
本文永久链接 – https://tonybai.com/2023/08/20/some-changes-in-go-1-21
美国时间2023年8月8日,Go团队在Go官博上正式发布了1.21版本!
早在今年4月末,我就撰写了文章《Go 1.21新特性前瞻》,对Go 1.21可能引入的新特性、新优化和新标准库包做了粗略梳理。
在6月初举办的GopherChina 2023大会上,我又以“The State Of Go 2023”为题目给大家分享了Go 1.21版本的当前状态:

那么以上分享的内容在Go 1.21的正式版中究竟真正落地了没有?Go 1.21正式版中还有哪些在之前的分享资料中未曾介绍的值得注意的变化呢?在这篇系列文章中,我们就来看一看。
注:从Go 1.21版本开始,Go Release版本的起始版本号(first release of the release family)由Go 1.N改为Go 1.N.0了。Go语言版本号(language version)依旧是Go 1.N,同时Go Release Family的版本号也依然是Go 1.N。
1. 语言变化
和以往的系列文章一样,我们先来看看语言特性方面有哪些值得注意的变化。
众所周知,Go语法特性变化甚少,在一些新版本中没有语言特性变化反倒是一种常态。在去年GopherCon 2022大会上,Russ Cox发表“How Go Programs Keep Working”的主题演讲,演讲中Russ Cox就提到:“我们发布Go 1.0版本及兼容性承诺,就是为了停止那种兴奋,以便Go的新版本会变得boring(平淡无奇)”,并且Go team认为boring is good, boring is stable:

这也意味着在未来Go的演化过程中,Go依旧会保持极少增加语言特性的节奏。
注:不要认为一门编程语言要保持boring很容易,在这篇文章后面也会提到Go核心团队对如何保持boring(向前向后兼容性)的思考和手段。
Go 1.21版本中,Go语言特性的变化还是可以的,主要是增加了几个builtin预定义函数、明确了包初始化顺序的算法、增强了泛型的类型推断能力并以实验性选项的方式修正了Go1中的两个容易导致问题的语法语义。接下来,我们就来逐个具体说明一下。
我们先来看看builtin中预定义函数的变化。
1.1 min、max和clear
builtin包是变更“常客”,最近几个Go版本中,builtin包都有新变化。
注:builtin包是一个特殊包,里面放置了Go语言预定义的标识符,用户层代码无需也不能导入builtin包。
在Go 1.21版本中,builtin增加了三个预定义函数:min、max和clear。
顾名思义,min和max函数分别返回参数列表中的最小值和最大值,它们都是泛型函数,原型如下:
func min[T cmp.Ordered](x T, y ...T) T
func max[T cmp.Ordered](x T, y ...T) T
通过原型我们看到,使用这两个函数时,参数的类型要相同,且至少要传入一个参数:
// lang/min_max.go
var x, y int = 5, 6
fmt.Println(max(x)) // 5
fmt.Println(max(x, y, 0)) // 6
fmt.Println(max("aby", "tony", "tom")) // tony
如果传入的参数的类型不同呢?我们看下面代码:
// lang/min_max.go
var f float64 = 5.6
fmt.Printf("%T\n", max(x, y, f)) // invalid argument: mismatched types int (previous argument) and float64 (type of f)
fmt.Printf("%T\n", max(x, y, 10.1)) // (untyped float constant) truncated to int
我们看到:Go 1.21编译器报错,即便是untyped constant,如果类型不同,也会提醒你可能存在值精度的truncated。
max和min支持哪些类型呢?通过min和max原型中的类型参数(type parameter)可以看到,其约束类型(constraint)为cmp.Ordered,我们看一下该约束类型的定义:
type Ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64 |
~string
}
符合Ordered约束的上述这些类型以及衍生类型都可以使用min、max获取最小值和最大值。
相对于min、max两个函数的简单,新增的clear函数的语义就略复杂一些。在《Go 1.21新特性前瞻》一文中提到过,这里再赘述一下:)
clear函数的原型如下:
func clear[T ~[]Type | ~map[Type]Type1](t T)
从原型来看,clear的操作对象是切片和map类型,不过其执行语义因依操作的对象类型而异。我们看下面例子:
// lang/clear.go
var sl = []int{1, 2, 3, 4, 5, 6}
fmt.Printf("before clear, sl=%v, len(sl)=%d, cap(sl)=%d\n", sl, len(sl), cap(sl))
clear(sl)
fmt.Printf("after clear, sl=%v, len(sl)=%d, cap(sl)=%d\n", sl, len(sl), cap(sl))
var m = map[string]int{
"tony": 13,
"tom": 14,
"amy": 15,
}
fmt.Printf("before clear, m=%v, len(m)=%d\n", m, len(m))
clear(m)
fmt.Printf("after clear, m=%v, len(m)=%d\n", m, len(m))
这段代码的输出结果如下:
before clear, sl=[1 2 3 4 5 6], len(sl)=6, cap(sl)=6
after clear, sl=[0 0 0 0 0 0], len(sl)=6, cap(sl)=6
before clear, m=map[amy:15 tom:14 tony:13], len(m)=3
after clear, m=map[], len(m)=0
我们看到:
- 针对slice,clear保持slice的长度和容量,但将所有slice内已存在的元素(len个)都置为元素类型的零值;
- 针对map,clear则是清空所有map的键值对,clear后,我们将得到一个empty map。
下面的表格是一个更直观、更泛化的clear函数语义总结:

注:clear函数在清空map中的键值对时,并未释放掉这些键值所占用的内存。
1.2 明确了包初始化顺序算法
在Go中,包既是功能单元,也是构建单元,Go代码通过导入其他包来复用导入包的导出功能(包括导出的变量、常量、函数、类型以及方法等)。Go程序启动时,程序会首先将依赖的包按一定顺序进行初始化,但长久以来,Go语言规范并没有明确依赖包初始化的顺序,这可能会导致一些对包初始化顺序有依赖的Go程序在不同Go版本下出现行为的差异。
为了消除这些可能存在的问题,Go核心团队在Go 1.21中明确了包初始化顺序的算法。
注:对包的初始化顺序有依赖,这本身就不是一种很好的设计,大家日常编码时应该注意避免。如果你的程序对包的初始化顺序存在依赖,那么升级到Go 1.21时你的程序行为可能会受到影响。
这个算法比较简单,其步骤如下:
- 将所有依赖包按照导入路径排序,放入一个list;
- 从list中按顺序找出第一个自身尚未初始化,但其依赖包已经全部初始化了的包,然后初始化该包,并将该包从list中删除;
- 重新执行上面步骤,直到list为空。
再简单的算法,用文字描述都会很抽象晦涩,我们用一个例子来诠释一下。我们建立一个init_order的目录,里面的包之间的依赖关系如下图:
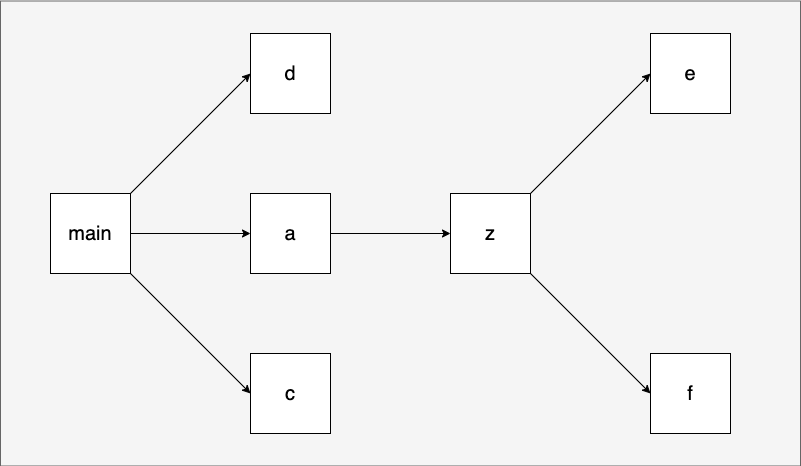
我们在init_order目录下按上面关系建立对应的包:
$tree init_order
init_order
├── a
│ └── a.go
├── c
│ └── c.go
├── d
│ └── d.go
├── e
│ └── e.go
├── f
│ └── f.go
├── go.mod
├── main.go
└── z
└── z.go
我们使用Go 1.21.0运行一下其中的main.go,得到如下结果:
$go run main.go
init c
init d
init e
init f
init z
init a
这个结果是怎么来的呢?我们根据Go 1.21.0明确后的算法来分析一下,具体分析过程见下图:
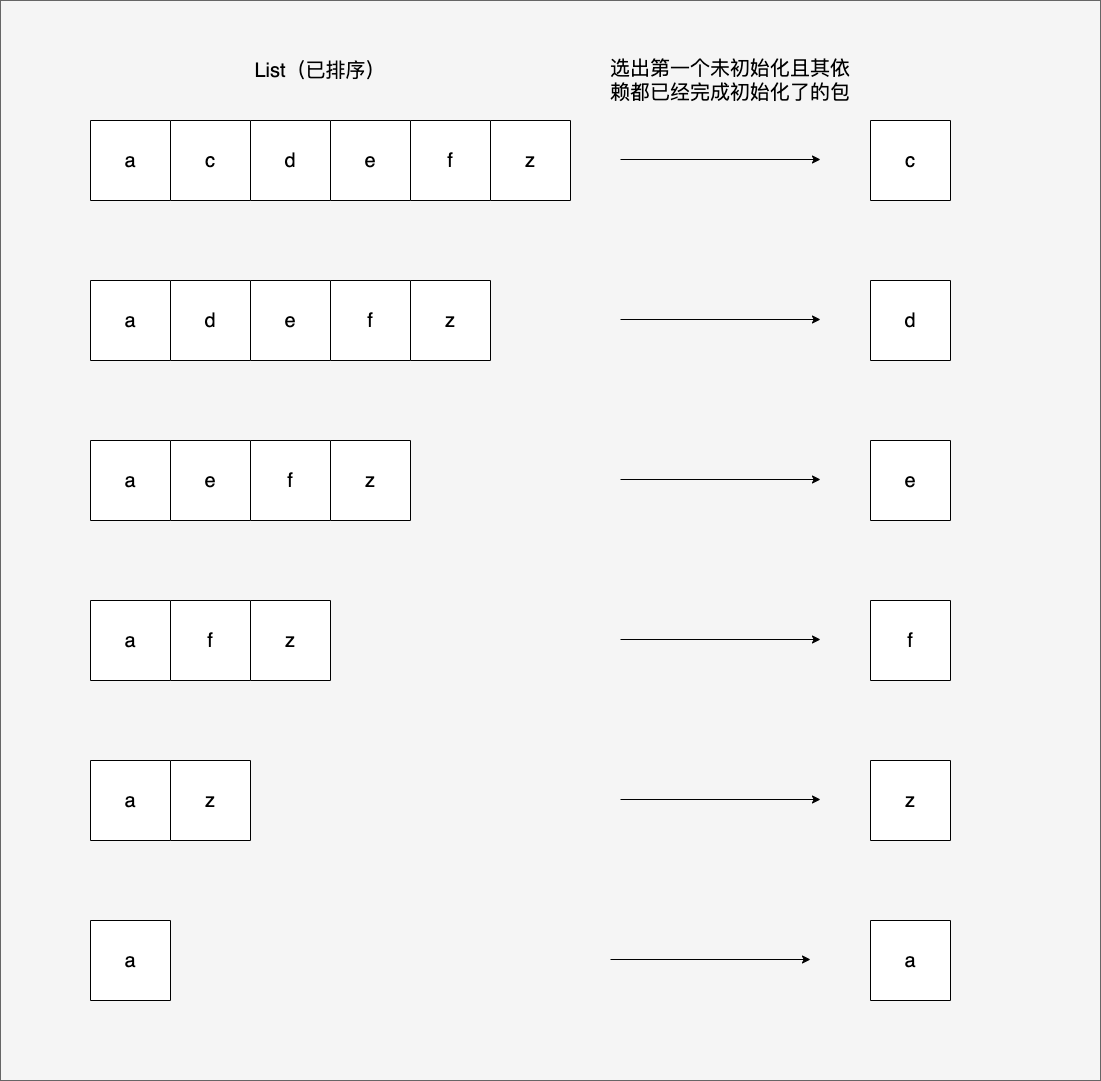
将右侧每一轮选出的包按先后顺序排列一下,就是main.go的依赖包的初始化顺序:c d e f z a。
我们再用Go 1.20版本运行一下这个示例,得到下面结果:
init e
init f
init z
init a
init c
init d
我们看到这个顺序与Go 1.21版本的完全不同。
注:我的极客时间专栏《Go语言第一课》的第8讲有对Go入口函数与包初始化次序的更为系统的讲解。
1.3 type inference的增强
Go 1.21版本对泛型的类型推断能力做了增强。但Go 1.21 Release Notes以及Go spec中对这块的说明都十分晦涩,这里尝试用例子简要直观的说明一下。
此次的类型推断增强主要包含以下三个方面:
- 部分实例化的泛型函数(Partially instantiated generic functions)
我们以下面IndexFunc函数为例,来说明一下这方面的增强:
// lang/type_inference/partially_instantiated_generic_func.go
// 该IndexFunc的实现来自Go 1.21的slices包
func IndexFunc[S ~[]E, E any](s S, f func(E) bool) int {
for i := range s {
if f(s[i]) {
return i
}
}
return -1
}
我们使用上面IndexFunc函数返回一个整型切片中的第一个负数,我们可以这样做:
func negative(n int) bool {
return n < 0
}
func main() {
numbers := []int{0, 42, -10, 8}
i := IndexFunc(numbers, negative)
fmt.Println("First negative at index", i) // First negative at index 2
}
IndexFunc是一个泛型函数,它可以操作任意类型切片,于是你可能会想是否可以写一个泛型版的negative函数,这样就可以应对所有数值类型的切片了,比如:
type Ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64 |
~string
}
func negative[T Ordered](n T) bool {
var zero T
return n < zero
}
接下来我们用这个泛型版negative函数作为IndexFunc的参数:
func main() {
numbers := []int{0, 42, -10, 8}
i := IndexFunc(numbers, negative)
fmt.Println("First negative at index", i)
}
用Go 1.21版本之前的Go编译器运行上述代码,我们会得到如下错误:
./partially_instantiated_generic_func.go:32:26: cannot use generic function negative without instantiation
也就是说Go 1.21版本之前的Go编译器无法根据对IndexFunc的第二个参数的赋值来推断出参数f的类型实参。要想通过编译器检查,需显式传入类型实参,比如:negative[int]。
Go 1.21版本对此做了增强,支持在将negative赋值给IndexFunc的第二个参数时,根据IndexFunc的上下文环境(比如:第一个参数中的元素类型)推断出negative的类型实参。
这种部分实例化的泛型函数的典型应用就是在操作容器类类型的函数中。
- 接口赋值推断(Interface assignment inference)
为了解释什么是接口赋值推断,我们也来看一个例子(不要计较例子设计的合理性):
// lang/type_inference/interface_assignment_inference.go
type Indexable[T any] interface {
At(i int) (T, bool)
}
func Index[T any](elems Indexable[T], i int) (T, bool) {
return elems.At(i)
}
type MyList[T any] []T
func (m MyList[T]) At(i int) (T, bool) {
var zero T
if i > len(m) {
return zero, false
}
return m[i], true
}
func main() {
var m = MyList[int]{11, 12, 13}
fmt.Println(Index(m, 2))
}
我们使用Go 1.20版本运行这个示例,将得到下面错误结果:
$go run interface_assignment_inference.go
./interface_assignment_inference.go:29:24: type MyList[int] of m does not match Indexable[T] (cannot infer T)
我们看到Go 1.20版本无法推断出泛型接口类型Indexable的类型实参。
但使用Go 1.21版本编译和运行,程序可以成功输出下面结果:
$go run interface_assignment_inference.go
13 true
在Go 1.21中,类型推断也会考虑接口类型的方法。当一个值被赋值给一个接口时,编译器可以从匹配方法的相应参数类型中推断出接口类型的类型实参。
- 对无类型常量的类型推断(Type inference for untyped constants)
我们还是通过一个例子来理解一下:
// lang/type_inference/untyped_constants_inference.go
func Sum[T int | float64](a ...T) T {
var sum T
for _, v := range a {
sum += v
}
return sum
}
func main() {
fmt.Printf("%T\n", Sum(1, 2, 3.5))
}
示例中的泛型函数Sum支持的类型实参为float64或int,但main函数调用Sum时使用了无类型常量,如果用Go 1.20版本编译器运行这段程序,我们将得到如下结果:
$go run untyped_constants_inference.go
./untyped_constants_inference.go:14:31: default type float64 of 3.5 does not match inferred type int for T
Go 1.20在做类型实参推断时,仅考虑了单个传入的实参,这导致编译器认为3.5这个float64与推断出的int不匹配。
Go 1.21版本改善了这个推断算法:如果多个不同类型的无类型常量参数(如例子中的一个无类型的 int 和一个无类型的浮点常量)被传递给具有相同类型参数类型的参数,现在类型推断将使用与具有无类型常量操作数的运算符相同的方法来确定类型,而不是报错。这一改进使从无类型常量参数推断出的类型与常量表达式的求值后的类型一致。
这样,上面的Sum(1,2,3.5)推断出的类型实参的类型与1 + 2 + 3.5这个表达式的求值结果的类型一致,即float64!我们用Go 1.21版本运行一下上述示例程序:
$go run untyped_constants_inference.go
float64
1.4 修正Go1中的“陷阱”
Go 1.21是一个“大”版本,这里的“大”并非是指Go 1.21涉及的内容广、变化多,而是指Go 1.21的一些变化的思路对后续版本可能有深远影响。比如Go 1.21就开启了修正Go1中一些语义“陷阱”的工作,并且这些修正可能会带来语义上的不向后兼容。不过这并不违反Go1兼容性承诺,因为在Go1兼容性承诺中,因对buggy语义或行为的修正而导致的对已有代码行为的破坏是允许的。
下面我们就来看看Go 1.21引入的两个“修正”。
1.4.1 panic(nil)语义
在Go 1.21中,Go编译器会将panic(nil)替换为panic(new(runtime.PanicNilError)),关于这个语义的变更,我在《Go 1.21新特性前瞻》一文中有详细说明,这里就不赘述了。
如果你要恢复原先的语义,可以使用GODEBUG=panicnil=1这个功能开关。
1.4.2 loop var per-loop -> loop var per-iteration
Go语言中的循环语句只有for这一种,for range是一种变体,专门用于对切片、数组、map和channel的遍历。
不过Go的for循环语句,尤其是for range语句有着很容易让程序出现错误的语义,即我们常说的“有坑”。
注:我的《Go语言精进之路vol1》一书的第19条“了解Go语言控制语句惯用法及使用注意事项”中对for range的“坑”做了系统的梳理并给出了避坑建议。
下面是一个典型的for range的“坑”的示例:
// lang/loopvar/loopvar_per_loop.go
func main() {
var m = [...]int{1, 2, 3, 4, 5}
for i, v := range m {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}()
}
time.Sleep(time.Second * 10)
}
这个示例意图在每次迭代启动的新的goroutine中输出迭代对应的i和v的值,但实际输出结果是什么呢?我们实际运行一下:
$go run loopvar_per_loop.go
4 5
4 5
4 5
4 5
4 5
我们看到:goroutine中输出的i、v值都是for range循环结束后的i、v的最终值,而不是各个goroutine启动时的i、v值。这是因为goroutine执行的闭包函数引用了它的外层包裹函数中的变量i、v,这样变量i、v在主goroutine和新启动的goroutine之间实现了共享。
而i, v值在整个循环过程中是重用的,即仅有一份。在for range循环结束后,i = 4, v = 5,因此各个goroutine在等待3秒后进行输出的时候,输出的是i, v的最终值。
这里的i和v被称为loop var per loop,即一个循环语句定义一次的变量,等价于下面代码:
{
var i, v int
for i, v = range m {
//... ...
}
}
一种解决这个问题的典型方法是这样的:
// lang/loopvar/loopvar_per_iteration_classic.go
for i, v = range m {
i := i
v := v
//... ...
}
我们在每个迭代中用短变量声明重新定义了在这次迭代中使用的i和v,这里的i和v就是loop var per-iteration的了。不过这个方法也存在问题,比如不能解决所有场景下的loop var per-iteration问题,另外就是需要手工创建。
Go团队决定在Go 1.22版本移除这个“坑”,并在Go 1.21版本中以实验语义(GOEXPERIMENT=loopvar)提供了默认采用loop var per-iteration语义的for循环(包括for range)。新语义仅在GOEXPERIMENT=loopvar且在for语句(包括for range)的前置条件表达式中使用短变量声明循环变量时才生效。
下面是for range的新语义的示例:
// lang/loopvar/loopvar_per_iteration.go
package main
import (
"fmt"
"time"
)
func main() {
var m = [...]int{1, 2, 3, 4, 5}
for i, v := range m {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}()
}
time.Sleep(time.Second * 10)
}
使用新语义运行该示例:
$GOEXPERIMENT=loopvar go run loopvar_per_iteration.go
2 3
1 2
4 5
0 1
3 4
我们看到,新loopvar语义就相当于我们在每次迭代时手动重新定义i := i和v := v。
对于经典的3段式for循环语句,新loopvar语义的逻辑略复杂一些,我们用下面这个例子来理解一下:
// lang/loopvar/classic_for_loop_in_1_21.go
func main() {
var m = [...]int{1, 2, 3, 4, 5}
for i := 0; i < len(m); i++ {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, m[i])
}()
}
time.Sleep(time.Second * 10)
}
采用经典的loopvar per loop语义执行上述代码:
$go run classic_for_loop_in_1_21.go
panic: runtime error: index out of range [5] with length 5
goroutine 21 [running]:
main.main.func1()
/Users/tonybai/Go/src/github.com/bigwhite/experiments/go1.21-examples/lang/loopvar/classic_for_loop_in_1_21.go:14 +0xb6
created by main.main in goroutine 1
/Users/tonybai/Go/src/github.com/bigwhite/experiments/go1.21-examples/lang/loopvar/classic_for_loop_in_1_21.go:12 +0x76
exit status 2
由于各个goroutine通过闭包捕获到同一个i,而该i值在loop结束后为5,因此当以该i作为下标访问数组时,就会出现越界的panic。
我们再来在新loopvar语义下执行上面代码:
$GOEXPERIMENT=loopvar go run classic_for_loop_in_1_21.go
2 3
4 5
3 4
0 1
1 2
我们看到了期望输出的结果。下面我使用一段等价代换代码来理解经典for loop的新语义:
for i := 0; i < 5; i++ {
// 使用i
}
在新语义下等价于
for i := 0; i < 5; i++ {
i' := i
// 使用i'
i = i'
}
我们看到:新语义相当于Go编译器在每次iteration的前后各插入一行代码,在迭代(iteration)开始处插入i’ := i,然后迭代过程中使用的是i’,而在迭代的末尾则将i’的最新值赋值给i,后续i继续参与到loop是否继续的条件判定以及后置语句的操作中去。
注:在Go 1.21版本中使用GOEXPERIMENT=loopvar引入的新loopvar语义可能会导致遗留代码出现错误。
到这里,我们就聊完了语言特性的变化。接下来,我们再来简单看看Go编译器和运行时的主要变化。
2. Go编译器与运行时
2.1 PGO默认开启
Go 1.20版本引入了PGO(profile-guided optimization)优化技术预览版,Go 1.21版本中,PGO正式GA。如果main包目录下包含default.pgo文件,Go 1.21编译器在编译二进制文件时就会默认开启基于default.pgo中数据的pgo优化。优化带来的性能提升因程序而异,一般是2%~7%。
Go 1.21编译器自身就是基于PGO优化过的,编译速度提升约6%。
2.2 大幅降低GC尾部延迟
Go 1.21通过对运行时内部的GC的优化,应用程序的尾部延迟最多可减少40%,内存使用量也会略有减少。不过有些应用可能会观察到吞吐量的少量损失。内存使用量的减少与吞吐量的损失大约成正比。
2.3 支持WASI(WebAssembly System Interface)
Go 1.21开始支持将Go编译为支持WASI规范的wasm程序,具体可参见《Go 1.21新特性前瞻》。
不过,Go 1.21版本尚没有导出自定义函数的机制,比如:在Go源代码中声明Add函数不会使得该函数在编译后的WebAssembly中被导出。因此,如果使用诸如wazero这样的wasm runtime在加载Wasm后查找Add函数,将无法找到。
注:wazero目前可以与支持导出自定义函数到wasm中的tinygo一起配合使用。
一旦Go支持将自定义函数导出到wasm中,那么是否可以实现基于wasm的Go应用插件机制呢?wasm的执行性能如何呢?这个就留到Go支持导出函数到wasm之后再行讨论吧。
3. Go工具链
Go 1.21在工具链方面最值得关注的就是Go团队对向后兼容(backwards compatibility)和向前兼容(forwards compatibility)的重新思考和新措施。
所谓向后兼容就是用新版Go编译器可以编译遗留的历史Go代码,并可以正常运行。比如用Go 1.21版本编译器编译基于Go 1.5版本编写的Go代码。Go在这方面做的一直很好,并提出了Go1兼容性承诺。
而向前兼容指的是用旧版编译器编译新版本Go的代码,比如用Go 1.19版本编译器编译基于Go 1.21版本编写的Go代码。显而易见,如果Go代码中使用了Go 1.21引入的新语法特性,比如clear,那么Go 1.19编译Go代码时会失败。
Go 1.21中对于Go工具链的向前和向后兼容又做了进一步的明确和增强,下面我们就来看一下具体的内容。
3.1 向后兼容
为了提高向后兼容性的体验,从Go 1.21版本开始,Go扩展和规范化了GODEBUG的使用。其大致思路如下:
-
对于每个在Go1兼容性承诺范围内的且可能会破坏(break)现有代码的新特性/新改变(比如:panic(nil)语义的改变)加入时,Go会向GODEBUG设置中添加一个新选项(比如GODEBUG=panicnil=1),以保留采用原语义进行编译的兼容能力;
-
GODEBUG中新增的选项将至少保留两年(4个Go release版本),对于一些影响重大的GODEBUG选项(比如http2client和http2server),保留的时间可能更长,甚至一直保留;
-
GODEBUG的选项设置与go.mod的go version是匹配的。例如,即便你现在的工具链是Go 1.21,如果go.mod中的go version为1.20,那么GODEBUG控制的新特性语义将不起作用,依旧保持Go 1.20时的行为。除非你将go.mod中的go version升级为go 1.21.0。下面的例子就展示了这一点:
// tools/godebug/go.mod module demo
go 1.20
// tools/godebug/panicnil.go
func foo() { defer func() { if e := recover(); e != nil { fmt.Println(“recover panic from”, e) return } fmt.Println(“panic is nil”) }()
panic(nil)}
func main() { foo() }
这个例子中go.mod中的go version为go 1.20,我们用go 1.21去编译运行该示例,得到如下结果:
$go run panicnil.go
panic is nil
我们看到,即便用go 1.21编译,由于go.mod中go version为go 1.20,go 1.21对panic(nil)的语义变更并未生效。
如果我们将go.mod中的go version改为go 1.21.0,再运行该示例:
$go run panicnil.go
recover panic from panic called with nil argument
我们看到,这次示例中的panic(nil)语义发生了变化,匹配了go 1.21对panic(nil)语义的改变。
在Go 1.21中,除了使用GODEBUG=panicnil=1来恢复原先语义外,还可以在main包中使用//go:debug指示符:
// tools/godebug/panicnil.go
//go:debug panicnil=1
package main
import "fmt"
// 省略... ...
使用//go:debug指示符后,即便使用go 1.21编译,panic(nil)也会恢复到之前的语义。
很多Gopher说,历经这么多版本,GODEBUG究竟有多少了开关选项已经记不住了,没关系,Go官方文档为gopher提供了GODEBUG演进历史的文档,使用时自行查阅。
这样,Go 1.21以后,GODEBUG就成为了应对在Go1兼容性承诺范围内,但又可能对现有代码造成破坏的change的一种标准兼容机制。
3.2 向前兼容
说完向后兼容,我们再来看看向前兼容,即用老编译器编译新版本代码。
有人会说:老编译器编译新版本代码能否编译通过并运行正常要看新版本代码中是否使用了新版本的特性。比如用Go 1.16版本编译带泛型语法的Go 1.18https://tonybai.com/2022/04/20/some-changes-in-go-1-18代码肯定是无法编译通过啊,升级一下编译器版本不就行了吗。向前兼容性的问题可能没有大家想象的这么简单。
如果当前代码中没有使用go 1.18中的泛型语法,使用go 1.16可以正常编译该代码,那么编译出的程序的运行行为就一定正常么?这要看Go 1.18中看似与Go 1.16版本代码兼容的部分是否有语义上的改变。如果存在这种语义上的改变,导致程序在生产中实际行为与预期行为不同,那么还不如编译失败带来的损失更小。因此,Go团队希望在向前兼容方面提供更精细化,更准确的管理手段。
从Go 1.21开始,go.mod文件中的go line将被当成一个约束规则。go line中的go版本号将被解释为用于编译该module时使用的最小Go语言版本,只有这个版本或其高于它的版本才能保证具有该module所需的Go语法语义。
Go始终允许用低版本go工具链编译go line中版本号高于工具链版本的go代码,之所以这么做,是为了避免不必要的编译失败给开发者情绪造成的影响:如果你被告知Go版本太旧无法编译程序,你肯定不会是开心的^_^。
但在Go 1.21之前,旧版本工具链编译新代码,有时候会构建成功(比如代码中没有使用新版本引入的新语法特性),有时会因代码中的新语法特性而构建失败。这种割裂的体验是Go团队不希望看到的,于是Go团队希望将工具链的管理也纳入到go命令中。
Go 1.21中一个最直观的变化就是当用Go 1.21编译一个go line为go 1.21.1的module时,如果本地不存在go 1.21.1工具链,go 1.21不会报错,而是去尝试下载go 1.21.1工具链到本地,如果下载成功,就会用go 1.21.1来编译这个module:
$go run panicnil.go // 将go.mod中的go line改为1.21.1后
go: downloading go1.21.1 (darwin/amd64)
go: download go1.21.1 for darwin/amd64: toolchain not available
不过Go 1.21的这种自动下载新版工具链后,并不会将它安装到GOPATH/bin或覆盖当前本地安装的工具链。它会将下载的新版本工具链当作Go module,这继承了module管理的所有安全和隐私优势,然后go会从module缓存中运行下载后的工具链module。
除此之外,Go 1.21还在go.mod中引入了toolchain指示符以及GOTOOLCHAIN环境变量。一个包含了toolchain指示符的go.mod的内容如下面所示:
// go.mod
module m
go 1.21.0
toolchain go1.21.4
这个go.mod中的go line含义是当其他go module依赖m时,需要至少使用go 1.21.0版本的工具链;而m模块的作者编译m时,需要了一个更新的工具链:go 1.21.4。
我们知道通过go get example.com/module@v1.2.1可以更新go.mod中的require block,在go 1.21版本中,我们可以使用go get go@1.21.1更新go.mod中的go line中的go version。当然以此类推,我们也可以通过go get toolchain@go1.21.1更新go.mod中的toolchain line中的工具链版本号。
Go工具链最终版本的选择规则较为繁琐,受到local安装的go工具链版本、GOTOOLCHAIN环境变量的设置以及go.mod中的toolchain line的综合影响,大家可以参考toolchain文档理解,这里就不引述了。
4. Go标准库
每个Go版本中变化最大的一定是标准库,这里不能一一列举所有变化,我挑了几个重要的包和大家简单分享一下。后续可能会安排专门文章对某个标准库包做专题说明。
4.1 log/slog
原生支持的结构化日志终于在go 1.21版本落地了,其路径为log/slog。在去年就写过一篇有关slog的文章《slog:Go官方版结构化日志包》,不过这近一年多以来,slog的设计和实现也都发生了一些调整,那篇文章的少部分内容可能已经不适用了。
关于slog值得单独写一篇新博文去专门说明,这个在后面可能会安排:)。
此外,Go标准库还增加了testing/slogtest包,来帮助大家验证slog.Handler的实现,这个是以前没有的。
slog是一个高质量、高性能的结构化日志实现,这里建议大家在启动新Go项目时,尽量采用log/slog作为日志输出的方案。
4.2 slices、maps和cmp
在Go实验库“孵化”了一年多的几个泛型包slices、maps和cmp终于在Go 1.21版本中正式加入到标准库中了。
slices切片包提供了针对切片的常用操作,slices包使用了泛型函数,可处理任何元素类型的切片。同理,maps包与slices包地位相似,只不过操作对象换成了map类型变量,它可以处理任意类型键和元素类型的map。
cmp包是slices包依赖的包,这个包非常简单且内聚,它仅提供了与compare和ordered相关的约束类型定义与简单泛型函数:
// cmp包
type Ordered interface {
~int | ~int8 | ~int16 | ~int32 | ~int64 |
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr |
~float32 | ~float64 |
~string
}
func Less[T Ordered](x, y T) bool {
return (isNaN(x) && !isNaN(y)) || x < y
}
func Compare[T Ordered](x, y T) int {
... ...
}
func isNaN[T Ordered](x T) bool {
return x != x
}
以上三个包没有太多可说的,都是一些utils类的函数,大家在日常开发中记得用就ok了,基于泛型的实现以及unified中间代码的优化,这些函数的性能相对于基于interface实现的通用工具函数要高出一些。
注:在Go 1.21正式版发布之前,Go team删除了maps包中原有的Keys和Values函数,其原因是要在后续版本中提供iter包。
4.3 其他变化
- 增加errors.ErrUnsupported
标准库各个包都有类似unsupported的Error类型的定义,第三方包更是多如牛毛。Go 1.21在errors包中增加了ErrUnsupported,旨在统一后续对unsupported的错误判定。不过在你的函数或方法中不要直接返回errors.ErrUnsupported,要么用自定义error包装(wrap) errors.ErrUnsupported,要实现Is方法。目的是使得你自己的Error类型提供的unsupported error满足:errors.Is(err, errors.ErrUnsupported) == true。
http包的ErrNotSupported采用的就是实现Is方法的方式支持errors.ErrNotSupported的:
// Is lets http.ErrNotSupported match errors.ErrUnsupported.
func (pe *ProtocolError) Is(err error) bool {
return pe == ErrNotSupported && err == errors.ErrUnsupported
}
注:errors.ErrUnsupported这种统一对unsupported类错误处理的设计方式直接借鉴。
- flag:增加BoolFunc函数
略。
- net: 在linux上支持多路径TCP
多路径TCP协议可以让一个TCP连接在多个网络路径之间进行数据传输,从而提高传输速度和可靠性的技术。Go 1.21在linux平台上支持net包使用多路径TCP协议(如果linux kernel支持的话)。不过目前这不是默认开启的,可以通过Dialer的下面方法来显式设置:
func (d *Dialer) SetMultipathTCP(use bool)
在将来的版本中,该机制很大可能会变为默认开启的。
- reflect:ValueOf允许在栈上分配Value的内容
在Go 1.21中,ValueOf不再强制Value内容在堆上分配,而是允许在栈上分配Value的内容。对Value的大多数操作也允许在栈中分配底层值。通过其代码实现可以更好地理解这点变化:
// Before Go 1.21, ValueOf always escapes and a Value's content
// is always heap allocated.
// Set go121noForceValueEscape to true to avoid the forced escape,
// allowing Value content to be on the stack.
// Set go121noForceValueEscape to false for the legacy behavior
// (for debugging).
const go121noForceValueEscape = true
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero Value.
func ValueOf(i any) Value {
if i == nil {
return Value{}
}
if !go121noForceValueEscape {
escapes(i)
}
return unpackEface(i)
}
- sync: 增加OnceFunc, OnceValue和OnceValues等语法糖函数
略。
- testing: 新增Testing函数
Go 1.21为testing包增加了func Testing() bool函数,该函数可以用来报告当前程序是否是go test创建的测试程序。使用Testing函数,我们可以确保一些无需在单测阶段执行的函数不被执行。比如下面这个例子:
// file/that/should/not/be/used/from/testing.go
func prodEnvironmentData() *Environment {
if testing.Testing() {
log.Fatal("Using production data in unit tests")
}
....
}
- crypto/tls:增加QUICConn以支持后续的QUIC实现
略。
- context包:新增WithoutCancel、WithDeadlineCause、WithTimeoutCause和AfterFunc
新增的WithoutCancel、WithDeadlineCause、WithTimeoutCause函数可以让你通过Cause函数获得导致cancel/timeout的真因:
ctx, cancel := context.WithCancelCause(parent)
cancel(myError)
ctx.Err() // returns context.Canceled
context.Cause(ctx) // returns myError
AfterFunc函数是一个高级函数,与time.AfterFunc的机制和用法都类似,官方文档中有三个使用AfterFunc的例子,大家可以移步过去看看,这里就不赘述了。
- runtime/trace:收集跟踪信息成本大幅降低
现在,trace在amd64和arm64上收集跟踪信息所需的CPU成本大幅降低:与上一版本相比,最多可提高10倍。
- unicode: 升级到Unicode 15.0.0版本
略。
5. 小结
个人觉得:Go 1.21是一个重要的“大”版本,它对Go语言后续的演进有着重大影响,尤其是对向前兼容和向后兼容的思考和手段的提供,为后续Go演进奠定了基础,即便这些规则读起来和理解起来有些复杂^_^。
本文示例代码可以在这里下载。
6. 参考资料
- Go 1.21 Release Notes – https://go.dev/doc/go1.21
- Go 1.21版本发布 – https://go.dev/blog/go1.21
- Backward Compatibility, Go 1.21, and Go 2 – https://go.dev/blog/compat
- Forward Compatibility and Toolchain Management in Go 1.21 – https://go.dev/blog/toolchain
- Godebug手册 – https://go.dev/doc/godebug
- LoopvarExperiment – https://github.com/golang/go/wiki/LoopvarExperiment
- How Golang Evolves without Breaking Programs – https://thenewstack.io/how-golang-evolves-without-breaking-programs
- PGO user guide – https://go.dev/doc/pgo
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) – https://gopherdaily.tonybai.com
我的联系方式:
- 微博(暂不可用):https://weibo.com/bigwhite20xx
- 微博2:https://weibo.com/u/6484441286
- 博客:tonybai.com
- github: https://github.com/bigwhite
- Gopher Daily归档 – https://github.com/bigwhite/gopherdaily

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。