续接上文。
五、第三步:启动emei、wudang上的apiserver
跨三个node的etcd cluster已经建成并完成了数据同步,下面进行ha cluster改造的重要一步:启动wudang、emei上的apiserver
1、启动emei、wudang上的apiserver
以shaolin node上的/etc/kubernetes/manifests/kube-apiserver.yaml为副本,制作emei、wudang上的kube-apiserver.yaml:
唯一需要变动的就是- --advertise-address这个option的值:
wudang:
- --advertise-address=10.24.138.208
emei:
- --advertise-address=10.27.52.72
在各自node上将kube-apiserver.yaml放入/etc/kubernetes/manifests中,各自node上的kubelet将会启动kube-apiserver并且各个apiserver默认连接本节点的etcd:
root@emei:~# pods
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
... ...
kube-system kube-apiserver-emei 1/1 Running 0 1d 10.27.52.72 emei
kube-system kube-apiserver-shaolin 1/1 Running 0 1d 10.27.53.32 shaolin
kube-system kube-apiserver-wudang 1/1 Running 0 2d 10.24.138.208 wudang
2、将emei、wudang上的kubelet改为连接自己所在节点的apiserver
所有apiserver都启动了。wudang、emei上的kubelet也应该连接自己节点的apiserver了!修改各自的/etc/kubernetes/kubelet.conf,修改server配置项:
wudang:
server: https://10.24.138.208:6443
emei:
server: https://10.27.52.72:6443
各自重启kubelet:
以wudang为例:
root@wudang:~# systemctl daemon-reload
root@wudang:~# systemctl restart kubelet
不过,问题出现了!查看重启的kubelet日志:
root@wudang:~# journalctl -u kubelet -f
-- Logs begin at Mon 2017-05-08 15:12:01 CST. --
May 11 14:33:27 wudang kubelet[8794]: I0511 14:33:27.919223 8794 kubelet_node_status.go:230] Setting node annotation to enable volume controller attach/detach
May 11 14:33:27 wudang kubelet[8794]: I0511 14:33:27.921166 8794 kubelet_node_status.go:77] Attempting to register node wudang
May 11 14:33:27 wudang kubelet[8794]: E0511 14:33:27.926865 8794 kubelet_node_status.go:101] Unable to register node "wudang" with API server: Post https://10.24.138.208:6443/api/v1/nodes: x509: certificate is valid for 10.96.0.1, 10.27.53.32, not 10.24.138.208
May 11 14:33:28 wudang kubelet[8794]: E0511 14:33:28.283258 8794 event.go:208] Unable to write event: 'Post https://10.24.138.208:6443/api/v1/namespaces/default/events: x509: certificate is valid for 10.96.0.1, 10.27.53.32, not 10.24.138.208' (may retry after sleeping)
May 11 14:33:28 wudang kubelet[8794]: E0511 14:33:28.499209 8794 reflector.go:190] k8s.io/kubernetes/pkg/kubelet/kubelet.go:390: Failed to list *v1.Node: Get https://10.24.138.208:6443/api/v1/nodes?fieldSelector=metadata.name%3Dwudang&resourceVersion=0: x509: certificate is valid for 10.96.0.1, 10.27.53.32, not 10.24.138.208
May 11 14:33:28 wudang kubelet[8794]: E0511 14:33:28.504593 8794 reflector.go:190] k8s.io/kubernetes/pkg/kubelet/config/apiserver.go:46: Failed to list *v1.Pod: Get https://10.24.138.208:6443/api/v1/pods?fieldSelector=spec.nodeName%3Dwudang&resourceVersion=0: x509: certificate is valid for 10.96.0.1, 10.27.53.32, not 10.24.138.208
从错误日志判断来看,似乎是wudang上的kubelet在与同一节点上的kube-apiserver通信过程中,发现这个apiserver返回的tls证书是属于10.27.53.32的,即shaolin node上的apiserver的,而不是wudang node上的apiserver的,于是报了错!问题的原因很明了,因为Wudang上的kube-apiserver用的apiserver.crt的确是从shaolin node上copy过来的。也就是说要解决这个问题,我们需要为wudang、emei两个node上的apiserver各自生成自己的数字证书。
我们先来查看一下shaolin上的apiserver.crt内容是什么样子的:
root@shaolin:/etc/kubernetes/pki# openssl x509 -noout -text -in apiserver.crt
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes
Subject: CN=kube-apiserver
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication
X509v3 Subject Alternative Name:
DNS:shaolin, DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, IP Address:10.96.0.1, IP Address:10.27.53.32
我们看到证书使用到了x509v3的扩展功能:subject alternative name,并且指定了多个value。我们为wudang、emei生成的apiserver.crt也应该如此。如何做呢?好在我们有整个集群的ca.key和ca.crt,可以用来签署证书请求。以wudang node为例,我们来为wudang node上的apiserver生成apiserver-wudang.key和apiserver-wudang.crt:
//生成2048位的密钥对
root@wudang:~# openssl genrsa -out apiserver-wudang.key 2048
//生成证书签署请求文件
root@wudang:~# openssl req -new -key apiserver-wudang.key -subj "/CN=kube-apiserver," -out apiserver-wudang.csr
// 编辑apiserver-wudang.ext文件,内容如下:
subjectAltName = DNS:wudang,DNS:kubernetes,DNS:kubernetes.default,DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, IP:10.96.0.1, IP:10.24.138.208
// 使用ca.key和ca.crt签署上述请求
root@wudang:~# openssl x509 -req -in apiserver-wudang.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out apiserver-wudang.key.crt -days 365 -extfile apiserver-wudang.ext
Signature ok
subject=/CN=10.24.138.208
Getting CA Private Key
//查看新生成的证书:
root@wudang:~# openssl x509 -noout -text -in apiserver-wudang.crt
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 16019625340257831745 (0xde51245f10ea0b41)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN=kubernetes
Validity
Not Before: May 12 08:40:40 2017 GMT
Not After : May 12 08:40:40 2018 GMT
Subject: CN=kube-apiserver,
Subject Public Key Info:
... ...
X509v3 extensions:
X509v3 Subject Alternative Name:
DNS:wudang, DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, IP Address:10.96.0.1, IP Address:10.24.138.208
将apiserver-wudang.key和apiserver-wudang.crt放入/etc/kubernetes/pki目录下,修改kube-apiserver.yaml文件:
// /etc/kubernetes/pki
- --tls-cert-file=/etc/kubernetes/pki/apiserver-wudang.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver-wudang.key
kube-apiserver重启后,再来查看kubelet日志,你会发现kubelet运行一切ok了。emei节点也要进行同样的操作。
至此,整个集群的状态示意图如下:
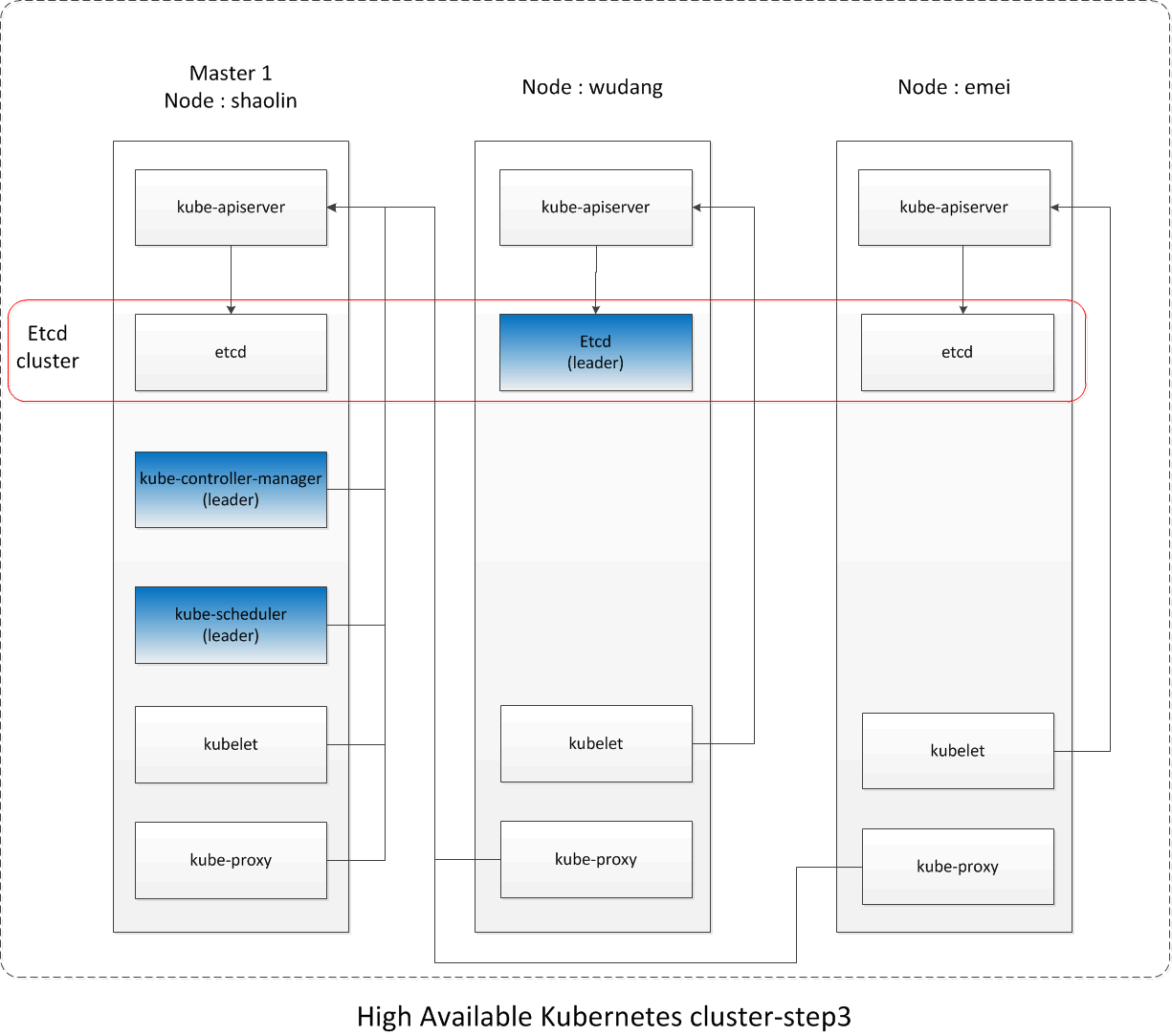
六、第四步:启动emei、wudang上的kube-controller-manager和kube-scheduler
这一步我们只需要将shaolin node上的/etc/kubernetes/manifests中的kube-controller-manager.yaml和kube-scheduler.yaml拷贝到wudang、emei两个node的相应目录下即可:
root@emei:~/kubernetes-conf-shaolin/manifests# pods
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
... ...
kube-system kube-controller-manager-emei 1/1 Running 0 8s 10.27.52.72 emei
kube-system kube-controller-manager-shaolin 1/1 Running 3 1d 10.27.53.32 shaolin
kube-system kube-controller-manager-wudang 1/1 Running 0 1m 10.24.138.208 wudang
... ...
kube-system kube-scheduler-emei 1/1 Running 0 15s 10.27.52.72 emei
kube-system kube-scheduler-shaolin 1/1 Running 3 1d 10.27.53.32 shaolin
kube-system kube-scheduler-wudang 1/1 Running 0 3m 10.24.138.208 wudang
... ...
查看一下各个node下kcm和scheduler的日志:
root@wudang:~/demo# kubectl logs -f kube-controller-manager-emei -n kube-system
I0511 07:34:53.804831 1 leaderelection.go:179] attempting to acquire leader lease...
root@wudang:~/demo# kubectl logs -f kube-controller-manager-wudang -n kube-system
I0511 07:33:20.725669 1 leaderelection.go:179] attempting to acquire leader lease...
root@wudang:~/demo# kubectl logs -f kube-scheduler-emei -n kube-system
I0511 07:34:45.711032 1 leaderelection.go:179] attempting to acquire leader lease...
root@wudang:~/demo# kubectl logs -f kube-scheduler-wudang -n kube-system
I0511 07:31:35.077090 1 leaderelection.go:179] attempting to acquire leader lease...
root@wudang:~/demo# kubectl logs -f kube-scheduler-shaolin -n kube-system
I0512 08:55:30.838806 1 event.go:217] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"my-nginx-2267614806-v1dst", UID:"c075c6c7-36f0-11e7-9c66-00163e000c7f", APIVersion:"v1", ResourceVersion:"166279", FieldPath:""}): type: 'Normal' reason: 'Scheduled' Successfully assigned my-nginx-2267614806-v1dst to emei
I0512 08:55:30.843104 1 event.go:217] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"my-nginx-2267614806-drnzv", UID:"c075da9f-36f0-11e7-9c66-00163e000c7f", APIVersion:"v1", ResourceVersion:"166278", FieldPath:""}): type: 'Normal' reason: 'Scheduled' Successfully assigned my-nginx-2267614806-drnzv to wudang
I0512 09:13:21.121864 1 event.go:217] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"my-nginx-2267614806-ld1dr", UID:"3e73d350-36f3-11e7-9c66-00163e000c7f", APIVersion:"v1", ResourceVersion:"168070", FieldPath:""}): type: 'Normal' reason: 'Scheduled' Successfully assigned my-nginx-2267614806-ld1dr to wudang
I0512 09:13:21.124295 1 event.go:217] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"my-nginx-2267614806-cmmkh", UID:"3e73c8b2-36f3-11e7-9c66-00163e000c7f", APIVersion:"v1", ResourceVersion:"168071", FieldPath:""}): type: 'Normal' reason: 'Scheduled' Successfully assigned my-nginx-2267614806-cmmkh to emei
可以看出,当前shaolin node上的kcm和scheduler是leader。
至此,整个集群的状态示意图如下:
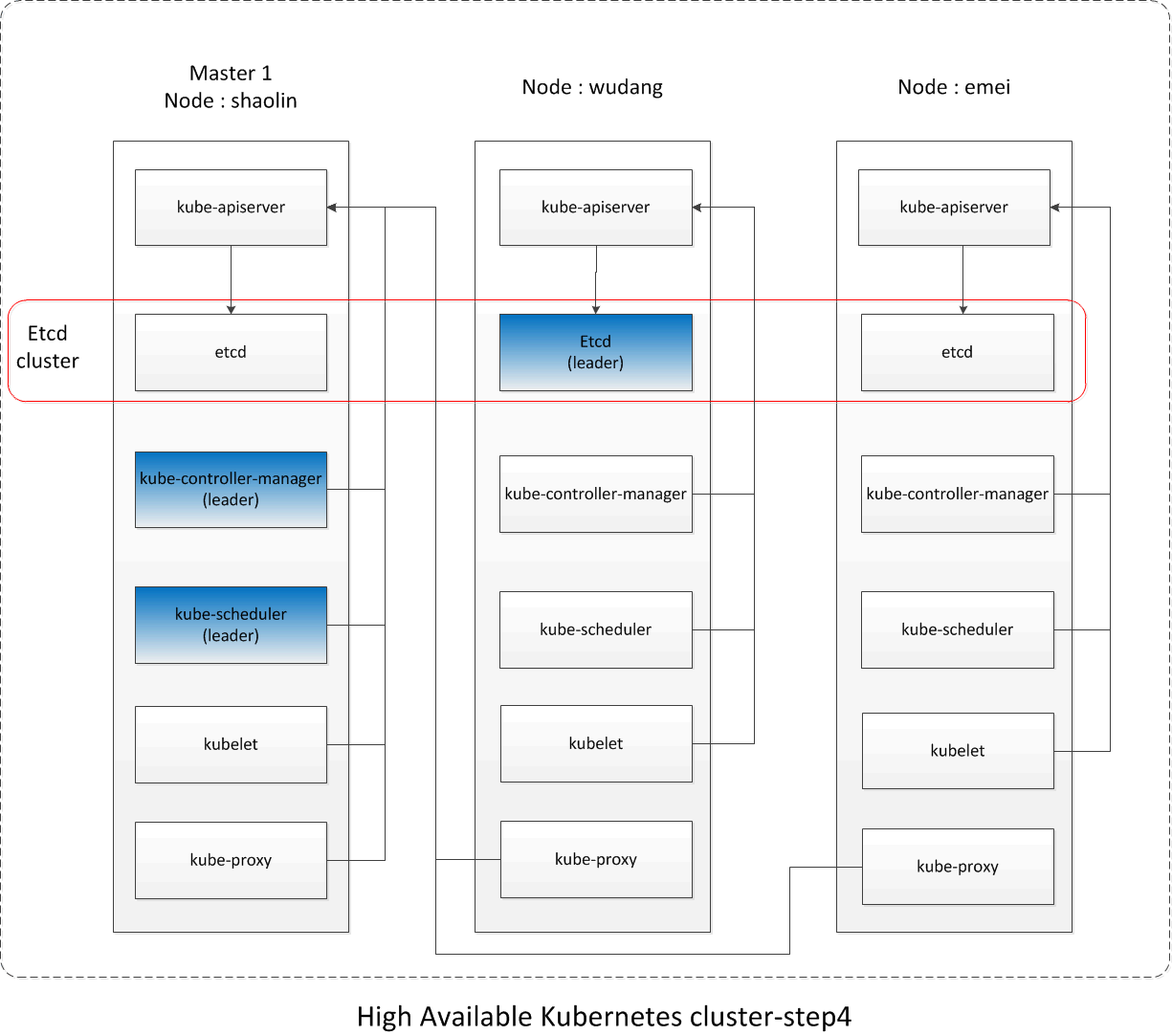
六、第五步:将wudang、emei设置为master node
我们试着在wudang节点上创建一个pod:
// run-my-nginx.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx:1.10.1
ports:
- containerPort: 80
发现pod居然被调度到了wudang、emei节点上了!
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default my-nginx-2267614806-drnzv 1/1 Running 0 5s 172.32.192.1 wudang
default my-nginx-2267614806-v1dst 1/1 Running 0 5s 172.32.64.0 emei
emei、wudang并没有执行taint,为何能承载workload? 查看当前cluster的node状态:
root@wudang:~# kubectl get node --show-labels
NAME STATUS AGE VERSION LABELS
emei Ready 1d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=emei
shaolin Ready 2d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=shaolin,node-role.kubernetes.io/master=
wudang Ready 1d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=wudang
从label看到,status列并没有明确输出谁是master,这和1.5.1版本以前似乎不同。emei、wudang与shaolin唯一的不同就是shaolin有一个key: node-role.kubernetes.io/master。难道这个label是指示谁是master的?我们给wudang打上这个label:
root@wudang:~/demo# kubectl label node wudang node-role.kubernetes.io/master=
node "wudang" labeled
root@wudang:~/demo# kubectl get node --show-labels
NAME STATUS AGE VERSION LABELS
emei Ready 1d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=emei
shaolin Ready 2d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=shaolin,node-role.kubernetes.io/master=
wudang Ready 1d v1.6.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=wudang,node-role.kubernetes.io/master=
再创建nginx pod,我们发现pod依旧分配在wudang、emei两个node上:
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default my-nginx-2267614806-cmmkh 1/1 Running 0 5s 172.32.64.0 emei
default my-nginx-2267614806-ld1dr 1/1 Running 0 5s 172.32.192.1 wudang
我们进一步查看并对比相关信息:
查看clustre-info:
wuddang node:
root@wudang:~/demo# kubectl cluster-info
Kubernetes master is running at https://10.24.138.208:6443 //wudang node:
KubeDNS is running at https://10.24.138.208:6443/api/v1/proxy/namespaces/kube-system/services/kube-dns
shaolin node:
root@shaolin:~/k8s-install/demo# kubectl cluster-info
Kubernetes master is running at https://10.27.53.32:6443
KubeDNS is running at https://10.27.53.32:6443/api/v1/proxy/namespaces/kube-system/services/kube-dns
查看详细node信息:
root@wudang:~# kubectl describe node/shaolin
Name: shaolin
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=shaolin
node-role.kubernetes.io/master=
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
Taints: node-role.kubernetes.io/master:NoSchedule
root@wudang:~# kubectl describe node/wudang
Name: wudang
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=wudang
node-role.kubernetes.io/master=
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
Taints: <none>
我们看到,在Taints属性里,shaolin node的值为 node-role.kubernetes.io/master:NoSchedule,而wudang node的为空。初步猜测这就是wudang被分配pod的原因了。
我们设置wudang node的Taints属性:
root@wudang:~# kubectl taint nodes wudang node-role.kubernetes.io/master=:NoSchedule
node "wudang" tainted
root@wudang:~# kubectl describe node/wudang|more
Name: wudang
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=wudang
node-role.kubernetes.io/master=
Annotations: node.alpha.kubernetes.io/ttl=0
volumes.kubernetes.io/controller-managed-attach-detach=true
Taints: node-role.kubernetes.io/master:NoSchedule
再创建nginx deployment:
root@wudang:~/demo# pods
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default my-nginx-2267614806-hmz5d 1/1 Running 0 14s 172.32.64.0 emei
default my-nginx-2267614806-kkt79 1/1 Running 0 14s 172.32.64.1 emei
发现pod全部分配到emei上了!
接下来按同样操作对emei的taints属性进行设置,这里就不赘述了。
到目前为止,整个k8s cluster的状态如下示意图:
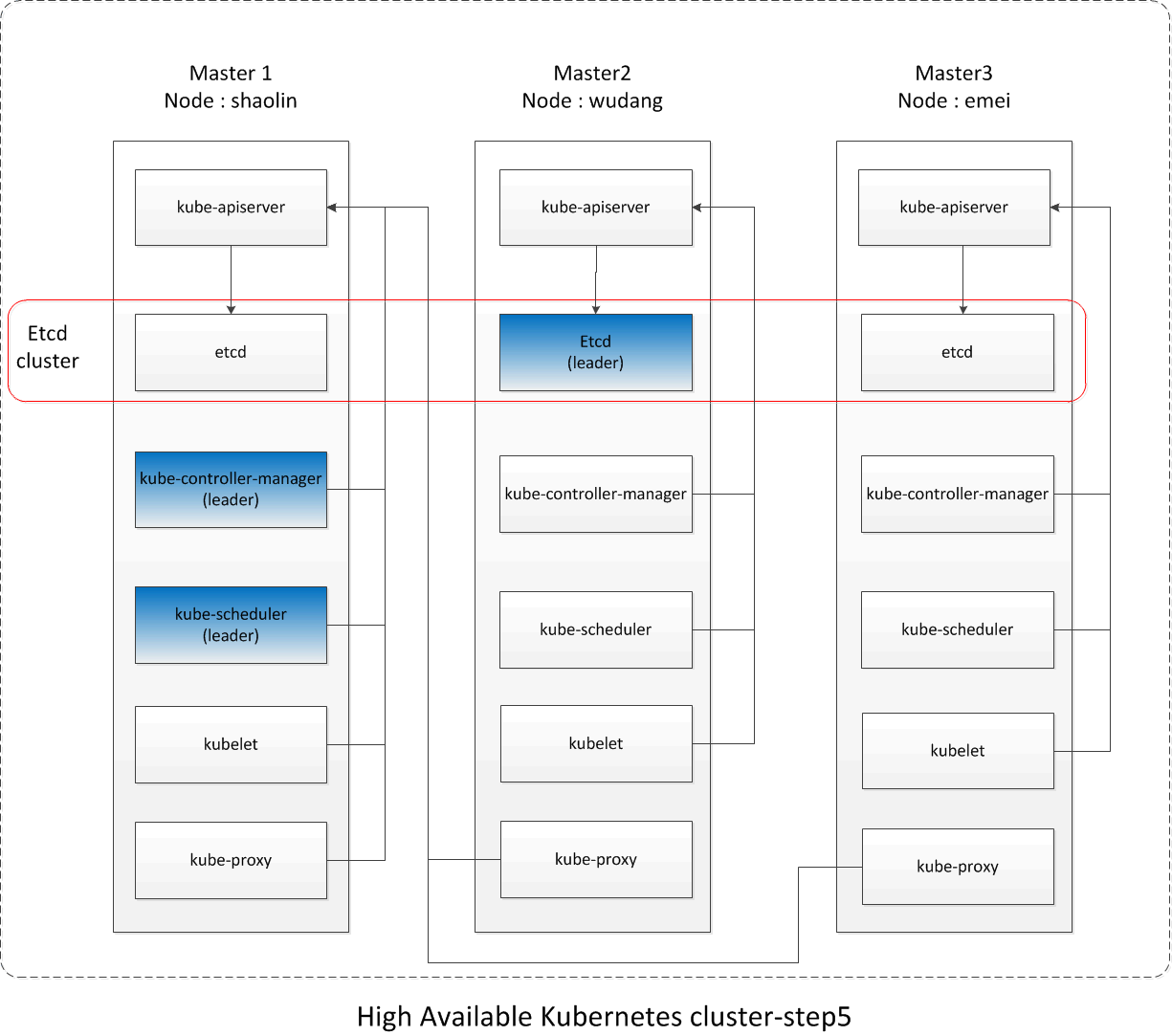
七、第六步:Load Balance
Kubernetes HA cluster的建立得益于kube-apiserver的无状态,按照最终目标,在三个kube-apiserver的前面是要假设一个负载均衡器的。考虑到apiserver对外通过https暴露服务,在七层做lb需要将证书配置在lb上,这改动较大;这里我们用四层lb。在这里,我们仅是搭建一个简易的demo性质的基于nginx的四层lb,在生产环境,如果你有硬件lb或者你所在的cloud provider提供类似lb服务,可以直接使用。
演示方便起见,我直接在emei上安装一个nginx(注意一定要安装支持–with-stream支持的nginx,可以通过-V查看):
root@emei:~# nginx -V
nginx version: nginx/1.10.3 (Ubuntu)
built with OpenSSL 1.0.2g 1 Mar 2016
TLS SNI support enabled
configure arguments: --with-cc-opt='-g -O2 -fPIE -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-Bsymbolic-functions -fPIE -pie -Wl,-z,relro -Wl,-z,now' --prefix=/usr/share/nginx --conf-path=/etc/nginx/nginx.conf --http-log-path=/var/log/nginx/access.log --error-log-path=/var/log/nginx/error.log --lock-path=/var/lock/nginx.lock --pid-path=/run/nginx.pid --http-client-body-temp-path=/var/lib/nginx/body --http-fastcgi-temp-path=/var/lib/nginx/fastcgi --http-proxy-temp-path=/var/lib/nginx/proxy --http-scgi-temp-path=/var/lib/nginx/scgi --http-uwsgi-temp-path=/var/lib/nginx/uwsgi --with-debug --with-pcre-jit --with-ipv6 --with-http_ssl_module --with-http_stub_status_module --with-http_realip_module --with-http_auth_request_module --with-http_addition_module --with-http_dav_module --with-http_geoip_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_image_filter_module --with-http_v2_module --with-http_sub_module --with-http_xslt_module --with-stream --with-stream_ssl_module --with-mail --with-mail_ssl_module --with-threads
我这里直接修改nginx的默认配置文件:/etc/nginx/nginx.conf,添加如下配置:
// /etc/nginx/nginx.conf
... ...
stream {
upstream apiserver {
server 10.27.53.32:6443 weight=5 max_fails=3 fail_timeout=30s;
server 10.24.138.208:6443 weight=5 max_fails=3 fail_timeout=30s;
server 10.27.52.72:6443 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 8443;
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass apiserver;
}
}
... ...
nginx -s reload后,配置生效!
我们用wudang上的kubectl来访问一下lb,我们先来做一下配置
root@wudang:~# cp /etc/kubernetes/admin.conf ./
root@wudang:~# mv admin.conf admin-lb.conf
root@wudang:~# vi admin-lb.conf
修改admin-lb.conf中的:
server: https://10.27.52.72:8443
export KUBECONFIG=~/admin-lb.conf
执行下面命令:
root@wudang:~# kubectl get pods -n kube-system
Unable to connect to the server: x509: certificate is valid for 10.96.0.1, 10.27.53.32, not 10.27.52.72
root@wudang:~# kubectl get pods -n kube-system
Unable to connect to the server: x509: certificate is valid for 10.24.138.208, not 10.27.52.72
可以看到上述两个请求被lb分别转到了shaolin和wudang两个node的apiserver上,客户端在校验server端发送的证书时认为server端”有诈“,于是报了错!怎么解决呢?在上面我们为每个apiserver生成apiserver.crt时,我们在subject alternative name值中填写了多个域名,我们用域名来作为client端访问的目的地址,再来看看:
修改~/admin-lb.conf中的:
server: https://kubernetes.default.svc:8443
在wudang node的/etc/hosts中添加:
10.27.52.72 kubernetes.default.svc
再访问集群:
root@wudang:~# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
etcd-emei 1/1 Running 0 1d
etcd-shaolin 1/1 Running 0 1d
etcd-wudang 1/1 Running 0 4d
kube-apiserver-emei 1/1 Running 0 1d
... ...
这里只是一个demo,在您自己的环境里如何将lb与apiserver配合在一起,方法有很多种,需要根据实际情况具体确定。
到目前为止,整个k8s cluster的状态如下示意图:
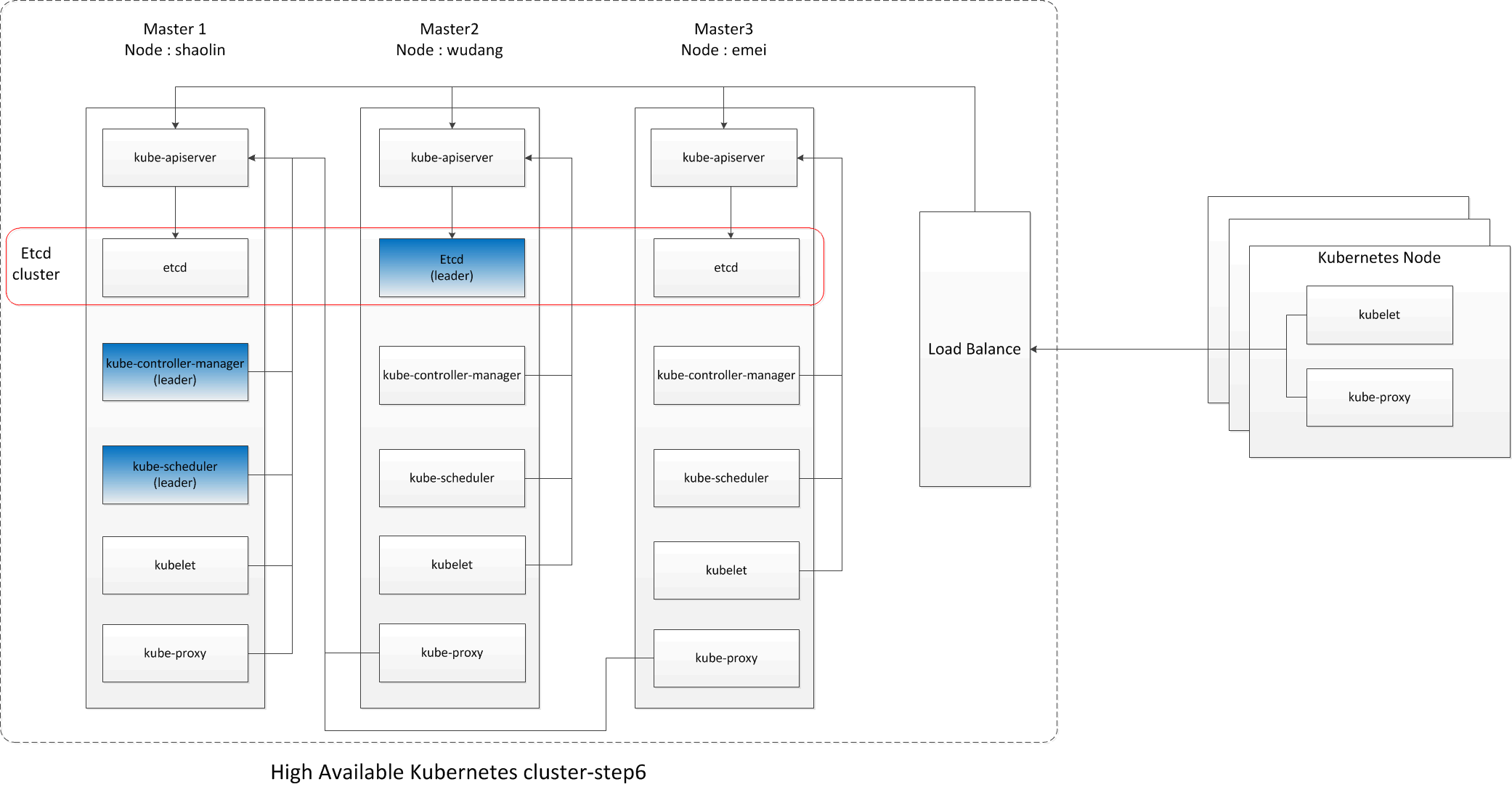
八、第七步:kube-proxy配置修改
kube-proxy是一个由一个daemonset创建的:
root@wudang:~# kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE-SELECTOR AGE
kube-proxy 3 3 3 3 3 <none> 5d
并且kube-proxy的配置是由一个configmap提供的,并未在外部留有修改的口,比如类似kube-scheduler.yaml或.conf那样:
root@shaolin:~# kubectl get configmap -n kube-system
NAME DATA AGE
kube-proxy 1 5d
root@shaolin:~# kubectl get configmap/kube-proxy -n kube-system -o yaml
apiVersion: v1
data:
kubeconfig.conf: |
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://10.27.53.32:6443
name: default
contexts:
- context:
cluster: default
namespace: default
user: default
name: default
current-context: default
users:
- name: default
user:
tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kind: ConfigMap
metadata:
creationTimestamp: 2017-05-10T01:48:28Z
labels:
app: kube-proxy
name: kube-proxy
namespace: kube-system
resourceVersion: "81"
selfLink: /api/v1/namespaces/kube-system/configmaps/kube-proxy
uid: c34f7d5f-3522-11e7-8f77-00163e000c7f
在这个默认的configmap中,kube-proxy连接的cluster的server地址硬编码为 https://10.27.53.32:6443,即shaolin node上apiserver的公共接口地址。这样一旦shaolin node宕掉了,其他node上的kube-proxy将无法连接到apiserver进行正常操作。而kube-proxy pod自身又是使用的是host network,因此我们需要将server地址配置为lb的地址,这样保证各node上kube-proxy的高可用。
我们根据上述输出的configmap的内容进行修改,并更新kube-proxy-configmap的内容:
root@shaolin:~# kubectl get configmap/kube-proxy -n kube-system -o yaml > kube-proxy-configmap.yaml
修改kube-proxy-configmap.yaml中的server为:
server: https://kubernetes.default.svc:6443
保存并更新configmap: kube-proxy:
root@shaolin:~# kubectl apply -f kube-proxy-configmap.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
configmap "kube-proxy" configured
root@shaolin:~# kubectl get configmap/kube-proxy -n kube-system -o yaml
apiVersion: v1
data:
kubeconfig.conf: |
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://kubernetes.default.svc:6443
name: default
... ...
重启kube-proxy(kubectl delete pods/kube-proxy-xxx -n kube-system)后,查看kube-proxy的日志:
root@shaolin:~# kubectl logs -f kube-proxy-h5sg8 -n kube-system
I0515 13:57:03.526032 1 server.go:225] Using iptables Proxier.
W0515 13:57:03.621532 1 proxier.go:298] clusterCIDR not specified, unable to distinguish between internal and external traffic
I0515 13:57:03.621578 1 server.go:249] Tearing down userspace rules.
I0515 13:57:03.738015 1 conntrack.go:81] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072
I0515 13:57:03.741824 1 conntrack.go:66] Setting conntrack hashsize to 32768
I0515 13:57:03.742555 1 conntrack.go:81] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_established' to 86400
I0515 13:57:03.742731 1 conntrack.go:81] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_close_wait' to 3600
九、小结
到这里,我们在第一部分中的最终思路方案已经实现了。不过这两篇文章对kubernetes ha cluster的打造还仅限于探索阶段,可能还有一些深层次的问题没有暴露出来,因此不建议在生产环境中采用。kubeadm在后续的版本中必然加入对k8s ha cluster的支持,那个时候,搭建一套可用于生产环境的HA cluster将不再这么麻烦了!