
本文永久链接 – https://tonybai.com/2026/01/21/integrating-cuda-in-go
大家好,我是Tony Bai。
长期以来,高性能计算(HPC)和 GPU 编程似乎是 C++ 开发者的专属领地。Go 语言虽然在并发和服务端开发上表现卓越,但在触及 GPU 算力时,往往显得力不从心。
然而,在最近的 GopherCon 2025 上,软件架构师 Sam Burns 打破了这一刻板印象。他展示了如何通过 Go 和 CUDA 的结合,让 Gopher 也能轻松驾驭 GPU 的海量核心,实现惊人的并行计算能力。
本文将带你深入这场演讲的核心,从 GPU 的独特架构到内存模型,再通过一个完整的、可运行的矩阵乘法示例,手把手教你如何用 Go 驱动 NVIDIA 显卡释放澎湃算力。

为什么 Go 开发者需要关注 GPU?
在摩尔定律逐渐失效的今天,CPU 的单核性能提升已遇瓶颈。虽然 CPU 拥有极低的延迟、卓越的分支预测能力和巨大的缓存,但它的核心数量(通常在几十个量级)限制了其处理大规模并行任务的能力。
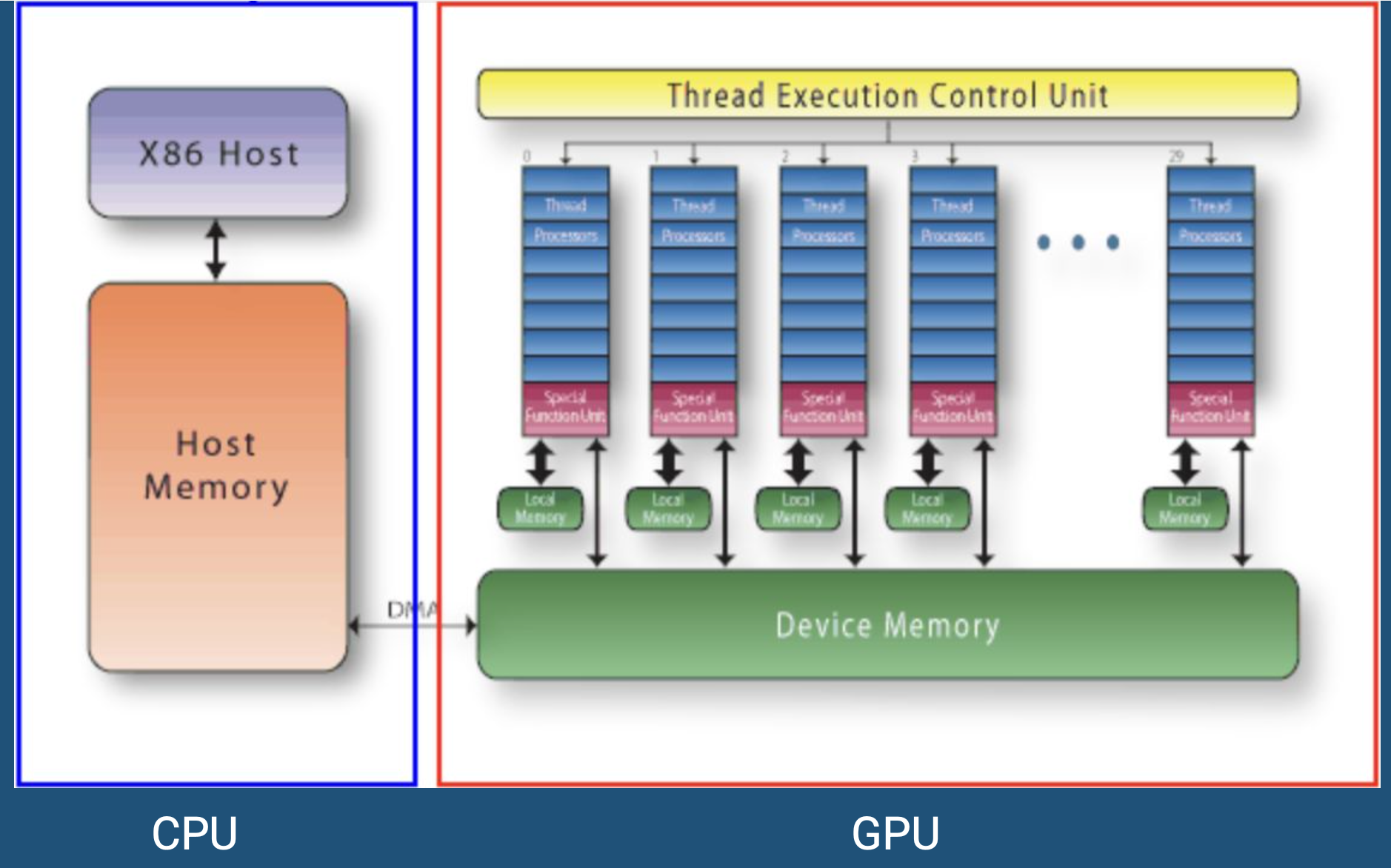
相比之下,GPU (Graphics Processing Unit) 走的是另一条路。它拥有成千上万个核心。虽然单个 GPU 核心的频率较低,且缺乏复杂的逻辑控制能力,但它们能同时处理海量简单的计算任务。这使得 GPU 成为以下场景的绝佳选择:
- 图形处理与视频转码
- AI 模型推理与训练(神经网络本质上就是大规模矩阵运算)
- 物理模拟与科学计算(如流体力学、分子动力学)
- 密码学与哈希碰撞
通过 Go 语言集成 CUDA,我们可以在享受 Go 语言高效开发体验(构建 API、微服务、调度逻辑)的同时,将最繁重的“脏活累活”卸载给 GPU,实现 CPU 负责逻辑,GPU 负责算力 的完美分工。
GPU架构与CUDA编程模型速览——理解 GPU 的“兵团”
在编写代码之前,我们需要理解 GPU 的独特架构。Sam Burns 用一个形象的比喻描述了 GPU 的线程模型。如果说 CPU 是几位精通各种技能的“专家”,那么 GPU 就是一支纪律严明、规模庞大的“兵团”。

而指挥这支兵团的指令集,我们称之为 “内核” (Kernel)。
0. 什么是 Kernel?
此 Kernel 非彼 Kernel(操作系统内核)。在 CUDA 语境下,Kernel 是一个运行在 GPU 上的函数。
当我们“启动”一个 Kernel 时,GPU 并不是简单地调用这个函数一次,而是同时启动成千上万个线程,每个线程都在独立执行这份相同的代码逻辑。每个线程通过读取自己独一无二的 ID(threadIdx),来决定自己该处理数据的哪一部分(比如图像的哪个像素,或矩阵的哪一行)。
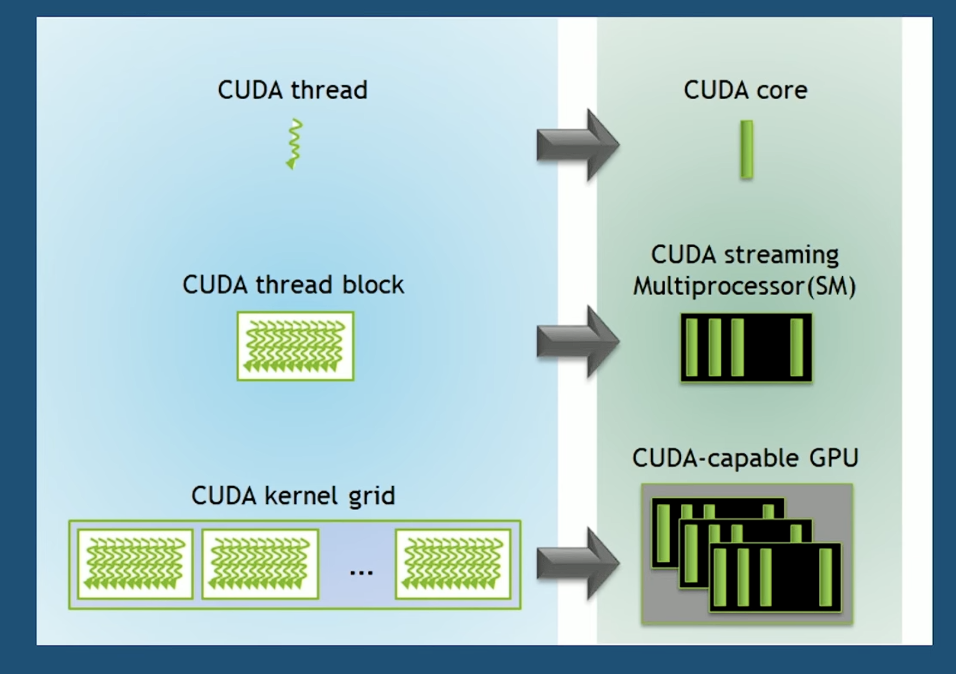
1. 线程模型:从 Thread 到 Grid
理解了 Kernel,我们再看它是如何被调度执行的。CUDA 编程模型将计算任务分解为三个层级:

- 线程 (Thread):GPU 工作的最小单位。它类似于 CPU 的线程,但极其轻量。每个线程都有自己的 ID,负责处理数据的一小部分(例如图像中的一个像素,或矩阵中的一个元素)。
- 块 (Block):一组线程的集合。一个 Block 内的线程运行在同一个流式多处理器 (SM) 上。关键点在于:同一个 Block 内的线程可以通过极快的“共享内存”进行协作和同步(__syncthreads())。
- 网格 (Grid):所有执行同一个内核函数(Kernel)的 Block 的集合。Grid 涵盖了整个计算任务。
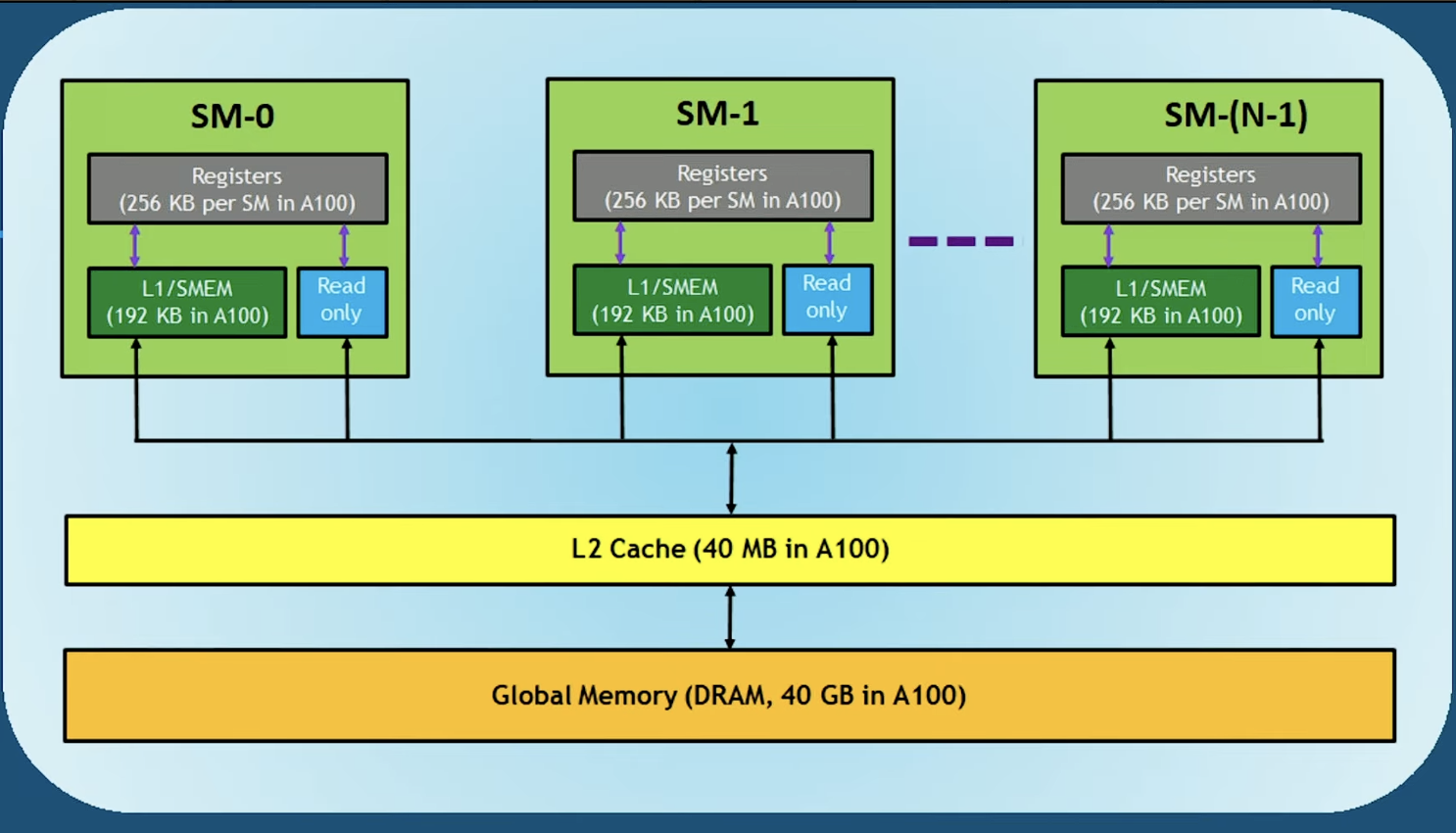
2. 内存模型:速度与容量的权衡
GPU 的内存架构比 CPU 更为复杂,理解它对于性能优化至关重要:
- 寄存器 (Registers):最快。每个线程私有,用于存储局部变量。数量有限,用多了会溢出到慢速内存。
- 共享内存 (Shared Memory):极快(L1 缓存级别)。属于 Block 私有,是线程间通信的桥梁。优化 CUDA 程序的核心往往在于如何高效利用共享内存来减少全局内存访问。
- 全局内存 (Global Memory):较慢(显存,如 24GB GDDR6X)。所有线程可见,容量大但延迟高。
- 常量内存 (Constant Memory):快(有缓存)。用于存储只读参数,适合广播给所有线程。
编写高效 CUDA 代码的秘诀,就是尽可能让数据停留在寄存器和共享内存中,减少对全局内存的访问。
Go + CUDA 实战——跨越鸿沟
理解了原理,现在让我们动手。我们将构建一个完整的 Go 项目,利用 GPU 并行计算两个矩阵的乘积。这个过程需要借助 CGO 作为桥梁。
1. 项目目录结构
go-cuda-cgo-demo/
├── main.go # Go 主程序 (CGO 入口,负责内存分配和调度)
├── matrix.cu # CUDA 内核代码 (在 GPU 上运行的 C++ 代码)
└── matrix.h # C 头文件 (声明导出函数,供 CGO 识别)
2. 编写 CUDA 内核 (matrix.cu)
这是在 GPU 上运行的核心代码。我们定义一个 matrixMulKernel,每个线程利用自己的坐标 (x, y) 计算结果矩阵中的一个元素。
// matrix.cu
#include <cuda_runtime.h>
#include <stdio.h>
// CUDA Kernel: 每个线程计算 C[row][col] 的值
__global__ void matrixMulKernel(float *a, float *b, float *c, int width) {
// 根据 Block ID 和 Thread ID 计算当前线程的全局坐标
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < width && col < width) {
float sum = 0;
// 计算点积
for (int k = 0; k < width; k++) {
sum += a[row * width + k] * b[k * width + col];
}
c[row * width + col] = sum;
}
}
extern "C" {
// 供 Go 调用的 C 包装函数
// 负责显存分配、数据拷贝和内核启动
void runMatrixMul(float *h_a, float *h_b, float *h_c, int width) {
int size = width * width * sizeof(float);
float *d_a, *d_b, *d_c;
// 1. 分配 GPU 显存 (Device Memory)
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// 2. 将数据从 Host (CPU内存) 复制到 Device (GPU显存)
// 这一步通常是性能瓶颈,应尽量减少
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 3. 定义 Grid 和 Block 维度
// 每个 Block 包含 16x16 = 256 个线程
dim3 threadsPerBlock(16, 16);
// Grid 包含足够多的 Block 以覆盖整个矩阵
dim3 numBlocks((width + threadsPerBlock.x - 1) / threadsPerBlock.x,
(width + threadsPerBlock.y - 1) / threadsPerBlock.y);
// 4. 启动内核!成千上万个线程开始并行计算
matrixMulKernel<<<numBlocks, threadsPerBlock>>>(d_a, d_b, d_c, width);
// 5. 将计算结果从 Device 传回 Host
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
// 6. 释放 GPU 内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
}
3. 定义 C 头文件 (matrix.h)
// matrix.h
#ifndef MATRIX_H
#define MATRIX_H
void runMatrixMul(float *a, float *b, float *c, int width);
#endif
4. 编写 Go 主程序 (main.go)
在 Go 代码中,我们准备数据,并通过 CGO 调用 runMatrixMul。
// go-cuda-cgo-demo/main.go
package main
/*
#cgo LDFLAGS: -L. -lmatrix -L/usr/local/cuda/lib64 -lcudart
#include "matrix.h"
*/
import "C"
import (
"fmt"
"math/rand"
"time"
"unsafe"
)
const width = 1024 // 矩阵大小 1024x1024,共 100万次计算
func main() {
size := width * width
h_a := make([]float32, size)
h_b := make([]float32, size)
h_c := make([]float32, size)
// 初始化矩阵数据
rand.Seed(time.Now().UnixNano())
for i := 0; i < size; i++ {
h_a[i] = rand.Float32()
h_b[i] = rand.Float32()
}
fmt.Printf("Starting Matrix Multiplication (%dx%d) on GPU...\n", width, width)
start := time.Now()
// 调用 CUDA 函数
// 使用 unsafe.Pointer 获取切片的底层数组指针,传递给 C
C.runMatrixMul(
(*C.float)(unsafe.Pointer(&h_a[0])),
(*C.float)(unsafe.Pointer(&h_b[0])),
(*C.float)(unsafe.Pointer(&h_c[0])),
C.int(width),
)
// 注意:在更复杂的场景中,需要使用 runtime.KeepAlive(h_a)
// 来确保 Go GC 不会在 CGO 调用期间回收切片内存。
elapsed := time.Since(start)
fmt.Printf("Done. Time elapsed: %v\n", elapsed)
// 简单验证:检查左上角元素
fmt.Printf("Result[0][0] = %f\n", h_c[0])
}
5. 编译与运行
前提:确保你的机器安装了 NVIDIA Driver 和 CUDA Toolkit。nvcc是CUDA编译器工具链,可以将基于CUDA的代码翻译为GPU机器码。
步骤一:编译 CUDA 代码
nvcc -c matrix.cu -o matrix.o
ar rcs libmatrix.a matrix.o
步骤二:编译 Go 程序
# 链接本地的 libmatrix.a 和系统的 CUDA 运行时库
go build -o gpu-cgo-demo main.go
步骤三:运行
./gpu-cgo-demo
预期输出:
Starting Matrix Multiplication (1024x1024) on GPU...
Done. Time elapsed: 611.815451ms
Result[0][0] = 262.440918
性能优化——从能用到极致
代码跑通只是第一步。Sam 推荐使用 NVIDIA 的 Nsight Systems (nsys) 来进行性能分析。你会发现,虽然 GPU 计算极快,但PCIe 总线的数据传输往往是最大的瓶颈。
优化黄金法则:
- 减少传输:PCIe 很慢。尽量一次性将所有数据传给 GPU,让其进行多次计算,最后再取回结果。
- 利用共享内存 (Shared Memory):Block 内的共享内存比全局显存快得多。在矩阵乘法中,可以利用它实现分块算法 (Tiling),将小块矩阵加载到共享内存中复用,从而大幅减少显存带宽压力。
小结:Gopher 的新武器
Go + CUDA 的组合,为 Go 语言打开了一扇通往高性能计算的大门。它证明了 Go 不仅是编写微服务的利器,同样可以成为驾驭底层硬件、构建计算密集型应用的强大工具。如果你正在处理大规模数据,不妨尝试将计算任务卸载给 GPU,你会发现,那个熟悉的蓝色 Gopher,也能拥有令人惊叹的爆发力。
资料链接:
- https://www.youtube.com/watch?v=d1R8BS-ccNk
- https://sam-burns.com/posts/gophercon-25-go-faster/#gophercon-2025-new-york
本文涉及的示例源码可以在这里下载。
附录:告别 CGO?尝试 PureGo 的无缝集成
虽然 CGO 是连接 Go 和 C/C++ 的标准桥梁,但它也带来了编译速度变慢、工具链依赖等问题。有没有一种更“纯粹”的 Go 方式?
答案是有的。借助 PureGo 库,我们可以在不开启 CGO 的情况下,直接加载动态链接库 (.so / .dll) 并调用其中的符号。
让我们看看如何用 PureGo 重写上面的 main.go。
1. 准备动态库
首先,我们需要将 CUDA 代码编译为共享对象 (.so),而不是静态库。
# 编译为共享库 libmatrix.so
nvcc -shared -Xcompiler -fPIC matrix.cu -o libmatrix.so
2. 编写 PureGo 版主程序 (go-cuda-purego-demo/main.go)
// go-cuda-purego-demo/main.go
package main
import (
"fmt"
"math/rand"
"runtime"
"time"
"github.com/ebitengine/purego"
)
const width = 1024
func main() {
// 1. 加载动态库
// 注意:在运行时,libmatrix.so 和 libcuder.so 必须在 LD_LIBRARY_PATH 中
libMatrix, err := purego.Dlopen("libmatrix.so", purego.RTLD_NOW|purego.RTLD_GLOBAL)
if err != nil {
panic(err)
}
// 还需要加载 CUDA 运行时库,因为 libmatrix 依赖它
_, err = purego.Dlopen("/usr/local/cuda/lib64/libcudart.so", purego.RTLD_NOW|purego.RTLD_GLOBAL)
if err != nil {
panic(err)
}
// 2. 注册 C 函数符号
var runMatrixMul func(a, b, c *float32, w int)
purego.RegisterLibFunc(&runMatrixMul, libMatrix, "runMatrixMul")
// 3. 准备数据 (与 CGO 版本相同)
size := width * width
h_a := make([]float32, size)
h_b := make([]float32, size)
h_c := make([]float32, size)
rand.Seed(time.Now().UnixNano())
for i := 0; i < size; i++ {
h_a[i] = rand.Float32()
h_b[i] = rand.Float32()
}
fmt.Println("Starting Matrix Multiplication via PureGo...")
start := time.Now()
// 4. 直接调用!无需 CGO 类型转换
runMatrixMul(&h_a[0], &h_b[0], &h_c[0], width)
// 5. 极其重要:保持内存存活
// PureGo 调用是纯汇编实现,Go GC 无法感知堆栈上的指针引用
// 必须显式保活,否则在计算期间 h_a 等可能被 GC 回收!
runtime.KeepAlive(h_a)
runtime.KeepAlive(h_b)
runtime.KeepAlive(h_c)
fmt.Printf("Done. Time: %v\n", time.Since(start))
fmt.Printf("Result[0][0] = %f\n", h_c[0])
}
3. 运行
# 无需 CGO,直接在go-cuda-purego-demo下运行
# 确保当前目录在 LD_LIBRARY_PATH 中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
CGO_ENABLED=0 go run main.go
Starting Matrix Multiplication via PureGo...
Done. Time: 584.397195ms
Result[0][0] = 260.088806
优势:
- 编译飞快:没有 CGO 的编译开销。
- 零外部依赖:编译环境不需要安装 GCC 或 CUDA Toolkit,只要运行时环境有 .so 即可。这对于在轻量级 CI/CD 环境中构建分发包非常有用。
注意:PureGo 方案虽然优雅,但也失去了 CGO 的部分类型安全检查,且需要开发者更小心地管理内存生命周期 (runtime.KeepAlive)。
你的“算力”狂想
Go + GPU 的组合,打破了我们对 Go 应用场景的想象边界。在你的业务场景中,有没有哪些计算密集型的任务(比如图像处理、复杂推荐算法、密码学计算)是目前 CPU 跑不动的?你是否会考虑用这种“混合动力”方案来重构它?
欢迎在评论区分享你的脑洞或实战计划! 让我们一起探索 Go 的算力极限。
如果这篇文章为你打开了高性能计算的大门,别忘了点个【赞】和【在看】,并转发给那个天天喊着“CPU 跑满了”的同事!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
- 告别低效,重塑开发范式
- 驾驭AI Agent(Claude Code),实现工作流自动化
- 从“AI使用者”进化为规范驱动开发的“工作流指挥家”
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
- 想写出更地道、更健壮的Go代码,却总在细节上踩坑?
- 渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
- 想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
