本文永久链接 – https://tonybai.com/2022/03/28/the-comparison-of-the-go-community-leading-kakfa-clients
一. 背景
众所周知,Kafka是Apache开源基金会下的明星级开源项目,作为一个开源的分布式事件流平台,它被成千上万的公司用于高性能数据管道、流分析、数据集成和关键任务应用。在国内,无论大厂小厂,无论是自己部署还是用像阿里云提供的Kafka云服务,很多互联网应用已经离不开Kafka了。
互联网不拘泥于某种编程语言,但很多人不喜欢Kafka是由Scala/Java开发的。尤其是对于那些对某种语言有着“宗教般”虔诚、有着“手里拿着锤子,眼中满世界都是钉子”的程序员来说,总是有想重写Kafka的冲动。但就像很多新语言的拥趸想重写Kubernetes一样,Kafka已经建立起了巨大的起步和生态优势,短期很难建立起同样规格的巨型项目和对应的生态了(近两年同样火热的类Kafka的Apache pulsar创建时间与Kafka是先后脚的,只是纳入Apache基金会托管的时间较晚)。
Kafka生态很强大,各种编程语言都有对应的Kafka client。Kafka背后的那个公司confluent.inc也维护了各大主流语言的client:

其他主流语言的开发人员只需要利用好这些client端,做好与Kafka集群的连接就好了。好了做了这么多铺垫,下面说说为啥要写下这篇文章。
目前业务线生产环境的日志方案是这样的:
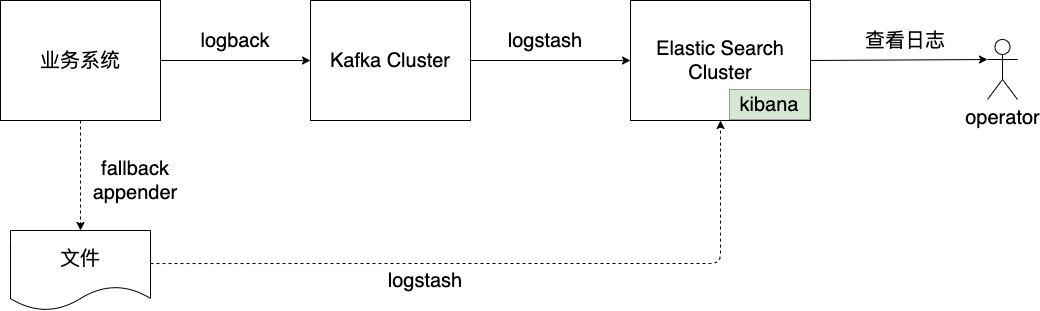
从图中我们看到:业务系统将日志写入Kafka,然后通过logstash工具消费日志并汇聚到后面的Elastic Search Cluster中供查询使用。 业务系统主要是由Java实现的,考虑到Kafka写失败的情况,为了防止log阻塞业务流程,业务系统使用了支持fallback appender的logback进行日志写入:这样当Kafka写入失败时,日志还可以写入备用的文件中,尽可能保证日志不丢失。
考虑到复用已有的IT设施与方案,我们用Go实现的新系统也向这种不落盘的log汇聚方案靠拢,这就要求我们的logger也要支持向Kafka写入并且支持fallback机制。
我们的log包是基于uber zap封装而来的,uber的zap日志包是目前Go社区使用最为广泛的、高性能的log包之一,第25期thoughtworks技术雷达也将zap列为试验阶段的工具推荐给大家,并且thoughtworks团队已经在大规模使用它:

不过,zap原生不支持写Kafka,但zap是可扩展的,我们需要为其增加写Kafka的扩展功能。而要写Kakfa,我们就离不开Kakfa Client包。目前Go社区主流的Kafka client有Shopify的sarama、Kafka背后公司confluent.inc维护的confluent-kafka-go以及segmentio/kafka-go。
在这篇文章中,我就根据我的使用历程逐一说说我对这三个客户端的使用感受。
下面,我们首先先来看看star最多的Shopify/sarama。
二. Shopify/sarama:星多不一定代表优秀
目前在Go社区星星最多,应用最广的Kafka client包是Shopify的sarama。Shopify是一家国外的电商平台,我总是混淆Shopify、Shopee(虾皮)以及传闻中要赞助巴萨的Spotify(瑞典流媒体音乐平台),傻傻分不清^_^。
下面我就基于sarama演示一下如何扩展zap,让其支持写kafka。在《一文告诉你如何用好uber开源的zap日志库》一文中,我介绍过zap建构在zapcore之上,而zapcore由Encoder、WriteSyncer和LevelEnabler三部分组成,对于我们这个写Kafka的功能需求来说,我们只需要定义一个给一个WriteSyncer接口的实现,即可组装成一个支持向Kafka写入的logger。
我们自顶向下先来看看创建logger的函数:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/zapkafka/log.go
type Logger struct {
l *zap.Logger // zap ensure that zap.Logger is safe for concurrent use
cfg zap.Config
level zap.AtomicLevel
}
func (l *Logger) Info(msg string, fields ...zap.Field) {
l.l.Info(msg, fields...)
}
func New(writer io.Writer, level int8, opts ...zap.Option) *Logger {
if writer == nil {
panic("the writer is nil")
}
atomicLevel := zap.NewAtomicLevelAt(zapcore.Level(level))
logger := &Logger{
cfg: zap.NewProductionConfig(),
level: atomicLevel,
}
logger.cfg.EncoderConfig.EncodeTime = func(t time.Time, enc zapcore.PrimitiveArrayEncoder) {
enc.AppendString(t.Format(time.RFC3339)) // 2021-11-19 10:11:30.777
}
logger.cfg.EncoderConfig.TimeKey = "logtime"
core := zapcore.NewCore(
zapcore.NewJSONEncoder(logger.cfg.EncoderConfig),
zapcore.AddSync(writer),
atomicLevel,
)
logger.l = zap.New(core, opts...)
return logger
}
// SetLevel alters the logging level on runtime
// it is concurrent-safe
func (l *Logger) SetLevel(level int8) error {
l.level.SetLevel(zapcore.Level(level))
return nil
}
这段代码中没有与kafka client相关的内容,New函数用来创建一个*Logger实例,它接受的第一个参数为io.Writer接口类型,用于指示日志的写入位置。这里要注意一点的是:我们使用zap.AtomicLevel类型存储logger的level信息,基于zap.AtomicLevel的level支持热更新,我们可以在程序运行时动态修改logger的log level。这个也是在《一文告诉你如何用好uber开源的zap日志库》遗留问题的答案。
接下来,我们就基于sarama的AsyncProducer来实现一个满足zapcore.WriteSyncer接口的类型:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/zapkafka/kafka_syncer.go
type kafkaWriteSyncer struct {
topic string
producer sarama.AsyncProducer
fallbackSyncer zapcore.WriteSyncer
}
func NewKafkaAsyncProducer(addrs []string) (sarama.AsyncProducer, error) {
config := sarama.NewConfig()
config.Producer.Return.Errors = true
return sarama.NewAsyncProducer(addrs, config)
}
func NewKafkaSyncer(producer sarama.AsyncProducer, topic string, fallbackWs zapcore.WriteSyncer) zapcore.WriteSyncer {
w := &kafkaWriteSyncer{
producer: producer,
topic: topic,
fallbackSyncer: zapcore.AddSync(fallbackWs),
}
go func() {
for e := range producer.Errors() {
val, err := e.Msg.Value.Encode()
if err != nil {
continue
}
fallbackWs.Write(val)
}
}()
return w
}
NewKafkaSyncer是创建zapcore.WriteSyncer的那个函数,它的第一个参数使用了sarama.AsyncProducer接口类型,目的是为了可以利用sarama提供的mock测试包。最后一个参数为fallback时使用的WriteSyncer参数。
NewKafkaAsyncProducer函数是用于方便用户快速创建sarama.AsyncProducer的,其中的config使用的是默认的config值。在config默认值中,Return.Successes的默认值都false,即表示客户端不关心向Kafka写入消息的成功状态,我们也无需单独建立一个goroutine来消费AsyncProducer.Successes()。但我们需要关注写入失败的消息,因此我们将Return.Errors置为true的同时在NewKafkaSyncer中启动了一个goroutine专门处理写入失败的日志数据,将这些数据写入fallback syncer中。
接下来,我们看看kafkaWriteSyncer的Write与Sync方法:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/zapkafka/kafka_syncer.go
func (ws *kafkaWriteSyncer) Write(b []byte) (n int, err error) {
b1 := make([]byte, len(b))
copy(b1, b) // b is reused, we must pass its copy b1 to sarama
msg := &sarama.ProducerMessage{
Topic: ws.topic,
Value: sarama.ByteEncoder(b1),
}
select {
case ws.producer.Input() <- msg:
default:
// if producer block on input channel, write log entry to default fallbackSyncer
return ws.fallbackSyncer.Write(b1)
}
return len(b1), nil
}
func (ws *kafkaWriteSyncer) Sync() error {
ws.producer.AsyncClose()
return ws.fallbackSyncer.Sync()
}
注意:上面代码中的b会被zap重用,因此我们在扔给sarama channel之前需要将b copy一份,将副本发送给sarama。
从上面代码看,这里我们将要写入的数据包装成一个sarama.ProducerMessage,然后发送到producer的Input channel中。这里有一个特殊处理,那就是当如果msg阻塞在Input channel上时,我们将日志写入fallbackSyncer。这种情况是出于何种考虑呢?这主要是因为基于sarama v1.30.0版本的kafka logger在我们的验证环境下出现过hang住的情况,当时的网络可能出现过波动,导致logger与kafka之间的连接出现过异常,我们初步怀疑就是这个位置阻塞,导致业务被阻塞住了。在sarama v1.32.0版本中有一个fix,和我们这个hang的现象很类似。
但这么做也有一个严重的问题,那就是在压测中,我们发现大量日志都无法写入到kafka,而是都写到了fallback syncer中。究其原因,我们在sarama的async_producer.go中看到:input channel是一个unbuffered channel,而从input channel读取消息的dispatcher goroutine也仅仅有一个,考虑到goroutine的调度,大量日志写入fallback syncer就不足为奇了:
// github.com/Shopify/sarama@v1.32.0/async_producer.go
func newAsyncProducer(client Client) (AsyncProducer, error) {
// Check that we are not dealing with a closed Client before processing any other arguments
if client.Closed() {
return nil, ErrClosedClient
}
txnmgr, err := newTransactionManager(client.Config(), client)
if err != nil {
return nil, err
}
p := &asyncProducer{
client: client,
conf: client.Config(),
errors: make(chan *ProducerError),
input: make(chan *ProducerMessage), // 笔者注:这是一个unbuffer channel
successes: make(chan *ProducerMessage),
retries: make(chan *ProducerMessage),
brokers: make(map[*Broker]*brokerProducer),
brokerRefs: make(map[*brokerProducer]int),
txnmgr: txnmgr,
}
... ...
}
有人说这里可以加定时器(Timer)做超时,要知道日志都是在程序执行的关键路径上,每写一条log就启动一个Timer感觉太耗了(即便是Reset重用Timer)。如果sarama在任何时候都不会hang住input channel,那么在Write方法中我们还是不要使用select-default这样的trick。
sarama的一个不错的地方是提供了mocks测试工具包,该包既可用于sarama的自测,也可以用作依赖sarama的go包的自测,以上面的实现为例,我们可以编写基于mocks测试包的一些test:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/zapkafka/log_test.go
func TestWriteFailWithKafkaSyncer(t *testing.T) {
config := sarama.NewConfig()
p := mocks.NewAsyncProducer(t, config)
var buf = make([]byte, 0, 256)
w := bytes.NewBuffer(buf)
w.Write([]byte("hello"))
logger := New(NewKafkaSyncer(p, "test", NewFileSyncer(w)), 0)
p.ExpectInputAndFail(errors.New("produce error"))
p.ExpectInputAndFail(errors.New("produce error"))
// all below will be written to the fallback sycner
logger.Info("demo1", zap.String("status", "ok")) // write to the kafka syncer
logger.Info("demo2", zap.String("status", "ok")) // write to the kafka syncer
// make sure the goroutine which handles the error writes the log to the fallback syncer
time.Sleep(2 * time.Second)
s := string(w.Bytes())
if !strings.Contains(s, "demo1") {
t.Errorf("want true, actual false")
}
if !strings.Contains(s, "demo2") {
t.Errorf("want true, actual false")
}
if err := p.Close(); err != nil {
t.Error(err)
}
}
测试通过mocks.NewAsyncProducer返回满足sarama.AsyncProducer接口的实现。然后设置expect,针对每条消息都要设置expect,这里写入两条日志,所以设置了两次。注意:由于我们是在一个单独的goroutine中处理的Errors channel,因此这里存在一些竞态条件。在并发程序中,Fallback syncer也一定要支持并发写,zapcore提供了zapcore.Lock可以用于将一个普通的zapcore.WriteSyncer包装成并发安全的WriteSyncer。
不过,使用sarama的过程中还遇到过一个“严重”的问题,那就是有些时候数据并没有完全写入到kafka。我们去掉针对input channel的select-default操作,然后创建一个concurrent-write小程序,用于并发的向kafka写入log:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/zapkafka/cmd/concurrent_write/main.go
func SaramaProducer() {
p, err := log.NewKafkaAsyncProducer([]string{"localhost:29092"})
if err != nil {
panic(err)
}
logger := log.New(log.NewKafkaSyncer(p, "test", zapcore.AddSync(os.Stderr)), int8(0))
var wg sync.WaitGroup
var cnt int64
for j := 0; j < 10; j++ {
wg.Add(1)
go func(j int) {
var value string
for i := 0; i < 10000; i++ {
now := time.Now()
value = fmt.Sprintf("%02d-%04d-%s", j, i, now.Format("15:04:05"))
logger.Info("log message:", zap.String("value", value))
atomic.AddInt64(&cnt, 1)
}
wg.Done()
}(j)
}
wg.Wait()
logger.Sync()
println("cnt =", atomic.LoadInt64(&cnt))
time.Sleep(10 * time.Second)
}
func main() {
SaramaProducer()
}
我们用kafka官方提供的docker-compose.yml在本地启动一个kafka服务:
$cd benchmark
$docker-compose up -d
然后我们使用kafka容器中自带的consumer工具从名为test的topic中消费数据,消费的数据重定向到1.log中:
$docker exec benchmark_kafka_1 /bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning > 1.log 2>&1
然后我们运行concurrent_write:
$ make
$./concurrent_write > 1.log 2>&1
concurrent_write程序启动了10个goroutine,每个goroutine向kafka写入1w条日志,多数情况下在benchmark目录下的1.log都能看到10w条日志记录,但在使用sarama v1.30.0版本时有些时候看到的是少于10w条的记录,至于那些“丢失”的记录则不知在何处了。使用sarama v1.32.0时,这种情况还尚未出现过。
好了,是时候看看下一个kafka client包了!
三. confluent-kafka-go:需要开启cgo的包还是有点烦
confluent-kafka-go包是kafka背后的技术公司confluent.inc维护的Go客户端,也可以算是Kafka官方Go客户端了。不过这个包唯一的“问题”在于它是基于kafka c/c++库librdkafka构建而成,这意味着一旦你的Go程序依赖confluent-kafka-go,你就很难实现Go应用的静态编译,也无法实现跨平台编译。由于所有业务系统都依赖log包,一旦依赖confluent-kafka-go只能动态链接,我们的构建工具链全需要更改,代价略大。
不过confluent-kafka-go使用起来也很简单,写入性能也不错,并且不存在前面sarama那样的“丢消息”的情况,下面是一个基于confluent-kafka-go的producer示例:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/confluent-kafka-go-static-build/producer.go
func ReadConfig(configFile string) kafka.ConfigMap {
m := make(map[string]kafka.ConfigValue)
file, err := os.Open(configFile)
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to open file: %s", err)
os.Exit(1)
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := strings.TrimSpace(scanner.Text())
if !strings.HasPrefix(line, "#") && len(line) != 0 {
kv := strings.Split(line, "=")
parameter := strings.TrimSpace(kv[0])
value := strings.TrimSpace(kv[1])
m[parameter] = value
}
}
if err := scanner.Err(); err != nil {
fmt.Printf("Failed to read file: %s", err)
os.Exit(1)
}
return m
}
func main() {
conf := ReadConfig("./producer.conf")
topic := "test"
p, err := kafka.NewProducer(&conf)
var mu sync.Mutex
if err != nil {
fmt.Printf("Failed to create producer: %s", err)
os.Exit(1)
}
var wg sync.WaitGroup
var cnt int64
// Go-routine to handle message delivery reports and
// possibly other event types (errors, stats, etc)
go func() {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
fmt.Printf("Failed to deliver message: %v\n", ev.TopicPartition)
} else {
fmt.Printf("Produced event to topic %s: key = %-10s value = %s\n",
*ev.TopicPartition.Topic, string(ev.Key), string(ev.Value))
}
}
}
}()
for j := 0; j < 10; j++ {
wg.Add(1)
go func(j int) {
var value string
for i := 0; i < 10000; i++ {
key := ""
now := time.Now()
value = fmt.Sprintf("%02d-%04d-%s", j, i, now.Format("15:04:05"))
mu.Lock()
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte(key),
Value: []byte(value),
}, nil)
mu.Unlock()
atomic.AddInt64(&cnt, 1)
}
wg.Done()
}(j)
}
wg.Wait()
// Wait for all messages to be delivered
time.Sleep(10 * time.Second)
p.Close()
}
这里我们还是使用10个goroutine向kafka各写入1w消息,注意:默认使用kafka.NewProducer创建的Producer实例不是并发安全的,所以这里用一个sync.Mutex对其Produce调用进行同步管理。我们可以像sarama中的例子那样,在本地启动一个kafka服务,验证一下confluent-kafka-go的运行情况。
由于confluent-kafka-go包基于kafka c库而实现,所以我们没法关闭CGO,如果关闭CGO,将遇到下面编译问题:
$CGO_ENABLED=0 go build
# producer
./producer.go:15:42: undefined: kafka.ConfigMap
./producer.go:17:29: undefined: kafka.ConfigValue
./producer.go:50:18: undefined: kafka.NewProducer
./producer.go:85:22: undefined: kafka.Message
./producer.go:86:28: undefined: kafka.TopicPartition
./producer.go:86:75: undefined: kafka.PartitionAny
因此,默认情况依赖confluent-kafka-go包的Go程序会采用动态链接,通过ldd查看编译后的程序结果如下(on CentOS):
$make build
$ldd producer
linux-vdso.so.1 => (0x00007ffcf87ec000)
libm.so.6 => /lib64/libm.so.6 (0x00007f473d014000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f473ce10000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f473cbf4000)
librt.so.1 => /lib64/librt.so.1 (0x00007f473c9ec000)
libc.so.6 => /lib64/libc.so.6 (0x00007f473c61e000)
/lib64/ld-linux-x86-64.so.2 (0x00007f473d316000)
那么在CGO开启的情况下是否可以静态编译呢?理论上是可以的。这个在我的《Go语言精进之路》中关于CGO一节有详细说明。
不过confluent-kafka-go包官方目前确认还不支持静态编译。我们来试试在CGO开启的情况下,对其进行静态编译:
// on CentOS
$ go build -buildvcs=false -o producer-static -ldflags '-linkmode "external" -extldflags "-static"'
$ producer
/root/.bin/go1.18beta2/pkg/tool/linux_amd64/link: running gcc failed: exit status 1
/usr/bin/ld: 找不到 -lm
/usr/bin/ld: 找不到 -ldl
/usr/bin/ld: 找不到 -lpthread
/usr/bin/ld: 找不到 -lrt
/usr/bin/ld: 找不到 -lpthread
/usr/bin/ld: 找不到 -lc
collect2: 错误:ld 返回 1
静态链接会将confluent-kafka-go的c语言部分的符号进行静态链接,这些符号可能在libc、libpthread等c运行时库或系统库中,但默认情况下,CentOS是没有安装这些库的.a(archive)版本的。我们需要手动安装:
$yum install glibc-static
安装后,我们再执行上面的静态编译命令:
$go build -buildvcs=false -o producer-static -ldflags '-linkmode "external" -extldflags "-static"'
$ producer
/root/go/pkg/mod/github.com/confluentinc/confluent-kafka-go@v1.8.2/kafka/librdkafka_vendor/librdkafka_glibc_linux.a(rddl.o):在函数‘rd_dl_open’中:
(.text+0x1d): 警告:Using 'dlopen' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
/root/go/pkg/mod/github.com/confluentinc/confluent-kafka-go@v1.8.2/kafka/librdkafka_vendor/librdkafka_glibc_linux.a(rdaddr.o):在函数‘rd_getaddrinfo’中:
(.text+0x440): 警告:Using 'getaddrinfo' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
这回我们的静态编译成功了!
$ ldd producer-static
不是动态可执行文件
但有一些警告!我们先不理这些警告,试试编译出来的producer-static是否可用。使用docker-compose启动本地kafka服务,执行producer-static,我们发现程序可以正常将10w消息写入kafka,中间没有错误发生。至少在producer场景下,应用并没有执行包含dlopen、getaddrinfo的代码。
不过这不代表在其他场景下上面的静态编译方式没有问题,因此还是等官方方案出炉吧。或者使用builder容器构建你的基于confluent-kafka-go的程序。
我们继续往下看segmentio/kafka-go。
四. segmentio/kafka-go:sync很慢,async很快!
和sarama一样,segmentio/kafka-go也是一个纯go实现的kafka client,并且在很多公司的生产环境经历过考验,segmentio/kafka-go提供低级conn api和高级api(reader和writer),以writer为例,相对低级api,它是并发safe的,还提供连接保持和重试,无需开发者自己实现,另外writer还支持sync和async写、带context.Context的超时写等。
不过Writer的sync模式写十分慢,1秒钟才几十条,但async模式就飞快了!
不过和confluent-kafka-go一样,segmentio/kafka-go也没有像sarama那样提供mock测试包,我们需要自己建立环境测试。kafka-go官方的建议时:在本地启动一个kafka服务,然后运行测试。在轻量级容器十分流行的时代,是否需要mock还真是一件值得思考的事情。
segmentio/kafka-go的使用体验非常棒,至今没有遇到过什么大问题,这里不举例了,例子见下面benchmark章节。
五. 写入性能
即便是简要对比,也不能少了benchmark。这里针对上面三个包分别建立了顺序benchmark和并发benchmark的测试用例:
// https://github.com/bigwhite/experiments/blob/master/kafka-clients/benchmark/kafka_clients_test.go
var m = []byte("this is benchmark for three mainstream kafka client")
func BenchmarkSaramaAsync(b *testing.B) {
b.ReportAllocs()
config := sarama.NewConfig()
producer, err := sarama.NewAsyncProducer([]string{"localhost:29092"}, config)
if err != nil {
panic(err)
}
message := &sarama.ProducerMessage{Topic: "test", Value: sarama.ByteEncoder(m)}
b.ResetTimer()
for i := 0; i < b.N; i++ {
producer.Input() <- message
}
}
func BenchmarkSaramaAsyncInParalell(b *testing.B) {
b.ReportAllocs()
config := sarama.NewConfig()
producer, err := sarama.NewAsyncProducer([]string{"localhost:29092"}, config)
if err != nil {
panic(err)
}
message := &sarama.ProducerMessage{Topic: "test", Value: sarama.ByteEncoder(m)}
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
producer.Input() <- message
}
})
}
func BenchmarkKafkaGoAsync(b *testing.B) {
b.ReportAllocs()
w := &kafkago.Writer{
Addr: kafkago.TCP("localhost:29092"),
Topic: "test",
Balancer: &kafkago.LeastBytes{},
Async: true,
}
c := context.Background()
b.ResetTimer()
for i := 0; i < b.N; i++ {
w.WriteMessages(c, kafkago.Message{Value: []byte(m)})
}
}
func BenchmarkKafkaGoAsyncInParalell(b *testing.B) {
b.ReportAllocs()
w := &kafkago.Writer{
Addr: kafkago.TCP("localhost:29092"),
Topic: "test",
Balancer: &kafkago.LeastBytes{},
Async: true,
}
c := context.Background()
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
w.WriteMessages(c, kafkago.Message{Value: []byte(m)})
}
})
}
func ReadConfig(configFile string) ckafkago.ConfigMap {
m := make(map[string]ckafkago.ConfigValue)
file, err := os.Open(configFile)
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to open file: %s", err)
os.Exit(1)
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := strings.TrimSpace(scanner.Text())
if !strings.HasPrefix(line, "#") && len(line) != 0 {
kv := strings.Split(line, "=")
parameter := strings.TrimSpace(kv[0])
value := strings.TrimSpace(kv[1])
m[parameter] = value
}
}
if err := scanner.Err(); err != nil {
fmt.Printf("Failed to read file: %s", err)
os.Exit(1)
}
return m
}
func BenchmarkConfluentKafkaGoAsync(b *testing.B) {
b.ReportAllocs()
conf := ReadConfig("./confluent-kafka-go.conf")
topic := "test"
p, _ := ckafkago.NewProducer(&conf)
go func() {
for _ = range p.Events() {
}
}()
key := []byte("")
b.ResetTimer()
for i := 0; i < b.N; i++ {
p.Produce(&ckafkago.Message{
TopicPartition: ckafkago.TopicPartition{Topic: &topic, Partition: ckafkago.PartitionAny},
Key: key,
Value: m,
}, nil)
}
}
func BenchmarkConfluentKafkaGoAsyncInParalell(b *testing.B) {
b.ReportAllocs()
conf := ReadConfig("./confluent-kafka-go.conf")
topic := "test"
p, _ := ckafkago.NewProducer(&conf)
go func() {
for range p.Events() {
}
}()
var mu sync.Mutex
key := []byte("")
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
mu.Lock()
p.Produce(&ckafkago.Message{
TopicPartition: ckafkago.TopicPartition{Topic: &topic, Partition: ckafkago.PartitionAny},
Key: key,
Value: m,
}, nil)
mu.Unlock()
}
})
}
本地启动一个kafka服务,运行该benchmark:
$go test -bench .
goos: linux
goarch: amd64
pkg: kafka_clients
cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
BenchmarkSaramaAsync-4 802070 2267 ns/op 294 B/op 1 allocs/op
BenchmarkSaramaAsyncInParalell-4 1000000 1913 ns/op 294 B/op 1 allocs/op
BenchmarkKafkaGoAsync-4 1000000 1208 ns/op 376 B/op 5 allocs/op
BenchmarkKafkaGoAsyncInParalell-4 1768538 703.4 ns/op 368 B/op 5 allocs/op
BenchmarkConfluentKafkaGoAsync-4 1000000 3154 ns/op 389 B/op 10 allocs/op
BenchmarkConfluentKafkaGoAsyncInParalell-4 742476 1863 ns/op 390 B/op 10 allocs/op
我们看到,虽然sarama在内存分配上有优势,但综合性能上还是segmentio/kafka-go最优。
六. 小结
本文对比了Go社区的三个主流kafka客户端包:Shopify/sarama、confluent-kafka-go和segmentio/kafka-go。sarama应用最广,也是我研究时间最长的一个包,但坑也是最多的,放弃;confluent-kafka-go虽然是官方的,但是基于cgo,无奈放弃;最后,我们选择了segmentio/kafka-go,已经在线上运行了一段时间,至今尚未发现重大问题。
不过,本文的对比仅限于作为Producer这块的场景,是一个“不完全”的介绍。后续如有更多场景的实践经验,还会再补充。
本文中的源码可以在这里下载。
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2022年,Gopher部落全面改版,将持续分享Go语言与Go应用领域的知识、技巧与实践,并增加诸多互动形式。欢迎大家加入!





我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 微信公众号:iamtonybai
- 博客:tonybai.com
- github: https://github.com/bigwhite
- “Gopher部落”知识星球:https://public.zsxq.com/groups/51284458844544

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。