
本文永久链接 – https://tonybai.com/2025/11/26/how-google-built-a-130000-node-k8s-cluster
大家好,我是Tony Bai。
Kubernetes 的官方支持上限通常被认为是 5,000 到 15,000 节点。然而,在 AI 时代的算力军备竞赛中,这个数字显得有些“捉襟见肘”。
近日,Google Cloud 发布了一份重磅技术报告,揭示了他们如何在 GKE (Google Kubernetes Engine) 上成功运行了一个130,000 节点的超大规模集群——这是目前已知全球最大的 Kubernetes 集群,其规模是 GKE 官方支持上限(65,000 节点)的两倍,更是开源 Kubernetes 社区上限的近十倍。
这不是一次规模的堆砌,而是一次涉及控制平面、调度器、存储和网络的系统级工程实践,极具参考价值。Google 是如何做到的?让我们深入其架构内部,一探究竟。

背景:AI 时代的“巨兽”需求
推动这一极限挑战的核心动力,是日益庞大的 AI 工作负载。随着大模型训练对算力需求的指数级增长,客户不再满足于万卡集群,而是向着 10万节点 的规模进军。
在这个量级下,挑战不仅来自芯片的短缺,更来自电力和数据中心的物理限制。一个拥有数万块高性能 GPU 的集群,其功耗可能高达数百兆瓦,必须跨越多个数据中心部署。这要求 Kubernetes 不仅要管理庞大的资源,还要具备跨故障域、跨数据中心的极致编排能力。
核心创新:四大技术支柱
为了支撑起这座“13万节点”的摩天大楼,Google 对 Kubernetes 的底层架构进行了四项关键的“手术”。
1. 读操作的极致优化:一致性缓存
在 13 万节点的集群中,数以百万计的 Pod 和对象会产生海量的 API 请求。如果所有读请求都直接打到 etcd(或 GKE 使用的 Spanner),数据库瞬间就会被压垮。
Google 的解决方案是:让 API Server 直接从内存缓存中服务读请求,同时保证强一致性。
具体来说,就是通过引入 Consistent Reads from Cache (KEP-2340),API Server 可以利用其内存中的 Watch Cache 来服务 GET 和 LIST 请求。
系统会确保缓存中的数据在服务请求前是可验证的最新状态(verifiably up-to-date),从而在不牺牲一致性的前提下,大幅降低了底层数据库的压力。
同时,通过 Snapshottable API Server Cache (KEP-4988),API Server 甚至可以直接从内存中构建 B-tree 快照,来服务带有 resourceVersion 的历史数据查询,彻底消除了“读放大”问题。
2. 存储后端的无限扩展:基于 Spanner 的分布式键值存储
标准的 Kubernetes 使用 etcd 作为存储后端,但在 13 万节点的规模下,etcd 的容量和吞吐量成为了瓶颈。
GKE 替换了这一层,使用了一个基于 Google Spanner 的专有键值存储系统。
- 性能数据:在测试中,该存储系统轻松支撑了 13,000 QPS 的租约 (Lease) 更新操作,确保了 13 万个节点的健康检查心跳畅通无阻。
- 容量:在峰值时,数据库中存储了超过 100 万个 Kubernetes 对象,依然保持了极低的延迟和极高的稳定性。
3. 调度器的进化:Kueue 与工作负载感知
默认的 Kubernetes 调度器是“Pod 中心”的,它一个个地调度 Pod。但这对于 AI 训练任务来说远远不够——AI 任务通常需要“全有或全无” (All-or-Nothing) 的调度保证(即 Gang Scheduling)。
Google 引入了 Kueue,一个构建在原生调度器之上的作业级 (Job-level) 队列管理器。Kueue 负责决定何时接纳一个作业,基于配额、优先级和公平策略进行裁决。它实现了Gang Scheduling,确保一个训练任务的所有 Pod 要么全部启动,要么全部排队,避免了资源死锁。
4. 数据访问的加速:GCS FUSE 与本地化缓存
对于 AI 训练,数据加载速度至关重要。GKE 利用 Cloud Storage FUSE 配合并行下载和区域性缓存 (Anywhere Cache),让存储在 GCS 对象存储中的海量数据,能像本地文件系统一样被 Pod 高速访问。这使得数据加载延迟降低了 70%,确保了 GPU 不会因为等待数据而空转。
实战演练:一场 13 万节点的压力测试
为了验证这套架构,Google 设计了一个包含四个阶段的极限压力测试,模拟了真实的 AI 生产环境。下图展示了整个测试的时间线和四个关键阶段。

图注:13万节点压力测试的完整执行时间线
阶段一:基线测试 —— 1000 Pods/秒的狂飙
在一个空集群中,一次性启动 130,000 个 Pod 的大规模训练任务。结果显示,控制平面极其稳定,支撑了高达 1,000 Pods/秒 的创建和调度吞吐量。
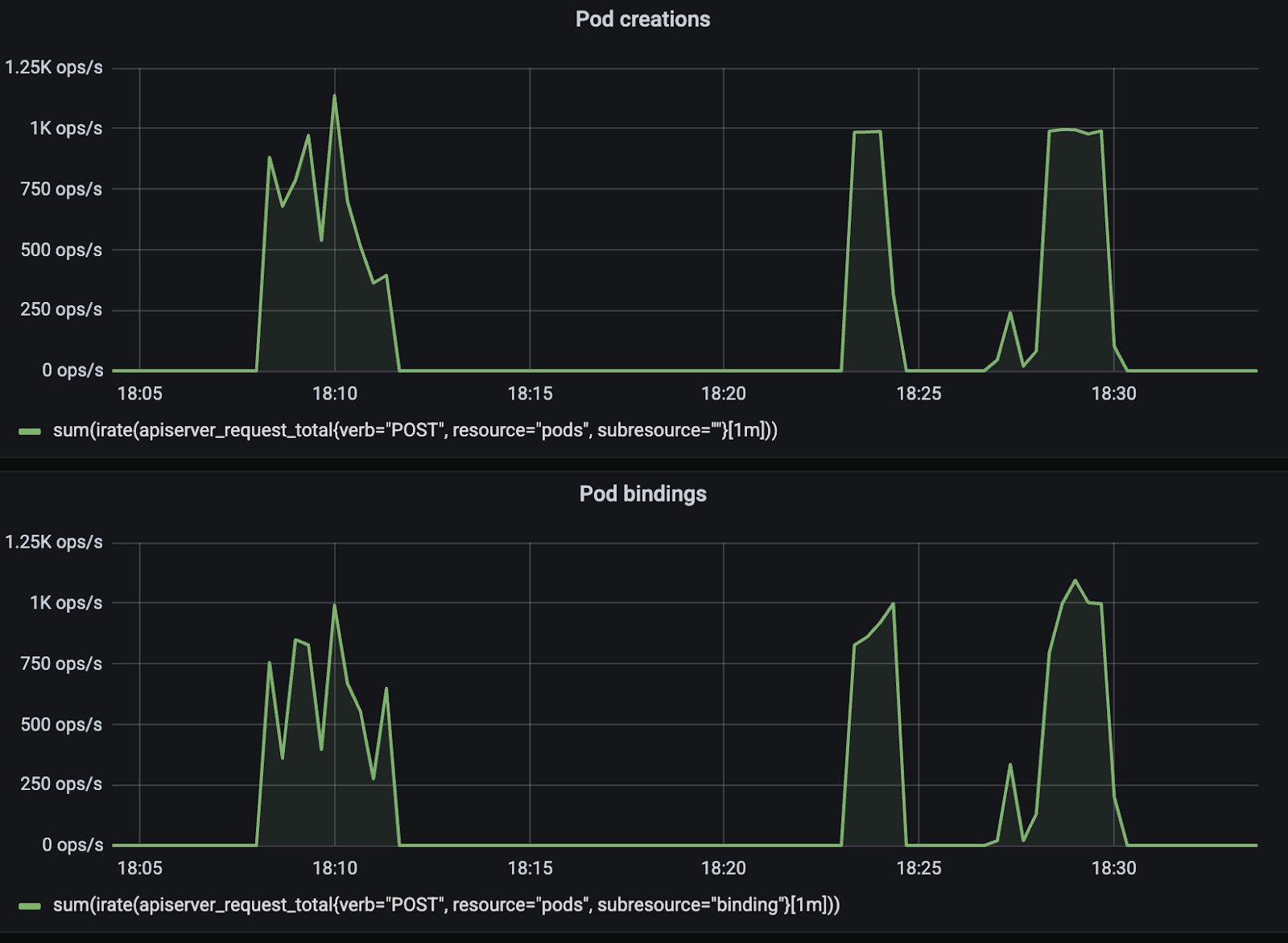
图注:控制平面的吞吐量监控
阶段二:混合负载与争抢 —— Kueue 的“铁腕”
测试引入了大量低优先级的批处理作业填满集群,然后突然提交高优先级的微调任务。此时,Kueue 展现了惊人的动态调整能力:它在 93 秒内精准抢占了 39,000 个低优 Pod,瞬间腾出资源给高优任务。
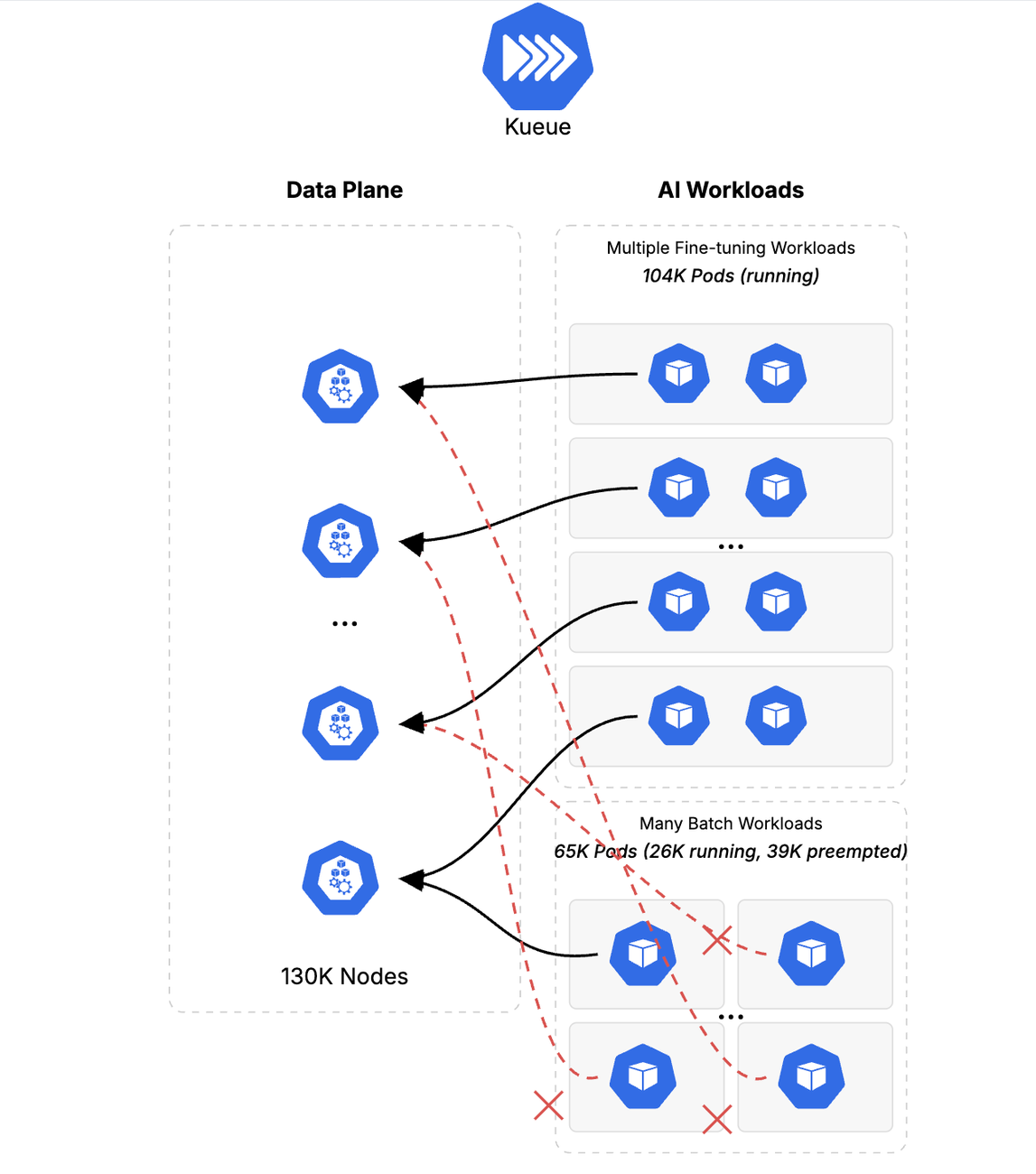
图注:Kueue 正在进行资源调度
阶段三与四:突发流量与弹性恢复
在第三阶段,模拟了“双十一”式的流量洪峰,提交最高优先级的推理服务。系统再次平稳应对,甚至在极高负载下,推理 Pod 的 P99 启动延迟仍控制在 10 秒左右,这对于对延迟敏感的在线服务至关重要。
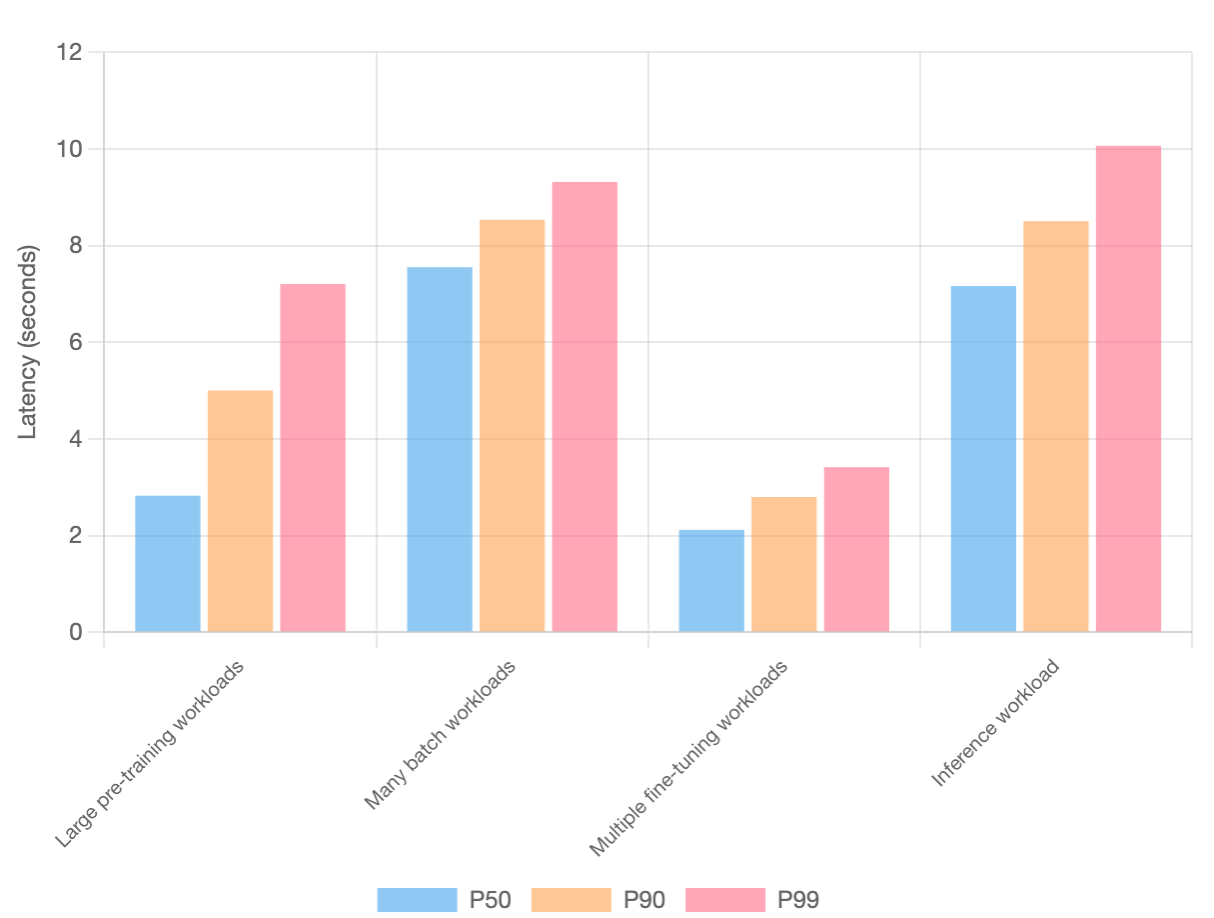
图注:不同负载类型下的 Pod 启动延迟 最后,当流量退去,系统自动释放资源,重新接纳之前被挂起的低优任务,实现了资源的完美闭环和极致利用。
小结:这就是未来的基础设施
Google 的这次 13 万节点实验,不仅是秀肌肉,更是为整个云原生社区指明了方向。它证明了 Kubernetes 在经过合理的架构优化后,完全有能力承载 AI 时代最苛刻的算力需求。
从内存一致性缓存到工作负载感知的调度,这些在极限场景下打磨出的技术创新,最终都会反哺到普通的 GKE 集群,甚至回馈给开源社区(如 Kueue 和 KEP 提案)。
对于我们每一位架构师而言,这都是生动的一课:真正的可扩展性,不仅仅是堆砌硬件,更是对系统每一个环节——从读写路径到调度逻辑——进行极致的工程优化。
资料链接:https://cloud.google.com/blog/products/containers-kubernetes/how-we-built-a-130000-node-gke-cluster/
聊聊你对“规模极限”的看法
Google的13万节点集群,为我们展示了云原生技术栈在AI时代的巨大潜力。在你看来,Kubernetes或其他云原生技术的下一个“物理极限”会是什么?除了Google提到的这四项优化,你认为还有哪些关键技术能帮助我们突破规模的瓶颈?或者,你在自己的工作中,遇到过哪些有趣的“规模化”挑战和解决方案?
欢迎在评论区留下你的真知灼见,让我们一起探讨未来基础设施的模样!
如果这篇文章让你对大规模系统设计有了新的启发,别忘了点个【赞】和【在看】,并分享给更多对技术极限充满好奇的同伴!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
- 告别低效,重塑开发范式
- 驾驭AI Agent(Claude Code),实现工作流自动化
- 从“AI使用者”进化为规范驱动开发的“工作流指挥家”
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
- 想写出更地道、更健壮的Go代码,却总在细节上踩坑?
- 渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
- 想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
