
本文永久链接 – https://tonybai.com/2024/06/24/range-over-func-and-package-iter-in-go-1-23
在《Go 1.23新特性前瞻》一文中,我们提到了Go 1.23中增加的一个主要的语法特性就是支持了用户自定义iterator,即range over func试验特性的正式转正。为此,Go 1.23还在标准库中增加了iter包,这个包对什么是Go自定义iterator做了诠释:
An iterator is a function that passes successive elements of a sequence to a callback function, conventionally named yield. The function stops either when the sequence is finished or when yield returns false, indicating to stop the iteration early.
迭代器是一个函数,它将一个序列中的连续元素传递给一个回调函数,通常称为"yield"。迭代器函数会在序列结束或者yield回调函数返回false(表示提前停止迭代)时停止。
除此之外,iter包还定义了标准的iterator泛型类型、给出了有关iterator的命名惯例以及在迭代中修改序列中元素的方法等,这些我们稍后会细说。
不过就在Go 1.23还有两个月就要发布之际,Go社区却出现了对Go iterator的质疑之声。
先是知名开源项目fasthttp作者、时序数据库VictoriaMetrics贡献者Aliaksandr Valialkin撰文谈及Go iterator引入给Go带来复杂性的同时,还破坏了Go的显式哲学,并且并未真的带来额外的好处,甚至觉得Go正朝着错误的方向演进,希望Go团队能revert Go 1.23中与iterator有关的代码。
注:第319期GoTime播客也在聊“Is Go evolving in the wrong direction?”这个话题,感兴趣的Gopher可以听一下。
之后,Odin语言的设计者站在局外人的角度,从语言设计层面谈到了为什么人们憎恨Go 1.23的iterator,该文章更是在Hacker News上引发热议。
那么到底Go 1.23中的自定义iterator和iter包带给Go社区的是强大的功能特性和表达力的提升,还是花哨不实用的复杂性呢?这里我也不好轻易下结论,我打算通过这篇文章,和大家一起全面地认识一下Go iterator。最终对iterator的是非曲直的判断还是由各位读者自行得出。
1. 开端
能找到的与最终Go iterator相关的最早的issue来自Go团队成员Michael Knyszek在2021年发起的issue:Proposal: Function values as iterators。
之后,2022年8月,Ian Lance Taylor发起了名为“standard iterator interface”的discussion作为Michael Knyszek发起的issue的后续。
最后,Go团队技术负责人Russ Cox在2022年10月份发起了针对iterator的最后一次讨论,在这次讨论中,Go团队初步完成了iterator的设计思路。此外,在该讨论的开场白处,Russ Cox还概述了Go为什么要增加对用户自定义iterator的支持:

总结下来就是Russ发现Go标准库中有很多库(如上截图)中都有迭代器的实现,但形式不统一,没有标准的“实现路径”,各自为战。这与Go面向工程的目标有悖,现状阻碍了大型Go代码库中的代码迁移。因此,Go团队希望给大家带来一致的迭代器形式,具体来说就是允许for range支持对一定类型函数值(function value)进行迭代,即range over func。
2024年2月,iterator以试验特性被Go 1.22版本引入,通过GOEXPERIMENT=rangefunc可以开启range-over-func特性以及使用iter包。
在golang.org/x/exp下面,Go团队还提议维护一个xiter包,这个包内提供了用于组合iterator的基本适配器(adapter),不过目前该xiter包依旧处于proposal状态,尚未落地。
2024年8月,iterator将伴随Go 1.23版本正式落地,现在我们可以通过Go playground在线体验iterator,当然你也可以安装Go tip版本或Go 1.23的rc版在本地体验。
注:关于Go tip的安装方法以及Go playground在线体验的详细说明,这里就不赘述了,《Go语言第一课》专栏的“03|配好环境:选择一种最适合你的Go安装方法”有系统全面的讲解,欢迎订阅阅读。
2. 形式
在Go tip版的Go spec中,我们可以看到下面for range的语法形式,其中下面红框中的三行是for range接自定义iterator的形式:
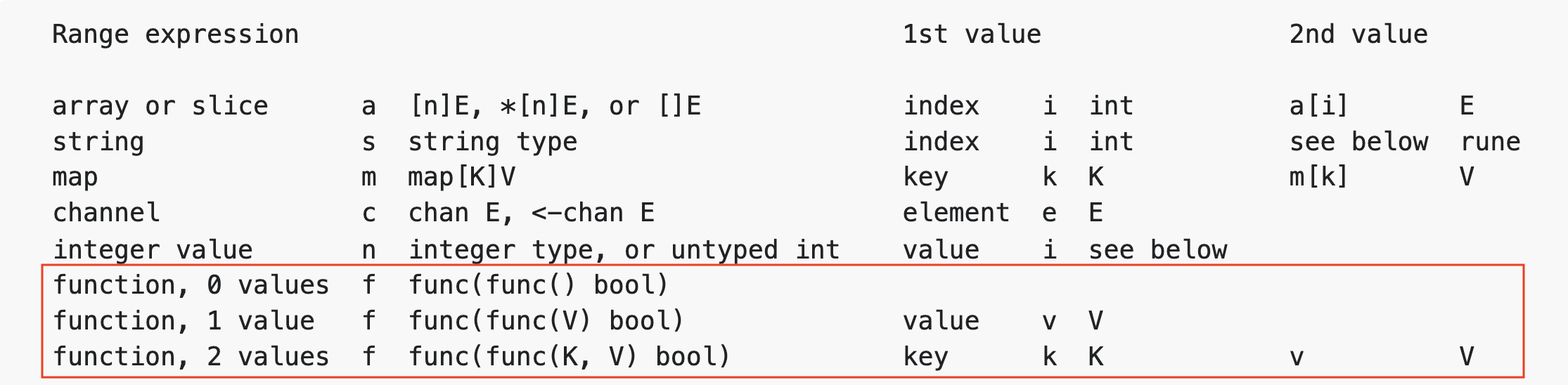
如果f是一个自定义迭代器,那么上图中红框中的三种情况分别对应的是下面的三类for range语句形式:
第一类:function, 0 values, f的签名为func(func() bool)
for range f { ... }
第二类:function, 1 value,f的签名为func(func(V) bool)
for x := range f { ... }
第三类:function, 2 values,f的签名为func(func(K, V) bool)
for x, y := range f { ... }
for x, _ := range f { ... }
for _, y := range f { ... }
我们可以看一个实际的应用上述三类迭代器的示例:
// go-iterator/iterator_spec.go
// https://go.dev/play/p/ffxygzIdmCB?v=gotip
package main
import (
"fmt"
"slices"
)
type Seq0 func(yield func() bool)
func iter0[Slice ~[]E, E any](s Slice) Seq0 {
return func(yield func() bool) {
for range s {
if !yield() {
return
}
}
}
}
var sl = []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
func main() {
// 1. for range f {...}
count := 0
for range iter0(sl) {
count++
}
fmt.Printf("total count = %d ", count)
fmt.Printf("\n\n")
// 2. for x := range f {...}
fmt.Println("all values:")
for v := range slices.Values(sl) {
fmt.Printf("%d ", v)
}
fmt.Printf("\n\n")
// 3. for x, y := range f{...}
fmt.Println("backward values:")
for _, v := range slices.Backward(sl) {
fmt.Printf("%d ", v)
}
}
在这个示例中,我在slices包中找到了Values和Backward两个函数,它们分别返回的是第二类和第三类的迭代器。针对第一类迭代器,在Russ Cox最初的设计中是有对应的,即一个名为Seq0的类型,但后续在iter包中,该类型并未落地。于是我们在上面示例中自己定义了这个类型,并定义了一个iter0的函数用于返回Seq0类型的迭代器。不过实际想来,使用到Seq0这个形式的迭代器的场景似乎极少。
运行上述示例,我们将得到如下结果:
total count = 9
all values:
1 2 3 4 5 6 7 8 9
backward values:
9 8 7 6 5 4 3 2 1
我们看到,在使用层面,通过for range+函数iterator来迭代像切片这样的集合类型中的元素还是蛮简单的,并且该方案并未引入新关键字或预定义标识符(像any、new这种)。
不过,在这样简洁的使用界面之下,for range对Go迭代器的支持究竟是如何实现的呢?接下来,我们就来简单看看其实现原理。
3. 原理
在《Go语言精进之路vol1》一书中,我曾引述了Go语言之父Rob Pike的一句话:“Go语言实际上是复杂的,但只是让大家感觉很简单”。Go iterator也是这样,“简单”外表的背后是Go语言自身实现层面的复杂,而这些复杂性被Go语言的设计者“隐藏”起来了。或者说,Go团队把复杂性留给了语言自身的设计和实现,留给了Go团队自身。
3.1 自定义迭代器、yield函数与迭代器创建API
下面我们先以slices的Backward函数为例,用下图说明一下自定义迭代器从实现到使用过程中涉及的各个方面:
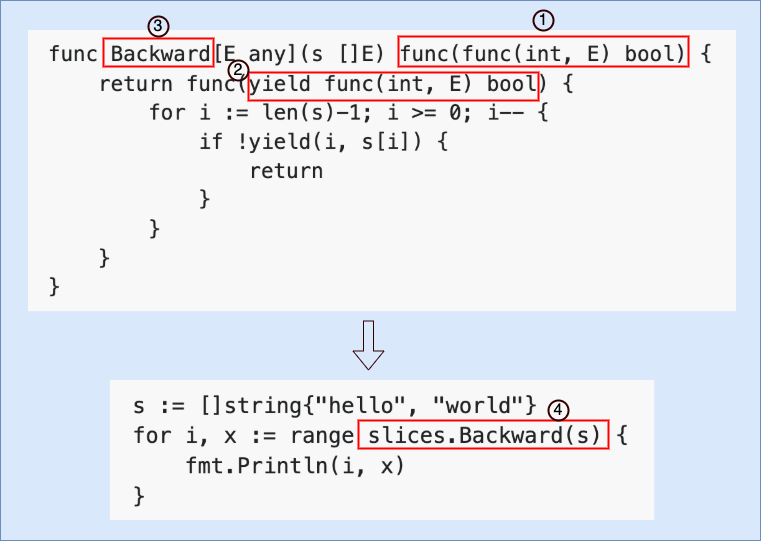
我们先来看上图中最下面for range与函数结合一起使用的代码,这里的红框④中的函数slices.Backward并非是iterator,而是slices包中的一个创建iterator的API函数。
Backward函数的实现在图的上方红框③,这是一个泛型函数,它的返回值也是一个函数,这个函数类型就是Go支持的自定义迭代器的类型之一。在iter包中,我们可以找到Go支持的两种函数迭代器类型,再加上上面定义的Seq0,这里完整地列一下:
// $GOROOT/src/iter/iter.go
type Seq[V any] func(yield func(V) bool)
type Seq2[K, V any] func(yield func(K, V) bool)
// 自定义的Seq0
type Seq0 func(yield func() bool)
也就是说只有符合上述函数签名的函数类型才是可以被for range支持的iterator。即所谓自定义iterator,本质上就是一个接受一个函数类型参数的函数(如上图中红框①),按惯例,这个函数类型的参数被命名为yield(见红框②)。从Backward函数的返回值(一个iterator)的实现来看,当yield函数返回false时,迭代结束;否则迭代继续进行,直到集合类型(如slice)中所有元素都被遍历完。
到这里,你可能依旧一头雾水。slices.Backward返回的是一个函数(即iterator),这个iterator函数也没有返回值啊,怎么就能在每轮迭代时向for range返回一个或两个值呢?
我们继续来看range over func和Go iterator的实现原理。
3.2 代码转换
其实,for range+自定义iterator可以看成是Go提供的又一个“语法糖”,它是通过Go编译器在编译阶段的代码转换来实现的。下面我们还基于Backward那个例子来看看这个转换过程:

通过这个例子,我们看到for range body中的逻辑被转换为了传给iterator函数的yield函数的实现了。相对于for range body,yield函数实现中多了一个return true。根据前面的说明,在iterator的实现逻辑中,当yield返回true,迭代会继续进行。在上图中,for range会遍历所有切片元素,所以yield始终返回true。
下面我们再看一个带有break的for range语句转换为yield函数的实现后是什么样子的:
s := []string{"hello", "world", "golang", "rust", "java"}
for i, x := range slices.Backward(s) {
fmt.Println(i, x)
if i == 3 {
break
}
}
Go编译器将上述代码转换为类似下面的代码:
slices.Backward(s)(func(#p1 int, #p2 string) bool {
i, x := #p1, #p2
fmt.Println(i, x)
if i == 3 {
return false
}
return true
})
我们看到原for range代码中的break语句将终止循环的运行,那么转换为yield函数后,就相当于yield返回false。
如果for range中有return语句呢?Go编译器会如何转换for range代码呢?我们看下面原始代码:
s := []string{"hello", "world", "golang", "rust", "java"}
for i, x := range slices.Backward(s) {
fmt.Println(i, x)
if i == 3 {
return
}
}
Go编译器会将上述代码转换为类似下面的代码:
{
var #next int
slices.Backward(s)(func(#p1 int, #p2 string) bool {
i, x := #p1, #p2
fmt.Println(i, x)
if i == 3 {
#next = -1
return false
}
return true
})
if #next == -1 {
return
}
}
我们看到由于yield函数只是传给iterator的输入参数,它的返回不会影响外层函数的返回,于是转换后的代码会设置一个标志变量(这里为#next),对于有return的for range,会在yield函数中设置该变量的值,然后在Backward调用之后,再次检查一下该变量以决定是否调用return从函数中返回。
如果for range的body中有defer调用,那么Go编译器会如何做代码转换呢?我们看下面示例:
s := []string{"hello", "world"}
for i, x := range slices.Backward(s) {
defer println(i, x)
}
我们知道defer的语义是在函数return之后按“先进后出”的次序执行,那么直接将上述代码转换为如下代码是否ok呢?
slices.Backward(s)(func(#p1 int, #p2 string) bool {
i, x := #p1, #p2
defer println(i, x)
})
这显然不行!这样转换后的代码,deferred function会在每次yield函数执行完就执行了,而不是在for range所在的函数返回前执行!为此,Go团队在runtime层增加了一个deferprocat函数,用于代码转换后的deferred函数执行。上面的示例将被Go编译器转换为类似下面的代码:
var #defers = runtime.deferrangefunc()
slices.Backward(s)(func(#p1 int, #p2 string) bool {
i, x := #p1, #p2
runtime.deferprocat(func() { println(i, x) }, #defers)
})
到这里,我们所举的代码示例其实都还是比较简单的情况!还有很多复杂的情况,比如break/continue/goto+label的、嵌套loop、loop中代码panic以及iterator自身panic等,想想就复杂。更多复杂的转换代码这里不展开了,展开的也很可能不对,这本来就是编译器的事情,而现在我也拿不到编译器转换代码后的中间输出。要了解转换的复杂逻辑,可以自行阅读Go项目库中的cmd/compile/internal/rangefunc/rewrite.go。
3.3 Push iterator和Pull iterator
前面我们所说的Go标准的自定义iterator在iter包和Go Wiki:Rangefunc Experiment中都被视为Push iterator。这类迭代器的特点是由迭代器自身控制迭代的进度,迭代器负责迭代的逻辑,并会主动将元素推送给yield函数。你回顾一下上面的例子,体会一下是不是这样的。这种迭代器在一些资料里也被称为内部迭代器(internal iterator)。再说的直白一些,Push迭代器更像是“for range loop + 对yield的回调”。Go语言for range后面接的函数迭代器都是这类迭代器。
不过有些时候,在实现迭代器时,通过push迭代器自身控制对容器内元素序列的迭代可能并非是最适合的,而由迭代器实现者控制的、一次获取一个后继元素值的pull函数更适合。并且很显然,这样的pull函数需要在内部维护一个状态。Go 1.23的rc1版在iter包的注释中提到过一个Pairs函数的示例,不过rc1版本中该示例的代码有误,会导致死循环,这个cl fix了这个问题中,但我个人觉得下面的实现似乎更准确:
func Pairs[V any](seq iter.Seq[V]) iter.Seq2[V, V] {
return func(yield func(V, V) bool) {
next, stop := iter.Pull(seq)
defer stop()
for {
v1, ok1 := next()
if !ok1 {
return // 序列结束
}
v2, ok2 := next()
if !ok2 {
// 序列中有奇数个元素,最后一个元素没有配对
return // 序列结束
}
if !yield(v1, v2) {
return // 如果 yield 返回 false,停止迭代
}
}
}
}
我们看到Pairs的实现与之前的Backward函数返回的iterator实现略有不同,这里通过iter.Pull将Pairs传入的push迭代器转换为了Pull迭代器,并通过Pull返回的next和stop来按需控制从容器(Seq)中取数据。这样的连取两个数据的需求在Push iterator中似乎也能实现,但的确没有Pull iterator这么自然!
Pull迭代器是不能直接对接for range的,目前来看iter包提供的Pull和Pull2两个函数更多是用来辅助实现Push iterator的,就像上面的Pairs函数那样。在一些其他语言中,Pull迭代器也被称为外部迭代器(External Iterator),即主动通过迭代器提供的类next方法从中获取数据。
此外要注意的是Pull/Pull2返回的next、stop不能在多个Goroutine中使用。Russ Cox很早就在其个人博客上对Go iterator的实现方式进行了铺垫,他的这篇“Coroutines for Go”对Go各类iterator的实现方式做了早期探讨,感兴趣的童鞋可以移步阅读一下。
3.4 性能考量
很多读者可能和我一样会有关于iterator性能的考量,比较转换后的代码额外地引入了多次函数调用,但按照Go rangefunc experiment wiki中的说法,这种转换后带来的函数调用开销是可以被优化(inline)掉的。
我们来实测一下iterator带来的额外的开销:
// go-iterator/benchmark_iterator_test.go
package main
import (
"slices"
"testing"
)
var sl = []string{"go", "java", "rust", "zig", "python"}
func iterateUsingClassicLoop() {
for i, v := range sl {
_, _ = i, v
}
}
func iterateUsingIterator() {
for i, v := range slices.All(sl) {
_, _ = i, v
}
}
func BenchmarkIterateUsingClassicLoop(b *testing.B) {
for range b.N {
iterateUsingClassicLoop()
}
}
func BenchmarkIterateUsingIterator(b *testing.B) {
for range b.N {
iterateUsingIterator()
}
}
我们对比一下使用传统for range + slice和for range + iterator的benchmark结果(基于go 1.23rc1的编译执行):
$go test -bench . benchmark_iterator_test.go
goos: darwin
goarch: amd64
... ..
BenchmarkIterateUsingClassicLoop-8 429305227 2.806 ns/op
BenchmarkIterateUsingIterator-8 218232373 5.442 ns/op
PASS
ok command-line-arguments 3.239s
我们看到:虽然有优化,但iterator还是带来了一定的开销,这个在性能敏感的系统中还是要考虑iterator带来的开销的。
4. 使用
关于Go iterator的定义与基本使用方法,在前面的说明与示例中我们已经见识过了。最后,我们再说一些有关iterator使用方面的内容。
4.1 “一次性”的iterator
通常iterator创建出来之后是可以重复使用,多次迭代的,比如下面这个示例:
// go-iterator/reuse_iterator.go
// https://go.dev/play/p/gczUIVB8NWd?v=gotip
package main
import (
"fmt"
"slices"
)
func main() {
s := []string{"hello", "world", "golang", "rust", "java"}
itor := slices.Backward(s)
println("first loop:\n")
for i, x := range itor {
fmt.Println(i, x)
if i == 3 {
break
}
}
println("\nsecond loop:\n")
for i, x := range itor {
fmt.Println(i, x)
}
}
运行该示例,我们将得到如下结果:
$go run reuse_iterator.go
first loop:
4 java
3 rust
second loop:
4 java
3 rust
2 golang
1 world
0 hello
我们看到多次对slices.Backward创建的iterator进行迭代,每次iterator都会从切片重新开始,并完整地迭代每个元素。
但也有一些情况建立的迭代器是一次性的,比如迭代读取文件行、从网络读取数据等,这些迭代器往往是有状态的,因此无法从头开始重复使用。我们来看下面这个一次性迭代器:
// go-iterator/single_use_iterator.go
// Lines 返回一个迭代器,用于逐行读取 io.Reader 的内容
func Lines(r io.Reader) func(func(string) bool) {
scanner := bufio.NewScanner(r)
return func(yield func(string) bool) {
for scanner.Scan() {
if !yield(scanner.Text()) {
return
}
}
}
}
func main() {
f, err := os.Open("ref.txt")
if err != nil {
panic(err)
}
defer f.Close()
itor := Lines(f)
println("first loop:\n")
for v := range itor {
fmt.Println(v)
}
println("\nsecond loop:\n")
for v := range itor {
fmt.Println(v)
}
}
Lines函数创建的就是一个从文件读取数据的一次使用的迭代器,代码中曾两次对其进行迭代,我们看看输出结果:
$go run single_use_iterator.go
first loop:
Most iterators provide the ability to walk an entire sequence:
when called, the iterator does any setup necessary to start the
sequence, then calls yield on successive elements of the sequence,
and then cleans up before returning. Calling the iterator again
walks the sequence again.
second loop:
我们看到第一次loop,将文件所有内容都输出了,第二次再使用该迭代器,输出内容为空。对于这样的一次使用的迭代器,你在使用时务必注意:每次需要迭代时,都应该调用Lines函数创建一个新的迭代器。
这种一次性使用的iterator往往都是有状态的,如果第一次loop没有迭代完其数据,后续再次用loop迭代还是可以继续读出其未迭代的数据的,比如下面这个示例:
// go-iterator/continue_use_iterator.go
// Lines 返回一个迭代器,用于逐行读取 io.Reader 的内容
func Lines(r io.Reader) func(func(string) bool) {
scanner := bufio.NewScanner(r)
return func(yield func(string) bool) {
for scanner.Scan() {
if !yield(scanner.Text()) {
return
}
}
}
}
func main() {
f, err := os.Open("ref.txt")
if err != nil {
panic(err)
}
defer f.Close()
itor := Lines(f)
println("first loop:\n")
lineCnt := 0
for v := range itor {
fmt.Println(v)
lineCnt++
if lineCnt >= 2 {
break
}
}
println("\nsecond loop:\n")
for v := range itor {
fmt.Println(v)
}
}
运行该示例,我们将得到如下结果:
$go run continue_use_iterator.go
first loop:
Most iterators provide the ability to walk an entire sequence:
when called, the iterator does any setup necessary to start the
second loop:
sequence, then calls yield on successive elements of the sequence,
and then cleans up before returning. Calling the iterator again
walks the sequence again.
4.2 组合iterator
正在策划但尚未落地的golang.org/x/exp/xiter包中有很多工具函数可以帮我们实现iterator的组合,我们来看一个示例:
// go-iterator/compose_iterator.go
package main
import (
"iter"
"slices"
)
// Filter returns an iterator over seq that only includes
// the values v for which f(v) is true.
func Filter[V any](f func(V) bool, seq iter.Seq[V]) iter.Seq[V] {
return func(yield func(V) bool) {
for v := range seq {
if f(v) && !yield(v) {
return
}
}
}
}
// 过滤奇数
func FilterOdd(seq iter.Seq[int]) iter.Seq[int] {
return Filter[int](func(n int) bool {
return n%2 == 0
}, seq)
}
// Map returns an iterator over f applied to seq.
func Map[In, Out any](f func(In) Out, seq iter.Seq[In]) iter.Seq[Out] {
return func(yield func(Out) bool) {
for in := range seq {
if !yield(f(in)) {
return
}
}
}
}
// Add 100 to every element in seq
func Add100(seq iter.Seq[int]) iter.Seq[int] {
return Map[int, int](func(n int) int {
return n + 100
}, seq)
}
var sl = []int{12, 13, 14, 5, 67, 82}
func main() {
for v := range Add100(FilterOdd(slices.Values(sl))) {
println(v)
}
}
这里借用了xiter那个issue的Filter和Map的实现,然后通过多个iterator的组合实现了对一个切片的元素的过滤与重新映射:先是过滤掉奇数,然后又在每个元素值的基础上加100。这有点其他语言支持那种函数式的链式调用的意思,但从代码层面看,还不似那么优雅。
我们也可以改造一下上述代码,让for range后面的迭代器的组合更像链式调用一些:
// go-iterator/compose_iterator1.go
package main
import (
"fmt"
"iter"
"slices"
)
// Sequence 是一个包装 iter.Seq 的结构体,用于支持链式调用
type Sequence[T any] struct {
seq iter.Seq[T]
}
// From 创建一个新的 Sequence
func From[T any](seq iter.Seq[T]) Sequence[T] {
return Sequence[T]{seq: seq}
}
// Filter 方法
func (s Sequence[T]) Filter(f func(T) bool) Sequence[T] {
return Sequence[T]{
seq: func(yield func(T) bool) {
for v := range s.seq {
if f(v) && !yield(v) {
return
}
}
},
}
}
// Map 方法
func (s Sequence[T]) Map(f func(T) T) Sequence[T] {
return Sequence[T]{
seq: func(yield func(T) bool) {
for v := range s.seq {
if !yield(f(v)) {
return
}
}
},
}
}
// Range 方法,用于支持 range 语法
func (s Sequence[T]) Range() iter.Seq[T] {
return s.seq
}
// 辅助函数
func IsEven(n int) bool {
return n%2 == 0
}
func Add100(n int) int {
return n + 100
}
func main() {
sl := []int{12, 13, 14, 5, 67, 82}
for v := range From(slices.Values(sl)).Filter(IsEven).Map(Add100).Range() {
fmt.Println(v)
}
}
这样看起来是不是更像链式调用了!
运行上述示例,我们将得到如下结果:
$go run compose_iterator1.go
112
114
182
4.3 处理数据生成时的错误
Go iterator是push类型的,更像一个generator,在前面一次性iterator那个示例中,我们感受最为明显。但是如果generator在产生数据的时候出错该如何处理呢?前面的实现中,我们没法在for range的body,即yield函数中感知到这种错误,要想支持对这类错误的处理,我们需要iterator迭代的数据元素中包含这种error,下面是一个改造后的示例,大家看一下:
// go-iterator/error_iterator.go
package main
import (
"bufio"
"fmt"
"io"
"strings"
)
// Lines 返回一个迭代器,用于逐行读取 io.Reader 的内容
// 使用 bufio.Reader.ReadLine() 来读取每一行并处理错误
func Lines(r io.Reader) func(func(string, error) bool) {
br := bufio.NewReader(r)
return func(yield func(string, error) bool) {
for {
line, isPrefix, err := br.ReadLine()
if err != nil {
// 如果是 EOF,我们不将其视为错误
if err != io.EOF {
yield("", err)
}
return
}
// 如果一行太长,isPrefix 会为 true,我们需要继续读取
fullLine := string(line)
for isPrefix {
line, isPrefix, err = br.ReadLine()
if err != nil {
yield(fullLine, err)
return
}
fullLine += string(line)
}
if !yield(fullLine, nil) {
return
}
}
}
}
func main() {
reader := strings.NewReader("Hello\nWorld\nGo 1.23\nThis is a very long line that might exceed the buffer size")
for line, err := range Lines(reader) {
if err != nil {
fmt.Printf("Error: %v\n", err)
break
}
fmt.Println(line)
}
}
我们将error类型作为迭代数据的第二个值的类型,这样在for range的body中就可以根据该值来做错误处理了。当然了在这个示例中,迭代器是不会返回non-nil的错误的:
$go run error_iterator.go
Hello
World
Go 1.23
This is a very long line that might exceed the buffer size
5. 小结
本文主要介绍了Go 1.23版本中引入的自定义迭代器和iter包。
我们首先回顾了Go迭代器的提案历程,然后详细解释了迭代器的语法形式和实现原理。Go迭代器本质上是一个接受yield函数作为参数的函数,通过编译器的代码转换来实现。本文还讨论了Push迭代器和Pull迭代器的区别,以及性能方面的考量。
在使用方面,本文介绍了一次性使用的迭代器的概念,以及如何组合多个迭代器。此外还讨论了在数据生成过程中处理错误的方法。
到这里,我们看到Go引入的iterator在一定程度上“违背”了Go显式的设计哲学,增加了Gopher代码理解上的难度。 并且将iterator实现的复杂性留给了Go包的作者,尤其是那些需要对外地提供iterator创建API的包作者。对于iterator使用者而言,iterator用起来还是蛮简单的。不过iterator会带来一些性能上的额外开销,这部分是否能在未来的Go版本中被完全优化掉还不可知。
此外,个人感觉对于原生的且支持for range迭代的容器类型,比如slice,下面的方法更自然,性能也更佳:
for i, v := range sl { }
我们似乎没有必要像如下这样来迭代一个slice:
for i, v := range slices.All(sl) { }
而对于一些用户自定义的容器类型,提供iterator实现,并与for range联合使用还是很实用的。
本章中涉及的源码可以在这里下载。
6. 参考资料
- spec: add range over int, range over func – https://github.com/golang/go/issues/61405
- user-defined iteration using range over func values – https://github.com/golang/go/discussions/56413
- iter: new package for iterators – https://github.com/golang/go/issues/61897
- proposal: x/exp/xiter: new package with iterator adapters – https://github.com/golang/go/issues/61898
- Coroutines for Go – https://research.swtch.com/coro
- Go evolves in the wrong direction – https://itnext.io/go-evolves-in-the-wrong-direction-7dfda8a1a620
- Why People are Angry over Go 1.23 Iterators – https://www.gingerbill.org/article/2024/06/17/go-iterator-design/
- Storing Data in Control Flow – https://research.swtch.com/pcdata
- for range spec – https://tip.golang.org/ref/spec#For_range
Gopher部落知识星球在2024年将继续致力于打造一个高品质的Go语言学习和交流平台。我们将继续提供优质的Go技术文章首发和阅读体验。同时,我们也会加强代码质量和最佳实践的分享,包括如何编写简洁、可读、可测试的Go代码。此外,我们还会加强星友之间的交流和互动。欢迎大家踊跃提问,分享心得,讨论技术。我会在第一时间进行解答和交流。我衷心希望Gopher部落可以成为大家学习、进步、交流的港湾。让我相聚在Gopher部落,享受coding的快乐! 欢迎大家踊跃加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) – https://gopherdaily.tonybai.com
我的联系方式:
- 微博(暂不可用):https://weibo.com/bigwhite20xx
- 微博2:https://weibo.com/u/6484441286
- 博客:tonybai.com
- github: https://github.com/bigwhite
- Gopher Daily归档 – https://github.com/bigwhite/gopherdaily

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。