本文翻译自《Illustrated Tales of Go Runtime Scheduler》。
译注:原文章结构有些乱,笔者自行在译文中增加了一些分级标题,让结构显得更清晰一些:)。
多goroutines形式的Go并发是编写现代并发软件的一种非常方便的方法,但是您的Go程序是如何高效地运行这些goroutines的呢?
在这篇文章中,我们将深入Go运行时底层,从设计角度了解Go运行时调度程序是如何实现其魔法的,并运用这些原理去解释在Go性能调试过程中产生的Go调度程序跟踪信息。
所有的工程奇迹都源于需要。因此,要了解为什么需要一个Go运行时调度程序以及它是如何工作的,我们可以让时间回到操作系统兴起的那个时代,回顾操作系统的历史可以使我们深入的了解问题的根源。如果不了解问题的根源,就没有解决它的希望。这就是历史所能做的。
一. 操作系统的历史
- 单用户(无操作系统)。
- 批处理,独占系统,直到运行完成。
- 多道程序(译注:允许多个程序同时进入内存并运行)
多道程序的目的是使CPU和I/O重叠(overlap)。(译注:多道程序出现之前,当操作系统执行I/O操作时,CPU是空闲的;多道程序的引入实现了在一个程序占用CPU的时候,另一个程序在执行I/O操作)
那怎么实现多道程序(的CPU与I/O重叠)呢?两种方式:多道批处理系统和分时系统。
-
多道批处理系统
- IBM OS/MFT(具有固定数量的任务的多道程序)
- IBM OS/MVT(具有可变数量的任务的多道程序)在这里,每个作业(job)仅获得其所需的内存量。随着job的进出,内存的划分会发生变化。
-
分时
- 这是一种多道程序设计,可以在作业之间快速切换。决定何时切换以及切换到哪个作业的过程就称为调度(scheduling)。
当前,大多数操作系统使用分时调度程序。
那么这些调度程序将用来调度什么实体(entity)呢?
- 不同的正在执行的程序(即进程process)
- 或作为进程子集存在使用CPU的基本单元:线程
但是在这些实体的切换是有代价的。
- 调度成本
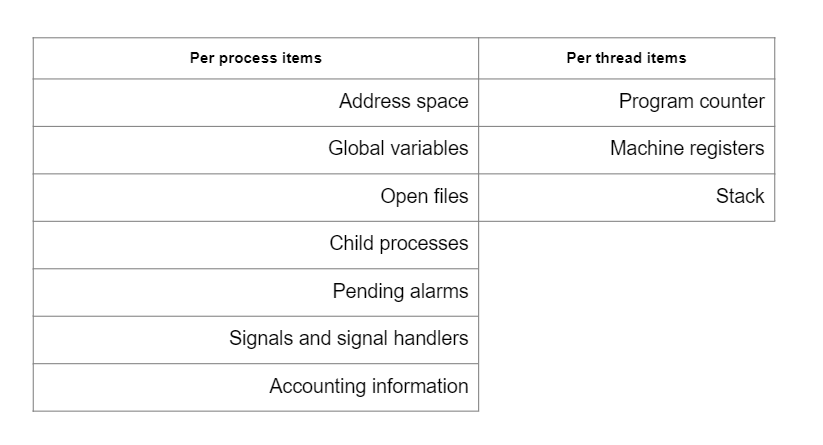
图: 进程和线程的状态变量
因此,使用一个包含多个线程的进程的效率更高,因为进程创建既耗时又耗费资源。但是随后出现了多线程问题:C10k成为主要问题。
例如,如果将调度周期定为10ms(毫秒),并且有2个线程,则每个线程将分别获得5ms。如果您有5个线程,则每个线程将获得2ms。但是,如果有1000个线程怎么办?给每个线程一个10μs(微秒)的时间片?错,这样做很愚蠢,因为您将花费大量时间进行上下文切换,但是真正要完成的工作却进展缓慢或停滞不前。
您需要限制时间片的长度。在最后一种情况下,如果最小时间片为2ms并且有1000个线程,则调度周期需要增加到2s(1000_2ms)。如果有10,000个线程,则调度程序周期为20秒(10000_2ms)。在这个简单的示例中,如果每个线程都将分配给它的时间片用完,那么所有线程都完成一次运行需要20秒。因此,我们需要一些可以使并发成本降低而又不会造成过多开销的东西。
- 用户层线程
- 线程完全由运行时系统(用户级库)管理。
- 理想情况下,快速高效:切换线程的代价不比函数调用多多少。
- 操作系统内核对用户层线程一无所知,并像对待单线程进程(single-threaded process)一样对其进行管理。
在Go中,我们知道这样的用户层线程被称为“Goroutine”。
- Goroutine
图: goroutine vs. 线程
goroutine是由Go运行时管理的轻量级线程(lightweight thread)。要启动一个新的goroutine,只需在函数前面使用go关键字:go add(a, b)。
-
Goroutine之旅
func main() { var wg sync.WaitGroup for i := 0; i <= 10; i++ { wg.Add(1) go func(i int) { defer wg.Done() fmt.Printf(“loop i is - %d\n”, i) }(i) } wg.Wait() fmt.Println(“Hello, Welcome to Go”) }
https://play.golang.org/p/73lESLiva0A
您能猜出上面代码片段的输出吗?
loop i is - 10
loop i is - 0
loop i is - 1
loop i is - 2
loop i is - 3
loop i is - 4
loop i is - 5
loop i is - 6
loop i is - 7
loop i is - 8
loop i is - 9
Hello, Welcome to Go
如果我们看一下输出的一种组合,你可能马上就会有两个问题:
- 11个goroutine如何并行运行?魔法?
- goroutine以什么顺序运行?

图:gopher版奇异博士
上面的这两个提问给我们带来了问题。
- 问题概述
- 如何将这些goroutines分配到在CPU处理器上运行的多个操作系统线程上运行?
- 这些goroutines应该以什么顺序运行才能保证公平?
本文后续的讨论将主要围绕Go运行时调度程序从设计角度如何解决这些问题。但是,与所有问题一样,我们的讨论也需要定义一个明确的边界。否则,问题陈述可能太含糊,无法形成结论。调度程序可能针对多个目标中的一个或多个,对于我们来说,我们将自己限制在以下需求之内:
- 应该是并行、可扩展且公平的。
- 每个进程应可扩展到数百万个goroutine(C10M)
- 内存利用率高。(RAM很便宜,但不是免费的。)
- 系统调用不应导致性能下降。(最大化吞吐量,最小化等待时间)
让我们开始为调度程序建模,以逐步解决这些问题。
二. Goroutine调度程序模型 (译者自行加的标题)
1. 模型概述(译者自行加的标题)
a) 一个线程执行一个Goroutine
局限性:
- 并行和可扩展
- 并行(是的)
- 可扩展(不是真的)
- 每个进程不能扩展到数百万个goroutine(C10M)。
b) M:N线程—混合线程
M个操作系统内核线程执行N个“goroutine”
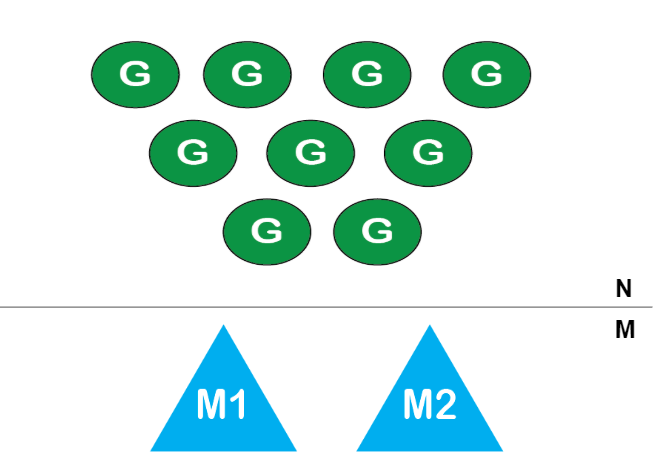
图: M个内核线程执行N个goroutine
实际执行代码和并行执行都需要内核线程。但是线程创建起来很昂贵,因此我们将N个goroutines映射到M个内核线程上去执行。Goroutine是Go代码,因此我们可以完全控制它。而且它在用户空间中,创建起来很便宜。
但是由于操作系统对goroutine一无所知。因此每个goroutine都有一个状态,以帮助调度器根据goroutine状态知道要运行哪个goroutine。与内核线程的状态信息相比,goroutine的状态信息很小,因此goroutine的上下文切换变得非常快。
- 正在运行(Running) – 当前在内核线程上运行的goroutine。
- 可运行(Runnable) – 等待内核线程来运行的goroutine。
- 已阻塞(Blocked) – 等待某些条件的Goroutine(例如,阻塞在channel操作,系统调用,互斥锁上的goroutine)
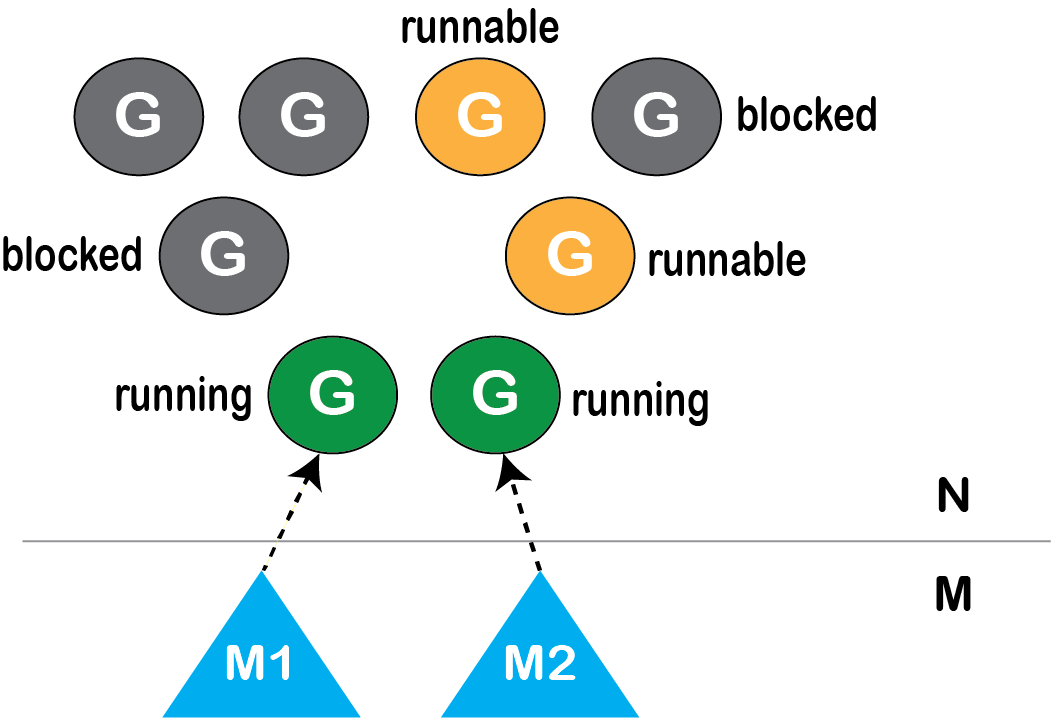
图: 2个线程同时运行2个goroutine
因此,Go运行时调度器通过将N个Goroutine多路复用到M个内核线程的方式来管理处于各种不同状态的goroutines。
2. 简单的M:N调度器
在我们简单的M:N调度器中,我们有一个全局运行队列(global run queue),某些操作将一个新的goroutine放入运行队列。M个内核线程访问调度程序从“运行队列”中获取并运行goroutine。多个线程正在尝试访问相同的内存区域,因此使用互斥锁来同步对该运行队列的访问。
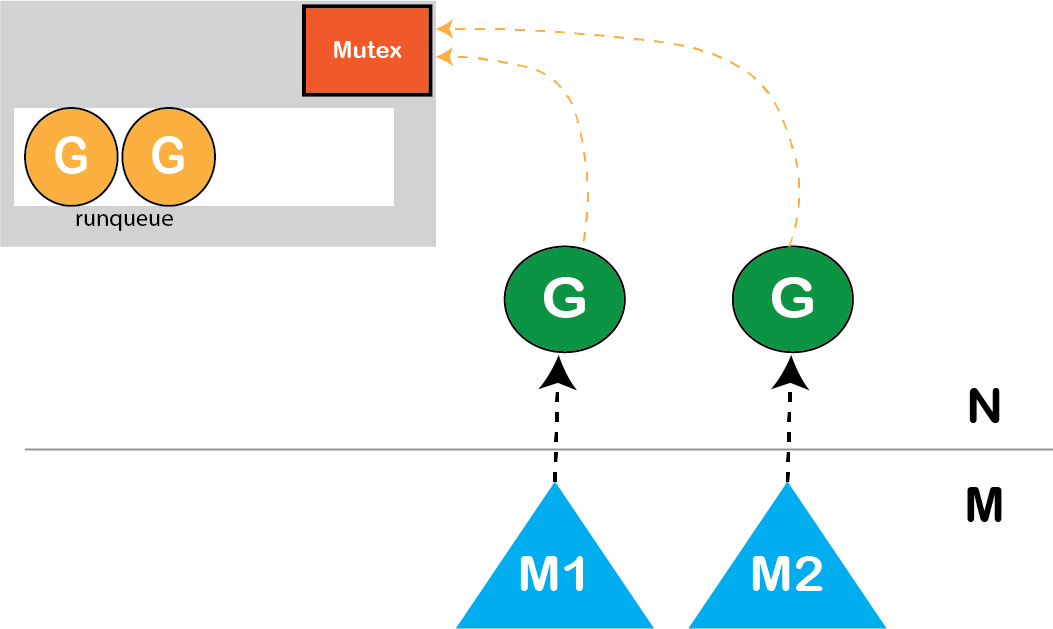
图: 简单的M:N调度器
但是,那些已阻塞的goroutine在哪里?
下面是goroutine可能会阻塞的情况:
- 在channel上发送和接收
- 网络I/O操作
- 阻塞的系统调用
- 使用定时器
- 使用互斥锁
那么我们将这些阻塞的goroutine放在哪里呢?— 将这些阻塞的goroutine放置在哪里的设计决策基本上是围绕一个基本原理进行的:
阻塞的goroutine不应阻塞底层内核线程!(避免线程上下文切换的成本)
channel操作期间阻塞的Goroutine
每个channel都有一个recvq(waitq),用于存储试图从该channel读取数据而阻塞的goroutine。
**Sendq(waitq)**存储试图将数据发送到channel而被阻止的goroutine 。(channel实现原理:-https://codeburst.io/diving-deep-into-the-golang-channels-549fd4ed21a8)
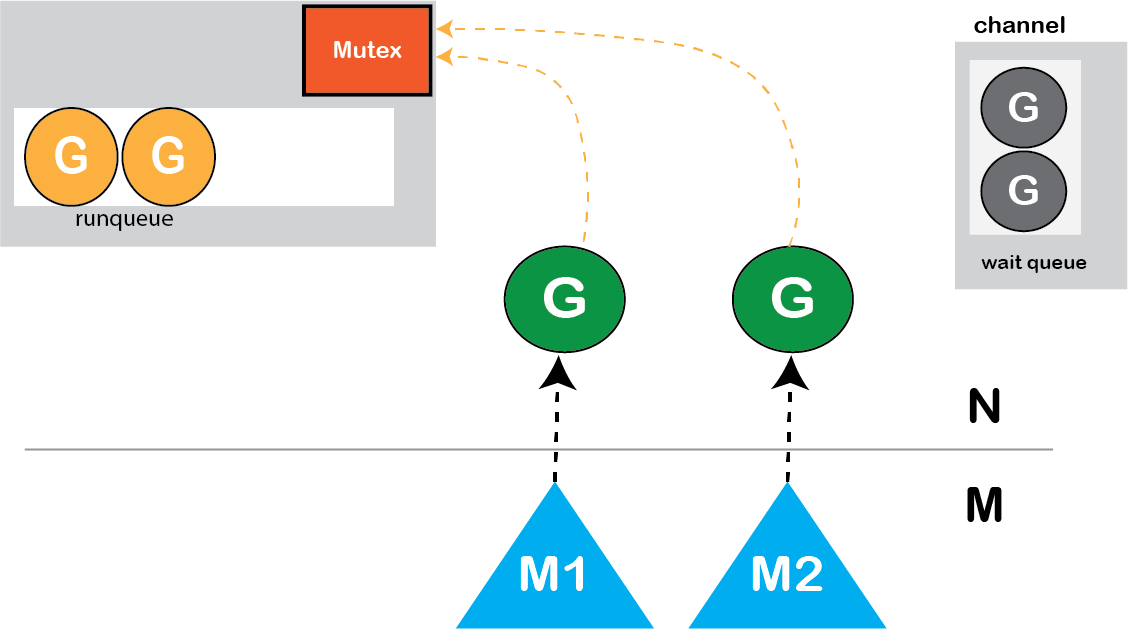
图: channel操作期间阻塞的Goroutine
channel本身会将channel操作后的未阻塞goroutine放入“运行”队列(run queue)。
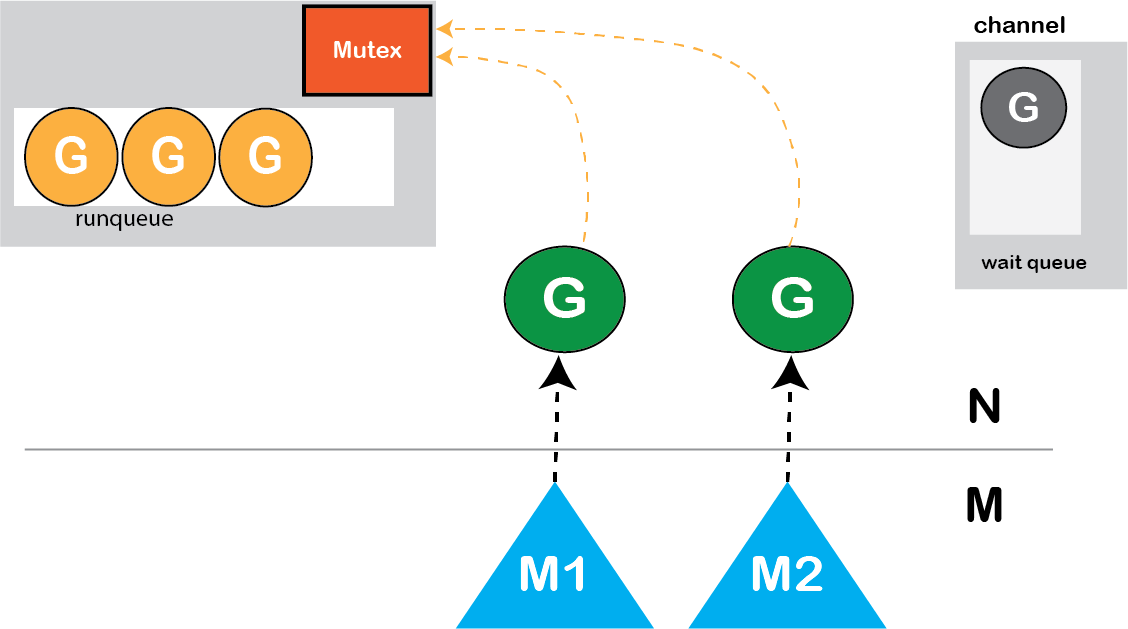
图: channel操作后未阻碍的goroutine
那系统调用呢?
首先,让我们看一下阻塞系统调用。系统调用会阻塞底层内核线程,因此我们无法在该线程上调度任何其他Goroutine。
隐含阻塞系统调用可降低并行度。
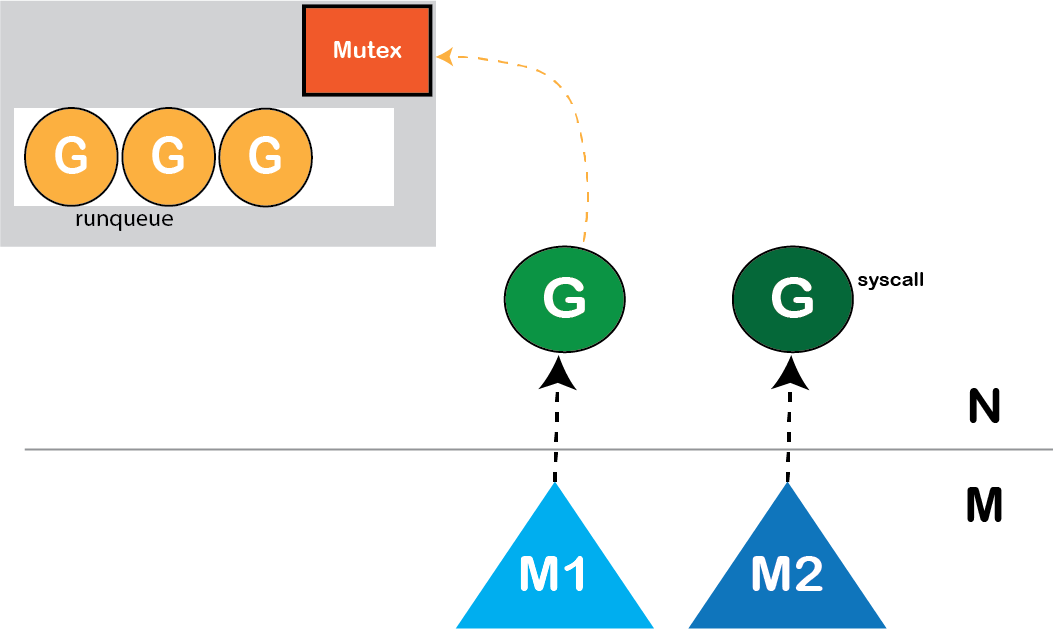
图: 阻塞系统调用可降低并行度
一旦发生阻塞系统调用,我们无法再在M2线程上安排任何其他Goroutine运行,从而导致CPU浪费。由于我们有工作要做,但没法运行它。
恢复并行度的方法是在进入系统调用时,我们可以唤醒另一个线程,该线程将从运行队列中选择可运行的goroutine。
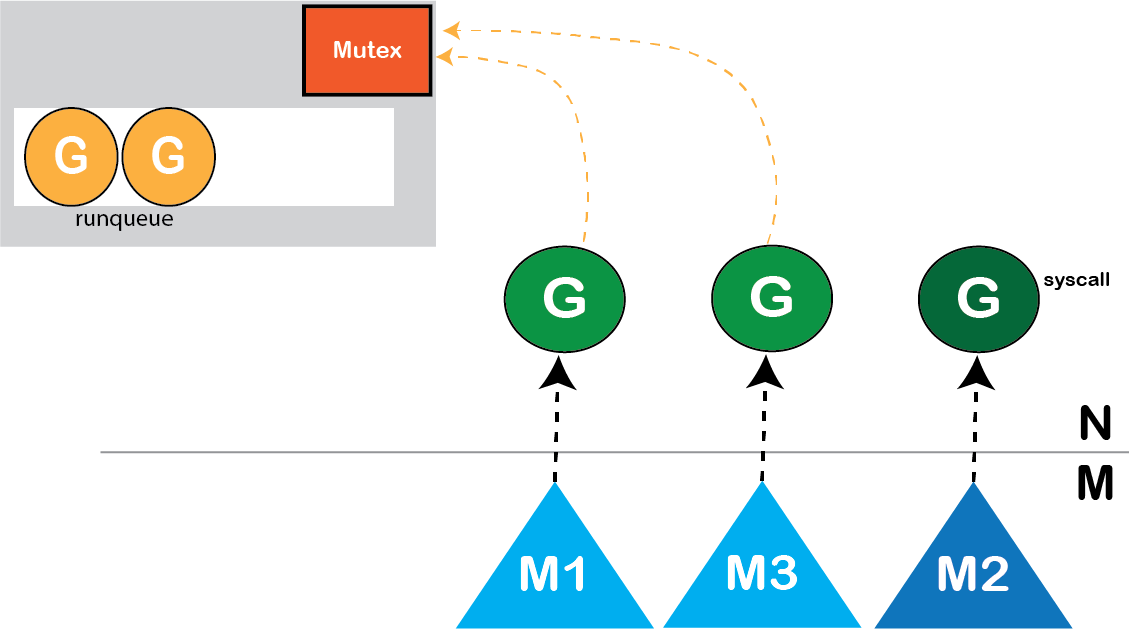
图: 恢复并行度的方法
但是现在,系统调用完成后,我们有超额等待调度的goroutine。因此,我们不会立即运行从阻塞系统调用中返回的goroutine。我们会将其放入调度程序的运行队列中。
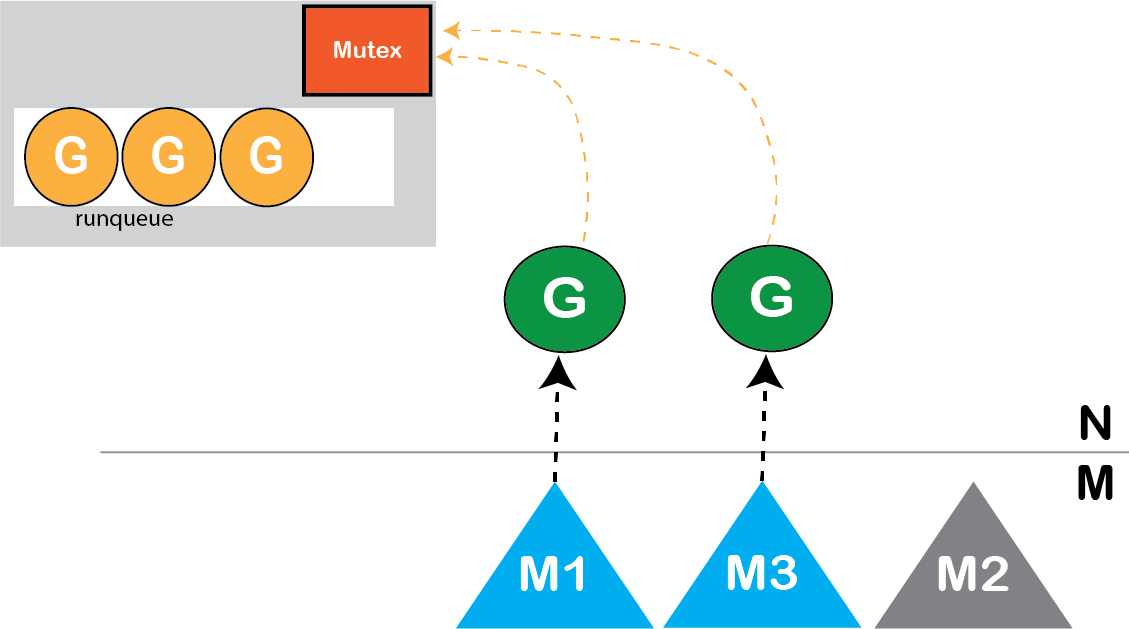
图: 避免超额等待调度
因此,在程序运行时,线程数远大于cpu核数。尽管没有明确说明,线程数大于cpu核数,并且所有空闲线程也由运行时管理,以避免启动过多的线程。
https://golang.org/pkg/runtime/debug/#SetMaxThreads
初始设置为10,000个线程,如果超过10,000个线程,程序将崩溃。
非阻塞系统调用-将goroutine阻塞在Integrated runtime poller上 ,并释放线程以运行另一个goroutine。

例如,在非阻塞I/O(例如HTTP调用)的情况下。由于资源尚未准备就绪,第一个syscall将不会成功,这将迫使Go使用network poller并将goroutine暂停。
部分net.Read函数的实现:
n, err := syscall.Read(fd.Sysfd, p)
if err != nil {
n = 0
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
}
一旦完成第一个系统调用并明确指出资源尚未准备就绪,goroutine将暂停,直到network poller通知它资源已准备就绪。在这种情况下,线程M将不会被阻塞。
Poller将基于操作系统使用select/kqueue/epoll/IOCP等机制来知道哪个文件描述符已准备好,一旦文件描述符准备好进行读取或写入,它将把goroutine放回到运行队列中。
还有一个Sysmon OS线程,如果超过10ms未轮询网络,它就将定期轮询网络,并将已就绪的G添加到队列中。
基本上所有goroutine都被阻塞在下面操作上:
- channel
- 互斥锁
- 网络IO
- 定时器
有某种队列,可以帮助调度这些goroutine。
现在,运行时拥有具有以下功能的调度程序。
- 它可以处理并行执行(多线程)。
- 处理阻塞系统调用和网络I/O。
- 处理阻塞在用户级别(在channel上)的调用。
但这不是可伸缩的(scalable)。
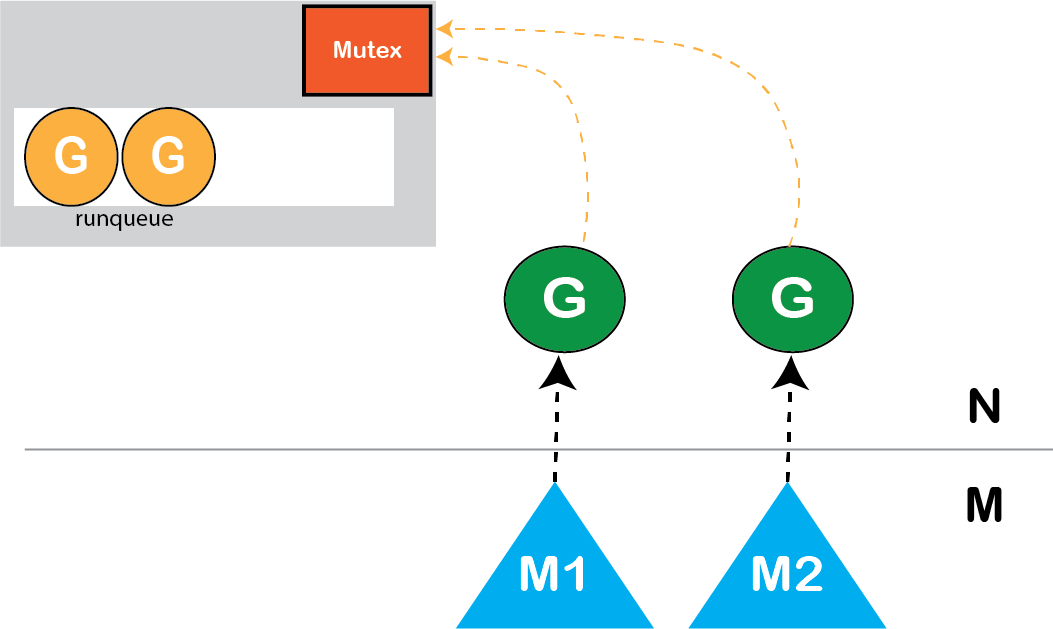
图: 使用Mutex同步全局运行队列
您可以通过Mutex同步全局运行队列,但最终会遇到一些问题,例如
- 缓存一致性保证的开销。
- 在创建,销毁和调度Goroutine G时进行激烈的锁竞争。
使用分布式调度程序解决可伸缩性问题。
分布式调度程序-每个线程一个运行队列
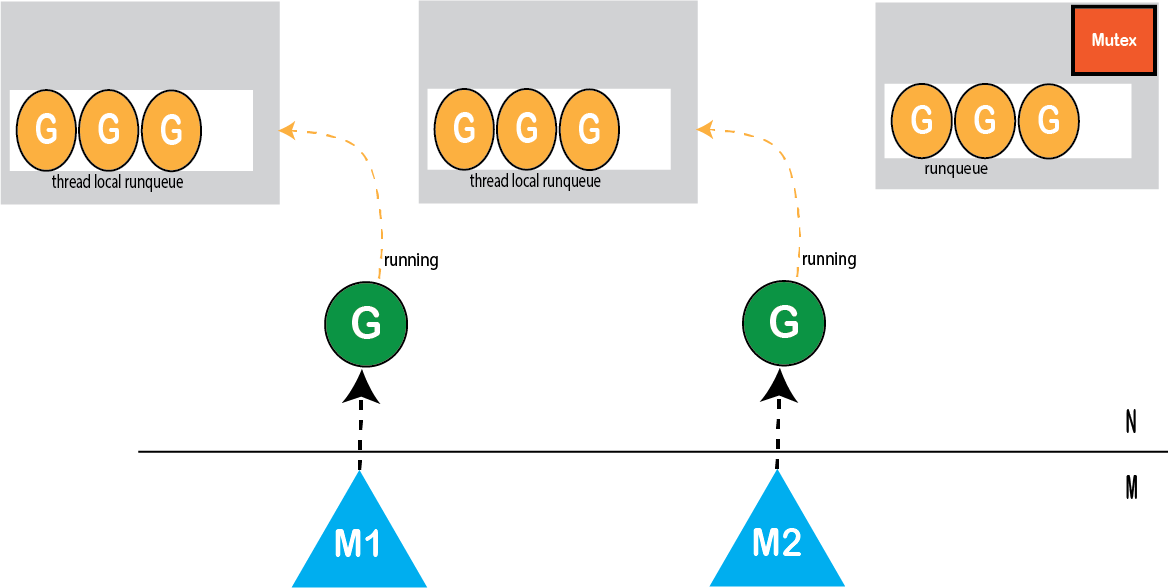
图: 分布式运行队列的调度程序
这样,我们可以看到的直接好处是,每个线程的本地运行队列(local run queue)现在都没有使用mutex。仍然有一个带有mutex的全局运行队列,但仅在特殊情况下使用。它不会影响可伸缩性。
但是现在,我们有多个运行队列。
- 本地运行队列
- 全局运行队列
- 网络轮询器(network poller)
我们应该从哪里运行下一个goroutine?
在Go中,轮询顺序定义如下:
1. 本地运行队列
2. 全局运行队列
3. 网络轮询器
4. 工作偷窃(work stealing)
即首先检查本地运行队列,如果为空则检查全局运行队列,然后检查网络轮询器,最后进行“偷窃工作”。到目前为止,我们对1,2,3有了一些概述。让我们看一下“工作偷窃(work stealing)”。
工作偷窃
如果本地工作队列为空,请尝试“从其他队列中偷窃工作”
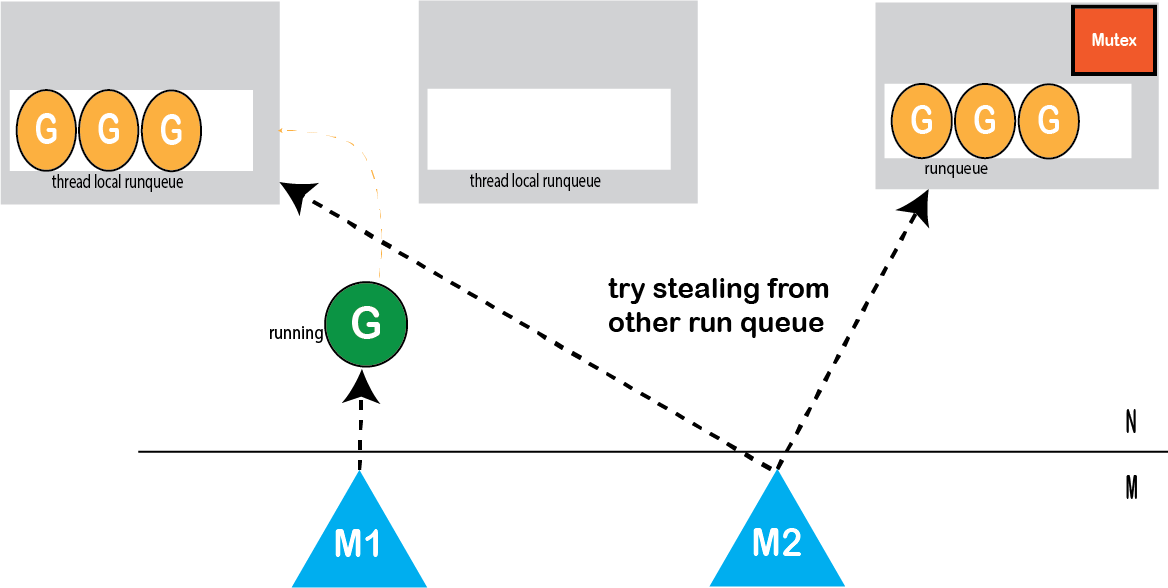
图: 偷窃工作
当一个线程有太多工作要做而另一个线程空闲时,工作偷窃可以解决这个问题。在Go中,如果本地队列为空,工作偷窃将尝试满足以下条件之一。
- 从全局队列中拉取工作。
- 从网络轮询器中拉取工作
- 从其他线程的本地队列中偷窃工作
到目前为止,Go运行时的调度器具有以下功能:
- 它可以处理并行执行(使用多线程)。
- 处理阻塞系统调用和网络I/O。
- 处理用户级别(比如:在channel)的阻塞调用。
- 可伸缩扩展(scalable)
但这仍不是最有效的。
还记得我们在阻塞系统调用中恢复并行度的方式吗?
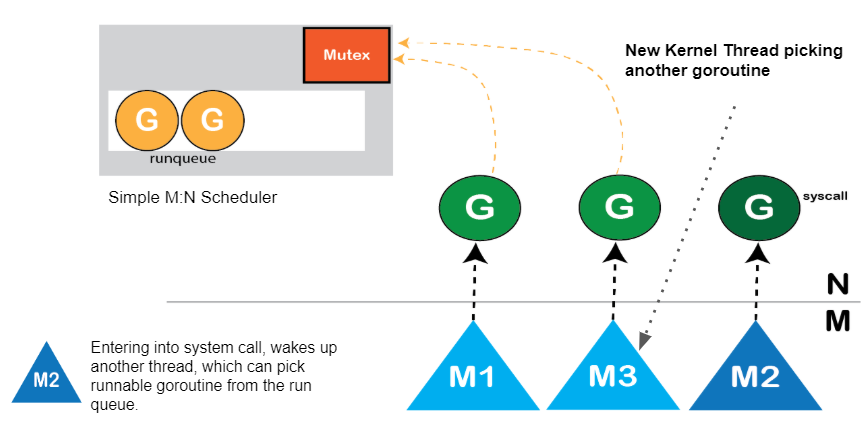
图: 系统调用操作
它暗示在一个系统调用中我们可以有多个内核线程(可以是10或1000),这可能会比cpu核数多很多。这个方案将最终在以下期间产生了恒定的开销:
- 偷窃工作时,它必须同时扫描所有内核线程(空闲的和运行goroutine的)本地运行队列,并且大多数都将是空闲的。
- 垃圾回收,内存分配器都会遇到相同的扫描问题。(https://blog.learngoprogramming.com/a-visual-guide-to-golang-memory-allocator-from-ground-up-e132258453ed)
使用M:P:N线程克服效率问题。
M:P:N(3级调度程序)— 引入逻辑处理器P
P —表示处理器,可以将其视为在线程上运行的本地调度程序
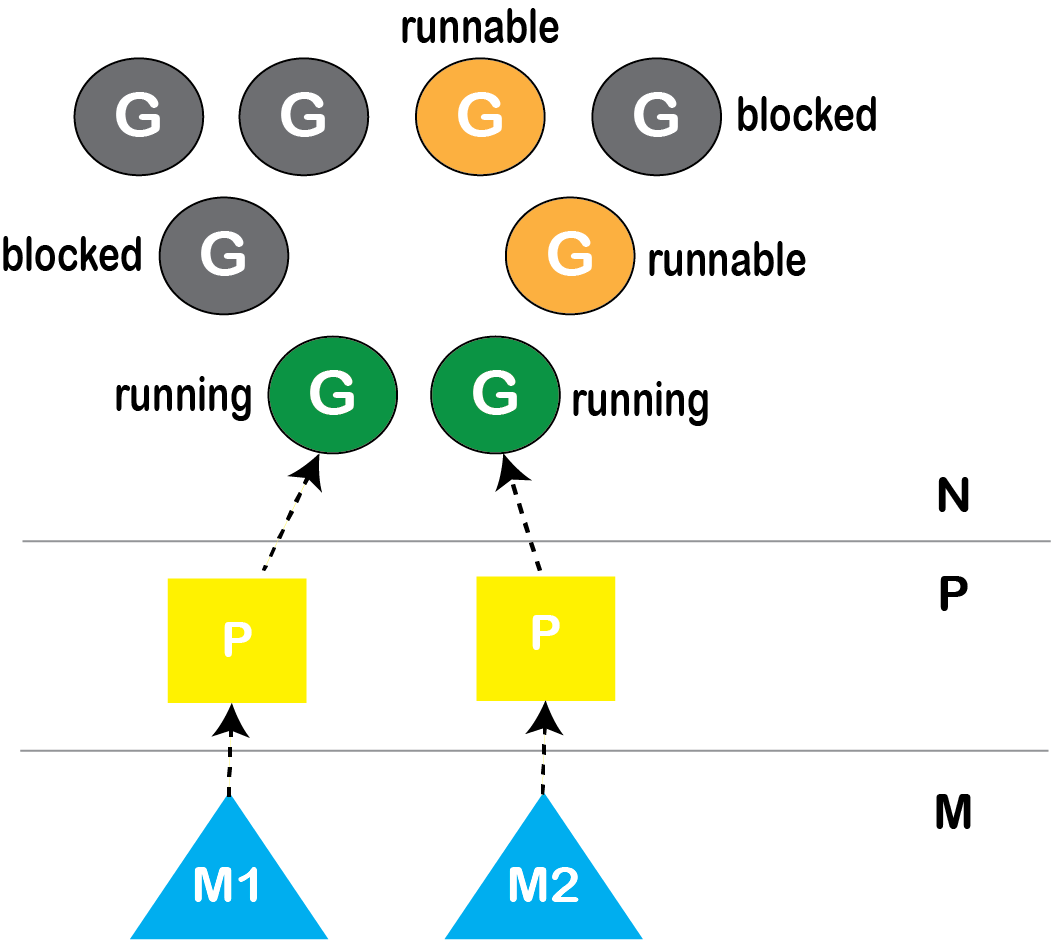
图: M:P:N模型
逻辑进程P的数量始终是固定的。(默认为当前进程可以使用的逻辑CPU数量)
然后,我们将本地运行队列(LRQ)放入固定数量的逻辑处理器(P)中(译者注:而不是每个内核线程一个本地运行队列)。
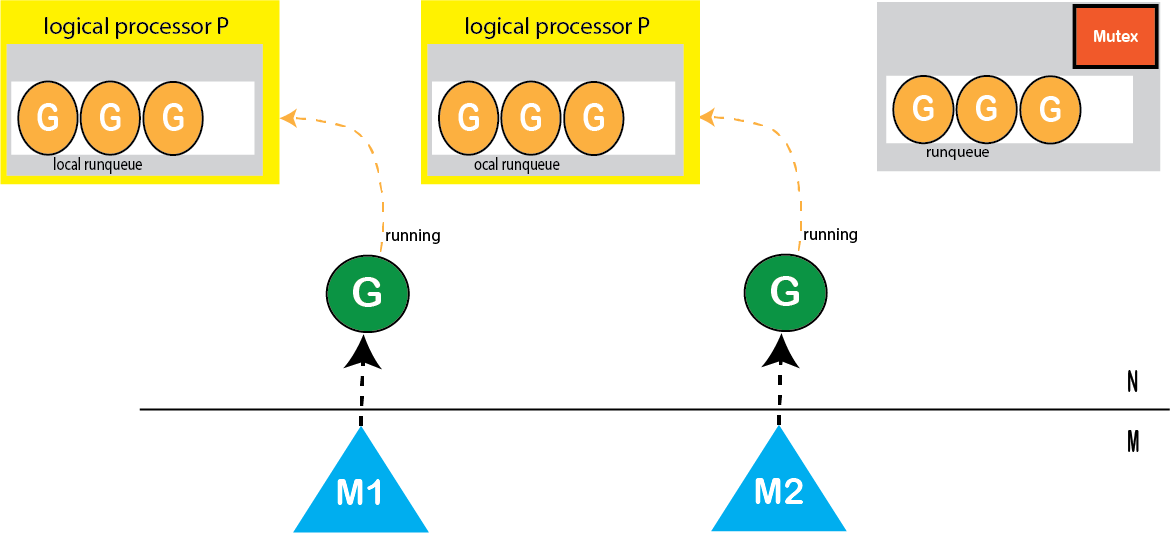
图: 分布式三级运行队列调度程序
Go运行时将首先根据计算机的逻辑CPU数量(或根据请求)创建固定数量的逻辑处理器P。
每个goroutine(G)将在分配了逻辑CPU(P)的OS线程(M)上运行。
所以现在我们在以下期间没有了恒定的开销:
- 偷窃工作 -只需扫描固定数量的逻辑处理器(P)的本地运行队列。
- 垃圾回收,内存分配器也将获得相同的好处。
使用固定逻辑处理器(P)的系统调用呢?
Go通过将它们包装在运行时中来优化系统调用(无论是否阻塞)。
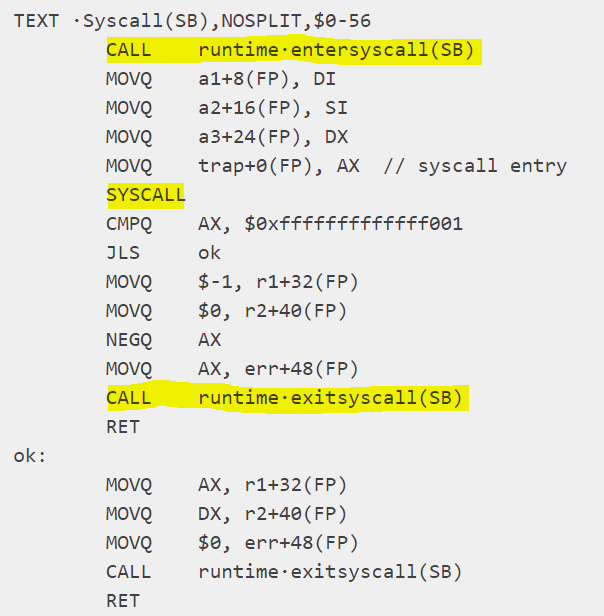
图: 阻塞系统调用的包装器
阻塞SYSCALL方法封装在runtime.entersyscall(SB)和 runtime.exitsyscall(SB)之间。
从字面上看,某些逻辑在进入系统调用之前被执行,而某些逻辑在系统调用返回之后执行。进行阻塞的系统调用时,此包装器将自动将P与线程M(即将执行阻塞系统调用的线程)解绑,并允许另一个线程在其上运行。
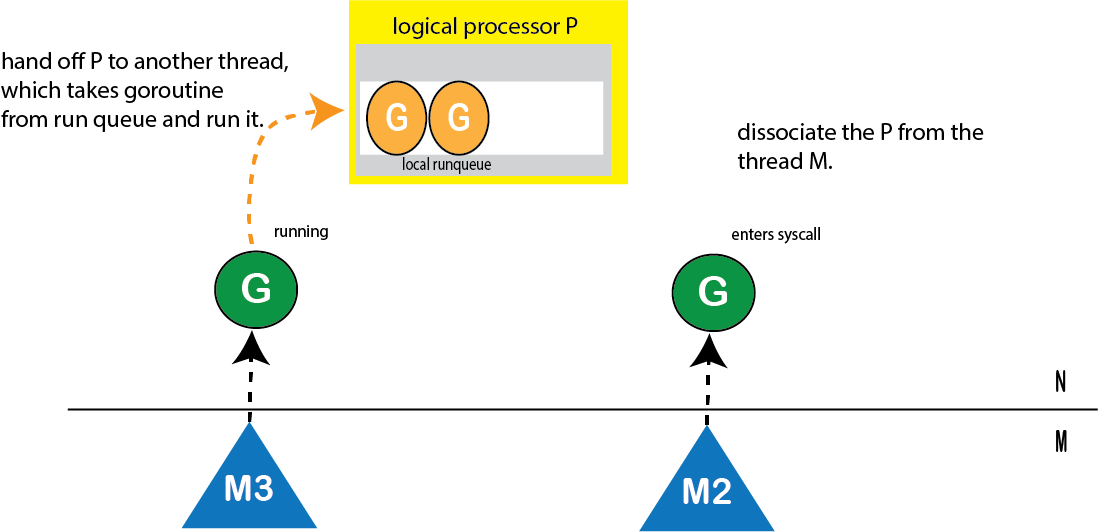
图:阻塞Syscall的M交出P
这使得Go运行时可以高效地处理阻塞的系统调用,而无需增加运行队列(译注:本地运行队列数量始终是和P数量一致的)。
一旦阻塞系统调用返回,会发生什么?
- 运行时会尝试获取之前绑定的那个P,然后继续执行。
- 运行时尝试在P空闲列表中获取一个P并恢复执行。
- 运行时将goroutine放在全局队列中,并将关联的M放回M空闲列表。
自旋线程和空闲线程
当M2线程在syscall返回后变得空闲时。如何处理这个空闲的M2线程。从理论上讲,如果线程完成了所需的操作,则应将其销毁,然后再安排进程中的其他线程到CPU上执行。这就是我们通常所说的操作系统中线程的“抢占式调度”。
考虑上述syscall中的情况。如果我们销毁了M2线程,而同时M3线程即将进入syscall。此时,在OS创建新的内核线程并将其调度执行之前,我们无法处理可运行的goroutine。频繁的线程前抢占操作不仅会增加OS的负载,而且对于性能要求更高的程序几乎是不可接受的。
因此,为了适当地利用操作系统的资源并防止频繁的线程抢占给操作系统带来的负担,我们不会销毁内核线程M2,而是使其执行自旋操作并以备将来使用。尽管这看起来是在浪费一些资源。但是,与线程之间的频繁抢占以及频繁的创建和销毁操作相比,“空闲线程”要付出的代价更少。
Spinning Thread(自旋线程) — 例如,在具有一个内核线程M(1)和一个逻辑处理器(P)的Go程序中,如果正在执行的M被syscall阻塞,则运行时会请求与P数量相同的“Spinning Threads”以允许等待的可运行goroutine继续执行。因此,在此期间,内核线程的数量M将大于P的数量(自旋线程+阻塞线程)。因此,即使将runtime.GOMAXPROCS的值设置为1,程序也将处于多线程状态。
调度中的公平性如何?—公平地选择下一个要执行的goroutine
与许多其他调度程序一样,Go也具有公平性约束,并且由goroutine的实现所强加,因为Runnable goroutine应该最终得到调度并运行。
这是Go Runtime Scheduler的四个典型的公平性约束:
任何运行时间超过10ms的goroutine都被标记为可抢占(软限制)。但是,抢占仅在函数执行开始处才能完成。Go当前在函数开始处中使用了由编译器插入的协作抢占点。
- 无限循环 – 抢占(约10毫秒的时间片)- 软限制
但请小心无限循环,因为Go的调度程序不是抢先的(直到Go 1.13)。如果循环不包含任何抢占点(例如函数调用或分配内存),则它们将阻止其他goroutine的运行。一个简单的例子是:
package main
func main() {
go println("goroutine ran")
for {}
}
如果你运行:
GOMAXPROCS=1 go run main.go
直到Go(1.13)才可能打印该语句。由于缺少抢占点,main Goroutine将独占处理器。
- 本地运行队列 -抢占(〜10ms时间片)- 软限制
- 通过每61次调度就检查一次全局运行队列,可以避免全局运行队列处于“饥饿”状态。
- 网络轮询器饥饿 后台线程会在主工作线程未轮询的情况下偶尔会轮询网络。
有了这种机制,Go运行时便有了具有所有必需功能的Scheduler。
- 它可以处理并行执行(多线程)。
- 处理阻塞系统调用和网络I/O。
- 处理用户级别(在channel上)的阻塞调用。
- 可扩展
- 高效
- 公平
这提供了大量的并发性,并且始终尝试实现最大的利用率和最小的延迟。
现在,我们总体上对Go运行时调度程序有了一些了解,我们如何使用它?Go为我们提供了一个跟踪工具,即调度程序跟踪(scheduler trace),目的是提供有关调度行为的信息并用来调试与goroutine调度器伸缩性相关的问题。
三. 调度器跟踪
使用GODEBUG=schedtrace=DURATION环境变量运行Go程序以启用调度程序跟踪。(DURATION是以毫秒为单位的输出周期。)

图:以100ms粒度对schedtrace输出采样
有关调度器跟踪的内容,Go Wiki拥有更多信息。
参考:Dmitry Vyukov的可扩展Go Scheduler设计文档和演讲 https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit
Gopher艺术作品致谢:Ashley Mcnamara。
我的网课“Kubernetes实战:高可用集群搭建、配置、运维与应用”在慕课网上线了,感谢小伙伴们学习支持!
我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/
smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
微博:https://weibo.com/bigwhite20xx
微信公众号:iamtonybai
博客:tonybai.com
github: https://github.com/bigwhite
微信赞赏:

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。