
本文永久链接 – https://tonybai.com/2024/06/28/go-and-nn-part3-handwritten-digit-recognition
在上一篇文章《Go与神经网络:线性回归》中,我们借由传统的机器学习方法:线性回归解决了房价预测问题。按照我初步设想的从传统机器学习到大语言模型的学习路线,是时候在这一篇中切换到学习神经网络了。
1. 从线性回归到神经网络
我们已经知道了如何使用多元线性函数构成的线性回归模型预测房价,其实线性模型也可以看作是一个神经网络。我们在上一篇文章中使用的假设函数如下图:
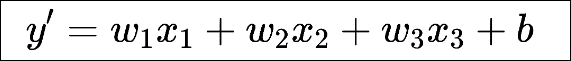
我们可以将y’表示成一个神经网络的结构:
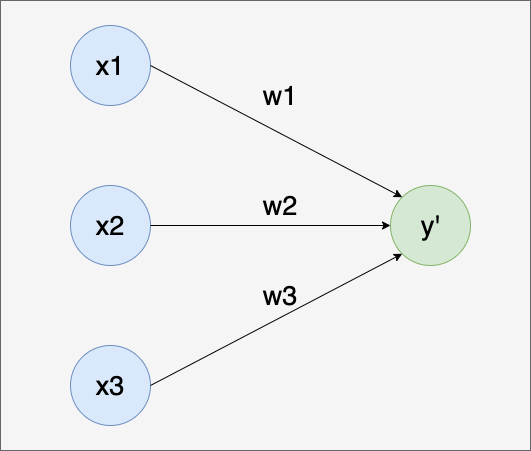
这里x1、x2和x3是神经网络的输入,y’是神经网络的输出(这里省略了偏置参数b),y’也是该网络里唯一一个具有计算功能的神经元,即计算神经元。
一个更具通用意义的与线性模型等价的神经网络结构如下图,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值:
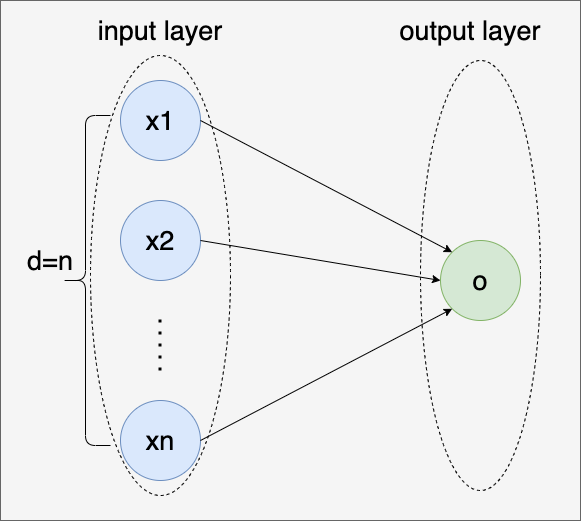
在上面神经网络中,输入为x1、x2…、xn,它们共同构成了该神经网络的输入层(input layer)。没错,在神经网络结构中,我们引入了“层(layer)”的概念。
神经网络中一般有三类层,它们分别是输入层、隐藏层和输出层。大家耳熟能详的(但却不知道具体是什么的)卷积层、池化层等,都可以被视为广义的隐藏层。每一层都包含多个神经元,并通过层与层之间的连接进行信息的前向传播和反向传播。这种分层结构也正是神经网络功能强大的关键。
隐藏层我们暂且不展开,我们就上面的图先来看看输入层。输入层中的输入数称为特征维度d,在上图中,我们有n个输入特征,因此特征维度d=n。在输出层,图中只有一个神经元o,该神经元也是计算神经元,计算后的结果即为神经网络的最终计算结果。
神经网络模型的重点是在发生计算的地方,即计算神经元,因此通常我们在计算神经网络的层数时不考虑输入层,也就是说上图中这个简单的神经网络的层数为1。
由此可以看出:线性回归模型可被视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
1.1 感知器
而这种单层神经网络最早可追溯至1958年罗森布拉特(Roseblatt) 提出的感知器(Perceptron)。这个感知器也是受到了1943年美国神经生理学家沃伦麦卡洛克(Warren McCulloch)和数学家沃尔特皮茨(Walter Pitts)早期对形式神经元模型(又称M-P模型)研究的影响。
下面是感知器的结构图:
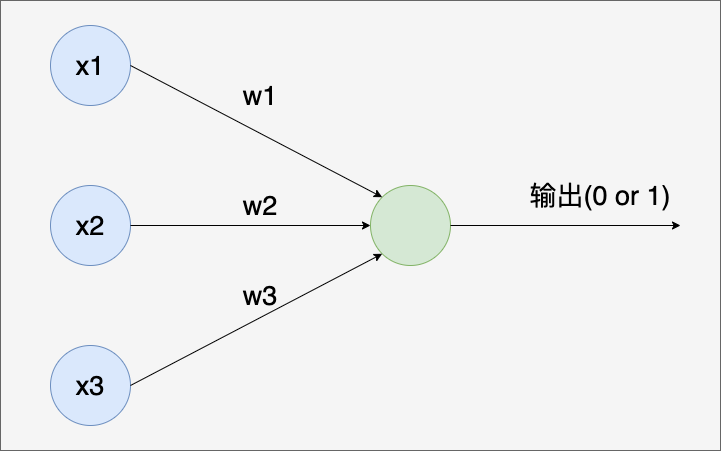
这张感知器的结构图是不是与前面的单层神经网络图十分相近啊。上图中感知器有3个输入x1、x2和x3。一般来说输入还可以更多或更少。Rosenblatt针对这样的一个感知器提出了一条计算输出的简单规则。他引入了权重w1、w2、w3,用这些实数来表示输入对于输出的重要性。感知器的输出由所有输入的加权和来决定,当加权和小于或等于某个阈值时,输出为0;否则当加权和大于某个阈值时,输出为1。
用下图表达感知器的计算过程更为准确:
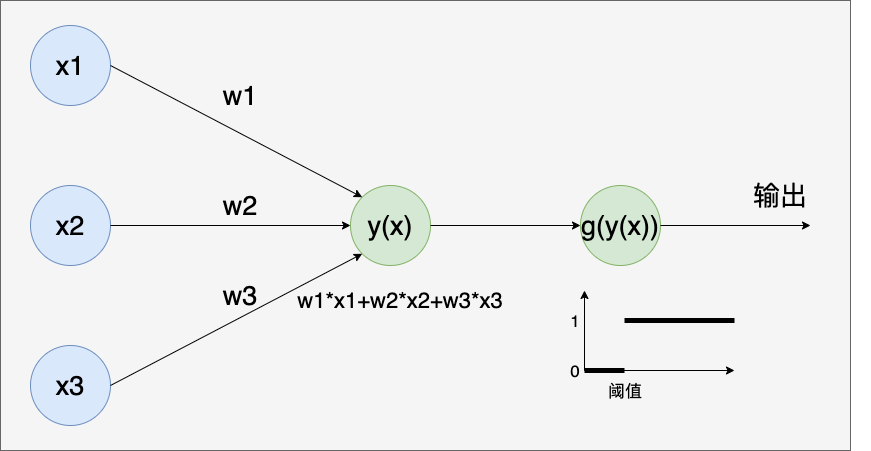
感知器的计算过程是一个阶跃函数g(x)复合一个线性函数f(x)的结果。如果将感知器整体看成一个神经元,那么该神经元的计算就是先计算线性函数,再计算阶跃函数。这个阶跃函数在神经网络中也被称为激活函数,它决定了这个神经元的输出值对后续神经元计算结果的影响程度。当输出为0时,则没有影响;当输出为1时,则有影响。
注:类似于权重,阈值也是实数,也是神经元的一个参数。
这里的激活函数(阶跃函数)是一个二值函数,只能用来决策“是”与“非”,带有这样的激活函数的感知器能够解决的问题有限,这个我们后面再说。
现在我们回到线性回归模型。我们可以将线性回归模型看成是由单个人工神经元组成的神经网络,即感知器,输出是输入特征加权求和后的连续值输出,但没有使用阶跃激活函数,而是使用了恒等激活函数(g(x)=x)。
既然是等价的,那这种单层神经网络也可以用来解决房价预测问题。下面我们就用神经网络结构来重新实现一下房价预测问题的解决方案。
1.2 解决线性回归房价预测问题
下面是使用神经网络的形式解决房价预测问题的实现,该实现使用的训练数据集(train.csv)和验证数据集(test.csv)与上一篇文章《Go与神经网络:线性回归》中使用的保持一致,这样从csv文件中加载数据(readCSV)以及标准化(standardize)的实现也与上一篇文章保持一致,这里就不列出其代码了。
// go-and-nn/ann/linear-regression/main.go
// Initialize a layer with the given number of inputs
func NewLayer(inputSize int) *Layer {
weights := make([]float64, inputSize)
for i := range weights {
weights[i] = 0.01 // small random values, here we use a small constant for simplicity
}
return &Layer{
weights: weights,
bias: 0.0,
}
}
// Forward propagation
func (layer *Layer) Forward(inputs []float64) float64 {
output := layer.bias
for i := range layer.weights {
output += layer.weights[i] * inputs[i]
}
return output
}
// Backward propagation (gradient computation and update)
func (layer *Layer) Backward(inputs []float64, error float64, learningRate float64) {
for i := range layer.weights {
layer.weights[i] -= learningRate * error * inputs[i]
}
layer.bias -= learningRate * error
}
// Training the neural network
func trainModel(data [][]float64, learningRate float64, epochs int) *Layer {
features := len(data[0]) - 1
layer := NewLayer(features)
for epoch := 0; epoch < epochs; epoch++ {
totalError := 0.0
for i := 0; i < len(data); i++ {
inputs := data[i][:features]
target := data[i][features]
prediction := layer.Forward(inputs)
error := prediction - target
totalError += error * error
layer.Backward(inputs, error, learningRate)
}
mse := totalError / float64(len(data))
fmt.Printf("Epoch %d: Weights: %v, Bias: %f, MSE: %f\n", epoch+1, layer.weights, layer.bias, mse)
}
return layer
}
// Evaluate the model
func predictAndEvaluate(data [][]float64, layer *Layer, mean []float64, std []float64) {
features := len(data[0]) - 1
totalError := 0.0
for i := 0; i < len(data); i++ {
standardizedFeatures := make([]float64, features)
for j := 0; j < features; j++ {
standardizedFeatures[j] = (data[i][j] - mean[j]) / std[j]
}
prediction := layer.Forward(standardizedFeatures)
error := prediction - data[i][features]
totalError += error * error
fmt.Printf("Sample %d: Predicted Value: %f, Actual Value: %f\n", i+1, prediction, data[i][features])
}
mse := totalError / float64(len(data))
fmt.Printf("Mean Squared Error: %f\n", mse)
}
func main() {
// Read training data
trainData, err := readCSV("train.csv")
if err != nil {
log.Fatalf("failed to read training data: %v", err)
}
// Read testing data
testData, err := readCSV("test.csv")
if err != nil {
log.Fatalf("failed to read testing data: %v", err)
}
// Standardize training data
standardizedTrainData, mean, std := standardize(trainData)
// Train model
learningRate := 0.01
epochs := 1000
layer := trainModel(standardizedTrainData, learningRate, epochs)
// Evaluate model on test data
predictAndEvaluate(testData, layer, mean, std)
}
我们看到与使用线性回归的实现不同的是,上述代码中定义了一个神经网络层,其中:
- Layer结构体表示神经网络的一层,包括权重和偏置。
- NewLayer函数用于初始化一个神经网络层。
- Layer的Forward方法实现前向传播计算输出。
- Layer的Backward方法实现反向传播计算梯度并更新权重和偏置。
相对于线性回归的实现,这里重新封装后的神经网络layer及其方法更能反映神经网路训练的核心思想,即每次训练迭代,通过前向传播计算预测值,通过反向传播计算梯度并更新模型参数,从而逐步降低损失函数值,优化模型。我们看到:封装为layer后,代码逻辑更清晰,更加模块化,并且可扩展。但本质上的前向传播和反向传播的计算方法并没有变化。
此外由于有了上一篇文章中对应超参值设置的经验,这里我们直接将learningRate设为0.01,epochs设置为1000,上述代码的运行输出结果如下:
$go run main.go
Epoch 1: Weights: [8.728884804818698 8.712975150143901], Bias: 32.778974, MSE: 115152.980580
Epoch 2: Weights: [15.814001516275553 15.78394955947715], Bias: 62.402472, MSE: 92863.737356
Epoch 3: Weights: [21.5696449805642 21.52641203275281], Bias: 89.173336, MSE: 75056.969233
Epoch 4: Weights: [26.243664907505245 26.1876016507747], Bias: 113.365517, MSE: 60777.711866
Epoch 5: Weights: [30.037914029652775 29.96891534482488], Bias: 135.226795, MSE: 49290.960631
Epoch 6: Weights: [33.11676440417245 33.03439154320403], Bias: 154.981251, MSE: 40026.212103
Epoch 7: Weights: [35.6140488515254 35.51762537760745], Bias: 172.831522, MSE: 32537.272869
... ...
Epoch 992: Weights: [59.437027713441424 32.25977558463242], Bias: 339.963336, MSE: 38.985916
Epoch 993: Weights: [59.448440160202296 32.24840584527085], Bias: 339.963329, MSE: 38.980859
Epoch 994: Weights: [59.45984819448098 32.2370405018792], Bias: 339.963322, MSE: 38.975806
Epoch 995: Weights: [59.47125181798348 32.22567955275781], Bias: 339.963315, MSE: 38.970758
Epoch 996: Weights: [59.482651032415184 32.214322996207684], Bias: 339.963308, MSE: 38.965713
Epoch 997: Weights: [59.494045839480805 32.20297083053052], Bias: 339.963300, MSE: 38.960672
Epoch 998: Weights: [59.50543624088439 32.1916230540286], Bias: 339.963293, MSE: 38.955636
Epoch 999: Weights: [59.516822238329354 32.18027966500492], Bias: 339.963286, MSE: 38.950603
Epoch 1000: Weights: [59.52820383351841 32.16894066176312], Bias: 339.963279, MSE: 38.945574
Sample 1: Predicted Value: 215.725493, Actual Value: 210.000000
Sample 2: Predicted Value: 241.257244, Actual Value: 230.000000
Sample 3: Predicted Value: 271.595687, Actual Value: 260.000000
Sample 4: Predicted Value: 304.337476, Actual Value: 310.000000
Sample 5: Predicted Value: 337.079264, Actual Value: 340.000000
Sample 6: Predicted Value: 369.821053, Actual Value: 370.000000
Sample 7: Predicted Value: 402.562841, Actual Value: 400.000000
Sample 8: Predicted Value: 435.304630, Actual Value: 430.000000
Sample 9: Predicted Value: 468.046418, Actual Value: 460.000000
Sample 10: Predicted Value: 500.788207, Actual Value: 490.000000
Mean Squared Error: 55.043119
我们看到,其模型效果与上一篇中优化后的模型差不多。
2. 多层感知器与深度神经网络
2.1 明斯基把感知器“打入冷宫”
1969年,AI的创始人之一马文·明斯基(Marvin Minsky)指出了简单神经网络,比如单层感知器的局限性,即只能运用于线性问题的求解。
单层感知器可以理解为一个简单的神经网络,由输入层和输出层组成。它通过以下方式进行计算:
y = f(w * x + b)
其中: w 是权重向量,x是输入向量,b是偏置,f是激活函数,通常为阶跃函数或线性函数。
单层感知器可以解决线性可分问题,即通过一条直线(在高维空间中是一个超平面)可以将数据分类的情况。例如,AND和OR逻辑门的输出可以通过一条直线分开,用下图可以直观地表示出来(参考《动手零基础机器学习》一书的图绘制):
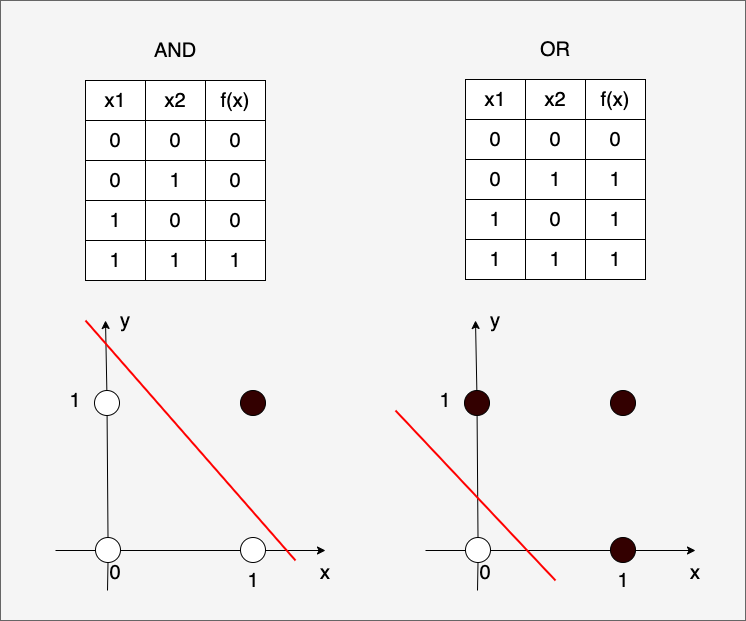
但对于非线性的异或问题(XOR),比如下图,无论我们用哪个线性函数所代表的直线都无法划分开,比如下面二维平面上的XOR问题:
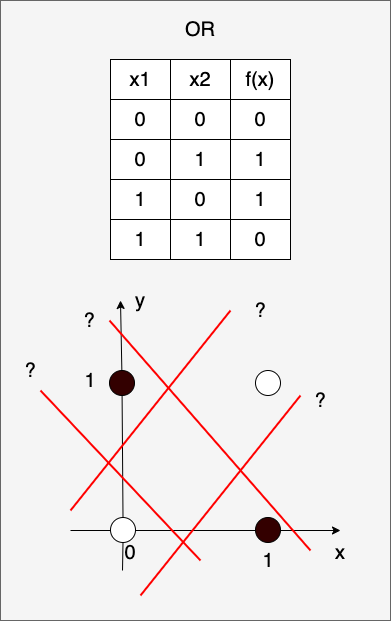
这就是单一感知器的局限。
为了处理XOR等非线性问题,我们需要使用多层感知器(即包含一个或多个隐藏层的神经网络)。多层感知器(Multiple Layer Perceptron, MLP)能够解决单层感知器(即感知器)无法解决的非线性问题,主要是因为引入了非线性的隐藏层,从而扩展了模型的假设空间。 多层感知器通过增加一个或多个隐藏层,使得模型能够表示更复杂的函数。每一层中的神经元节点通过激活函数(例如 Sigmoid, ReLU 等)将输入映射到非线性空间。根据“通用近似定理”(Universal Approximation Theorem),一个包含足够数量的隐藏层和隐藏单元的多层感知器可以以任意精度逼近任何连续函数。这意味着MLP理论上可以学习和表示任何复杂的非线性关系。下图就是一个利用非线性关系解决XOR问题的示意图:
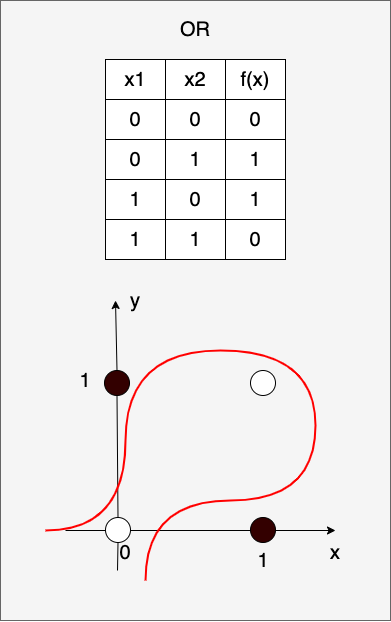
接下来,我们就用多层感知器训练来得到一个可以解决XOR问题的模型。
2.2 多层感知器解决XOR问题
说是多层感知器,但这个结构中并没有真正使用感知器的激活函数:阶跃函数。多层感知器中使用的是像sigmoid、ReLU等函数的激活函数,这些函数可以为感知器带来非线性。以下面的sigmoid函数为例:
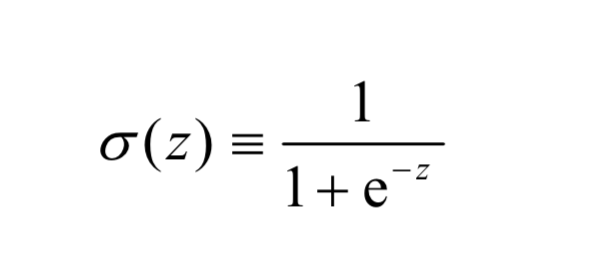
而它的函数图像如下:
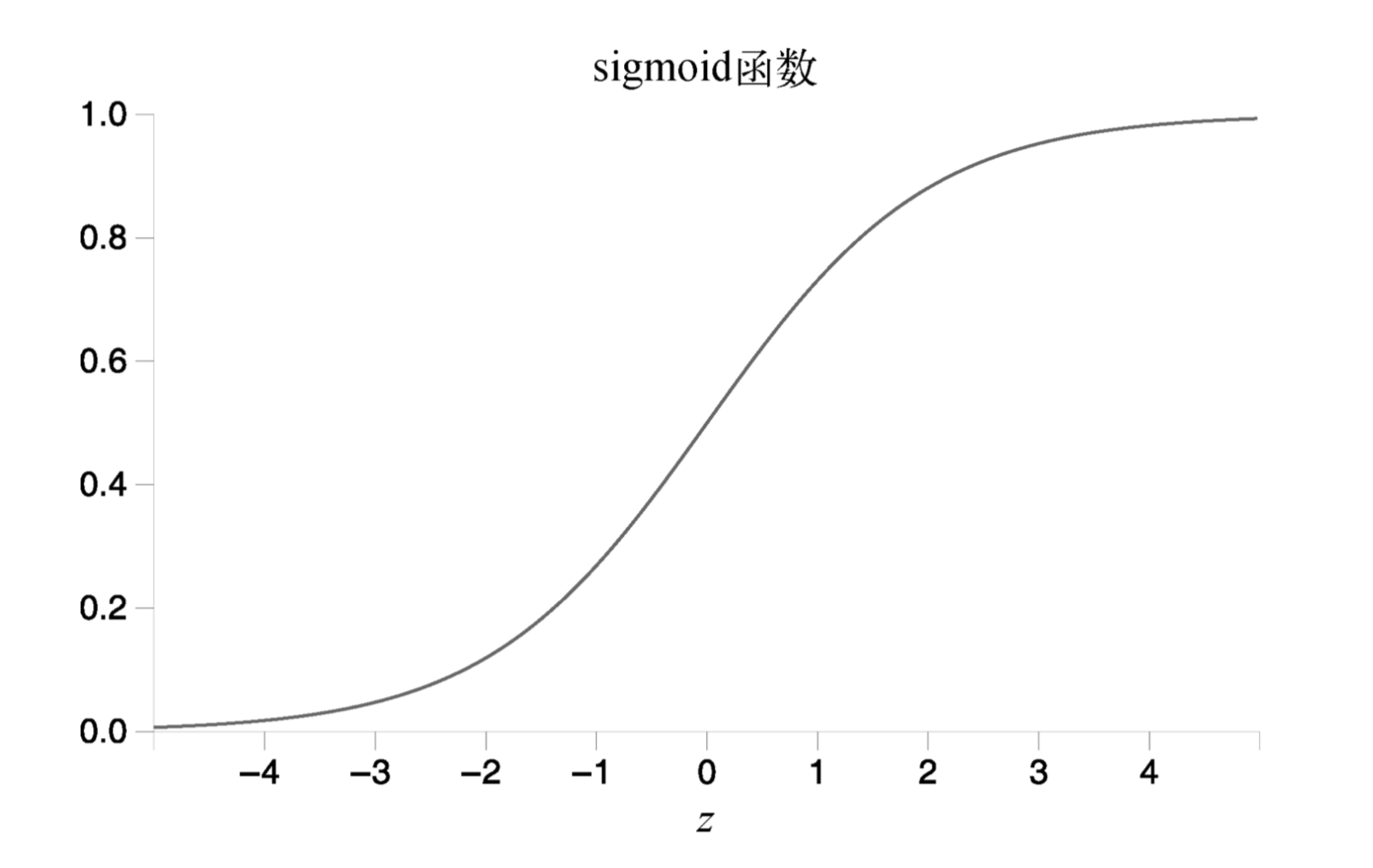
由sigmoid函数复合线性函数所构成的计算神经元被称为sigmoid神经元。sigmoid神经元与感知器之间的一个很大的区别是sigmoid神经元不仅仅输出0或1,它可以输出0到1之间的任何实数,0.173…和0.689…等都是合理的输出,这非常有用。sigmoid神经元被用于构建神经网络的隐藏层,并对输入进行变换。这些非线性函数将输入映射到更高维度的空间,使得在该空间中,数据可以通过非线性决策边界分开。此外,由于历史的原因,由sigmoid神经元而不是感知机构成的多层神经网络,但仍被称为多层感知器。
下面我们就用一个利用sigmoid神经元构造隐藏层的神经网络来解决一下XOR问题,这个神经网络模型的结构示意图如下:
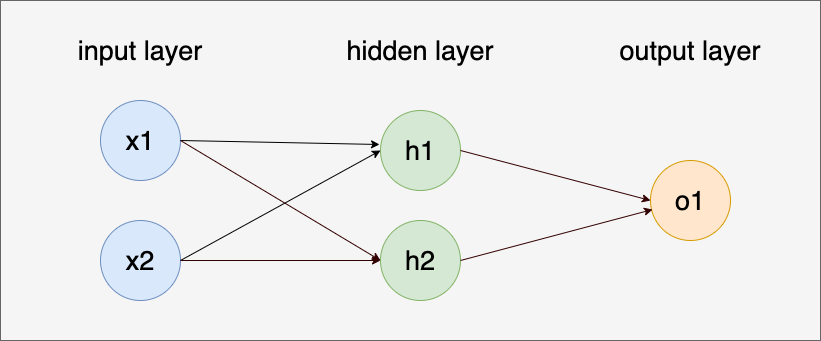
这个神经网络的输入层有两个输入节点,分别对应XOR问题的两个输入。 中间是隐藏层,有两个隐藏节点,每个节点都接收来自所有输入节点的输入,并通过激活函数(Sigmoid 函数)进行处理。 输出层有一个输出节点,它接收来自所有隐藏层节点的输入,并通过激活函数(Sigmoid 函数)进行处理。
注:从图中可以看到,上面的多层感知器(MLP)是一种全连接神经网络(Fully Connected Neural Network, FCNN)。全连接神经网络是指网络中的每一个神经元都与前一层的每一个神经元相连接。这种结构在每一层都完全连接,确保信息能够充分传递和组合。不过,全连接神经网络(FCNN)的定义比多层感知器(MLP)更为广泛,因此虽然所有的MLP都是FCNN,但并不是所有的FCNN都是MLP。MLP是一种特定的FCNN,具有明确的层次结构和用于监督学习的目标,而FCNN可以包含更广泛的模型,包括一些不符合传统MLP定义的结构和用途。
下面是解决该XOR问题的MLP的训练和验证的Go代码,该示例仅仅用于展示一个包含足够数量的隐藏层和隐藏单元的多层感知器可以以任意精度逼近任何连续函数,即MLP理论上可以学习和表示任何复杂的非线性关系:
// go-and-nn/ann/xor/main.go
// Activation function (Sigmoid)
func sigmoid(x float64) float64 {
return 1.0 / (1.0 + math.Exp(-x))
}
// Derivative of the sigmoid function
func sigmoidDerivative(x float64) float64 {
return x * (1.0 - x)
}
// MLP structure
type MLP struct {
inputLayer []float64
hiddenLayer []float64
outputLayer []float64
weightsInputHidden [][]float64
weightsHiddenOutput []float64
learningRate float64
}
// Initialize the MLP
func (mlp *MLP) Initialize(inputSize, hiddenSize, outputSize int, learningRate float64) {
mlp.inputLayer = make([]float64, inputSize)
mlp.hiddenLayer = make([]float64, hiddenSize)
mlp.outputLayer = make([]float64, outputSize)
mlp.weightsInputHidden = make([][]float64, inputSize)
for i := 0; i < inputSize; i++ {
mlp.weightsInputHidden[i] = make([]float64, hiddenSize)
for j := 0; j < hiddenSize; j++ {
mlp.weightsInputHidden[i][j] = randWeight()
}
}
mlp.weightsHiddenOutput = make([]float64, hiddenSize)
for i := 0; i < hiddenSize; i++ {
mlp.weightsHiddenOutput[i] = randWeight()
}
mlp.learningRate = learningRate
}
// Forward pass
func (mlp *MLP) Forward(inputs []float64) []float64 {
// Input to Hidden
for j := 0; j < len(mlp.hiddenLayer); j++ {
mlp.hiddenLayer[j] = 0
for i := 0; i < len(mlp.inputLayer); i++ {
mlp.hiddenLayer[j] += inputs[i] * mlp.weightsInputHidden[i][j]
}
mlp.hiddenLayer[j] = sigmoid(mlp.hiddenLayer[j])
}
// Hidden to Output
for k := 0; k < len(mlp.outputLayer); k++ {
mlp.outputLayer[k] = 0
for j := 0; j < len(mlp.hiddenLayer); j++ {
mlp.outputLayer[k] += mlp.hiddenLayer[j] * mlp.weightsHiddenOutput[j]
}
mlp.outputLayer[k] = sigmoid(mlp.outputLayer[k])
}
return mlp.outputLayer
}
// Training using backpropagation
func (mlp *MLP) Train(inputs [][]float64, targets [][]float64, epochs int) {
for epoch := 0; epoch < epochs; epoch++ {
for idx, input := range inputs {
outputs := mlp.Forward(input)
// Calculate output layer errors and deltas
outputErrors := make([]float64, len(mlp.outputLayer))
outputDeltas := make([]float64, len(mlp.outputLayer))
for k := 0; k < len(mlp.outputLayer); k++ {
outputErrors[k] = targets[idx][k] - outputs[k]
outputDeltas[k] = outputErrors[k] * sigmoidDerivative(outputs[k])
}
// Calculate hidden layer errors and deltas
hiddenErrors := make([]float64, len(mlp.hiddenLayer))
hiddenDeltas := make([]float64, len(mlp.hiddenLayer))
for j := 0; j < len(mlp.hiddenLayer); j++ {
hiddenErrors[j] = 0
for k := 0; k < len(mlp.outputLayer); k++ {
hiddenErrors[j] += outputDeltas[k] * mlp.weightsHiddenOutput[j]
}
hiddenDeltas[j] = hiddenErrors[j] * sigmoidDerivative(mlp.hiddenLayer[j])
}
// Update weights for Hidden to Output
for j := 0; j < len(mlp.hiddenLayer); j++ {
for k := 0; k < len(mlp.outputLayer); k++ {
mlp.weightsHiddenOutput[j] += mlp.learningRate * outputDeltas[k] * mlp.hiddenLayer[j]
}
}
// Update weights for Input to Hidden
for i := 0; i < len(mlp.inputLayer); i++ {
for j := 0; j < len(mlp.hiddenLayer); j++ {
mlp.weightsInputHidden[i][j] += mlp.learningRate * hiddenDeltas[j] * input[i]
}
}
}
if epoch%1000 == 0 {
error := 0.0
for i, input := range inputs {
outputs := mlp.Forward(input)
for k := 0; k < len(mlp.outputLayer); k++ {
error += math.Pow(targets[i][k]-outputs[k], 2)
}
}
fmt.Printf("Epoch %d, Error: %f\n", epoch, error)
}
}
}
// Helper function to generate random weight
func randWeight() float64 {
return rand.Float64()*2 - 1 // Random weight between -1 and 1
}
// Main function
func main() {
rand.Seed(time.Now().UnixNano())
inputs := [][]float64{
{0, 0},
{0, 1},
{1, 0},
{1, 1},
}
targets := [][]float64{
{0},
{1},
{1},
{0},
}
mlp := MLP{}
mlp.Initialize(2, 2, 1, 0.1) // Increased hidden layer size to 2
mlp.Train(inputs, targets, 20000) // Increased epochs to 20000
fmt.Println("Trained model parameters:")
fmt.Println("Hidden Layer Weights:", mlp.weightsInputHidden)
fmt.Println("Output Layer Weights:", mlp.weightsHiddenOutput)
fmt.Println("\nTesting the neural network:")
for _, input := range inputs {
predicted := mlp.Forward(input)
class := 0
if predicted[0] >= 0.5 {
class = 1
}
fmt.Printf("Input: %v, Predicted: %v, Classified as: %d, Actual: %v\n", input, predicted, class, targets)
}
}
有了前面对神经网络训练原理作为基础,再理解这段示例代码就容易多了,只是这里多了一个隐藏层,代码将整个神经网络封装到一个名为MLP的类型中,该类型的Forward方法实现前向传播计算,通过输入层到隐藏层,再到输出层。Train方法实现反向传播训练,更新权重。输入和目标数据现在是二维数组,表示多条训练样本。在模型测试阶段,通过设置阈值0.5来将神经网络的输出值转化为分类结果,从而得到明确的分类结果。这种方法可以更准确地确定每个样本属于哪一类。
我们运行一下该代码:
$go run main.go
Epoch 0, Error: 1.001896
Epoch 1000, Error: 0.996300
Epoch 2000, Error: 0.977860
Epoch 3000, Error: 0.881434
Epoch 4000, Error: 0.733544
Epoch 5000, Error: 0.607196
Epoch 6000, Error: 0.509769
Epoch 7000, Error: 0.434591
Epoch 8000, Error: 0.375748
Epoch 9000, Error: 0.328935
Epoch 10000, Error: 0.291102
Epoch 11000, Error: 0.260083
Epoch 12000, Error: 0.234317
Epoch 13000, Error: 0.212660
Epoch 14000, Error: 0.194264
Epoch 15000, Error: 0.178488
Epoch 16000, Error: 0.164841
Epoch 17000, Error: 0.152943
Epoch 18000, Error: 0.142496
Epoch 19000, Error: 0.133264
Trained model parameters:
Hidden Layer Weights: [[6.5952517156621395 0.8739403187885498] [6.587550620852982 0.87284609499487]]
Output Layer Weights: [15.12268364344881 -19.22613598232755]
Testing the neural network:
Input: [0 0], Predicted: [0.11387807762931963], Classified as: 0, Actual: [[0] [1] [1] [0]]
Input: [0 1], Predicted: [0.8236051399161078], Classified as: 1, Actual: [[0] [1] [1] [0]]
Input: [1 0], Predicted: [0.8229923791763072], Classified as: 1, Actual: [[0] [1] [1] [0]]
Input: [1 1], Predicted: [0.22282071968348732], Classified as: 0, Actual: [[0] [1] [1] [0]]
我们看经过20000轮训练,我们得到了一组可以表示解决XOR问题的非线性关系的函数权重参数,经过验证,可以得到正确的预测结果。
如果训练处的模型效果不好,我们可以调整超参,比如学习率、训练轮数,也可以修改隐藏层的神经元数量,比如从2改为4等。
多层感知器的出现和应用引发了后续基于深度神经网络的深度学习革命,接下来我们就来用深度学习的一个“Hello, World”任务来入门一下深度神经网络。
3. 手写数字识别:神经网络和深度学习的双料“Hello, World”任务
3.1 从多层感知器到深度神经网络
通过前面的学习,我们了解到感知器只能解决线性可分问题,而多层感知器通过增加隐藏层,可以处理非线性可分问题,例如上面的XOR问题。多层感知器通过多层结构和非线性激活函数,可以学习到更复杂的函数映射关系,从而提升模型的表现力。
尽管MLP增加了网络的复杂性以及模型表现力,但在初期,由于缺乏有效的训练算法,训练深层网络(且是全连接网络)仍然面临巨大挑战。20世纪80年代,反向传播(Backpropagation)算法的提出解决了这一问题。反向传播通过计算损失函数相对于各层权重的梯度,并使用梯度下降法进行参数更新,使得训练深层网络成为可能。
随着反向传播算法的成熟和计算资源的提升,研究者开始探索更深的神经网络结构,即深度神经网络(DNN)。DNN通常包含多个隐藏层,每层可以提取不同层次的特征,从而大幅提升模型的表示能力和预测精度。
相对于MLP,深度网络在下面几个关键方面又做了改进:
- 激活函数的改进:ReLU、Leaky ReLU、eLU等激活函数的引入有效缓解了梯度消失和梯度爆炸问题。
- 正则化技术:Dropout和Batch Normalization等技术的应用提高了深度网络的泛化能力和训练效率。
- 残差连接(residual connection):真正解决梯度消失问题。它的基本思想是:在大型深度网络中(至少10层以上),让前面某层的输出跨越多层直接输入至较靠后的层,形成神经网络中的捷径(shortcut)。这样,就不必担心过大的网络中梯度逐渐消失的问题了。
- 网络结构创新:研究者为特定类任务发明了卷积神经网络(CNN)和循环神经网络(RNN),前者专为处理图像数据设计,具有局部连接和参数共享的特性,提高了计算效率和模型性能。而后者和长短期记忆网络(LSTM)一起专为处理序列数据设计,能够捕捉时间序列中的长依赖关系。
当然算法的进步离不开硬件的发展。GPU的崛起大大加速了大规模并行计算,使得训练深度神经网络变得切实可行。
注:随着层数的增加,网络最终变得无法训练。神经网络梯度下降的原理是将来自输出损失的反馈信号反向传播到更底部的层。如果这个反馈信号的传播需要经过很多层,那么信号可能会变得非常微弱,甚至完全丢失,梯度无法传到的层就好比没有经过训练一样。这就是梯度消失。而梯度爆炸则是指神经元权重过大时,网络中较前面层的梯度通过训 练变大,而后面层的梯度呈指数级增大。梯度爆炸和梯度消失问题都是因为网络太深、网络权重更新不 稳定造成的,本质上都是梯度反向传播中的连锁效应。
深度神经网络是一个较大的领域,这里仅打算用一个神经网络和深度学习的双料入门问题:手写数字识别任务来感受一下深度神经网络的威力。接下来,我们先来说说这是一个什么任务。
3.2 手写数字识别任务介绍
在图灵奖得主杨立昆(Yann LeCun)的个人主页上,我们能看到对手写数字识别以及对应的公开数据集MNIST的介绍。
手写数字识别任务是神经网络和深度学习领域中的经典入门任务之一。它不仅涵盖了基本的机器学习和深度学习技术,还提供了一个清晰、易理解的应用实例。
手写数字识别任务旨在通过计算机自动识别手写数字图像中的数字。这项任务最常用的数据集是MNIST数据集,它包含了大量的手写数字图像及其对应的标签。MNIST数据集被广泛用于评估和比较不同的机器学习算法和模型。MNIST数据集包含60000张训练图像和10000张测试图像,每张图像都是28×28像素的灰度图,代表从0到9的手写数字。每个图像都被标注了一个对应的数字标签(0-9)。

从杨立昆关于该任务的主页来看,这是一个时间跨度和方法跨度都很大的任务。从1998年使用线性分类器(一个单层神经网络)到2011和2012年的深度卷积神经网络,解决该问题的模型的数字识别精度也从80%多提升到97%以上。
接下来,我们用一个多层MLP(简单全连接神经网络)来解决一下该问题。
3.3 手写数字识别解决示例
下面是解决手写数字识别问题的神经网络结构的示意图:
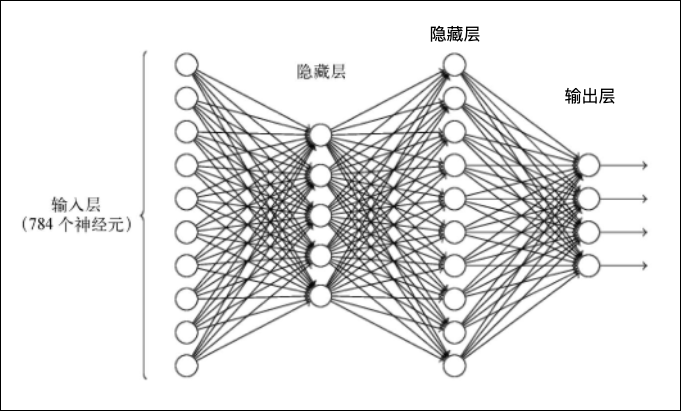
上图改自《深入浅出神经网络与深度学习》一书
这依然是一个全连接神经网络,该网络有两个隐藏层和一个输出层,隐藏层的神经元个数分别为128个和64个(与图中的展示略有差异),并且隐藏层使用的激活函数为ReLU。ReLU是一种常用的非线性激活函数,其定义如下:
f(x) = max(0, x)
也就是如果输入x大于0,则输出为x本身;如果输入x小于等于0,则输出为0。ReLU计算复杂度很低,可以大大加快神经网络的训练速度。其引入的非线性使得神经网络能够拟合更复杂的函数。当输入大于0时,ReLU的导数恒为1,这有助于梯度的有效传播。
输出层则用了一个Softmax函数,它是一种广泛用于多分类问题的激活函数。给定一个k维输入向量z = (z0, z1, …, zk),Softmax函数的定义如下:
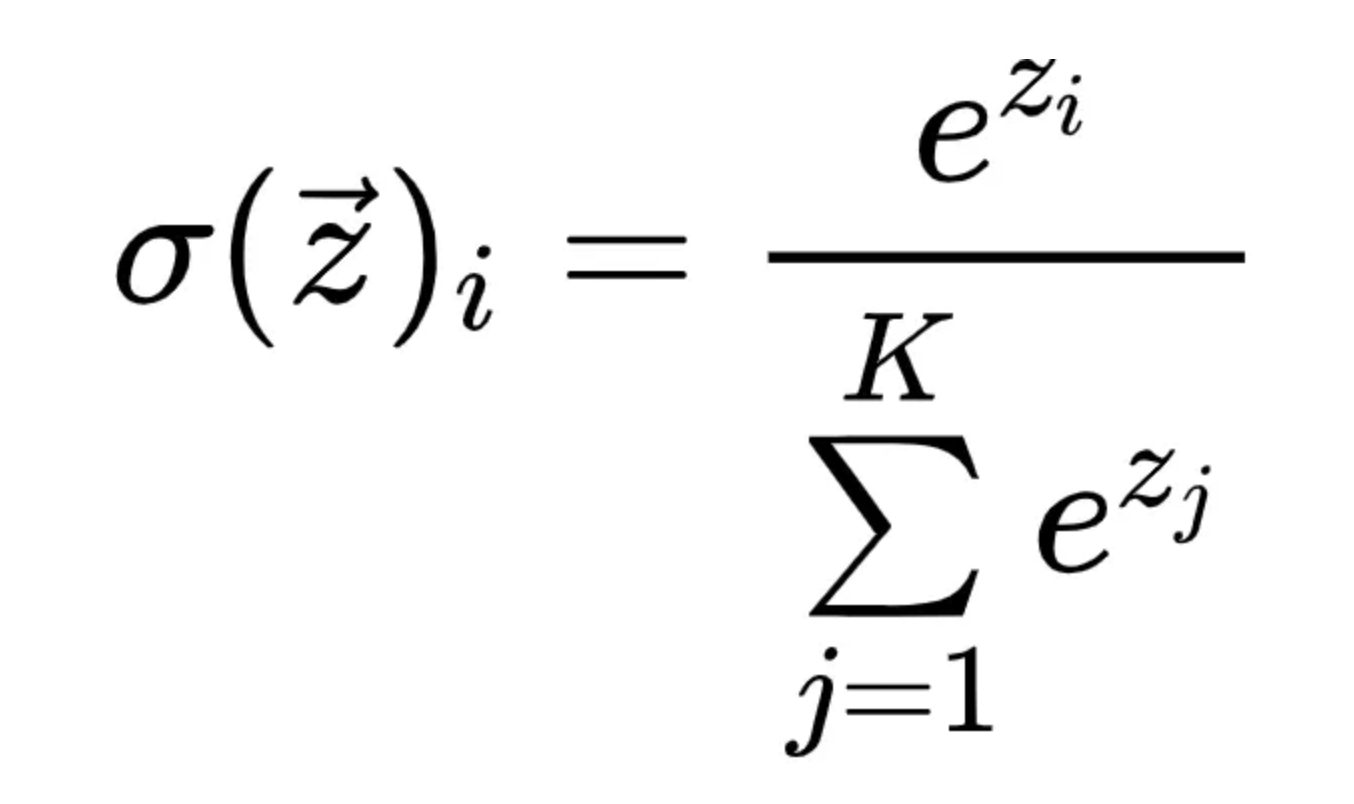
Softmax函数的输出是非负的且总和为1,因此可以被解释为概率分布。它还放大了较大值,抑制了较小值,使得输出更加”尖锐”。并且,它的导数简单,便于反向传播计算梯度。
下面是手写数字识别的神经网络的训练和效果评估的实现:
// go-and-nn/ann/handwritten-digit-recognition/main.go
package main
... ...
// DNN结构体定义
type DNN struct {
inputSize int
hiddenSize1 int
hiddenSize2 int
outputSize int
learningRate float64
weights1 [][]float64
weights2 [][]float64
weights3 [][]float64
}
// 激活函数和其导数
func relu(x float64) float64 {
if x > 0 {
return x
}
return 0
}
func reluDerivative(x float64) float64 {
if x > 0 {
return 1
}
return 0
}
func softmax(x []float64) []float64 {
expSum := 0.0
for i := range x {
x[i] = math.Exp(x[i])
expSum += x[i]
}
for i := range x {
x[i] /= expSum
}
return x
}
... ...
// 初始化权重
func initializeWeights(inputSize, outputSize int) [][]float64 {
weights := make([][]float64, inputSize)
for i := range weights {
weights[i] = make([]float64, outputSize)
for j := range weights[i] {
weights[i][j] = rand.Float64()*2 - 1
}
}
return weights
}
// DNN结构体的方法
func (dnn *DNN) forward(input []float64) ([]float64, []float64, []float64) {
hidden1 := make([]float64, len(dnn.weights1[0]))
for i := range hidden1 {
for j := range input {
hidden1[i] += input[j] * dnn.weights1[j][i]
}
hidden1[i] = relu(hidden1[i])
}
hidden2 := make([]float64, len(dnn.weights2[0]))
for i := range hidden2 {
for j := range hidden1 {
hidden2[i] += hidden1[j] * dnn.weights2[j][i]
}
hidden2[i] = relu(hidden2[i])
}
output := make([]float64, len(dnn.weights3[0]))
for i := range output {
for j := range hidden2 {
output[i] += hidden2[j] * dnn.weights3[j][i]
}
}
output = softmax(output)
return hidden1, hidden2, output
}
func (dnn *DNN) train(images [][]float64, labels []int, epochs int) {
for epoch := 0; epoch < epochs; epoch++ {
totalLoss := 0.0
for i, input := range images {
label := labels[i]
// 前向传播
hidden1, hidden2, output := dnn.forward(input)
// 计算损失和误差
target := make([]float64, dnn.outputSize)
target[label] = 1.0
outputError := make([]float64, dnn.outputSize)
for j := range output {
outputError[j] = target[j] - output[j]
totalLoss += 0.5 * (target[j] - output[j]) * (target[j] - output[j])
}
hidden2Error := make([]float64, dnn.hiddenSize2)
for j := range hidden2 {
for k := range outputError {
hidden2Error[j] += outputError[k] * dnn.weights3[j][k]
}
hidden2Error[j] *= reluDerivative(hidden2[j])
}
hidden1Error := make([]float64, dnn.hiddenSize1)
for j := range hidden1 {
for k := range hidden2Error {
hidden1Error[j] += hidden2Error[k] * dnn.weights2[j][k]
}
hidden1Error[j] *= reluDerivative(hidden1[j])
}
// 反向传播和权重更新
for j := range dnn.weights3 {
for k := range dnn.weights3[j] {
dnn.weights3[j][k] += dnn.learningRate * outputError[k] * hidden2[j]
}
}
for j := range dnn.weights2 {
for k := range dnn.weights2[j] {
dnn.weights2[j][k] += dnn.learningRate * hidden2Error[k] * hidden1[j]
}
}
for j := range dnn.weights1 {
for k := range dnn.weights1[j] {
dnn.weights1[j][k] += dnn.learningRate * hidden1Error[k] * input[j]
}
}
}
fmt.Printf("Epoch %d/%d, Loss: %f\n", epoch+1, epochs, totalLoss/float64(len(images)))
}
}
func (dnn *DNN) predict(input []float64) int {
_, _, output := dnn.forward(input)
maxIndex := 0
for i := range output {
if output[i] > output[maxIndex] {
maxIndex = i
}
}
return maxIndex
}
func (dnn *DNN) evaluate(images [][]float64, labels []int) float64 {
correct := 0
for i, input := range images {
prediction := dnn.predict(input)
if prediction == labels[i] {
correct++
}
}
return float64(correct) / float64(len(labels))
}
// NewDNN 创建和初始化DNN
func NewDNN(inputSize, hiddenSize1, hiddenSize2, outputSize int, learningRate float64) *DNN {
return &DNN{
inputSize: inputSize,
hiddenSize1: hiddenSize1,
hiddenSize2: hiddenSize2,
outputSize: outputSize,
learningRate: learningRate,
weights1: initializeWeights(inputSize, hiddenSize1),
weights2: initializeWeights(hiddenSize1, hiddenSize2),
weights3: initializeWeights(hiddenSize2, outputSize),
}
}
func main() {
rand.Seed(time.Now().UnixNano())
trainImages, err := loadMNISTImages("train-images.idx3-ubyte")
if err != nil {
fmt.Println("Failed to load training images:", err)
return
}
trainLabels, err := loadMNISTLabels("train-labels.idx1-ubyte")
if err != nil {
fmt.Println("Failed to load training labels:", err)
return
}
testImages, err := loadMNISTImages("t10k-images.idx3-ubyte")
if err != nil {
fmt.Println("Failed to load test images:", err)
return
}
testLabels, err := loadMNISTLabels("t10k-labels.idx1-ubyte")
if err != nil {
fmt.Println("Failed to load test labels:", err)
return
}
epochs := 10
learningRate := 0.01
dnn := NewDNN(28*28, 128, 64, 10, learningRate)
dnn.train(trainImages, trainLabels, epochs)
accuracy := dnn.evaluate(testImages, testLabels)
fmt.Printf("Model accuracy on test set: %.2f%\n", accuracy*100)
}
我们看到这段代码的整体结构和之前的神经网络训练和验证代码差不多。数据加载这里没有贴出来,大家可以到代码库中自行阅读,数据读取完全按照MNIST数据集特征数据和标签数据文件的格式进行(这个格式在杨立昆的THE MNIST DATABASE of handwritten digits页面有介绍)。前向传播时,每个隐藏层神经元都是一个线性函数(省略偏置)+ReLU,输出层也是线性函数+Softmax函数。反向传播使用的损失函数也是均方差。
超参中,学习率为0.01,轮次为10轮。训练后,用测试集验证模型权重,用输出层得到的数组中找到SoftMax后值最大的那个元素,其下标值即为手写数字的值。与测试集的标签比对后,确定预测是否正确。
我们运行一下上述程序,这个过程需要花上几分钟:
# go run main.go
Epoch 1/10, Loss: 0.205671
Epoch 2/10, Loss: 0.080040
Epoch 3/10, Loss: 0.053254
Epoch 4/10, Loss: 0.042409
Epoch 5/10, Loss: 0.035353
Epoch 6/10, Loss: 0.030497
Epoch 7/10, Loss: 0.027139
Epoch 8/10, Loss: 0.023803
Epoch 9/10, Loss: 0.022004
Epoch 10/10, Loss: 0.020014
Model accuracy on test set: 95.17%
我们看到一次训练,我们训练出的模型在测试集的手写数字识别率就能达到95%以上。
这里我们就不再对模型进行调优了。此外,手写数字识别任务的模型训练算法有太多种,使用更高级的深度学习算法以及并发加速训练过程的优化工作,在这篇入门文章中也不展开介绍了。
4. 小结
关于基于深度神经网络解决手写数字识别问题的内容就说到这里了。
在这篇文章中,我们先回顾了在上一篇文章中使用线性回归预测房价的方法,并指出线性回归模型也可以视为一种单层神经网络。通过对比线性回归模型与感知器的结构图,我们介绍了感知器这一早期的神经网络模型。感知器虽然能解决一些简单的二分类问题,但由于使用了阶跃函数作为激活函数,其解决问题的能力是有限的。
接下来,我们将线性回归模型重新用神经网络的形式实现了一遍,通过这个过程加深了读者对单层神经网络的理解。这种过渡性的做法可以很好地引导大家从熟悉的线性模型平滑地切入到神经网络领域。
之后,我们在前文的基础上,了解了感知器的不足,并了解了如何通过引入更多隐藏层的多层感知器解决“线性不可分”的XOR问题,进而来到深度神经网络。并结合深度学习中的经典的手写数字识别问题,看到了多层/深度神经网络的强大的非线性表示能力。
在通往大模型理解的道路,我们又进了一步,虽然这里我们还没有介绍深度学习的一些高级算法,比如循环神经网络和卷积神经网络。
有了多层深度神经网络这柄利器后,接下来我将和大家一起走近机器学习的一个重要分支:自然语言处理(NLP),看看在NLP领域机器学习能解决哪些问题!
本文涉及的源码可以在这里下载 – https://github.com/bigwhite/experiments/blob/master/go-and-nn/ann
本文中的部分源码由OpenAI的GPT-4o生成。
5. 参考资料
- 《科学之路》 – https://book.douban.com/subject/35560368/
- 《图解深度学习》 – https://book.douban.com/subject/30221593/
- 《Python深度学习(第二版)》 – https://book.douban.com/subject/36078304/
- 鱼书《深度学习入门:基于Python的理论与实现》 – https://book.douban.com/subject/30270959/
- 苹果书《深入浅出神经网络与深度学习》 – https://book.douban.com/subject/35128111/
- 《人工智能:现代方法(第4版)》 – https://book.douban.com/subject/36152133/
- 《零基础学机器学习》 – https://book.douban.com/subject/35264202/
- 《动手学深度学习2nd-pytorch版》 – https://zh-v2.d2l.ai
- 《深度学习进阶:自然语言处理》 – https://book.douban.com/subject/35225413/
- 《机器学习:Go语言实现》 – https://book.douban.com/subject/30457083/
- 《深度学习入门2:自制框架》 – https://book.douban.com/subject/36303408/
Gopher部落知识星球在2024年将继续致力于打造一个高品质的Go语言学习和交流平台。我们将继续提供优质的Go技术文章首发和阅读体验。同时,我们也会加强代码质量和最佳实践的分享,包括如何编写简洁、可读、可测试的Go代码。此外,我们还会加强星友之间的交流和互动。欢迎大家踊跃提问,分享心得,讨论技术。我会在第一时间进行解答和交流。我衷心希望Gopher部落可以成为大家学习、进步、交流的港湾。让我相聚在Gopher部落,享受coding的快乐! 欢迎大家踊跃加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) – https://gopherdaily.tonybai.com
我的联系方式:
- 微博(暂不可用):https://weibo.com/bigwhite20xx
- 微博2:https://weibo.com/u/6484441286
- 博客:tonybai.com
- github: https://github.com/bigwhite
- Gopher Daily归档 – https://github.com/bigwhite/gopherdaily

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。