
本文永久链接 – https://tonybai.com/2023/06/13/understand-go-gc-overhead-behind-the-convenience
注:本文部分摘录自GopherChina 2023前的《Go高级工程师训练营》课程。
1. 简介
当今,移动互联网和人工智能的快(越)速(来)发(越)展(卷),对编程语言的高效性和便利性提出了更高的要求。Go作为一门高效、简洁、易于学习的编程语言,受到了越来越多开发者的青睐。
Go语言的垃圾回收机制(Garbage Collection,简称 GC)是其重要的运行机制之一,它可以帮助开发人员避免手动管理内存的复杂性和错误,为开发者带来开发上的便利,使开发者可以更专注于业务逻辑的实现。然而,GC的便利性背后也带来了一定的系统开销,作为成熟的Go开发者,我们需要了解GC带来的开销和优化方法,以帮助我们更好的了解和使用Go语言。
了解Go GC的原理是了解GC开销的前提条件,我们首先来简要看看Go GC的原理。
2. Go GC的简明原理
Go语言的垃圾回收器采用了并发三色标记清除算法(Concurrent Tri-Color Mark-And-Sweep),尽可能减少STW(stop the world)时间,以降低吞吐为代价换取低延迟,实现了高效的垃圾回收。
标记清除算法的基本原理是,垃圾回收器将所有的存活对象标记为“活”的,未被标记的对象则被认为是垃圾。经典的标记清除算法通常分为两个阶段:
- 标记阶段:垃圾回收器从根对象开始,遍历所有可达对象,并将它们标记为“活”的。
- 清除阶段:垃圾回收器从堆的起始地址开始遍历,将未被标记的对象清除,回收内存。
Go语言的垃圾回收器采用了三色标记法(Tri-Color Marking),将堆上的内存对象分为三种颜色:
- 白色:未被标记为“活”的对象,是潜在的垃圾,后续可能会被GC回收。
- 灰色:待扫描的对象,当扫描某个灰色对象时,GC会将其标记为黑色,然后将该对象指向的所有对象都标记为灰色,待后续标记。
- 黑色:被标记为“活”的对象,在这轮GC中不会被回收。
垃圾回收器开始工作时不存在黑色对象,垃圾回收器会将根对象标记为灰色,并从根对象(通常是栈对象和全局对象)开始遍历。垃圾回收器会将灰色对象标记为黑色,并将该对象指向的对象标记为灰色。垃圾回收器重复这个过程,直到所有可达对象都被标记为黑色。最后,垃圾回收器清除所有未被标记为黑色的对象,即清除所有白色对象。
前面提到过,Go语言的GC采用了并发标记的技术,以减少GC对系统性能的影响。并发标记指的是在GC运行时程序仍然可以继续运行,而不必停止程序的执行。为了避免程序修改对象时对标记的影响,GC会利用混合写屏障技术,在对象被修改时进行特殊标记(若程序修改黑色对象(已被扫描完毕,不会再扫描),使之指向白色对象时,写屏障技术会将白色对象标记为灰色,避免白色对象被释放导致黑色对象出现悬挂指针的情况)。写屏障技术可以有效避免并发标记阶段的错误标记,但也会带来一定的性能开销。
3. GC的开销
从上面的Go GC原理来看,GC在带来便利的同时,开销是不可避免的。
3.1 GC开销的主要来源
GC开销的主要来源包括以下几个:
- STW时间
Go诞生初期,GC的实现不是很成熟,STW时间很长,这让很对想使用Go在生产上作为一番的开发人员打了“退堂鼓”。Go 1.5版本自举后,GC的STW时间大幅下降,又经过几个版本的打磨后,STW时间已经被Go降低到很短了,通常情况下都在1毫秒以内,甚至可以到几十微秒,STW时间的大幅缩短让Go真正走进了生产环境。
不过再短的STW对于程序执行来说也是开销,因为STW期间,所有属于业务逻辑的代码都无法向前推进(make progress)。
那么一个GC周期究竟会做几次STW呢?这里借用“Go语言原本”中的一个表格:
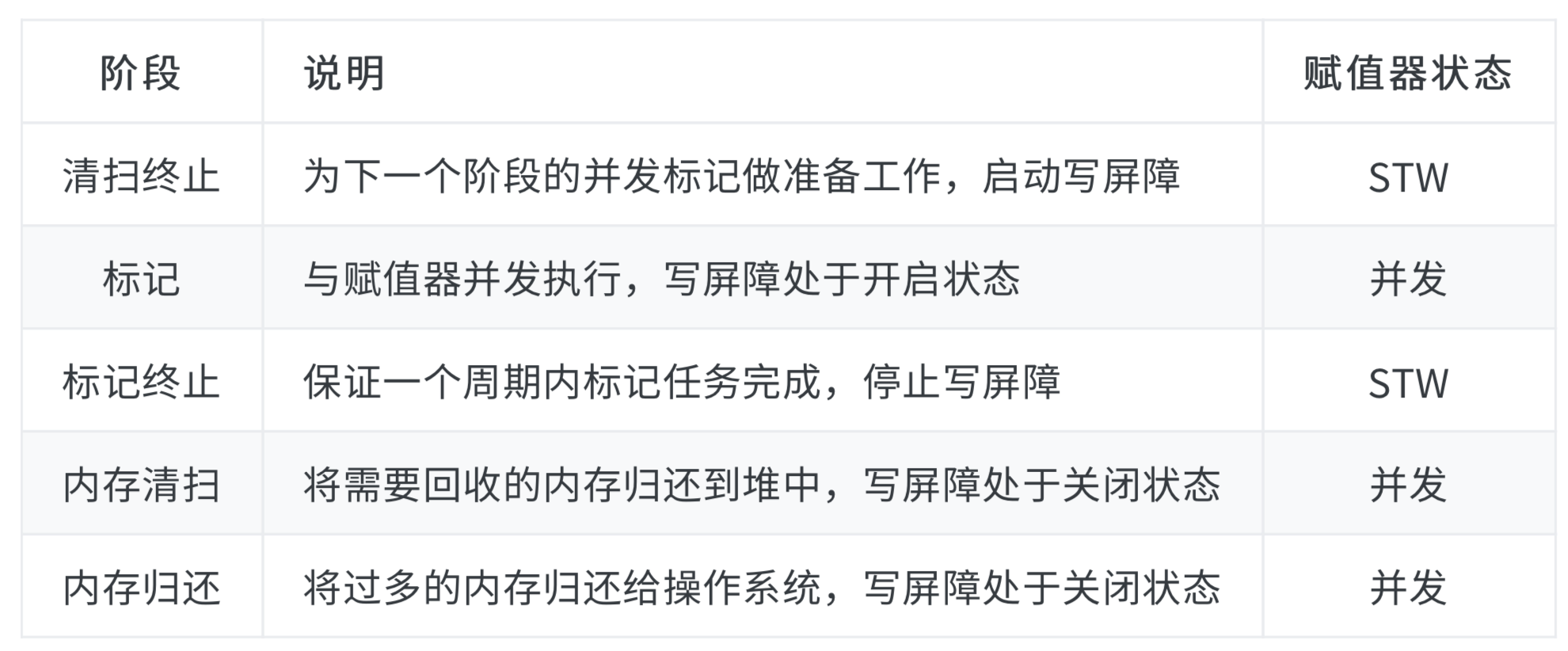
这个表格描述了Go垃圾回收器主要包含的五个阶段,我们看到虽然采用了并发三色标记和清除,但在一次GC周期内,还是要有2次STW,一次是结束标记,关闭写屏障,另一次是为下一个周期的并发标记做准备,开启写屏障。
STW时间依然是GC开销的主要来源之一。减少STW时间对于优化GC的性能依然至关重要,尤其是任意场景下都要保证尽可能短暂的STW,但这是Go core团队的任务。
- 标记与清除阶段的负荷
在标记与清除阶段,GC需要遍历堆内存中的所有对象,并进行标记和清除,这也是十分消耗cpu的工作。
- 标记辅助
GC的并发标记并非只是由特定(dedicated) goroutine去完成的,为了保证GC标记清扫的速度不低于业务goroutine分配内存的速度,保证程序不因消耗内存过快过大而被OS OOM(Out Of Memory) Killed,GC引入标记辅助技术,即让每个业务goroutine都有机会参与到GC标记工作中来!并且,这种标记辅助采用的是一种补偿机制,即该业务goroutine分配的内存越多,它要辅助标记的内存就越多。一旦某个业务goroutine被“拉壮丁”执行标记辅助工作,那么该goroutine的业务执行就会暂停,业务逻辑也就无法向前推进。
- 堆内存的释放
当Go GC回收了堆内存之后,如果堆的大小变得比之前小了,那么垃圾回收器会向操作系统归还多余的内存空间。在Linux等操作系统中,操作系统会将这些内存页标记为“未使用”,但是这些内存页并不会立即返回给操作系统,而是留给程序使用,以便程序将来再次申请内存时可以直接使用已经分配的内存页,从而减少内存分配的时间和开销。当程序没有使用这些内存页一段时间后,操作系统会将这些内存页回收,并将它们标记为“可用”,并在需要时重新分配给程序。这个过程是由操作系统的虚拟内存管理机制来完成的,具体的开销取决于操作系统的实现和硬件的性能等因素。
3.2 度量GC的开销
由于标记辅助技术的存在,单纯地从每个GC cycle的执行时间以及GC间隔时间来度量GC开销似乎就不那么准确了,更为直观的反映GC开销的是GC消耗cpu的占比。
不过目前上没有特别好的工具可以特别直观且直接告诉你当前Go程序执行时GC CPU占用率。我们可以通过pprof工具或类似Pyroscope这样的持续profiling的图形化工具来间接查看GC的cpu占用。
比如:通过Pyroscope提供的火焰图,查看runtime.gcBgMarkWorker(runtime后台专用的用于GC标记阶段的goroutine执行的函数)和runtime.gcAssistAlloc(标记辅助时调用的函数)的cpu消耗时间。
更为完整的Go runtime metrics指标,可以查看metrics包的文档。
注:GODEBUG=gctrace=1可以输出关于每个GC周期的详细信息,关于详细信息中各个字段的解读可以参见这里。更高级的选手还可以使用Go execution tracer工具来剖析GC的开销。
GC的CPU开销占比通常在25%以下,一旦超过这个负荷比例,就要考虑做调优了,Go保证GC cpu占用不会超过50%。
4. 优化GC的开销
优化GC的开销是提高系统性能和响应速度的重要手段。
前面我们分析了Go GC开销的主要来源。下面就针对每种来源说说优化开销的可能性与手段。
4.1 缩短STW时间
我们知道一旦GC STW后,所有业务逻辑都将暂停,这期间的CPU由GC 100%占用,降低STW时间是降低gc cpu占比的好方法。不过STW的算法是Go核心团队把控的,降低每个GC周期的STW时间也是Go核心团队的不二职责。从用户层面是很难影响到单次STW时间的。
不过,我们可以通过减少GC次数来间接减少STW次数,从而降低GC CPU占比。当然减少GC次数对后面的所有优化手段都有效,这是一个总开关。
那么如何减少GC次数呢?我们先来了解GC的触发时机。Go GC触发时机大体分为三种:
- 手动触发:调用runtime.GC()
- 常规触发:Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100
- sysmon后台周期性强制触发GC
我们看到,这三种触发时机我们能干预的只有常规触发,而常规触发的公式中,可以调整的只有GOGC这个参数(等价于debug.SetGCPercent())。GOGC默认值为100,也就是说当新分配heap内存的数量是上一周期的活跃heap内存的一倍的时候,触发GC:
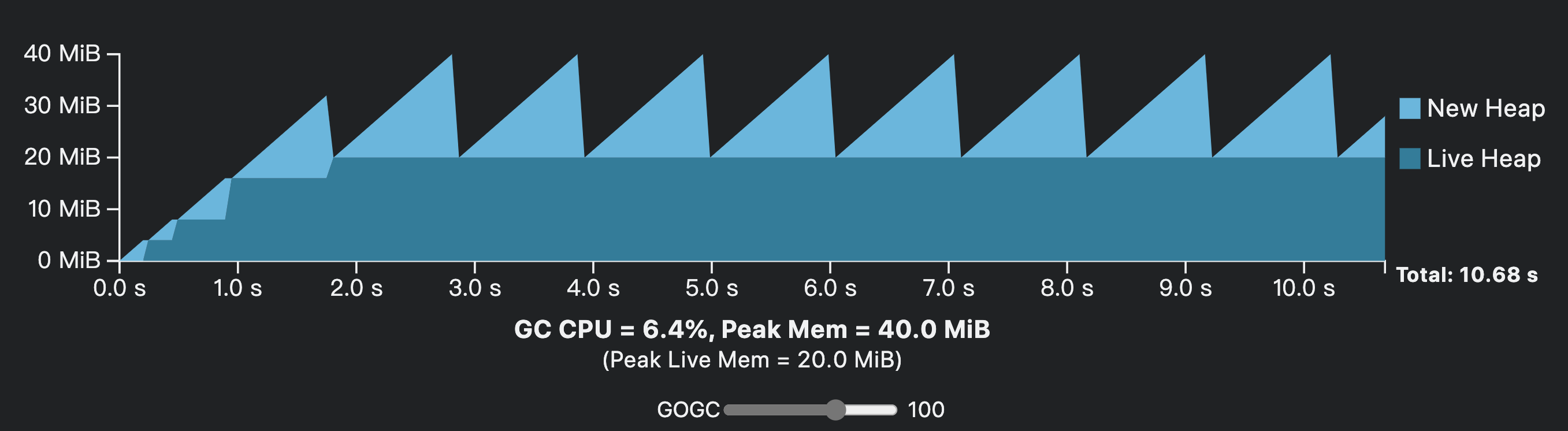
如果我们将GOGC改为200,那么GC的触发间隔将增加,频度会下降,CPU开销会降低(6.4%->3.8%),如下图:
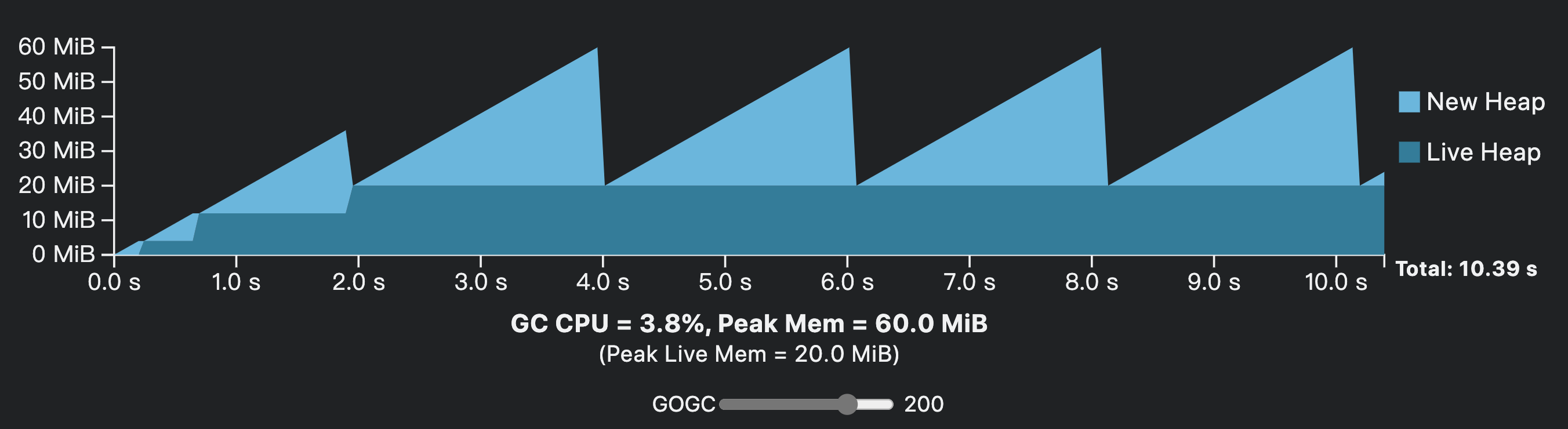
不过这是以整个程序的内存开销增大为代价的(40MB -> 60MB),并且对一般开发者而言,GOGC的值改起来确有风险,稍有不慎可能就会触发OMM killed。之前uber曾发表一篇文章,讲述了uber是如何通过在线自动调整GOGC参数来大幅降低CPU资源开销的,可以一看。
当然除了GOGC这一个唯一可调参数外,Go社区在降低GC频率方面也有自己的小妙招,比如之前经常使用的ballast(压舱石)技术。其原理就是在程序初始化时先分配一块大内存:
func main() {
// Create a large heap allocation of 10 GiB
ballast := make([]byte, 10<<30)
// Application execution continues
// ...
runtime.KeepAlive(ballast) // make sure the ballast won't be collected
}
这块内存仅体现在VSZ中,即该程序进程的虚拟内存中,但并不占用程序进程的常驻内存(RSS)中。但一旦分配,Go GC就会将其算作是一个“活”堆内存对象,在计算下一次GC时就会将其作为上述公式中的live heap考量。如果ballast为10GB,那么GC就会在程序每新分配10GB内存时才会被触发。
注:RSS是这个进程目前在主内存(RAM)中拥有多少内存。VSZ是该进程总共有多少虚拟内存。
Go 1.19版本引入了Soft memory limit,这个方案在runtime/debug包中添加了一个名为SetMemoryLimit的函数以及GOMEMLIMIT环境变量,通过他们任意一个都可以设定Go应用的Memory limit。
一旦设定了Memory limit,当Go堆大小达到“Memory limit减去非堆内存后的值”时,一轮GC会被触发。即便你手动关闭了GC(GOGC=off),GC亦会被触发。 不过soft memory limit不保证不会出现oom-killed。并且如果一个Go应用的live heap object超过了soft memory limit但还尚未被kill,那么此时GC可能会被频繁触发,将大量消耗cpu资源:
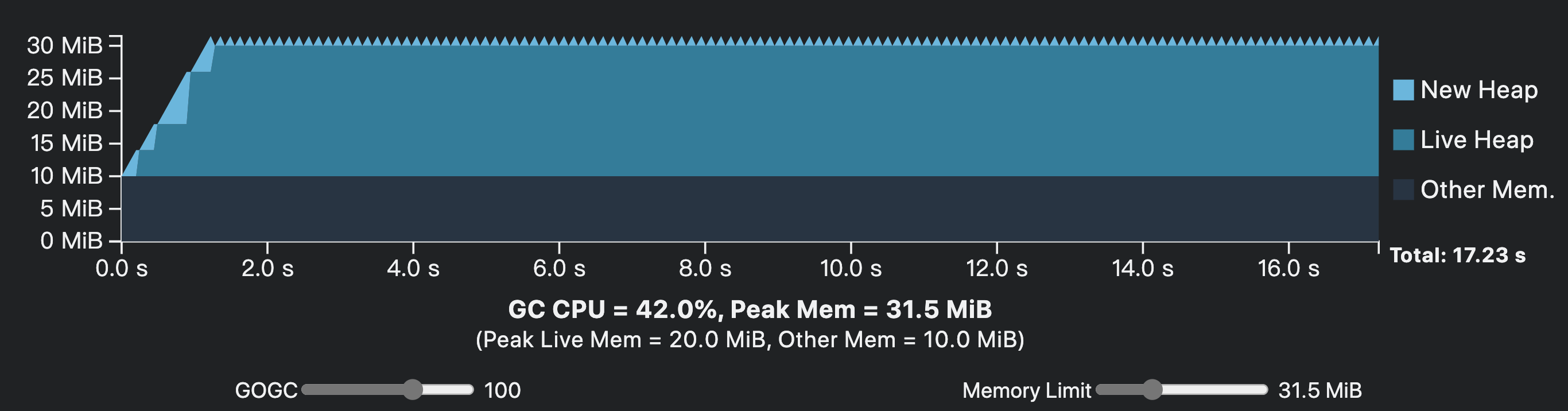
但为了保证在这种情况下业务依然能继续进行,soft memory limit方案保证GC最多只会使用50%的CPU算力,以保证业务处理依然能够得到cpu资源。
那么多大的值是合理的soft memory limit值呢?在Go服务独占容器资源时,一个好的经验法则是留下额外的5-10%的空间。uber在其博客中设定的limit为资源上限的70%,也是一个不错的经验值。
Memory Limit被看作是Go官方的ballast替代方案,但还是不有所不同的。Memory limit只是规定了一个上限,如果未到memory limit,Go的常规GC还是会照例执行的。GOGC=off+ soft Memory limit下的行为特征与ballast更类似,不过将GC关掉的风险还是很大的,要三思而后行。
Go GC没有采用分代机制,每次都是FullGC,减少GC次数确是降低GC CPU开销的良方。不过除此之外,我们还有一个优化GC开销的方法,我们继续看。
4.2 减少堆内存的分配和释放
GC开销大的根源在于heap object多,Go的每轮GC都是FullGC,每轮都要将所有heap object标记(mark)一遍,即便大多数heap object都是长期alive的,因此,一个直观的降低GC开销的方法就是减少heap object的数量,即减少alloc。
沿着这样的思路,我们可以很直接的想出如下两种手段:
- 把小对象聚合到一个结构体中,然后做一次分配即可
这样不仅利于减少分配次数,还有利于减少堆内存碎片,提高堆内存的利用率。如果整个结构体中没有指针对象,那么结构体的分配与释放将更加高效,具体原因可参见我的《Go GC如何检测内存对象中是否包含指针》一文。
- 重用
Go GC开销优化的一个典型手段就是内存空间重用,即建立一个池子,需要的时候从池中申请,用完后再放回池子里,供其他goroutine重用。这个过程不再有分配与释放。
Go中最典型的重用的例子就是sync.Pool的使用,不过sync.Pool并非完全不做释放操作,它是在一定程度上提高了重用的比例罢了。
5. 小结
Go GC的自动内存管理减少了内存泄漏和悬挂指针等问题。然而,GC给开发者带来便利的同时,开销也是不可避免的,它会对系统的性能和响应速度产生影响。Go开发者需要了解这些开销。
在本文中,我们介绍了GC的基本原理、GC的开销及其主要来源,并提供了优化GC开销的一些方法。
然而,要想有效地利用 GC,开发者需要了解其内部机制和算法,并根据实际情况进行调优。
除了通过GC参数降低GC频率外,在实际编码过程中,开发者还应该尽可能地减少对象的分配以降低Go每轮FullGC扫描对象的数量。
GC的优化是一项长期的工作。开发者应该不断地监控系统的性能和行为,并根据需要进行调整和优化,以确保系统的性能和响应速度始终保持在最佳状态。
6. 参考资料
- A Guide to the Go Garbage Collector – https://go.dev/doc/gc-guide
- Go GC的过去、现在与未来 – https://golang.design/under-the-hood/zh-cn/part2runtime/ch08gc/history/
- Go memory ballast: How I learned to stop worrying and love the heap – https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博(暂不可用):https://weibo.com/bigwhite20xx
- 微博2:https://weibo.com/u/6484441286
- 博客:tonybai.com
- github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。