自《A Tutorial Introduction to the ARM and POWER Relaxed Memory Models》):
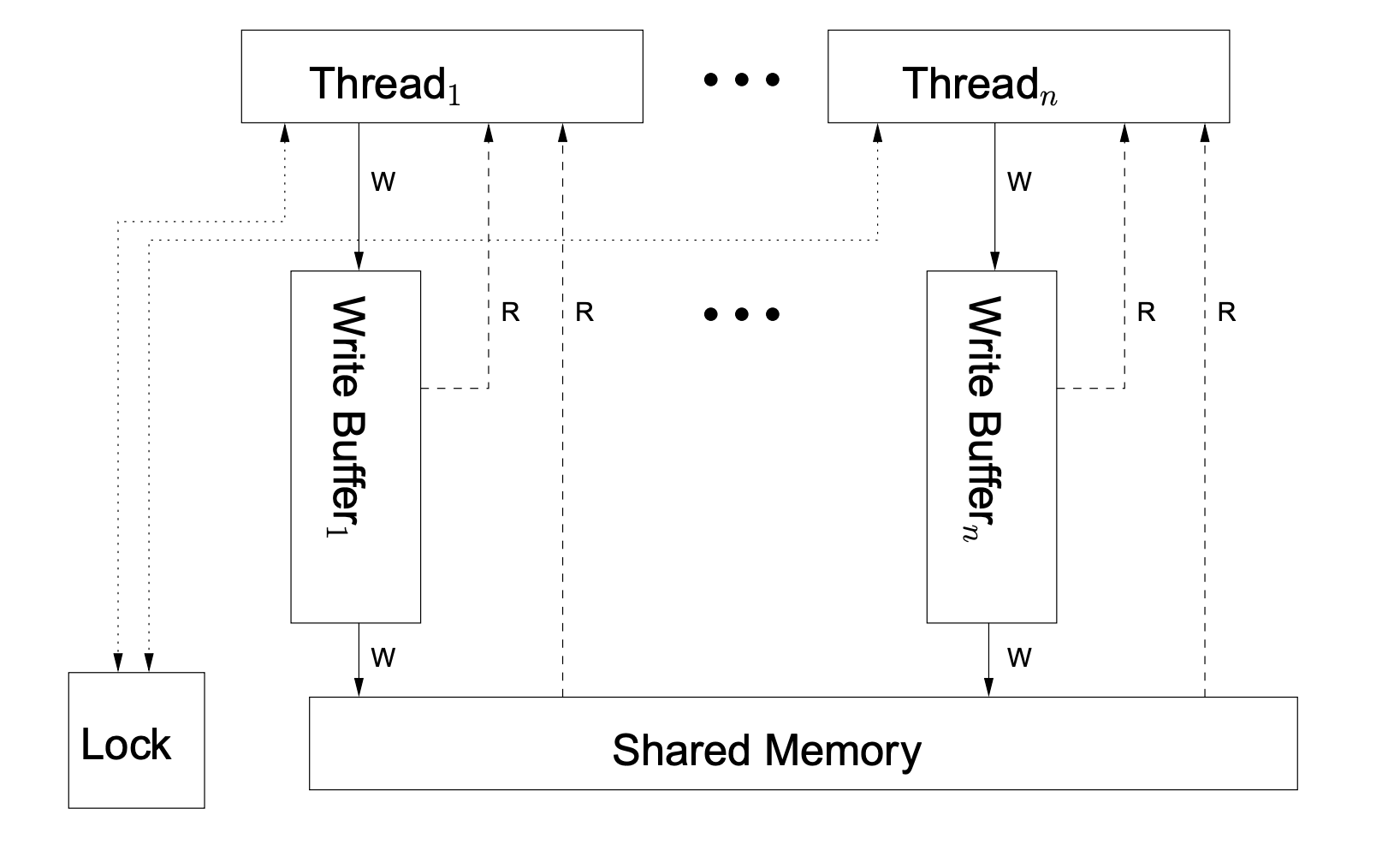
我们看到,在这种机器下,所有处理器仍连接到单个共享内存,但每个处理器的写内存操作从写入共享内存变为了先写入本处理器的写缓存队列(write buffer),这样处理器无需因要等待写完成(write complete)而被阻塞,并且一个处理器上的读内存操作也会先查阅本处理器的写缓存队列(但不会查询其他处理器的写缓存队列)。写缓存队列的存在极大提升了处理器写内存操作的速度。
但也正是由于写缓存的存在,TSO模型无法满足顺序一致性,比如:“每条写入指令对所有线程(包括进行写入的线程)都是同时可见的”这一特性就无法满足,因为写入本地写缓存队列的数据在未真正写入共享内存前只对自己可见,对其他处理器(硬件线程)并不可见。
根据Lamport的理论,在不满足SC的多处理器机器上程序员没法开发出可以正确运行的并发程序(Data Race Free, DRF),那么怎么办呢?处理器提供同步指令给开发者。对开发者而言,有了同步指令的非SC机器,具备了SC机器的属性。只是这一切对开发人员不是自动的/透明的了,需要开发人员熟悉同步指令,并在适当场合,比如涉及数据竞争Data Race的场景下正确使用,这大大增加了开发人员的心智负担。
开发人员通常不会直面硬件,这时就要求高级编程语言对硬件提供的同步指令进行封装并提供给开发人员,这就是编程语言的同步原语。而编程语言使用哪种硬件同步指令,封装出何种行为的同步原语,怎么应用这些原语,错误的应用示例等都是需要向编程语言的使用者进行说明的。而这些都将是编程语言内存模型文档的一部分。
如今主流的编程语言的内存模型都是顺序一致性(SC)模型,它为开发人员提供了一种理想的SC机器(虽然实际中的机器并非SC的),程序是建构在这一模型之上的。但就像前面说的,开发人员要想实现出正确的并发程序,还必须了解编程语言封装后的同步原语以及他们的语义。只要程序员遵循并发程序的同步要求合理使用这些同步原语,那么编写出来的并发程序就能在非SC机器上跑出顺序一致性的效果。
知道了编程语言内存模型的含义后,接下来,我们再来看看老版Go内存模型文档究竟表述了什么。
2. Go内存模型文档
按照上面的说明,Go内存模型文档描述的应该是要用Go写出一个正确的并发程序所要具备的条件。
再具体点,就像老版内存模型文档开篇所说的那样:Go内存模型规定了一些条件,一旦满足这些条件,当在一个goroutine中读取一个变量时,Go可以保证它可以观察到不同goroutine中对同一变量的写入所产生的新值。
接下来,内存模型文档就基于常规的happens-before定义给出了Go提供的各种同步操作及其语义,包括:
- 如果一个包p导入了包q,那么q的init函数的完成发生在p的任何函数的开始之前。
- 函数main.main的开始发生在所有init函数完成之后。
- 启动一个新的goroutine的go语句发生在goroutine的执行开始之前。
- 一个channel上的发送操作发生在该channel的对应接收操作完成之前。
- 一个channel的关闭发生在一个返回零值的接收之前(因为该channel已经关闭)。
- 一个无缓冲的channel的接收发生在该channel的发送操作完成之前。
- 一个容量为C的channel上的第k个接收操作发生在该channel第k+C个发送操作完成之前。
- 对于任何sync.Mutex或sync.RWMutex变量l,当n<m时,第n次l.Unlock调用发生在第m次调用l.Lock()返回之前。
- once.Do(f)中的f()调用发生在对once.Do(f)的任何一次调用返回之前。
接下来,内存模型文档还定义了一些误用同步原语的例子。
那么新内存模型文档究竟更新了哪些内容呢?我们继续往下看。
3. 修订后的内存模型文档都有哪些变化
图:修订后的Go内存模型文档
负责更新内存模型文档的Russ Cox首先增加了Go内存模型的总体方法(overall approach)。
Go的总体方法在C/C++和Java/Js之间,既不像C/C++那样将存在Data race的程序定义为违法的,让编译器以未定义行为处置它,即运行时表现出任意可能的行为;又不完全像Java/Js那样尽量明确Data Race情况下各种语义,将Data race带来的影响限制在最小,使程序更为可靠。
Go对于一些存在data Race的情况会输出race报告并终止程序,比如多goroutine在未使用同步手段下对map的并发读写。除此之外,Go对其他存数据竞争的场景有明确的语义,这让程序更可靠,也更容易调试。
其次,新版Go内存模型文档增补了对这些年sync包新增的API的说明,比如: mutex.TryLock、mutex.TryRLock等。而对于sync.Cond、Map、Pool、WaitGroup等文档没有逐一描述,而是建议看API文档。
在老版内存模型文档中,没有对sync/atom包进行说明,新版文档增加了对atom包以及runtime.SetFinalizer的说明。
最后,文档除了提供不正确同步的例子,还增加了对不正确编译的例子的说明。
另外这里顺便提一下:Go 1.19在atomic包中引入了一些新的原子类型,包括: Bool, Int32, Int64, Uint32, Uint64, Uintptr和Pointer。这些新类型让开发人员在使用atomic包是更为方便,比如下面是Go 1.18和Go 1.19使用Uint64类型原子变量的代码对比:
对比Uint64的两种作法:
// Go 1.18
var i uint64
atomic.AddUint64(&i, 1)
_ = atomic.LoadUint64(&i)
vs.
// Go 1.19
var i atomic.Uint64 // 默认值为0
i.Store(17) // 也可以通过Store设置初始值
i.Add(1)
_ = i.Load()
atomic包新增的Pointer,避免了开发人员在使用原子指针时自己使用unsafe.Pointer进行转型的麻烦。同时atomic.Pointer是一个泛型类型,如果我没记错,它是Go 1.18加入comparable预定义泛型类型之后,第一次在Go中引入基于泛型的标准库类型:
// $GOROOT/src/sync/atomic/type.go
// A Pointer is an atomic pointer of type *T. The zero value is a nil *T.
type Pointer[T any] struct {
_ noCopy
v unsafe.Pointer
}
// Load atomically loads and returns the value stored in x.
func (x *Pointer[T]) Load() *T { return (*T)(LoadPointer(&x.v)) }
// Store atomically stores val into x.
func (x *Pointer[T]) Store(val *T) { StorePointer(&x.v, unsafe.Pointer(val)) }
// Swap atomically stores new into x and returns the previous value.
func (x *Pointer[T]) Swap(new *T) (old *T) { return (*T)(SwapPointer(&x.v, unsafe.Pointer(new))) }
// CompareAndSwap executes the compare-and-swap operation for x.
func (x *Pointer[T]) CompareAndSwap(old, new *T) (swapped bool) {
return CompareAndSwapPointer(&x.v, unsafe.Pointer(old), unsafe.Pointer(new))
}
此外,atomic包新增的Int64和Uint64类型还有一个特质,那就是Go保证其地址可以自动对齐到8字节上(即地址可以被64整除),即便在32位平台上亦是如此,这可是连原生int64和uint64也尚无法做到的。
go101在推特上分享了一个基于atomic Int64和Uint64的tip。利用go 1.19新增的atomic.Int64/Uint64,我们可以用下面方法保证结构体中某个字段一定是8 byte对齐的,即该字段的地址可以被64整除。
import "sync/atomic"
type T struct {
_ [0]atomic.Int64
x uint64 // 保证x是8字节对齐的
}
前面的代码中,为何不用_ atomic.Int64呢,为何用一个空数组呢,这是因为空数组在go中不占空间,大家可以试试输出上面结构体T的size,看看是不是8。
三. 引入Soft memory limit
1. 唯一GC调优选项:GOGC
近几个大版本,Go GC并没有什么大的改动/优化。和其他带GC的编程语言相比,Go GC算是一个奇葩的存在了:对于开发者而言,Go 1.19版本之前,Go GC的调优参数仅有一个:GOGC(也可以通过runtime/debug.SetGCPercent调整)。
GOGC默认值为100,通过调整它的值,我们可以调整GC触发的时机。计算下一次触发GC的堆内存size的公式如下:
// Go 1.18版本之前
目标堆大小 = (1+GOGC/100) * live heap // live heap为上一次GC标记后的堆上的live object的总size
// Go 1.18版本及之后
目标堆大小 = live heap + (live heap + GC roots) * GOGC / 100
注:Go 1.18以后将GC roots(包括goroutine栈大小和全局变量中的指针对象大小)纳入目标堆大小的计算
以Go 1.18之前的版本为例,当GOGC=100(默认值)时,如果某一次GC后的live heap为10M,那么下一次GC开启的目标堆heap size为20M,即在两次GC之间,应用程序可以分配10M的新堆对象。
可以说GOGC控制着GC的运行频率。当GOGC值设置的较小时,GC运行的就频繁一些,参与GC工作的cpu的比重就多一些;当GOGC的值设置的较大时,GC运行的就不那么频繁,相应的参与GC工作的cpu的比重就小一些,但要承担内存分配接近资源上限的风险。
这样一来,摆在开发者面前的问题就是:GOGC的值很难选,这唯一的调优选项也就成为了摆设。
同时,Go runtime是不关心资源limit的,只是会按照应用的需求持续分配内存,并在自身内存池不足的情况下向OS申请新的内存资源,直到内存耗尽(或到达平台给应用分配的memory limit)而被oom killed!
为什么有了GC,Go应用还是会因耗尽系统memory资源而被oom killed呢?我们继续往下看。
2. Pacer的问题
上面的触发GC的目标堆大小计算公式,在Go runtime内部被称为pacer算法,pacer中文有翻译成“起搏器”的,有译成“配速器”的。不管译成啥,总而言之它是用来控制GC触发节奏的。
不过pacer目前的算法是无法保证你的应用不被OOM killed的,举个例子(见下图):
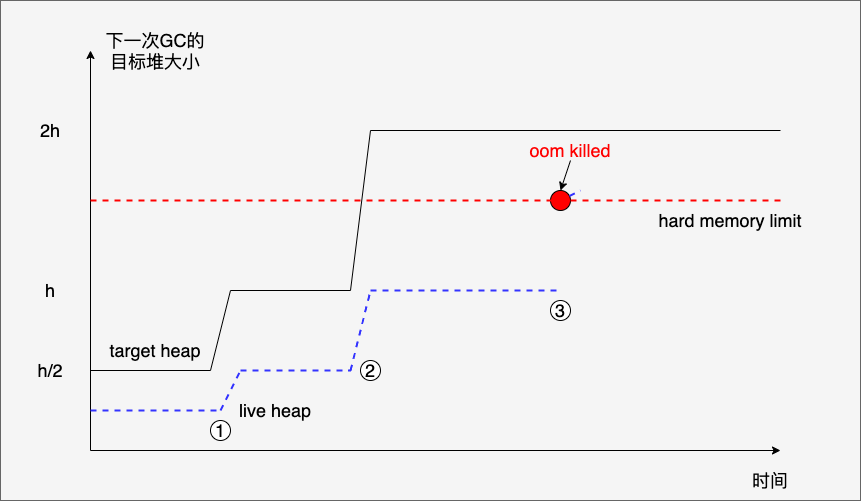
在这个例子中:
- 一开始live heap始终平稳,净增的heap object保持0,即新分配的heap object与被清扫掉的heap object相互抵消。
- 后续在(1)处出现一次target heap的跃升(从h/2->h),原因显然是live heap object变多了,都在用,即便触发GC也无法清除。不过此时target heap(h)是小于hard memory limit的;
- 程序继续执行,在(2)处,又出现一次target heap的跃升(从h->2h),而live heap object也变多了,稳定在h,此时,target heap变为2h,高于hard memory limit了;
- 后续程序继续执行,当live heap object到达(3)时,实际Go的堆内存(包括未清理的)超过了hard memory limit,但由于尚未到达target heap(2h),GC没有被执行,因此应用被oom killed。
我们看到这个例子中,并非Go应用真正需要那么多内存(如果有GC及时清理,live heap object就在(3)的高度),而是Pacer算法导致了没能及时触发GC。
那么如何尽可能的避免oom killed呢?我们接下来看一下Go社区给出了两个“民间偏方”。
3. Go社区的GC调优方案
这两个“偏方”, 一个是twitch游戏公司给出的memory ballast(内存压舱石),另外一个则是像uber这样的大厂采用的自动GC动态调优方案。当然这两个方案不光是要避免oom,更是为了优化GC,提高程序的执行效率。
下面我们分别简单介绍一下。先来说说twitch公司的memory ballast。twitch的Go服务运行在具有64G物理内存的VM上,通过观察运维人员发现,服务常驻的物理内存消耗仅为400多M,但Go GC的启动却十分频繁,这导致其服务响应的时间较长。twitch的工程师考虑充分利用内存,降低GC的启动频率,从而降低服务的响应延迟。
于是他们想到了一种方法,他们在服务的main函数初始化环节像下面这样声明了一个10G容量的大切片,并保证这个切片在程序退出前不被GC释放掉:
func main() {
// Create a large heap allocation of 10 GiB
ballast := make([]byte, 10<<30)
// Application execution continues
// ...
runtime.Keepalive(ballast)
// ... ...
}
这个切片由于太大,将在堆上分配并被runtime跟踪,但这个切片并不会给应用带去实质上的物理内存消耗,这得益于os对应用进程内存的延迟簿记:只有读写的内存才会导致缺页中断并由OS为之分配物理内存。从类似top的工具来看,这10个G的字节仅会记录在VIRT/VSZ(虚拟内存)上,而不会记录在RES/RSS(常驻内存)上。
这样一来,根据前面Pacer算法的原理,触发GC的下一个目标堆大小就至少为20G,在Go服务分配堆内存到20G之前GC都不会被触发,所有cpu资源都会被用来处理业务,这也与twitch的实测结果一致(GC次数下降99%)。
一旦到了20G,由于之前观测的结果是服务仅需400多M物理内存,大量heap object会被回收,Go服务的live heap会回到400多M,但重新计算目标堆内存时,由于前面那个“压舱石”的存在,目标堆内存已经会在至少20G的水位上,就这样GC次数少了,GC少了,worker goroutine参加“劳役”的时间就少了,cpu利用率高了,服务响应的延迟也下来了。
注:“劳役”是指worker goroutine在mallocgc内存时被runtime强制“劳役”:停下自己手头的工作,去辅助GC做heap live object的mark。
不过使用该方案的前提是你对你的Go服务的内存消耗情况(忙闲时)有着精确的了解,这样才能结合硬件资源情况设定合理的ballast值。
按照Soft memory limit proposal的说法,该方案的弊端如下:
- 不能跨平台移植,据说Windows上不适用(压舱石的值会直接反映为应用的物理内存占用);
- 不能保证随着Go运行时的演进而继续正常工作(比如:一旦pacer算法发生了巨大变化);
- 开发者需要进行复杂的计算并估计运行时内存开销以选择适合的ballast大小。
接下来我们再来看看自动GC动态调优方案。
去年12月,uber在其官方博客分享了uber内部使用的半自动化Go GC调优方案,按uber的说法,这种方案实施后帮助uber节省了70K cpu核的算力。其背后的原理依旧是从Pacer的算法公式出发,改变原先Go服务生命周期全程保持GOGC值静态不变的作法,在每次GC时,依据容器的内存限制以及当前的live heap size动态计算并设置GOGC值,从而实现对内存不足oom-killed的保护,同时最大程度利用内存,改善Gc对cpu的占用率。
显然这种方案更为复杂,需要有一个专家团队来保证这种自动调优的参数的设置与方案的实现。
4. 引入Soft memory limit
其实Go GC pacer的问题还有很多, Go核心团队开发者Michael Knyszek提了一个pacer问题综述的issue,将这些问题做了汇总。但问题还需一个一个解决,在Go 1.19这个版本中,Michael Knyszek就带来了他的Soft memory limit的解决方案。
这个方案在runtime/debug包中添加了一个名为SetMemoryLimit的函数以及GOMEMLIMIT环境变量,通过他们任意一个都可以设定Go应用的Memory limit。
一旦设定了Memory limit,当Go堆大小达到“Memory limit减去非堆内存后的值”时,一轮GC会被触发。即便你手动关闭了GC(GOGC=off),GC亦是会被触发。
通过原理我们可以看到,这个特性最直接解决的就是oom-killed这个问题!就像前面pacer问题示意图中的那个例子,如果我们设定了一个比hard memory limit小一些的soft memory limit的值,那么在(3)那个点便不会出现oom-killed,因为在那之前soft memory limit就会触发一次GC,将一些无用的堆内存回收掉了。
但我们也要注意:soft memory limit不保证不会出现oom-killed,这个也很好理解。如果live heap object到达limit了,说明你的应用内存资源真的不够了,是时候扩内存条资源了,这个是GC无论如何都无法解决的问题。
但如果一个Go应用的live heap object超过了soft memory limit但还尚未被kill,那么此时GC会被持续触发,但为了保证在这种情况下业务依然能继续进行,soft memory limit方案保证GC最多只会使用50%的CPU算力,以保证业务处理依然能够得到cpu资源。
对于GC触发频率高,要降低GC频率的情况,soft memory limit的方案就是关闭GC(GOGC=off),这样GC只有当堆内存到达soft memory limit值时才会触发,可以提升cpu利用率。不过有一种情况,Go官方的GC guide中不建议你这么做,那就是当你的Go程序与其他程序共享一些有限的内存时。这时只需保留内存限制并将其设置为一个较小的合理值即可,因为它可能有助于抑制不良的瞬时行为。
那么多大的值是合理的soft memory limit值呢?在Go服务独占容器资源时,一个好的经验法则是留下额外的5-10%的空间,以考虑Go运行时不知道的内存来源。uber在其博客中设定的limit为资源上限的70%,也是一个不错的经验值。
四. 小结
也许Go 1.19因开发周期的压缩给大家带来的惊喜并不多。不过特性虽少,却都很实用,比如上面的soft memory limit,一旦用好,便可以帮助大家解决大问题。
而拥有正常开发周期的Go 1.20已经处于积极的开发中,从目前里程碑中规划的功能和改进来看,Go泛型语法将得到进一步的补全,向着完整版迈进,就这一点就值得大家期待了!
五. 参考资料
- Russ Cox内存模型系列 – https://research.swtch.com/mm
- 关于Go内存模型的讨论 – https://github.com/golang/go/discussions/47141
- How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs- https://www.microsoft.com/en-us/research/publication/make-multiprocessor-computer-correctly-executes-multiprocess-programs
- A Tutorial Introduction to the ARM and POWER Relaxed Memory Models- https://www.cl.cam.ac.uk/~pes20/ppc-supplemental/test7.pdf
- Weak Ordering – A New Definition- https://people.eecs.berkeley.edu/~kubitron/courses/cs258-S08/handouts/papers/adve-isca90.pdf
- Foundations of the C++ Concurrency Memory Model – https://www.hpl.hp.com/techreports/2008/HPL-2008-56.pdf
- Go GC pacer原理 – https://docs.google.com/document/d/1wmjrocXIWTr1JxU-3EQBI6BK6KgtiFArkG47XK73xIQ/edit
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2022年,Gopher部落全面改版,将持续分享Go语言与Go应用领域的知识、技巧与实践,并增加诸多互动形式。欢迎大家加入!




我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 博客:tonybai.com
- github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。