上周六开源中国的源创会在沈阳举办了一次技术活动,很荣幸以本地讲师的身份和大家交流了一个topic: “基于Harbor的高可用企业级私有容器镜像仓库部署实践”。之所以选择这个topic,是因为这是我们团队的项目实践心得。很多企业和组织在深入使用Docker之后,都会有类似的高可用私有容器仓库搭建的需求,于是我就把我们摸索的实践和填坑过程拿出来,用30分钟与大家分享一下。另外这算是一个入门级的分享,并未深入过多原理。以下就是本次分享的内容讲稿整理。如有不妥或不正确的地方,欢迎交流指正。

大家下午好,欢迎各位来到源创会沈阳站。在这里我也代表沈阳的IT人欢迎源创会来到沈阳,希望能有更多的像源创会这样的组织到沈阳举办技术活动。非常高兴能有这个机会在源创会这个平台上做分享, 今天和大家一起探讨的题目是:“基于Harbor的高可用企业级私有容器镜像仓库部署实践”。题目有些长,简单来说就是如何搭建一个好用的镜像仓库。

首先做个简单的自我介绍。我叫白明,东软(注:源创会这次活动的会场在东软沈阳园区)是我的主场,在这里工作很多年,目前就职东软云科技;Gopher一枚,近两年主要使用Go语言开发;技术译者,曾参与翻译过《七周七语言》一书;并且参与过智慧城市架构系列丛书的编著工作;GopherChina大会讲师,这里顺便说一下GopherChina大会,它是目前中国地区规模最大、水平最高的Go语言技术大会,一般每年4月份在北京或上海举行。希望有志于Go语言开发的开发者积极参与;Blogger,写博10多年,依旧笔耕不倦;目前主要从事Docker&kubernetes的研究和实践。
当今,IT技术发展飞快。五年前, IT从业者口中谈论最多的技术是Virtual Machine,即虚拟化技术,人们经常争论的是到底是vmware的技术好,还是原生kvm技术稳定,又或是xen的技术完美。转眼间五年过去了,大家口中经常讨论的技术词汇发生了变化,越来越多的技术人在谈论Docker,谈论容器。
Docker是什么? Docker这门技术非常热,但我们要透过现象看其本质:
Docker技术并不是新技术,而是将已有技术进行了更好的整合和包装。
内核容器技术以一种完整形态最早出现在Sun公司的Solaris操作系统上,Solaris是当时最先进的服务器操作系统。2005年Solaris发布Solaris Container技术,从此开启了内核容器之门。
IT技术发展的趋势就是这样:商业有的,开源也要有。三年后,即2008年,以Google公司开发人员为主导的Linux Container,LXC功能在被merge到Linux内核。LXC是一种内核级虚拟化技术,主要基于namespaces和cgroup技术,实现共享一个os kernel前提下的进程资源隔离,为进程提供独立的虚拟执行环境,这样的一个虚拟的执行环境就是一个容器。本质上说,LXC容器与现在的Docker所提供容器是一样的。但是,当时LXC处于早期阶段,开发人员可能更为关注LXC的技术实现,而对开发体验方面有所忽略,导致LXC技术使用门槛较高,普通应用开发者学习、理解和使用它的心智负担较高,因此应用并不广泛。
这一情况一直持续到2013年,当时美国一家名不见经传的公司dotCloud发布了一款平台工具Docker,对外宣称可以实现:“build,ship and run any app and anywhere”。Docker实质上也是基于namespaces和cgroup技术的,Docker的创新之处在于其基于union fs技术定义了一套应用打包规范,真正将应用及其运行的所有依赖都封装到一个特定格式的文件中,这种文件就被称为image,即镜像文件。同时,Docker还提供了一套抽象层次更高的工具集,这套工具对dev十分友好,具有良好的开发体验(Developer eXperience),开发者无需关心namespace, cgroups之类底层技术,即可很easy的启动一个承载着其应用的容器:
Docker run ubuntu echo hello
因此, 从2013发布以来,Docker项目就像坐上了火箭,发展迅猛,目前已经是github上最火爆的开源项目之一。这里还要提一点就是:Docker项目是使用go语言开发的,Docker项目的成功,也或多或少得益于Go优异的开发效率和执行效率。
Docker技术的出现究竟给我们带来了哪些好处呢,个人觉得至少有以下三点:
- 交付标准化:Docker使得应用程序和依赖的运行环境真正绑定结合为一体,得之即用。这让开发人员、测试和运维实现了围绕同一交付物,保持开发交付上下文同步的能力,即“test what you write, ship what you test”;
- 执行高效化:应用的启动速度从原先虚拟机的分钟级缩短到容器的秒级甚至ms级,使得应用可以支持快速scaling伸缩;
- 资源集约化:与vm不同的是,Container共享一个内核,这使得一个container的资源消耗仅为进程级别或进程组级别。同时,容器的镜像也因为如此,其size可以实现的很小,最小可能不足1k,平均几十M。与vm动辄几百兆的庞大身段相比,具有较大优势。
有了image文件后,自然而言我们就有了对image进行存取和管理的需求,即我们需要一个镜像仓库,于是Docker推出了Docker registry这个项目。Docker Registry就是Docker image的仓库,用来存储、管理和分发image的;Docker registry由Docker公司实现,项目名为distribution,其实现了Docker Registr 2.0协议,与早前的Registry 1.x协议版本相比,Distribution采用Go语言替换了Python,在安全性和性能方面都有了大幅提升;Docker官方运行着一个世界最大的公共镜像仓库:hub.docker.com,最常用的image都在hub上,比如反向代理nginx、redis、ubuntu等。鉴于国内访问hub网速不佳,多使用国内容器服务厂商提供的加速器。Docker官方还将Registry本身打入到了一个image中,方便开发人员快速以容器形式启动一个Registry:
docker run -d -p 5000:5000 --restart=always --name registry registry:2
不过,这样启动的Registry更多仅仅是一个Demo级别或满足个体开发者自身需要的,离满足企业内部开发流程或生产需求还差了许多。
既然Docker官方运行着免费的镜像仓库,那我们还需要自己搭建吗?实际情况是,对Docker的使用越深入,对私有仓库的需求可能就越迫切。我们先来看一组Docker 2016官方的调查数据,看看Docker都应用在哪些场合。 从Docker 2016官方调查来看,Docker 更多用于dev、ci和DevOps等环节,这三个场合下的应用占据了半壁江山。而相比于公共仓库,私有镜像仓库能更好的满足开发人员在这些场合对镜像仓库的需求。理由至少有四点:
-
便于集成到内部CI/Cd
以我司内部为例,由于公司内部办公需要使用正向代理访问外部网络,要想将Public Registry集成到你的内部CI中,技术上就会有很多坎儿,整个搭建过程可能是非常痛苦的; -
对镜像可以更全面掌控
一般来说,外部Public Registry提供的管理功能相对单一,往往无法满足企业内部的开发和交付需求; -
内部网络,网络传输性能更好
内部开发运维流水线很多环节是有一定的时间敏感性的,比如:一次CI如果因为network问题导致image pull总是timeout,会让dev非常闹心,甚至影响整体的开发和交付效率。 -
出于安全考虑
总是有企业不想将自己开发的软件或数据放到公网上,因此在企业内部选择搭建一个private registry更会让这些企业得到满足;另外企业对仓库的身份验证可能还有LDAP支持的需求,这是外部registry无法满足的。
一旦企业决定搭建自己的private仓库,那么就得做一个private仓库的技术选型。商业版不在我们讨论范围内,我们从开源软件中挑选。不过开源的可选的不多,Docker 官方的Registry更聚焦通用功能,没有针对企业客户需求定制,开源领域我们大致有两个主要候选者:SUSE的Portus和Vmware的Harbor。针对开源项目的技术选型,我个人的挑选原则最简单的就是看社区生态,落实到具体的指标上包括:
- 项目关注度(即star数量)
- 社区对issue的反馈数量和积极性
- 项目维护者对issue fix的积极程度以及是否有远大的roadmap
对比后,我发现在这三个指标上,目前Harbor都暂时领先portus一段距离,于是我们选择Harbor。
Harbor是VMware中国团队开源的企业级镜像仓库项目,聚焦镜像仓库的企业级需求,这里从其官网摘录一些特性,大家一起来看一下:
– 支持基于角色的访问控制RBAC;
– 支持镜像复制策略(PUSH);
– 支持无用镜像数据的自动回收和删除; – 支持LDAP/AD认证;
– Web UI;
– 提供审计日志功能;
– 提供RESTful API,便于扩展;
– 支持中文&部署Easy。
不过,Harbor默认安装的是单实例仓库,并非是高可用的。对于接纳和使用Docker的企业来说,镜像仓库已经企业内部开发、交付和运维流水线的核心,一旦仓库停掉,流水线将被迫暂停,对开发交付的效率会产生重要影响;对于一些中大型企业组织,单实例的仓库性能也无法满足需求,为此高可用的Harbor势在必行。在设计Harbor HA方案之前,我们简单了解一下Harbor组成架构。
一个Harbor实例就是一组由docker-compose工具启动的容器服务,主要包括四个主要组件:
-
proxy
实质就是一个反向代理nginx,负责流量路由分担到ui和registry上; -
registry
这里的registry就是原生的docker官方的registry镜像仓库,Harbor在内部内置了一个仓库,所有仓库的核心功能均是由registry完成的; -
core service
包含了ui、token和webhook服务; -
job service
主要用于镜像复制供。
同时,每个Harbor实例还启动了一个MySQL数据库容器,用于保存自身的配置和镜像管理相关的关系数据。
高可用系统一般考虑三方面:计算高可用、存储高可用和网络高可用。在这里我们不考虑网络高可用。基于Harbor的高可用仓库方案,这里列出两个。
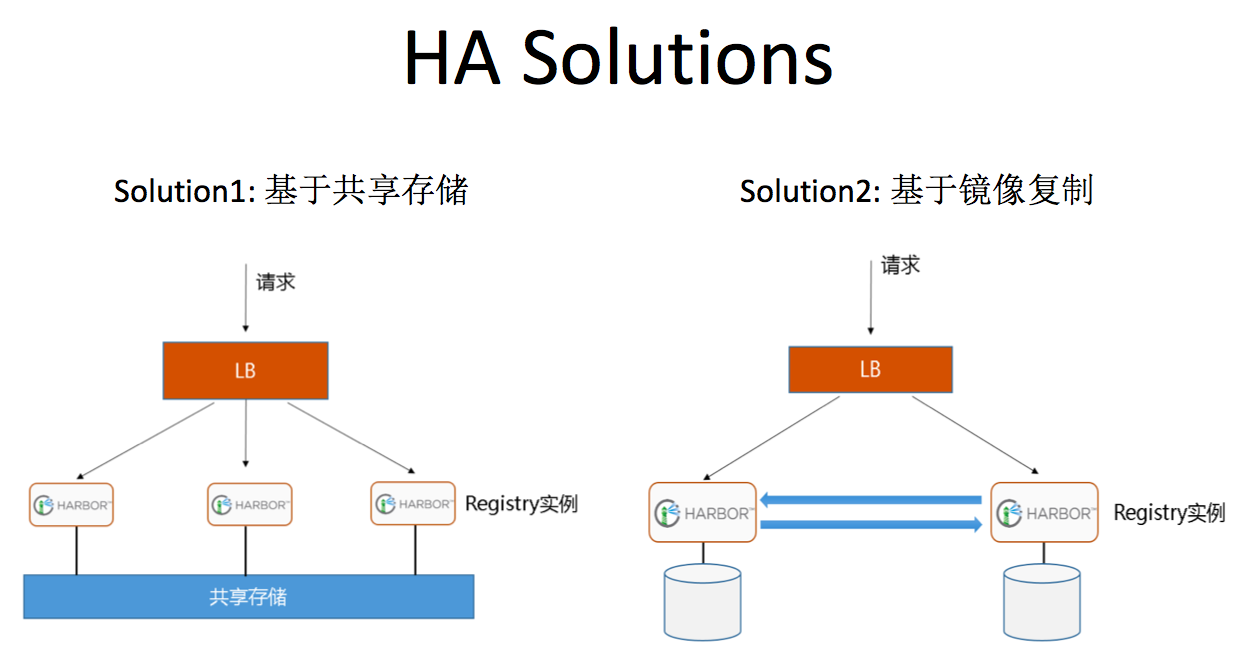
两个方案的共同点是计算高可用,都是通过lb实现的多主热运行,保证无单点;存储高可用则各有各的方案。一个使用了分布式共享存储,数据可靠性由共享存储provider提供;另外一个则需要harbor自身逻辑参与,通过镜像相互复制的方式保持数据的多副本。
两种方案各有优缺点,就看哪种更适合你的组织以及你手里的资源是否能满足方案的搭建要求。
方案1是Harbor开发团队推荐的标准方案,由于基于分布式共享存储,因此其scaling非常好;同样,由于多Harbor实例共享存储,因此可以保持数据是实时一致的。方案1的不足也是很明显的,第一:门槛高,需要具备共享存储provider;第二搭建难度要高于第二个基于镜像复制的方案。
方案2的优点就是首次搭建简单。不足也很多:scaling差,甚至是不能,一旦有三个或三个以上节点,可能就会出现“环形复制”;镜像复制需要时间,因此存在多节点上数据周期性不一致的情况;Harbor的镜像复制规则以Project为单位配置,因此一旦新增Project,需要在每个节点上手工维护复制规则,非常繁琐。因此,我们选择方案1。
我们来看一下方案1的细节: 这是一幅示意图。
- 每个安放harbor实例的node都mount cephfs。ceph是目前最流行的分布式共享存储方案之一;
- 每个node上的harbor实例(包含组件:ui、registry等)都volume mount node上的cephfs mount路径;
- 通过Load Balance将request流量负载到各个harbor实例上;
- 使用外部MySQL cluster替代每个Harbor实例内部自维护的那个MySQL容器;对于MySQL cluster,可以使用mysql galera cluster或MySQL5.7以上版本自带的Group Replication (MGR) 集群。
- 通过外部Redis实现访问Harbor ui的session共享,这个功能是Harbor UI底层MVC框架-beego提供的。
接下来,我们就来看具体的部署步骤和细节。
环境和先决条件:
- 三台VM(Ubuntu 16.04及以上版本);
- CephFS、MySQL、Redis已就绪;
- Harbor v1.1.0及以上版本;
- 一个域名:hub.tonybai.com:8070。我们通过该域名和服务端口访问Harbor,我们可以通过dns解析多ip轮询实现最简单的Load balance,虽然不完美。
第一步:挂载cephfs
每个安装Harbor instance的节点都要mount cephfs的相关路径,步骤包括:
#安装cephfs内核驱动
apt install ceph-fs-common
# 修改/etc/fstab,添加挂载指令,保证节点重启依旧可以自动挂载cephfs
xx.xx.xx.xx:6789:/apps/harbor /mnt/cephfs/harbor ceph name=harbor,secretfile=/etc/ceph/a dmin.secret,noatime,_netdev 0 2
这里涉及一个密钥文件admin.secret,这个secret文件可以在ceph集群机器上使用ceph auth tool生成。
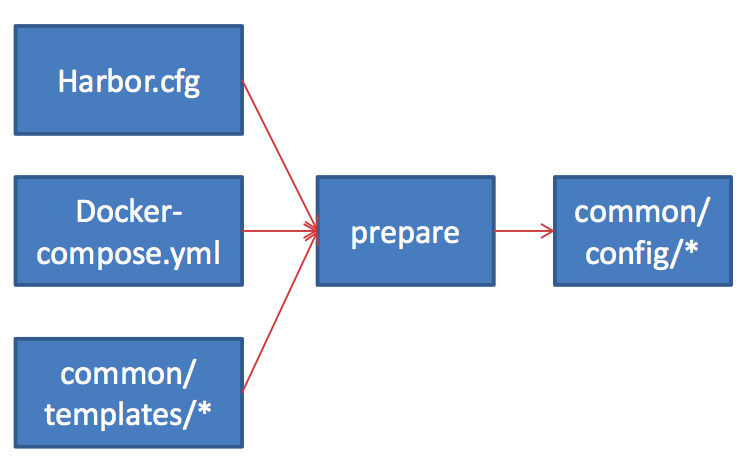
前面提到过每个Harbor实例都是一组容器服务,这组容器启动所需的配置文件是在Harbor正式启动前由prepare脚本生成的,Prepare脚本生成过程的输入包括:harbor.cfg、docker-compose.yml和common/templates下的配置模板文件。这也是部署高可用Harbor的核心步骤,我们逐一来看。
第二步:修改harbor.cfg
我们使用域名访问Harbor,因此我们需要修改hostname配置项。注意如果要用域名访问,这里一定填写域名,否则如果这里使用的是Harbor node的IP,那么在后续会存在client端和server端仓库地址不一致的情况;
custom_crt=false 关闭 crt生成功能。注意:三个node关闭其中两个,留一个生成一套数字证书和私钥。
第三步:修改docker-compose.yml
docker-compose.yml是docker-compose工具标准配置文件,用于配置docker-compose即将启动的容器服务。针对该配置文件,我们主要做三点修改:
- 修改volumes路径
由/data/xxx 改为:/mnt/cephfs/harbor/data/xxx - 由于使用外部Mysql,因此需要删除mysql service以及其他 service对mysql service的依赖 (depends_on)
- 修改对proxy外服务端口 ports: 8070:80
第四步:配置访问external mysql和redis
external mysql的配置在common/templates/adminserver/env中,我们用external Mysql的访问方式覆盖下面四项配置:
MYSQL_HOST=harbor_host
MYSQL_PORT=3306
MYSQL_USR=harbor
MYSQL_PWD=harbor_password
还有一个关键配置,那就是将RESET由false改为true。只有改为true,adminserver启动时,才能读取更新后的配置:
RESET=true
Redis连接的配置在common/templates/ui/env中,我们需要新增一行:
_REDIS_URL=redis_ip:6379,100,password,0
第五步:prepare并启动harbor
执行prepare脚本生成harbor各容器服务的配置;在每个Harbor node上通过下面命令启动harbor实例:
docker-compose up -d
启动后,可以通过docker-compose ps命令查看harbor实例中各容器的启动状态。如果启动顺利,都是”Up”状态,那么我们可以在浏览器里输入:http://hub.tonybai.com:8070,不出意外的话,我们就可以看到Harbor ui的登录页面了。
至此,我们的高可用Harbor cluster搭建过程就告一段落了。
Troubleshooting
不过,对Harbor的认知还未结束,我们在后续使用Harbor的过程中遇到了一些问题,这里举两个例子。
问题1: docker login hub.tonybai.com:8070 failed
现象日志:
Error response from daemon: Get https://hub.tonybai.com:8070/v1/users/: http: server gave HTTP response to HTTPS client
通过错误日志分析应该是docker daemon与镜像仓库所用协议不一致导致。docker engine默认采用https协议访问仓库,但之前我们搭建的Harbor采用的是http协议提供服务,两者不一致。
解决方法有两种,这里列出第一种:让docker引擎通过http方式访问harbor仓库:
在/etc/docker/daemon.json中添加insecure-registry:
{
"insecure-registries": ["hub.tonybai.com:8070"]
}
重启docker service生效
第二种方法就是让Harbor支持https,需要为harbor的proxy配置私钥和证书,位置:harbor.cfg中
#The path of cert and key files for nginx, they are applied only the protocol is set to https
ssl_cert = /data/cert/server.crt
ssl_cert_key = /data/cert/server.key
这里就不细说了。
问题2:docker login hub.tonybai.com:8070 有时成功,有时failed
现象日志:
第一次登录成功:
# docker login -u user -p passwd http://hub.tonybai.com:8070 Login Succeeded
第二次登录失败:
# docker login -u user -p passwd http://hub.tonybai.com:8070
Error response from daemon: login attempt to http://hub.tonybai.com:8070/v2/ failed with status: 401 Unauthorized
这个问题的原因在于对docker registry v2协议登录过程理解不够透彻。docker registry v2是一个两阶段登录的过程:
- 首先:docker client会到registry去尝试登录,registry发现request中没有携带token,则返回失败应答401,并告诉客户端到哪里去获取token;
- 客户端收到应答后,获取应答中携带的token service地址,然后到harbor的core services中的token service那里获取token(使用user, password进行校验)。一旦token service校验ok,则会使用private_key.pem生成一个token;
- 客户端拿到token后,再次到registry那里去登录,这次registry用root.crt去校验客户端携带的token,校验通过,则login成功。
由于我们是一个harbor cluster,如果docker client访问的token service和registry是在一个harbor实例中的,那么login就会ok;否则docker client就会用harbor node1上token service生成的token到harbor node2上的registry去登录,由于harbor node2上root.crt与harbor node1上private_key.pem并非一对,因此登录失败。
解决方法:将所有节点上使用同一套root.crt和private_key.pem。即将一个harbor node(harbor.cfg中custom_crt=true的那个)上的 common/config/ui/private_key.pem和 common/config/registry/root.crt复制到其他harbor node;然后重建各harbor实例中的容器。
至此,我们的高可用Harbor仓库部署完了。针对上面的配置过程,我还做了几个录屏文件,由于时间关系,这里不能播放了,大家可以在下面这个连接下载并自行播放收看。
Harbor install 录屏: https://pan.baidu.com/s/1o8JYKEe
谢谢大家!
讲稿slide可以在这里获取到。
微博:@tonybai_cn
微信公众号:iamtonybai
github.com: https://github.com/bigwhite