
本文永久链接 – https://tonybai.com/2025/10/31/deep-into-go-green-tea-gc
大家好,我是Tony Bai。
关注 Go 语言演进的 Gopher 们可能已经注意到,Go 团队更换技术负责人以来,对运行时 (runtime) 和编译器 (compiler) 核心组件的打磨正日益成为团队的工作重心。从备受期待的“绿茶”GC (Green Tea GC),到 标准库simd 加速包的探索,再到 基于swisstable的 map 的实现,以及 json/v2 的设计实现,一系列动作都预示着 Go 正在其性能核心地带进行着深刻的自我革新。
而就在最近,Go 运行时和编译器团队的一项决议,更是将这一趋势推向了高潮:他们计划在 Go 1.26 版本中,将实验性的“绿茶”GC 作为默认的垃圾回收器正式落地。
为了帮助大家深入理解这一重大变更背后的技术原理与深层思考,我翻译了 Go 官方博客10月29日的最新文章《The Green Tea Garbage Collector》。该文是基于 Go 团队核心成员 Michael Knyszek 在 GopherCon 2025 大会上的演讲整理而成。在这篇极具技术深度的原理文章中,没有人能比官方团队的讲解更为专业和权威。因此,为了最大程度地保留其“原汁原味”,我选择以全文翻译的形式,将其最真实、最精确的面貌呈现给大家。
以下是译文全文,供大家参考。

Go 1.25 包含一个名为“绿茶”(Green Tea)的全新实验性垃圾回收器,在构建时通过设置 GOEXPERIMENT=greenteagc 即可启用。使用该垃圾回收器后,许多工作负载在垃圾回收上花费的时间减少了约 10%,而有些工作负载的降幅甚至高达 40%!
它已为生产环境准备就绪,并在 Google 内部投入使用,因此我们鼓励你进行尝试。我们知道某些工作负载的收益不大,甚至完全没有,所以你的反馈对于我们向前推进至关重要。根据我们目前掌握的数据,我们计划在 Go 1.26 中将其设为默认GC。
如需报告任何问题,请提交一个新 issue。
如需分享任何成功经验,请回复至现有的 Green Tea issue。
下文是基于 Michael Knyszek 在 GopherCon 2025 上的演讲整理的博文。一旦演讲视频上线,我们将会更新此博文并附上链接。
追踪垃圾回收过程
在讨论“绿茶”之前,让我们先就垃圾收集问题达成共识。
对象和指针
垃圾回收的目的是自动回收并重用程序不再使用的内存。
为此,Go 垃圾回收器关注的是对象(Object)和指针(Pointer)。
在 Go 运行时的上下文中,对象是Go值(Value),其底层内存分配自堆。当 Go 编译器无法找到其他方式为某个值分配内存时,就会创建堆对象。例如,以下代码片段会分配一个堆对象:一个指针切片的底层存储空间。
var x = make([]*int, 10) // 全局变量
Go 编译器只能在堆上分配切片后备存储,因为它很难(甚至可能不可能)知道 x 将引用该对象多长时间。
指针只是一些数字,用于指示 Go 值在内存中的位置,Go 程序通过它们来引用对象。例如,要获取上一个代码片段中分配的对象的起始指针,我们可以这样写:
&x[0] // 0xc000104000
标记-清除算法
Go 的垃圾回收器遵循一种广义上称为“追踪式垃圾回收”的策略,这意味着垃圾回收器会跟随或追踪程序中的指针,以识别程序仍在使用的对象。
更具体地说,Go 垃圾回收器实现了标记-清除(mark-sweep)算法。这比听起来要简单得多。 可以把对象和指针想象成计算机科学意义上的图:对象是节点,指针是边。
标记-清除算法就在这个图上运行的,顾名思义,它分两个阶段进行。
在第一阶段,即标记阶段,它从一组明确定义的、称为“根(root)”的源边开始遍历对象图。可以将其理解为全局变量和局部变量。然后,它将沿途找到的所有东西标记为已访问(visited),以避免循环。这类似于典型的图遍历算法,如深度优先或广度优先搜索。
接下来是清除阶段。在我们的图遍历中未被访问到的任何对象,都是程序未使用或不可达(unreachable)的。我们称这种状态为不可达,因为通过语言的语义,正常的安全 Go 代码已无法再访问那块内存。为完成清除阶段,算法只需遍历所有未访问的节点,并将其内存标记为空闲,以便内存分配器可以重用它们。
就是这样?
你可能觉得我在这里把事情想得有点过于简单了。垃圾回收器经常被比作魔法和黑盒子 。你的说法也对了一部分,实际情况要复杂得多。
例如,实际上,这个算法会与你的常规 Go 代码并行执行。遍历一个不断变化的图会带来挑战。我们还对这个算法进行了并行化,这一点稍后会再次提及。
但请相信我,这些细节大多与核心算法无关。核心算法实际上只是一个简单的图泛洪(graph flood)操作。
图泛洪示例
我们来看一个例子。请浏览下面的幻灯片图片,跟随步骤操作。
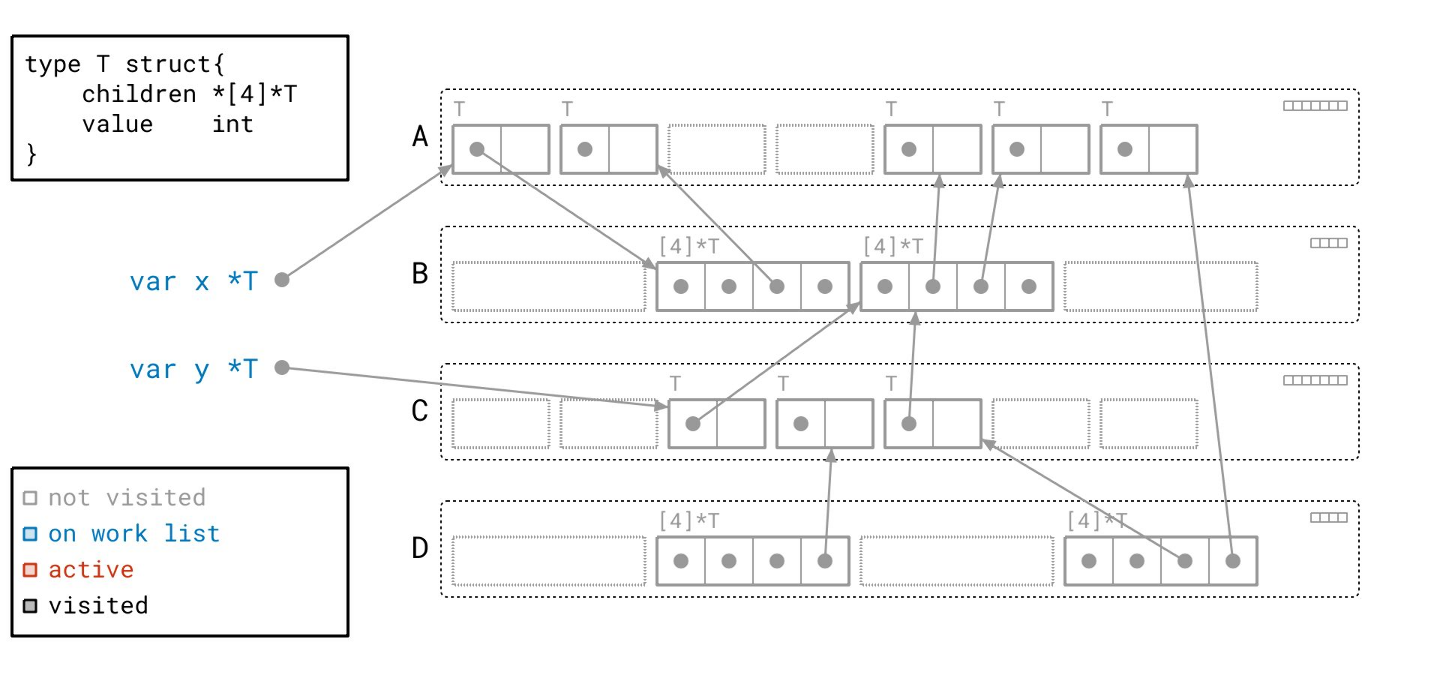
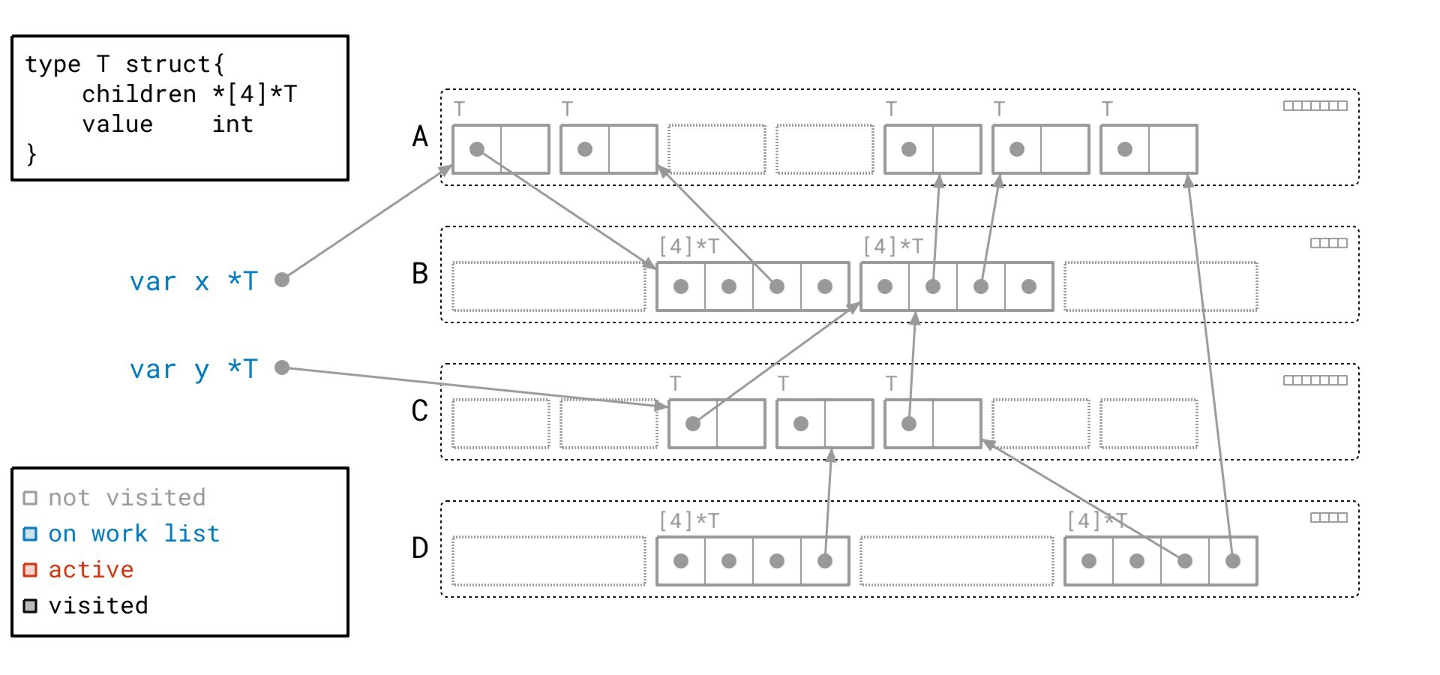
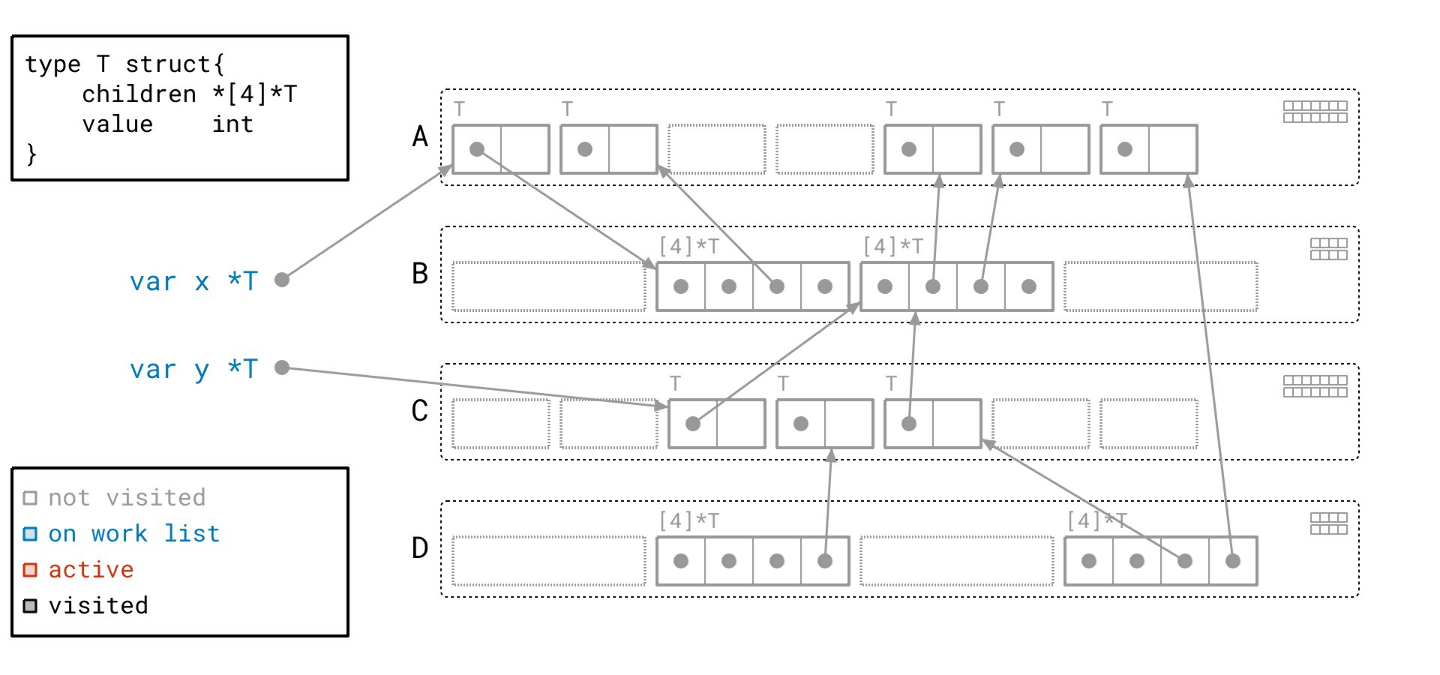
这里我们有一个包含一些全局变量和 Go 堆的图示。让我们一步步来分析。
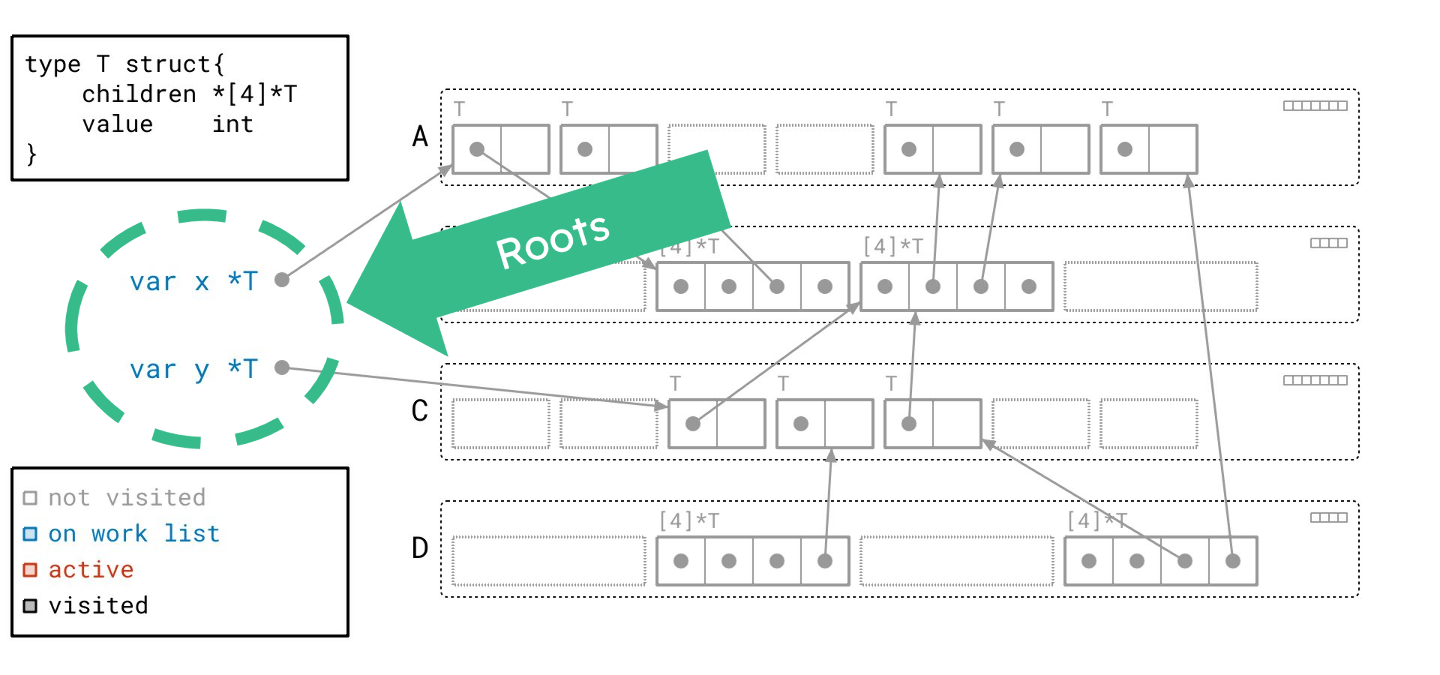
左边是我们的根。它们是全局变量 x 和 y。这将是我们图遍历的起点。根据左下角的图例,它们被标记为蓝色,表示它们当前在我们的工作列表上。
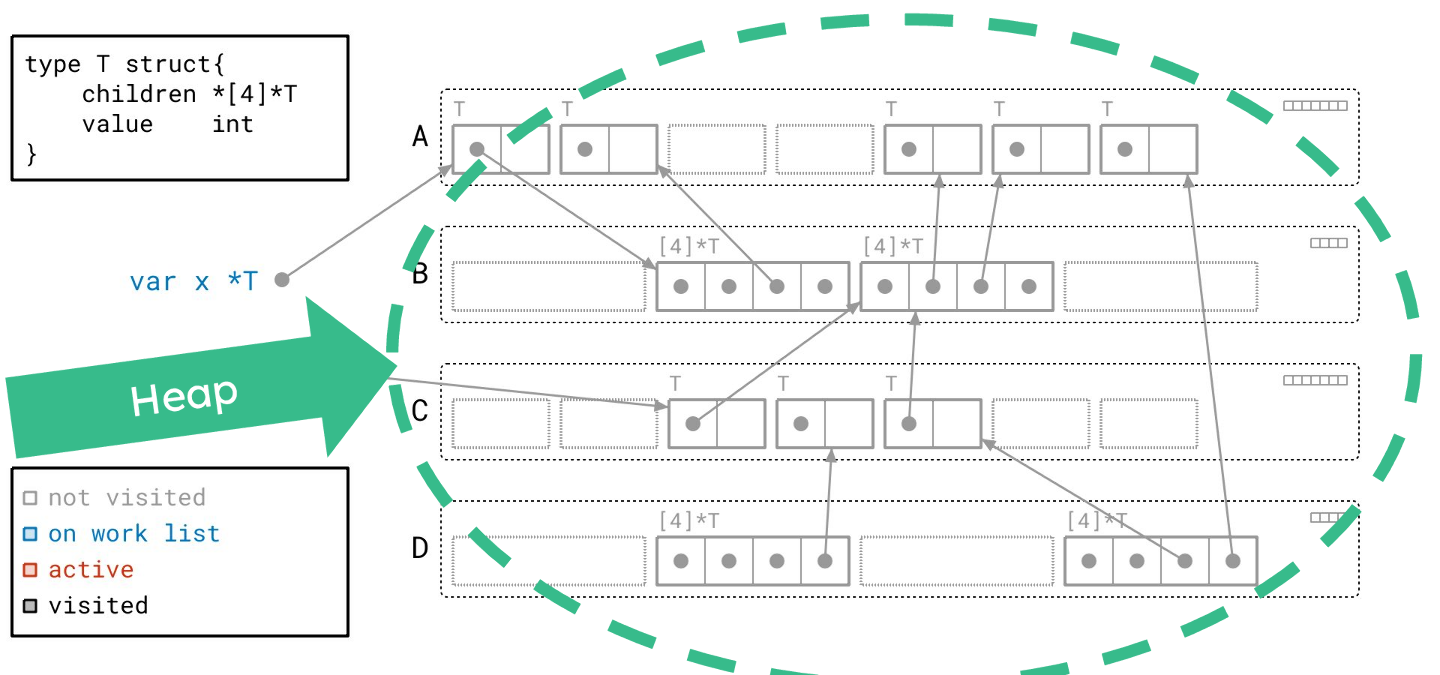
右边是我们的堆。目前,堆中的所有东西都是灰色的,因为我们还没有访问过任何部分。
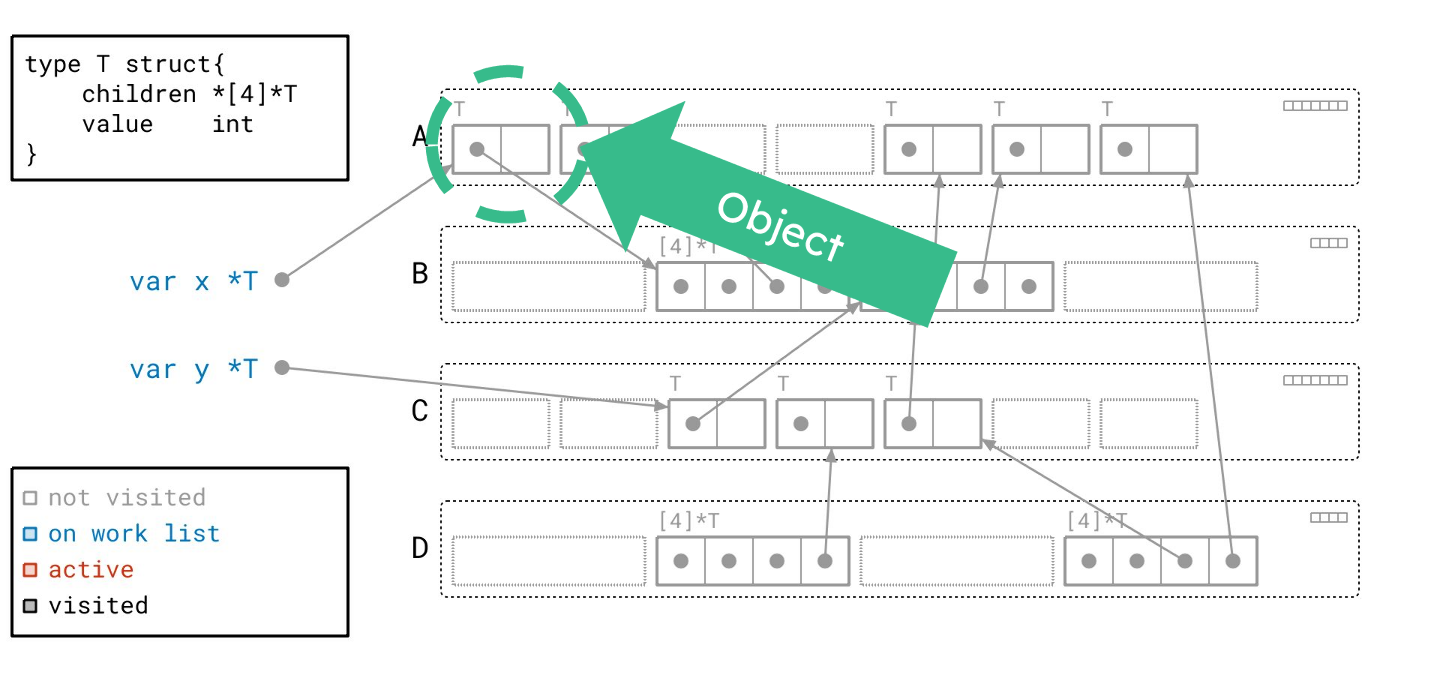
每个矩形中代表一个对象。每个对象都标有其类型。这个特殊的对象是 T 类型的对象,其类型定义在左上角。它有一个指向子节点数组的指针和一些值。我们可以推断这是一种递归的树形数据结构。
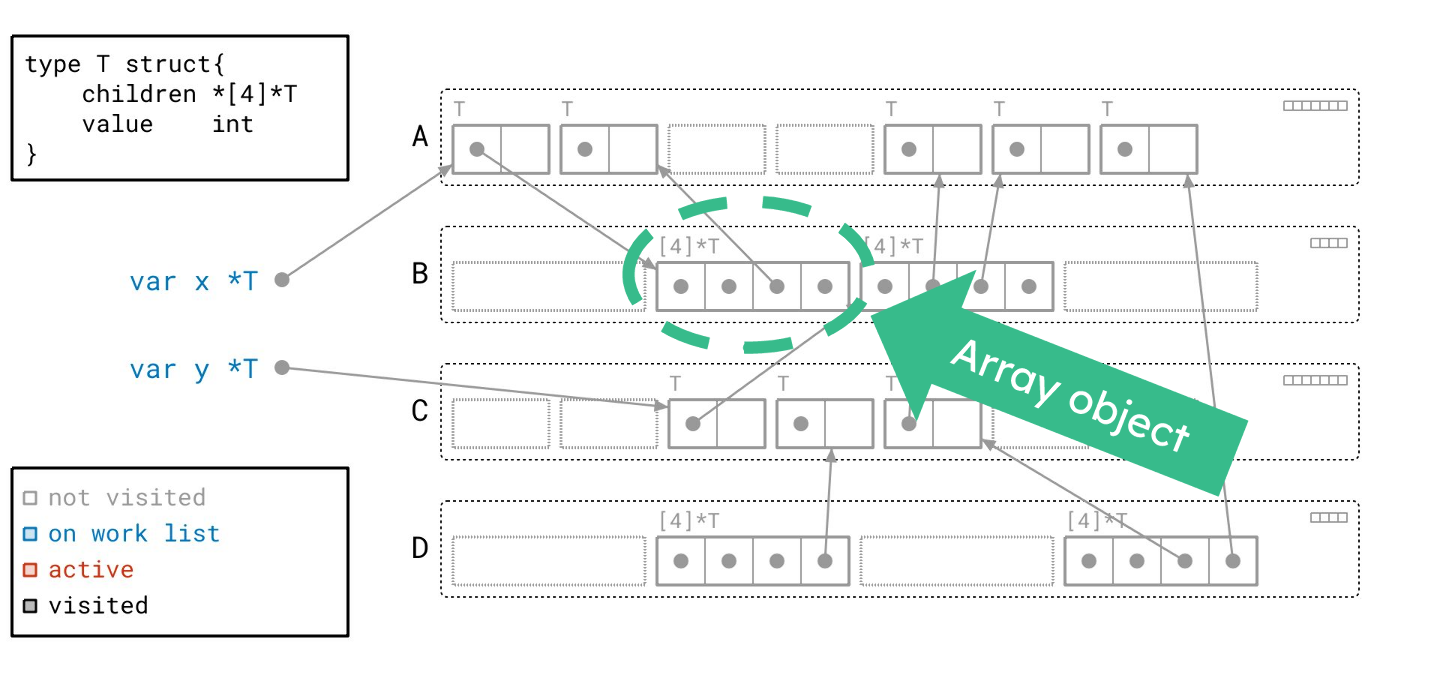
除了 T 类型的对象,你还会注意到我们有包含 *T 的数组对象。这些数组对象由 T 类型对象的 “children” 字段指向。
矩形内的每个方块代表 8 字节的内存。带有点的方块是一个指针。如果它有箭头,那么它是一个指向某个其他对象的非空指针。
如果它没有对应的箭头,那么它就是一个空指针。
接下来,这些虚线矩形代表空闲空间,我称之为空闲“槽位(slot)”。我们可以在那里放置一个对象,但目前还没有。
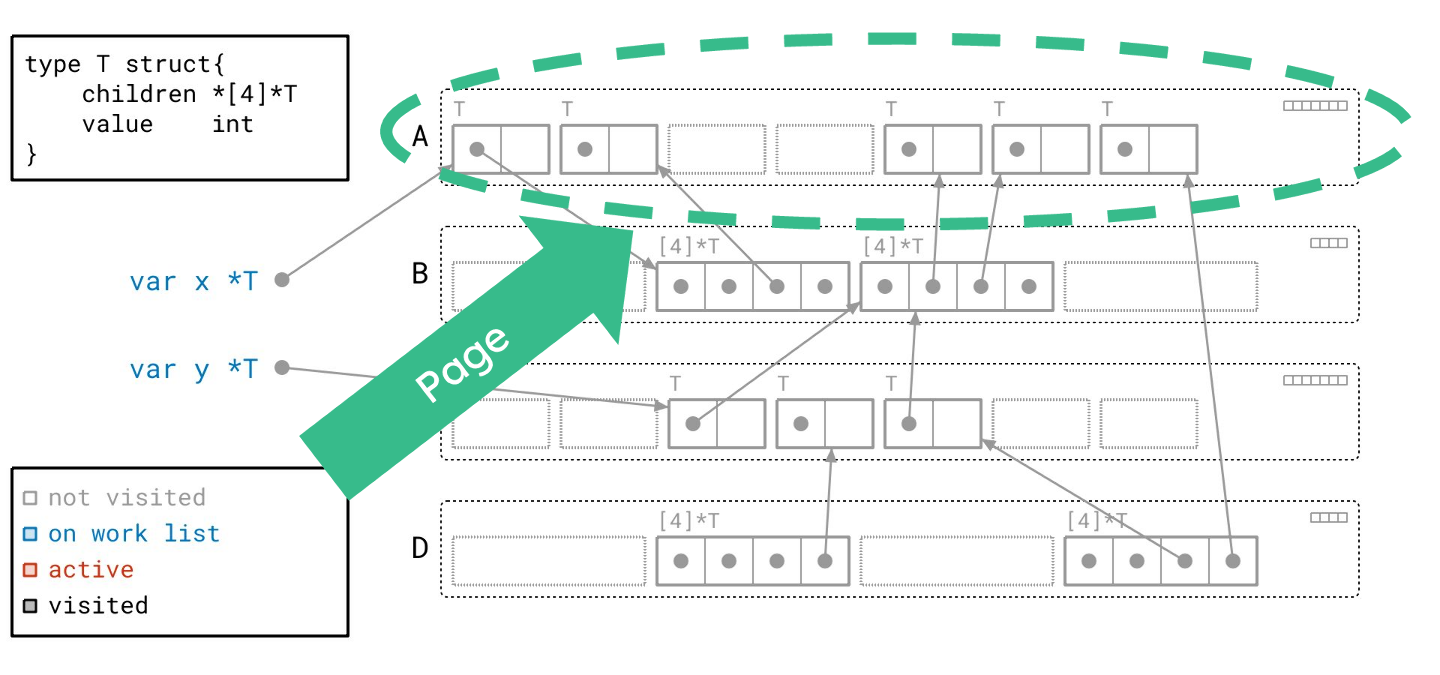
你还会注意到对象被这些带标签的、虚线圆角矩形组合在一起。每一个都代表一个页(page):一块连续的内存块。这些页被标记为 A、B、C 和 D,我将以此来称呼它们。
在这个图中,每个对象都被分配到某个页面中。就像实际实现一样,这里的每个页面只包含特定大小的对象。这正是 Go 堆的组织方式。
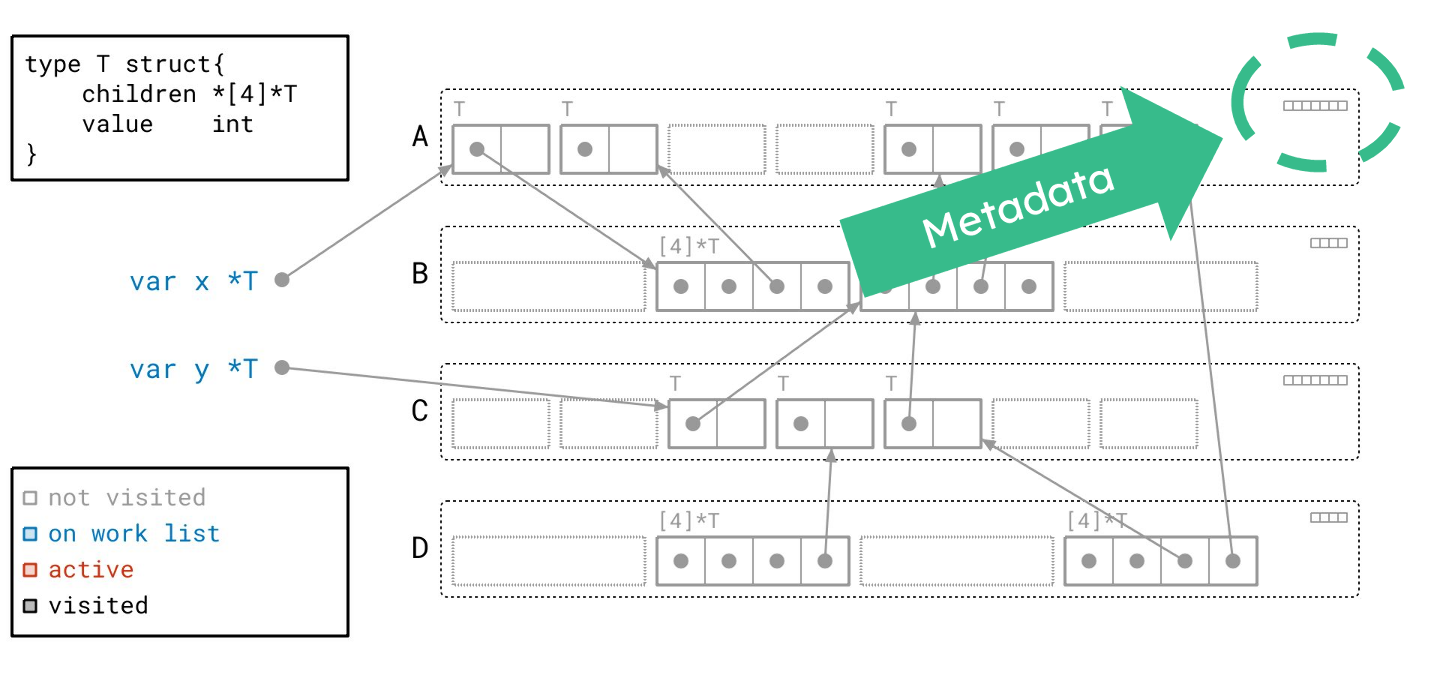
页也是我们组织每个对象元数据的方式。这里你可以看到七个框,每个对应页 A 中的七个对象槽位之一。
每个框代表一位(bit)信息:我们之前是否见过这个对象。实际上,Go运行时就是通过这种方式来管理对象是否已被访问过的,这一点稍后会很重要。
细节讲了很多,感谢你跟读。这些稍后都会派上用场。现在,让我们看看图泛洪如何应用于这幅图。
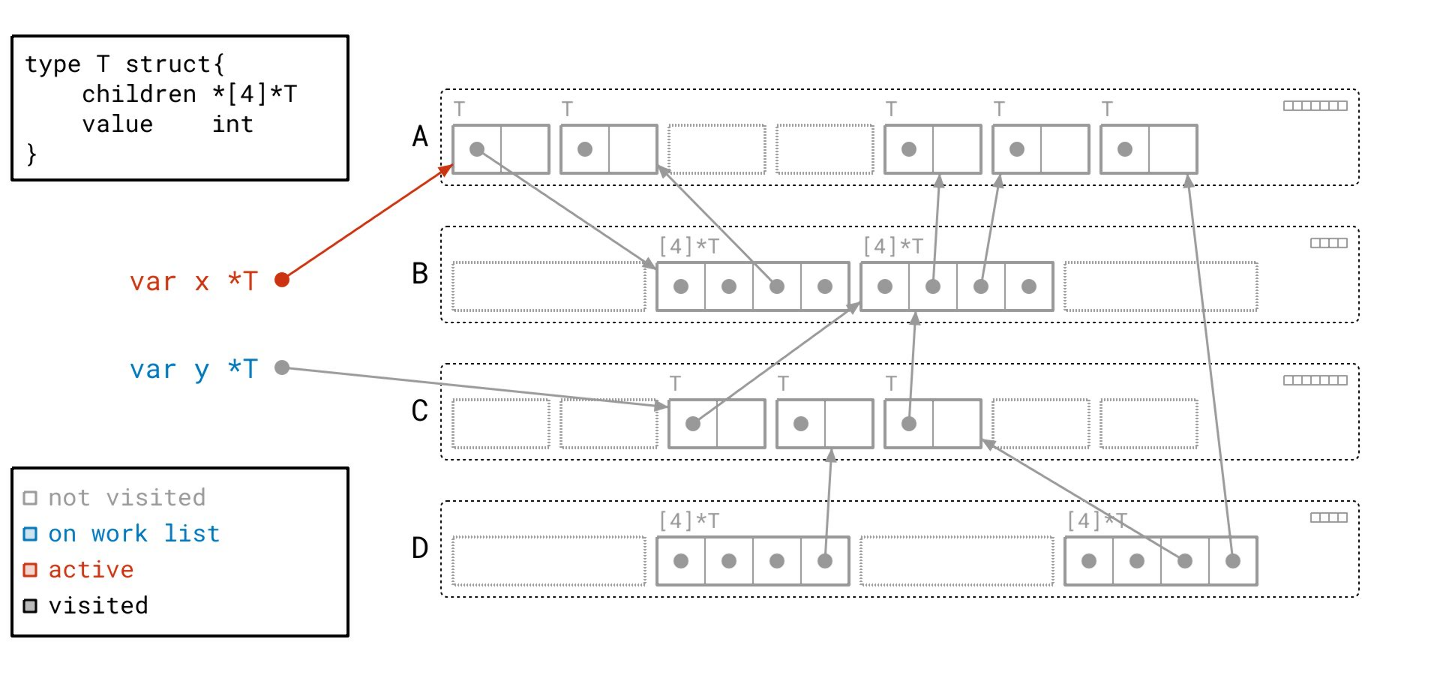
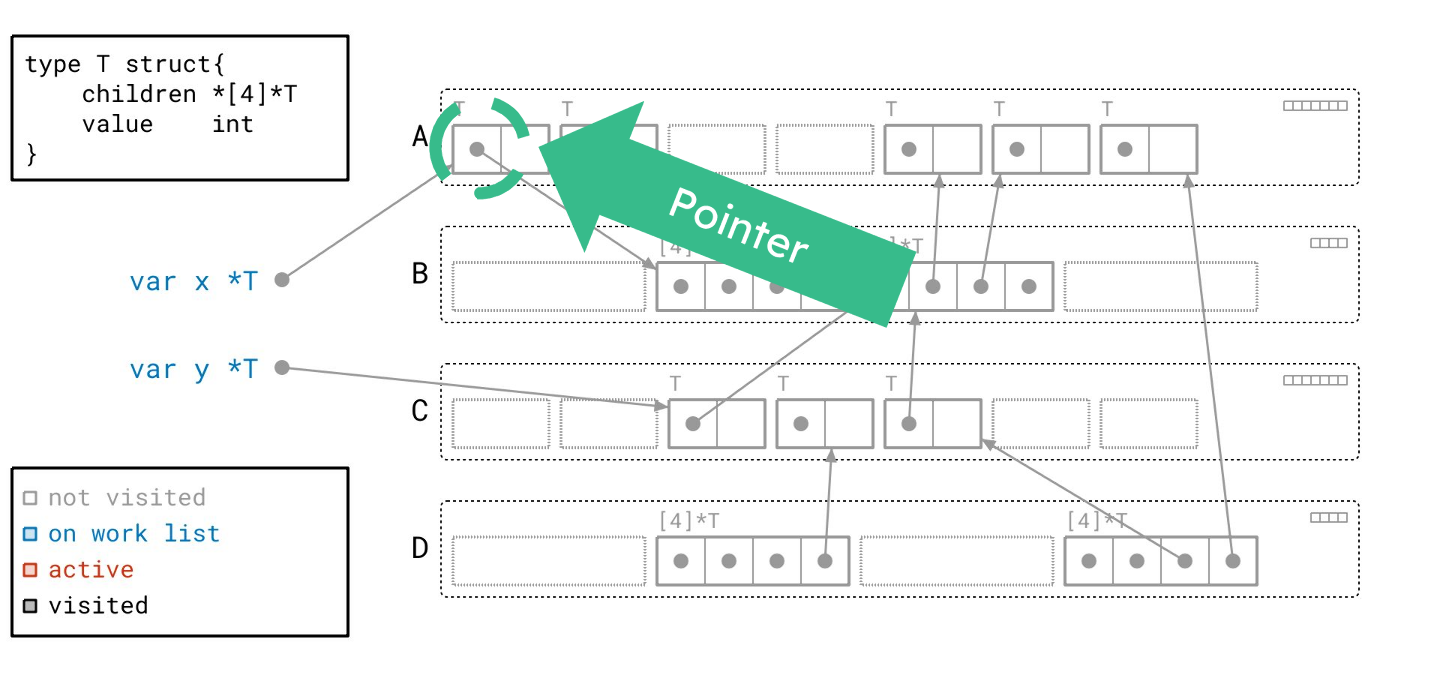
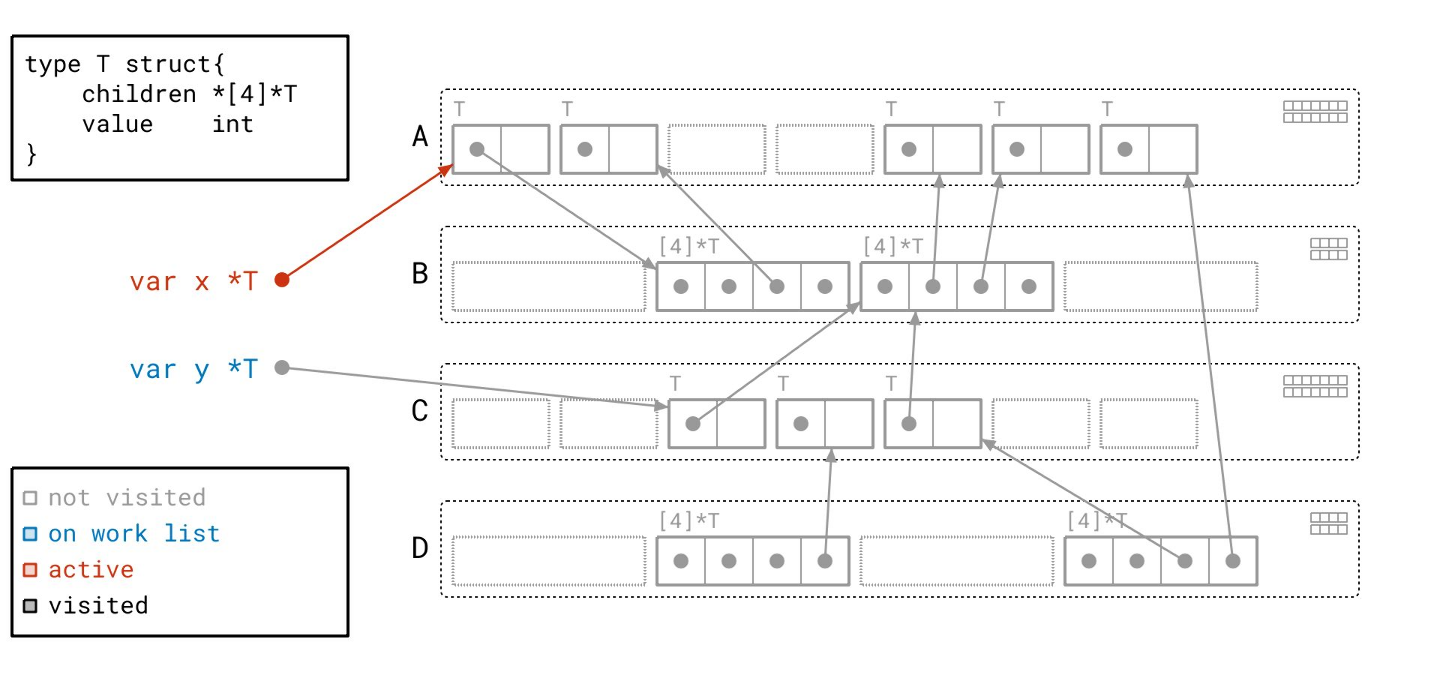
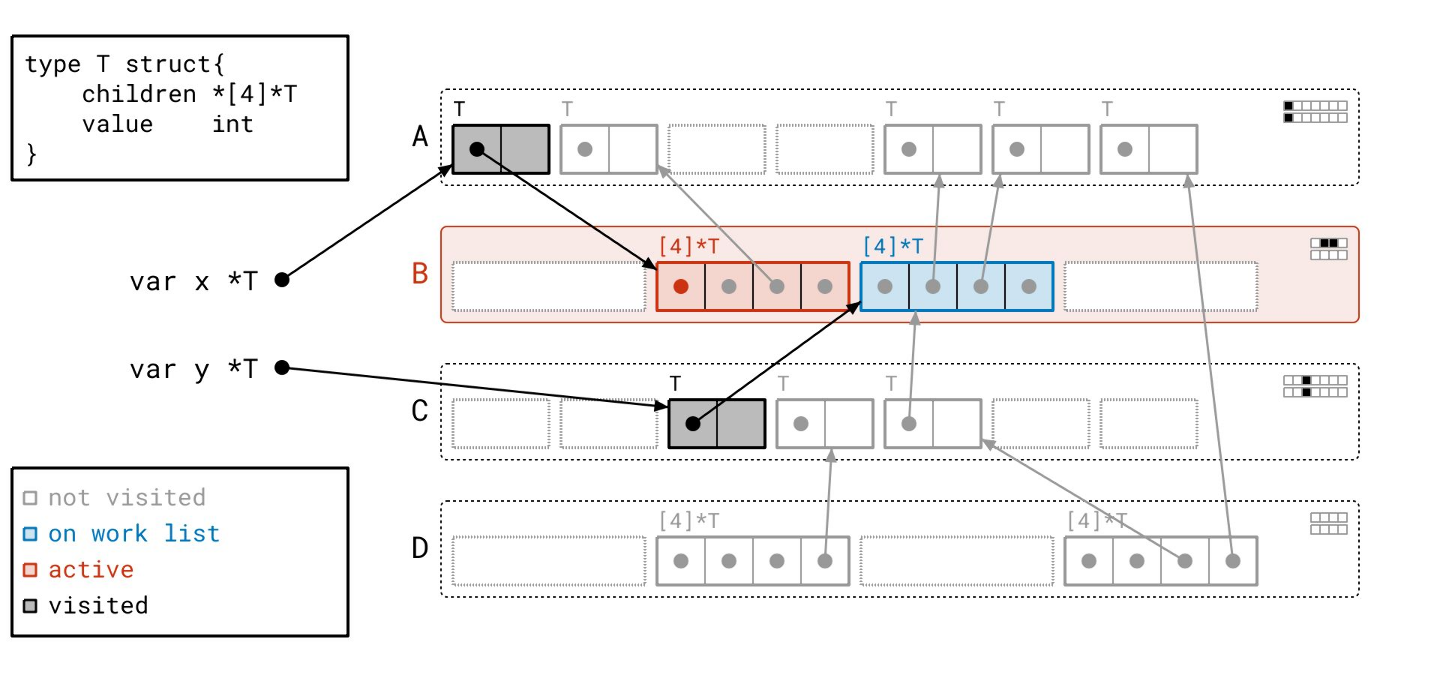
我们首先从工作列表中取出一个根。我们将其标记为红色,表示它现在是活跃的。
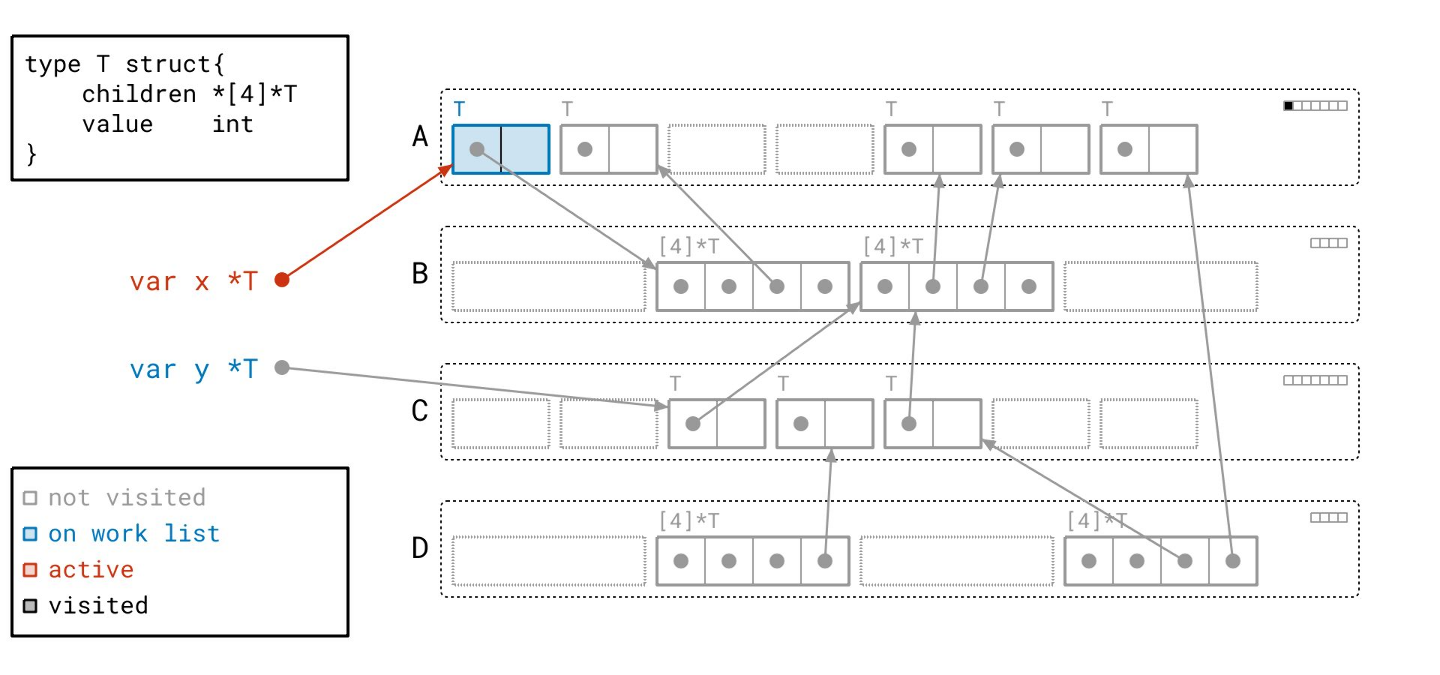
沿着根指针,我们找到了一个 T 类型的对象,并将其添加到我们的工作列表。根据图例,我们将该对象绘制成蓝色,以表明它已在工作列表中。请注意,我们同时在右上角的元数据中设置了与此对象对应的“已见”位。
下一个根也同样处理。
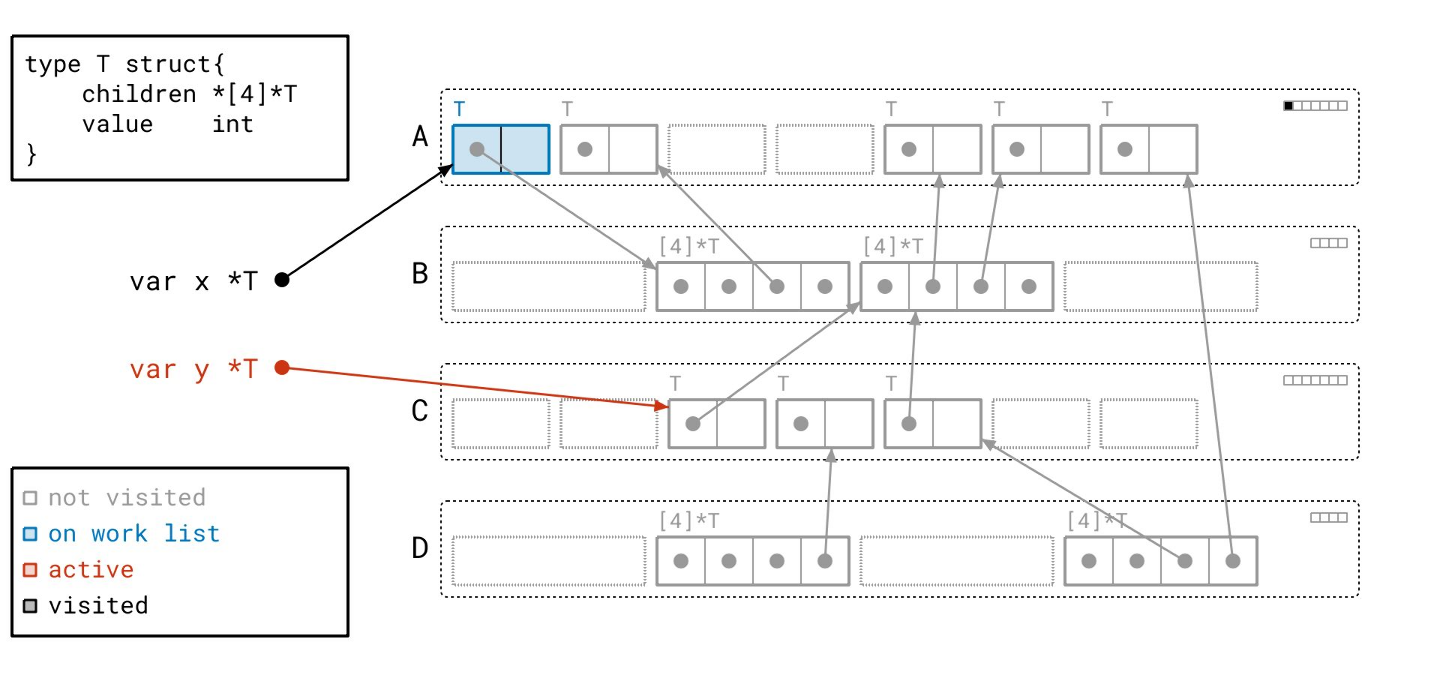
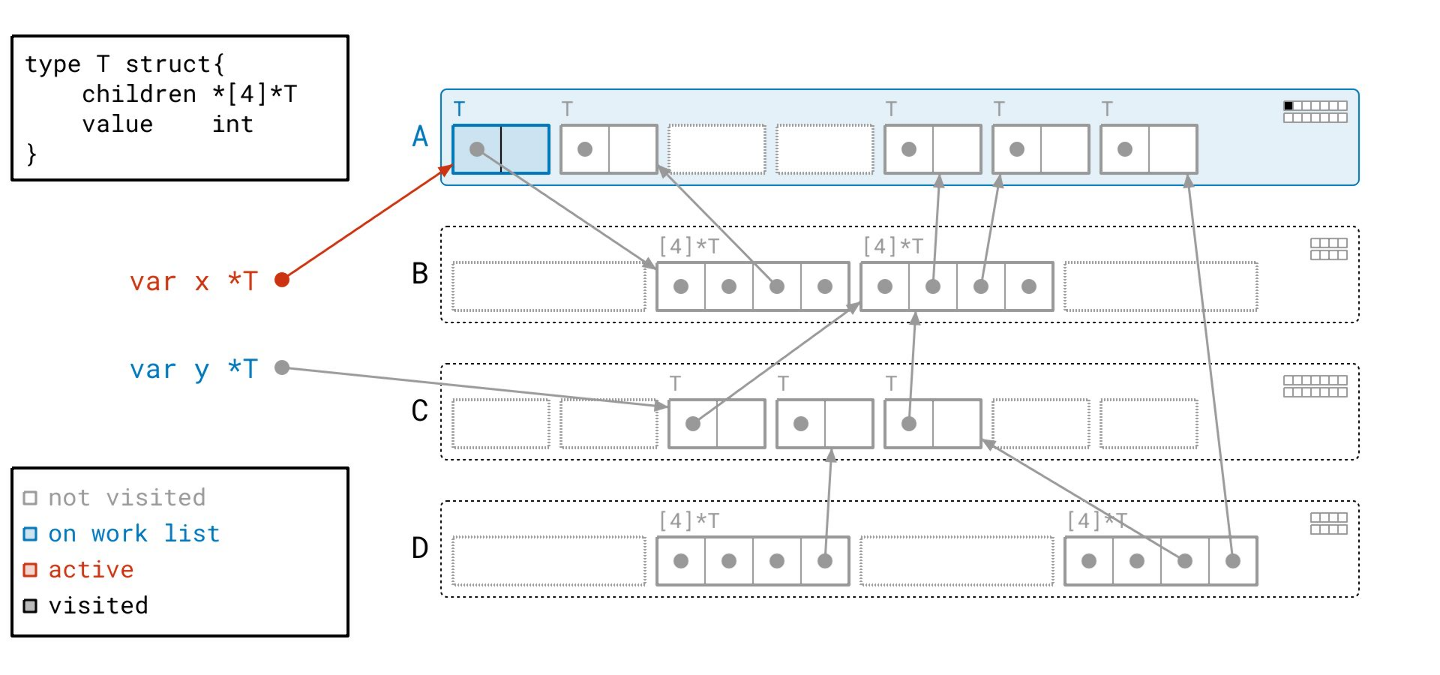
现在我们处理完了所有的根,工作列表上还剩下两个对象。让我们从工作列表中取出一个对象。
我们现在要做的是遍历该对象的指针,以找到更多的对象。顺便说一下,我们称遍历一个对象的指针为“扫描”该对象。
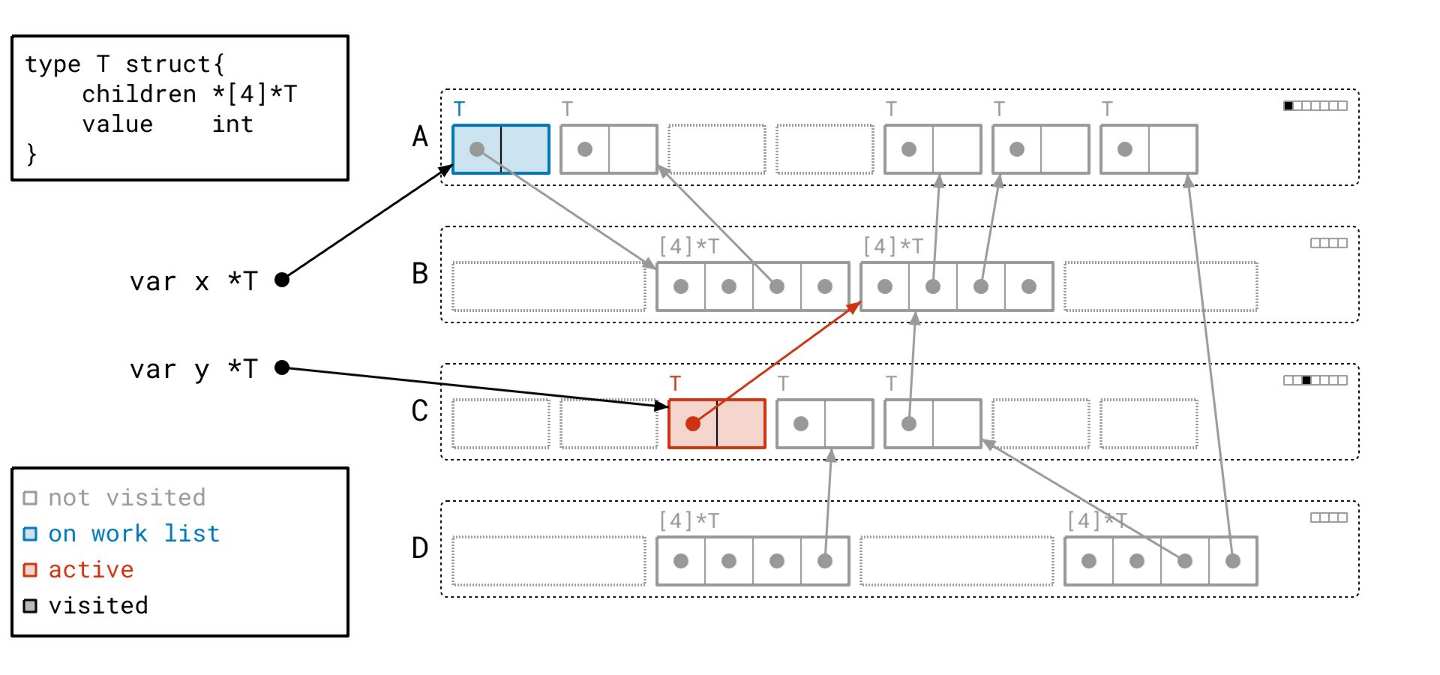
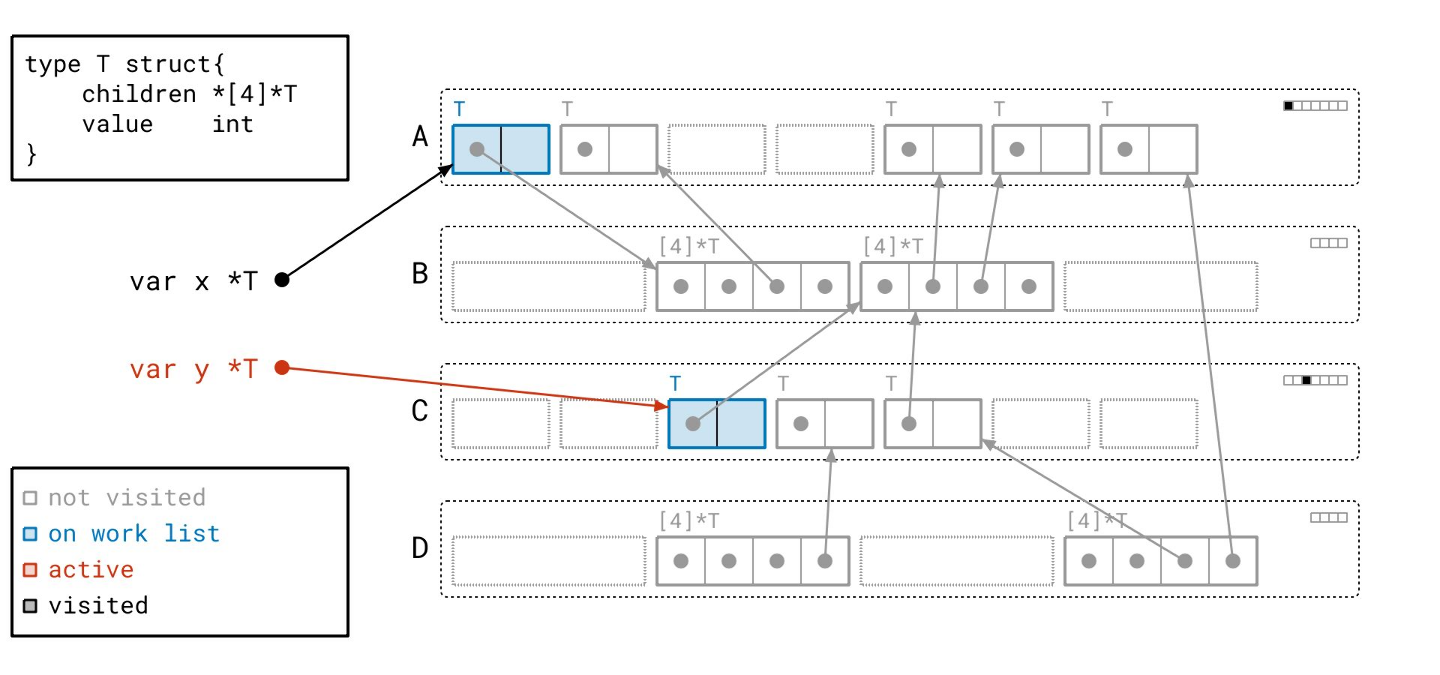
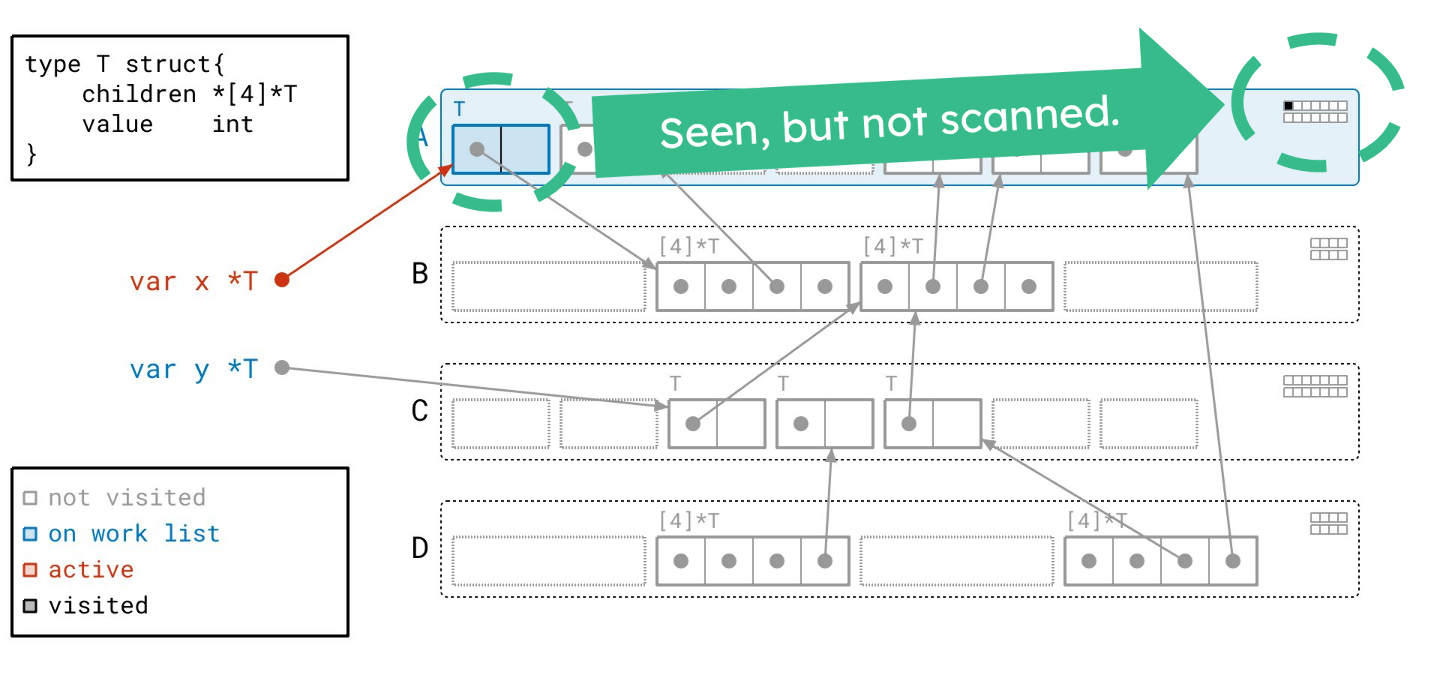
我们找到了这个有效的数组对象…
… 并将其添加到我们的工作列表中。
从这里开始,我们递归地进行。
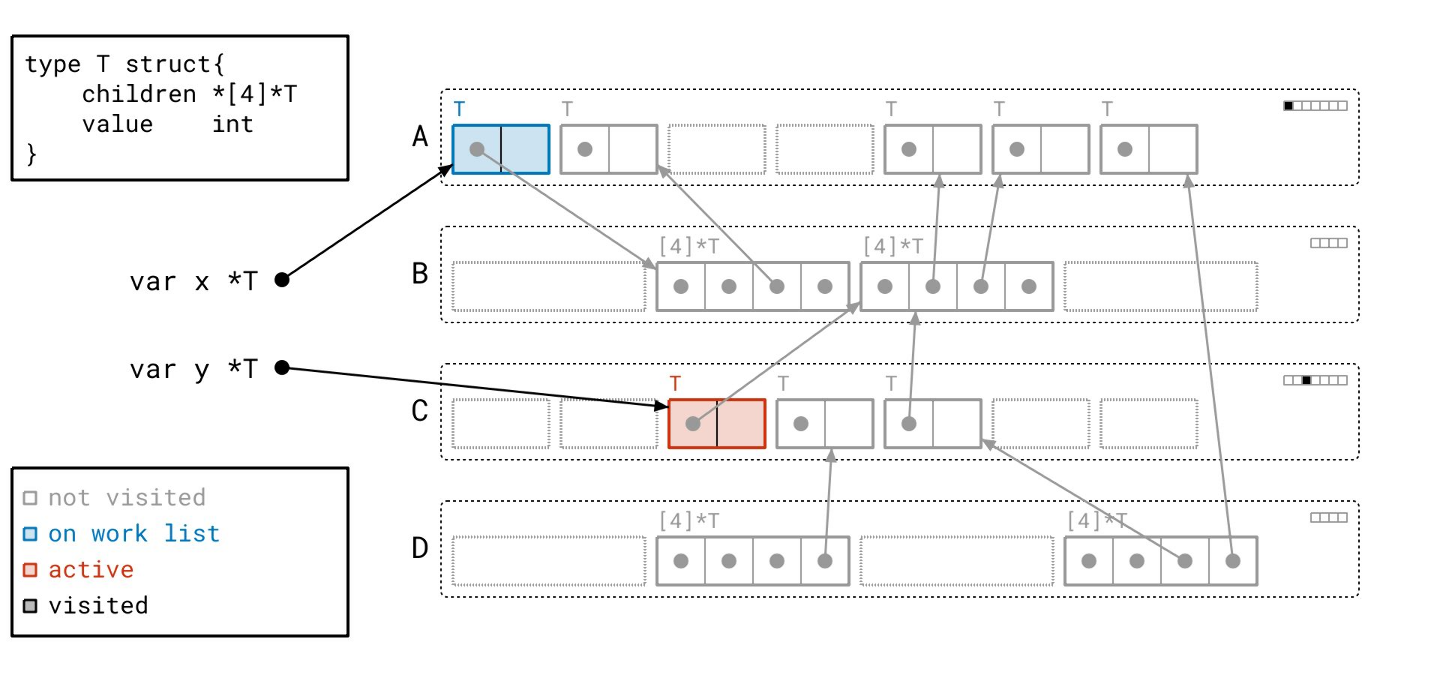
我们遍历数组的指针。
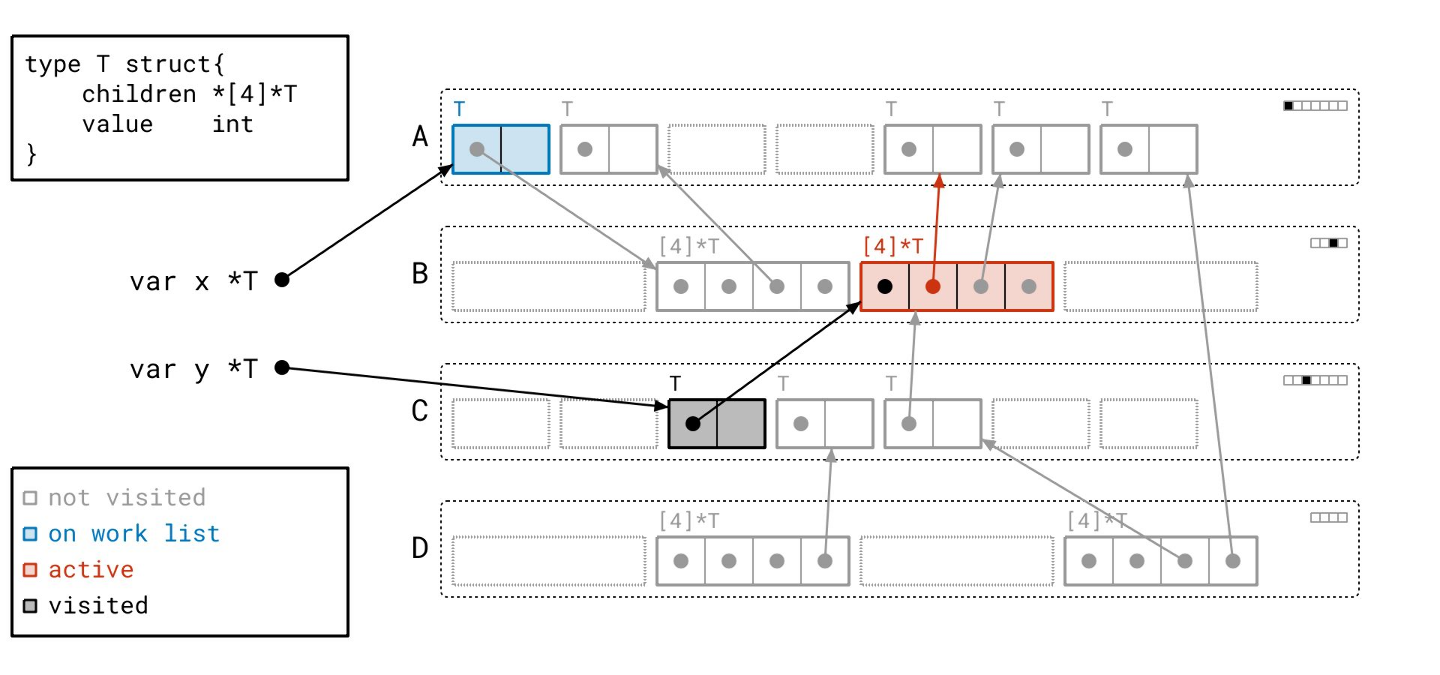
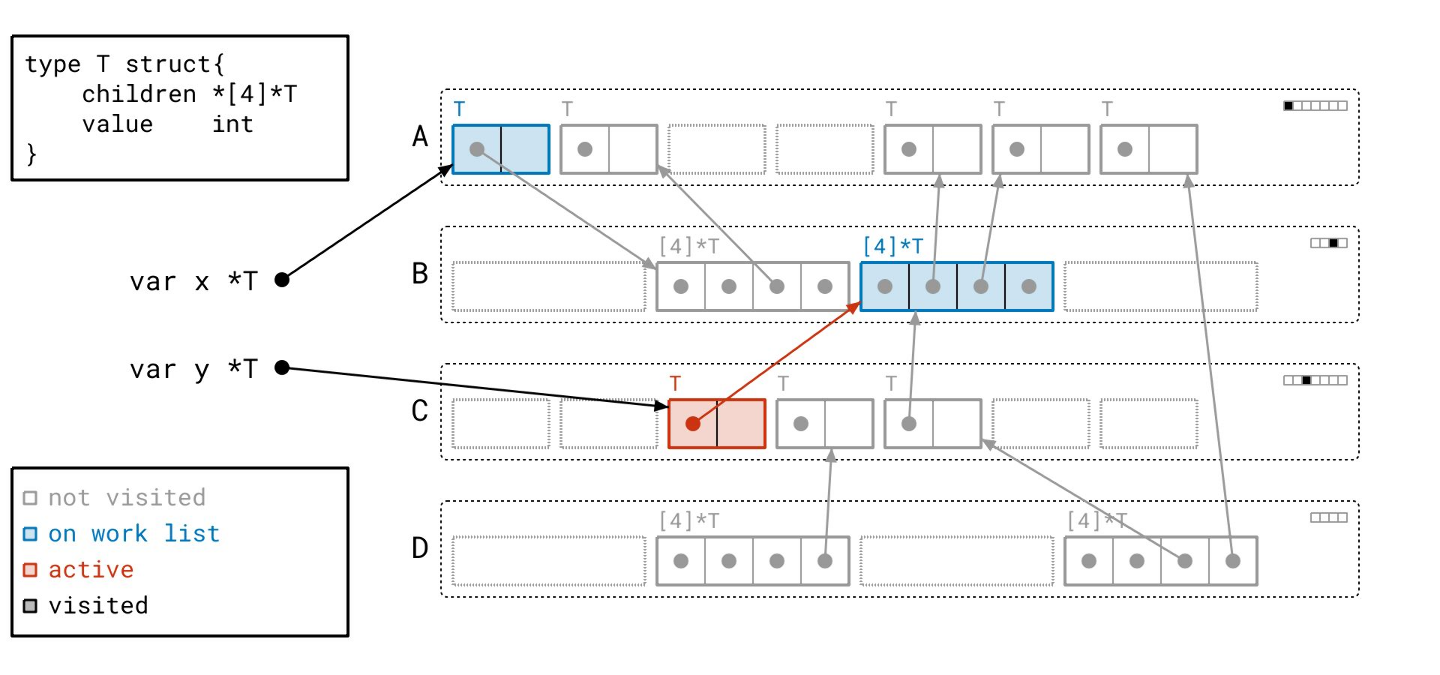
找到更多对象…
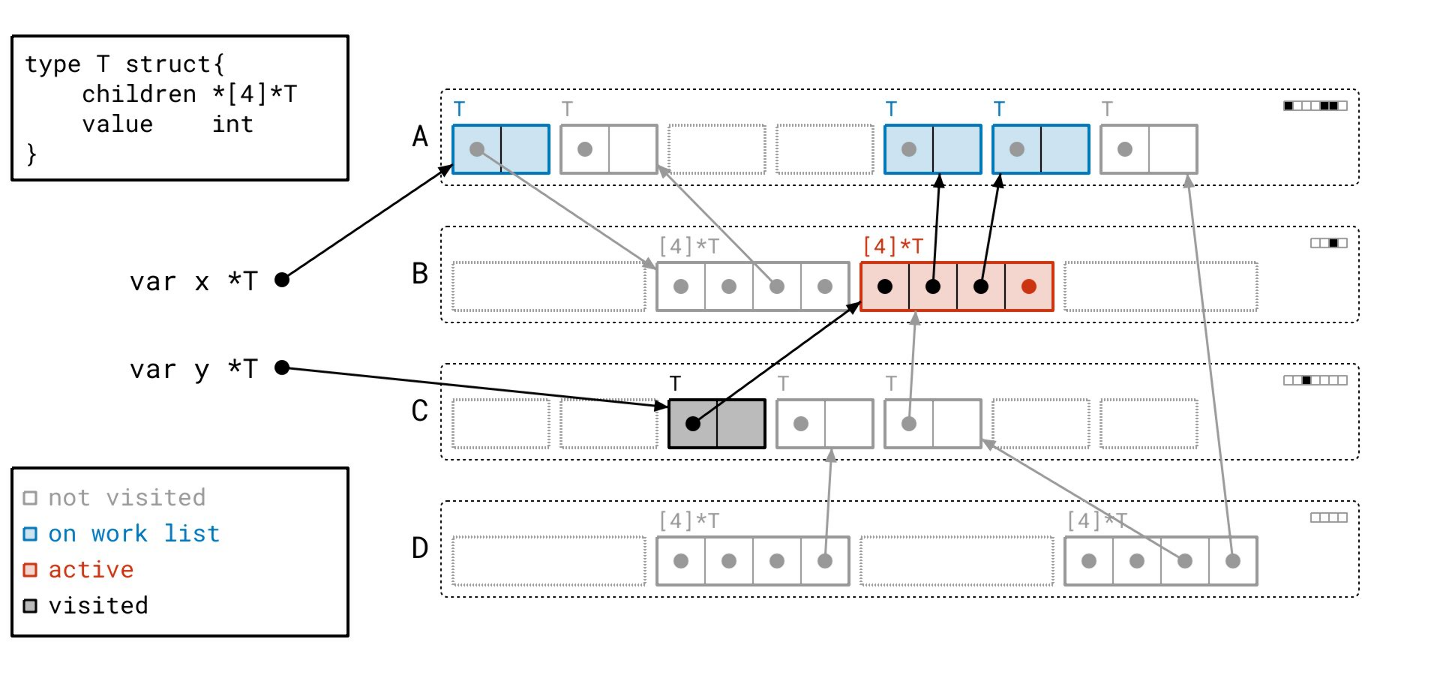
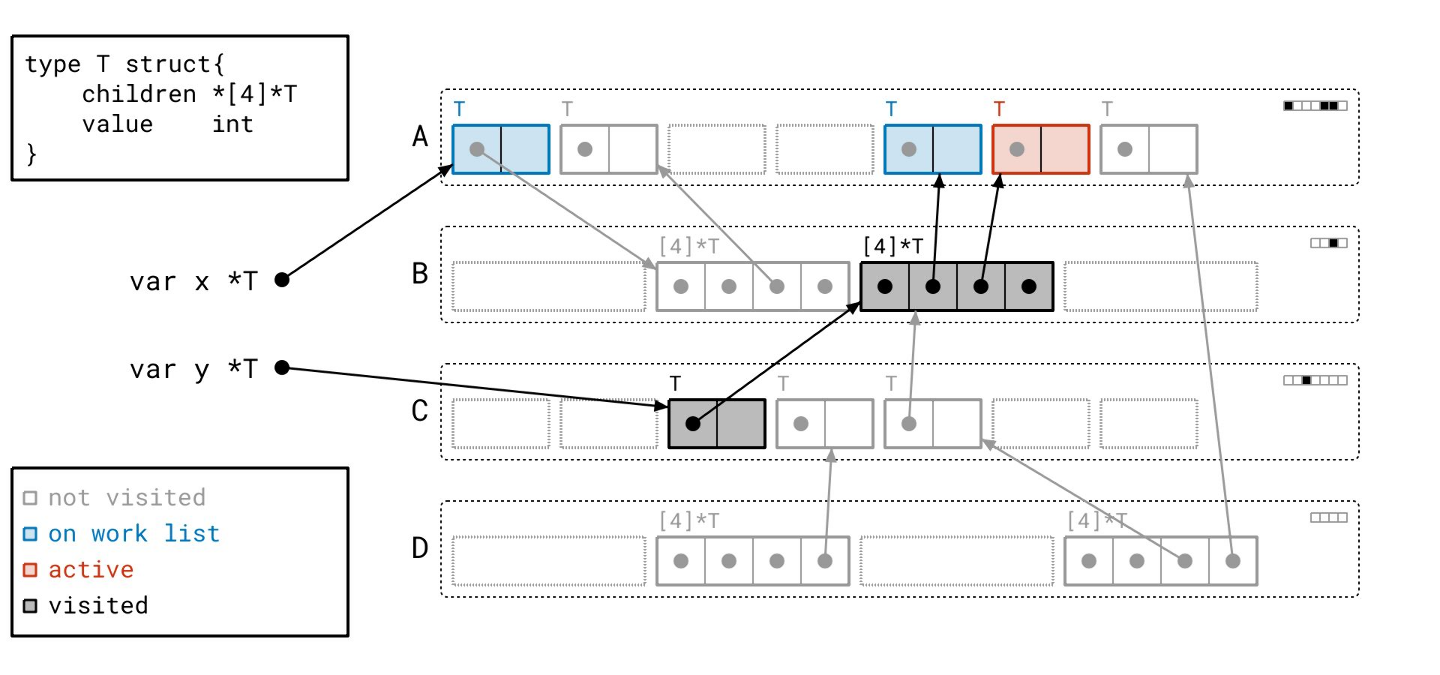
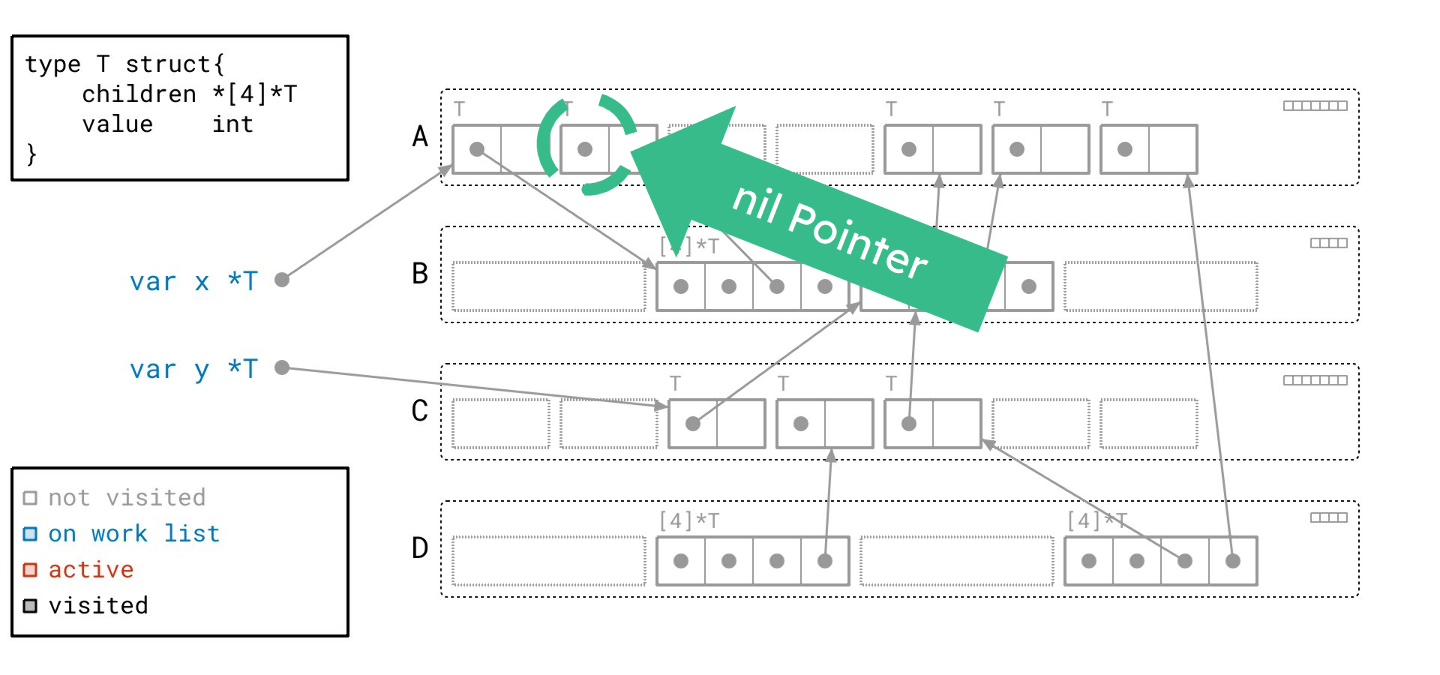
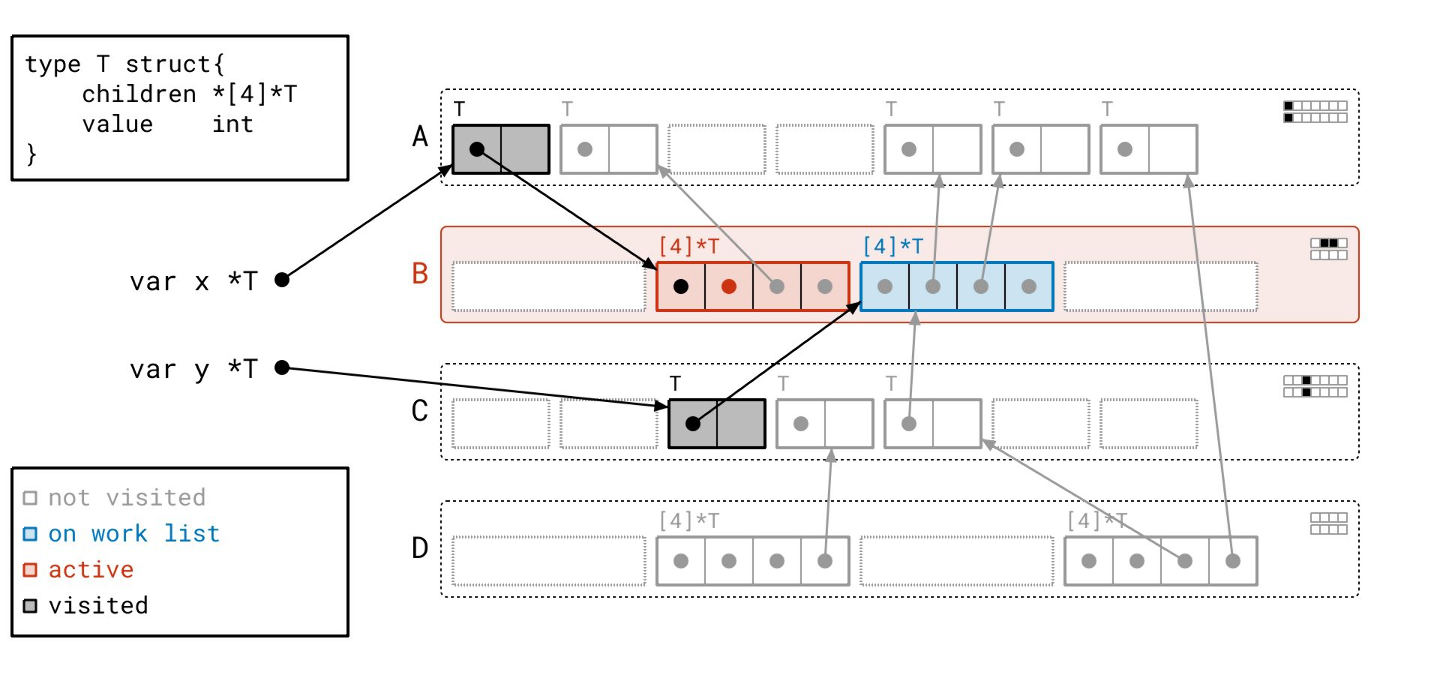
然后我们遍历数组对象引用的那些对象!
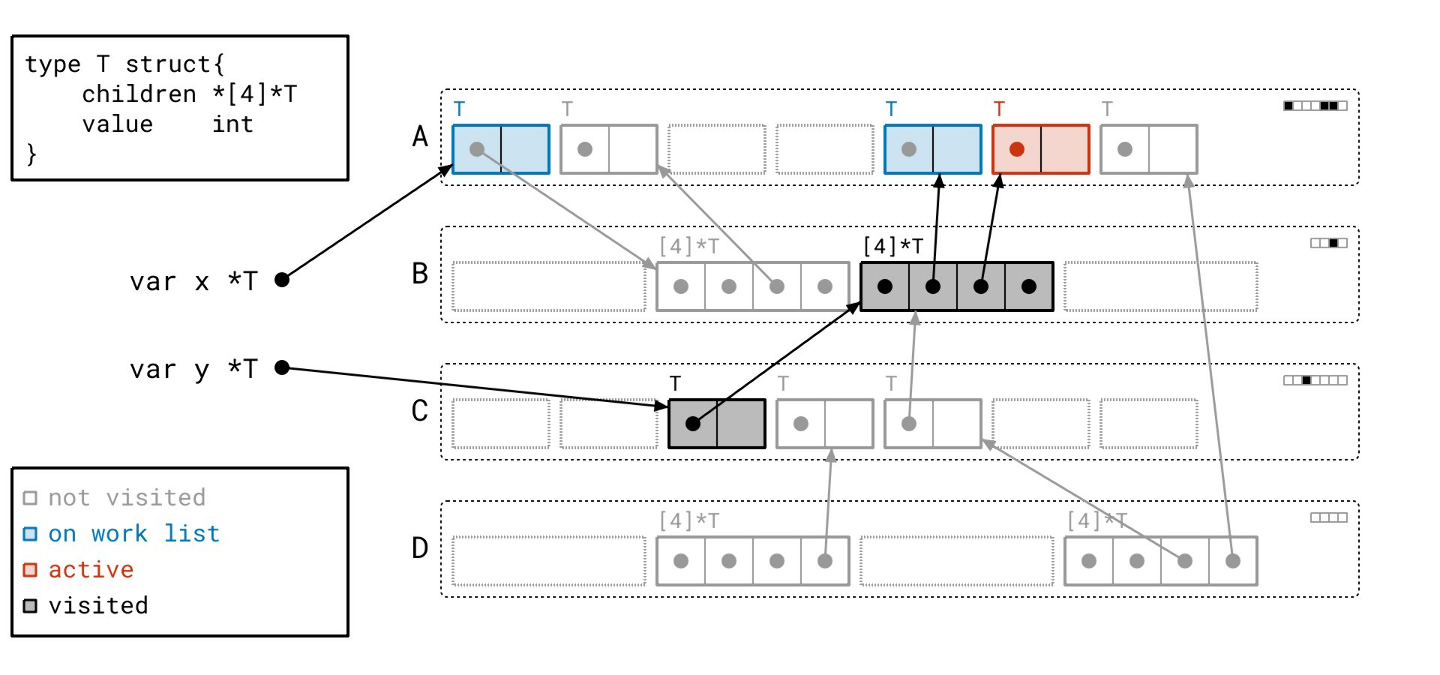
请注意,我们仍然需要遍历所有指针,即使它们是 nil。我们事先并不知道它们是否为空。
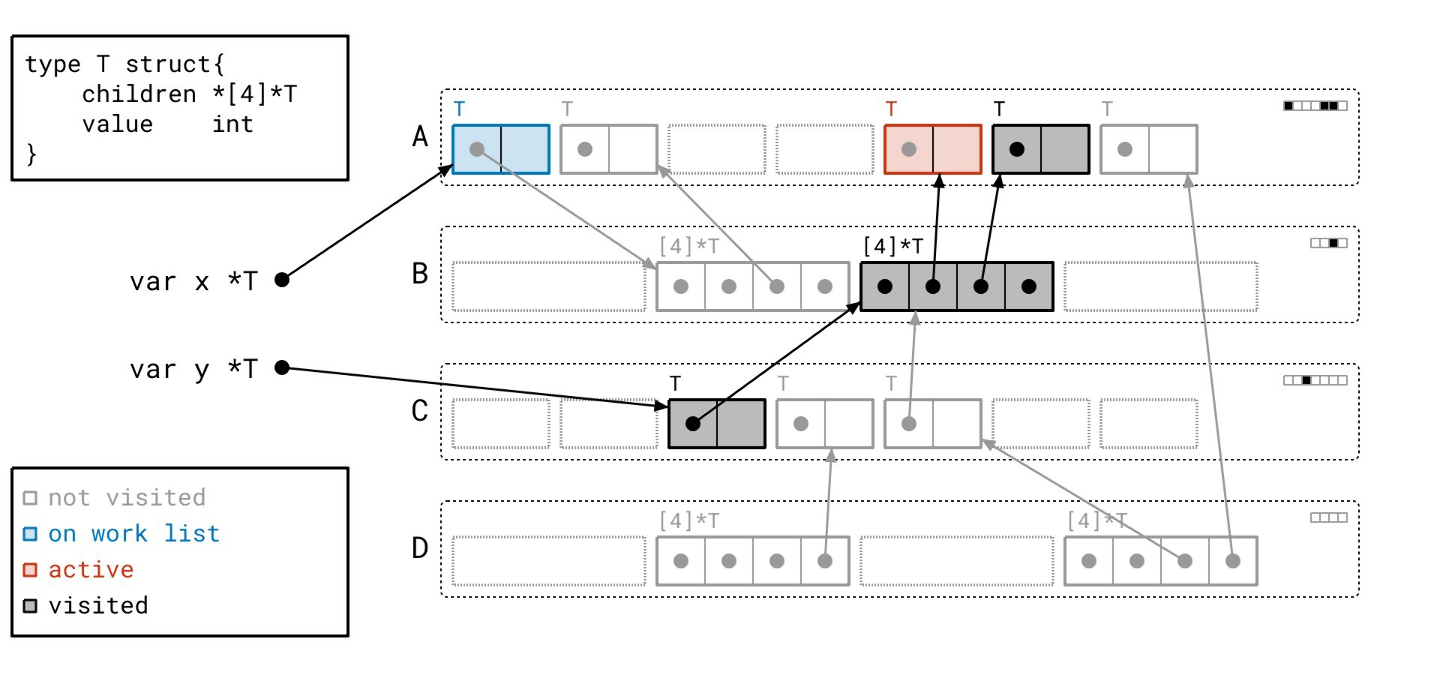
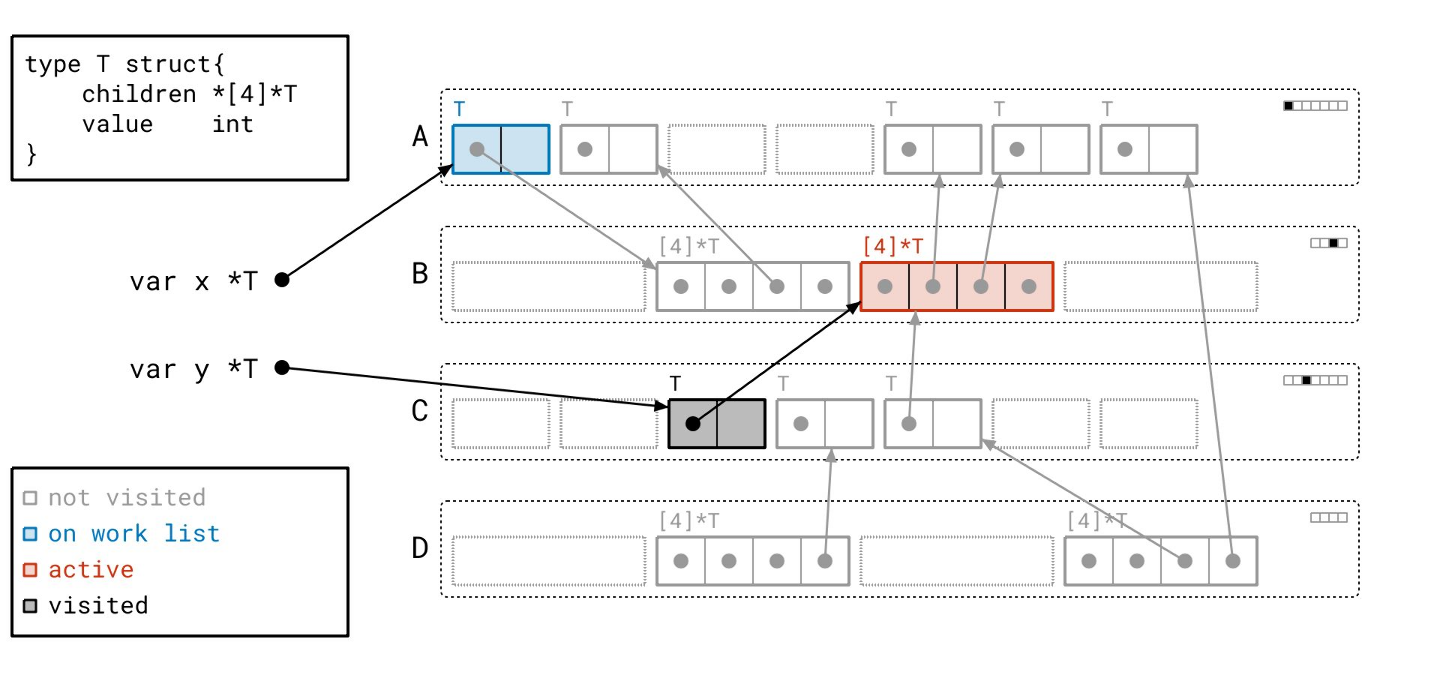
这个分支下还有一个对象…
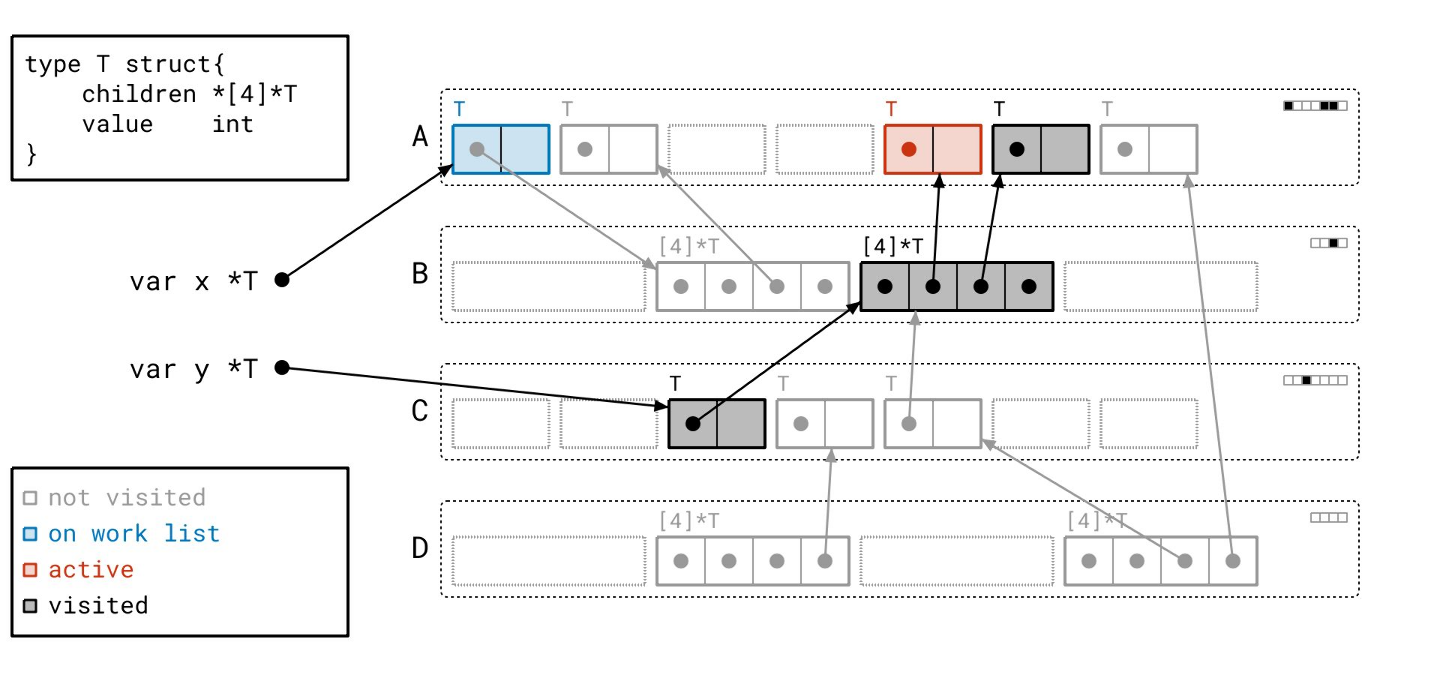
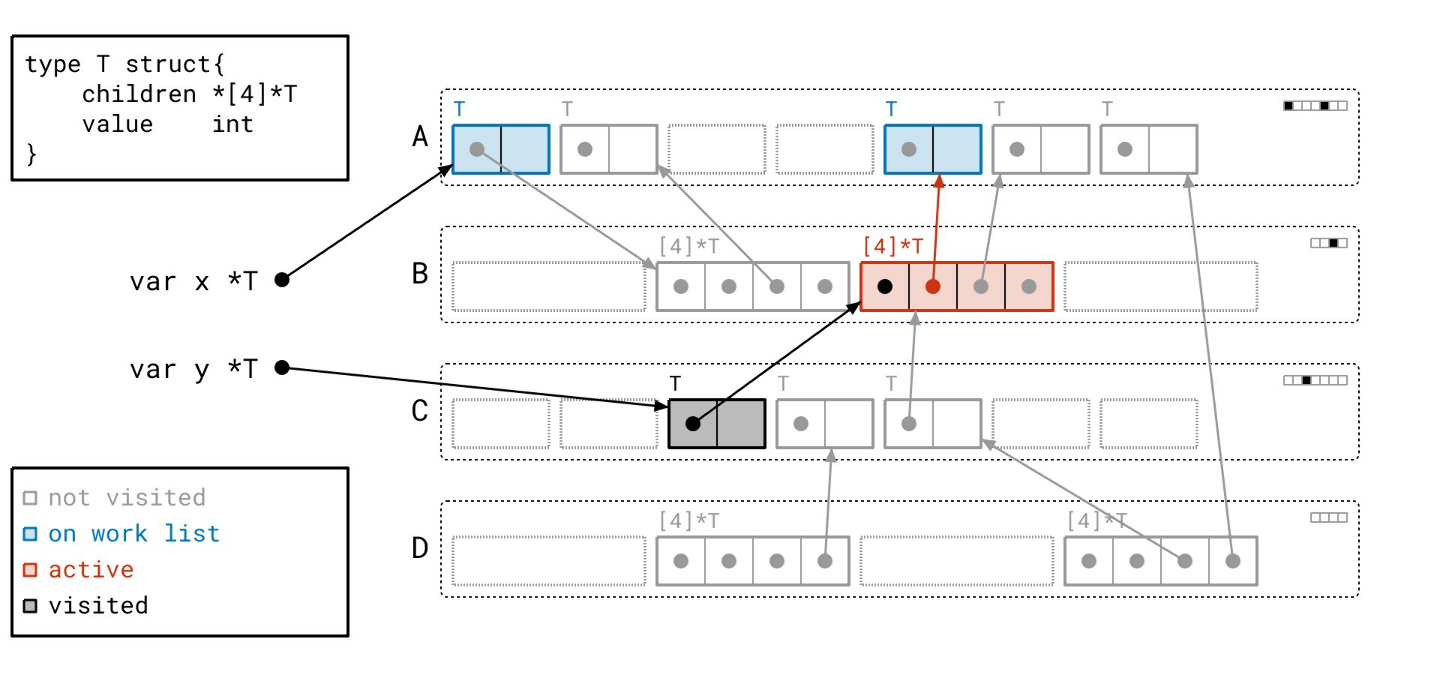
现在我们到达了另一个分支,从我们早先从某个根找到的页 A 中的那个对象开始。
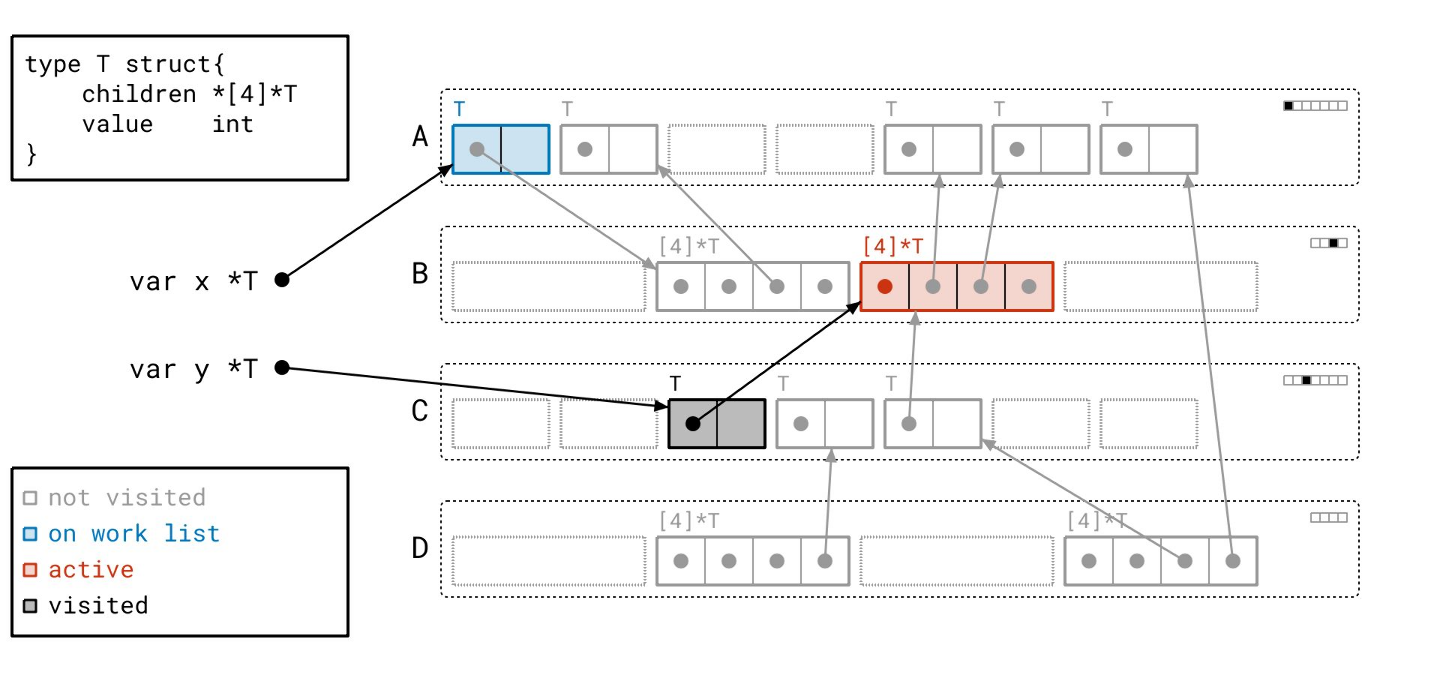
你可能注意到了我们工作列表的“后进先出”规则,这表明我们的工作列表是一个栈,因此我们的图遍历近似于深度优先。这是有意为之的,并反映了 Go 运行时中实际的图遍历算法。
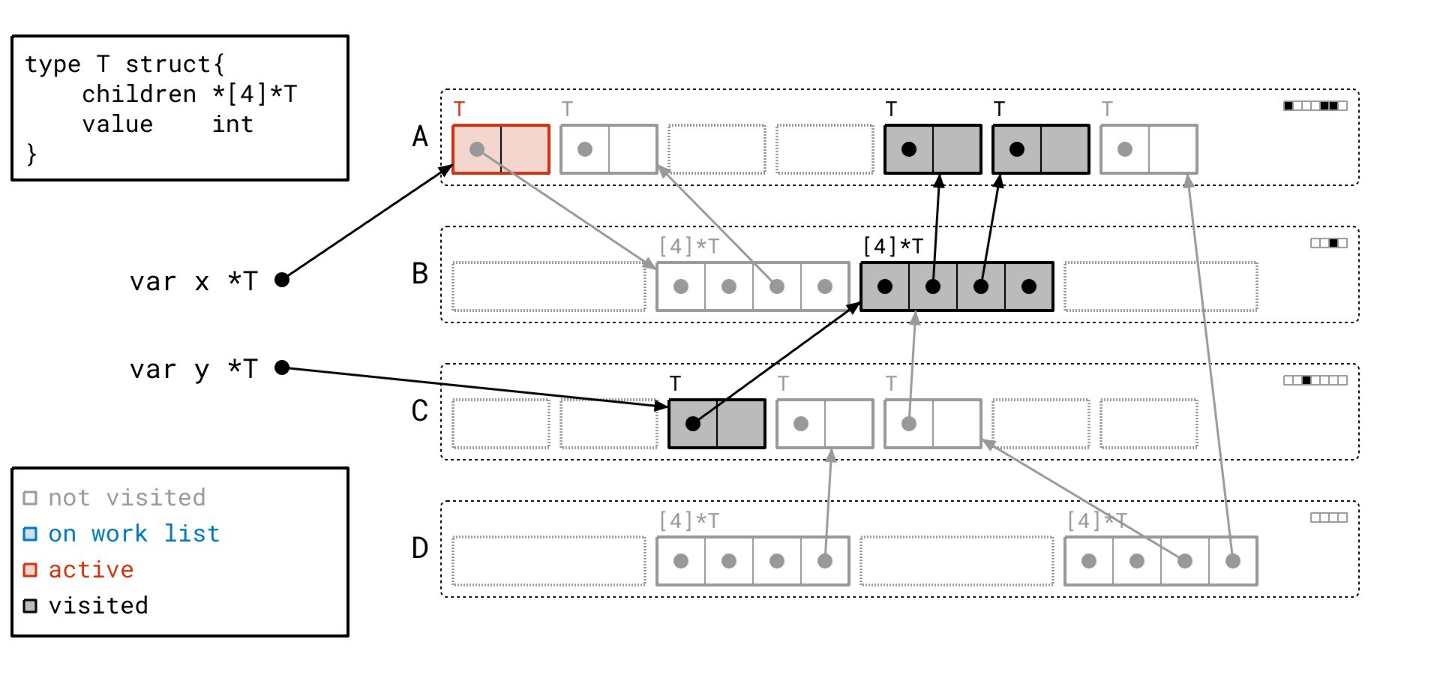
让我们继续…
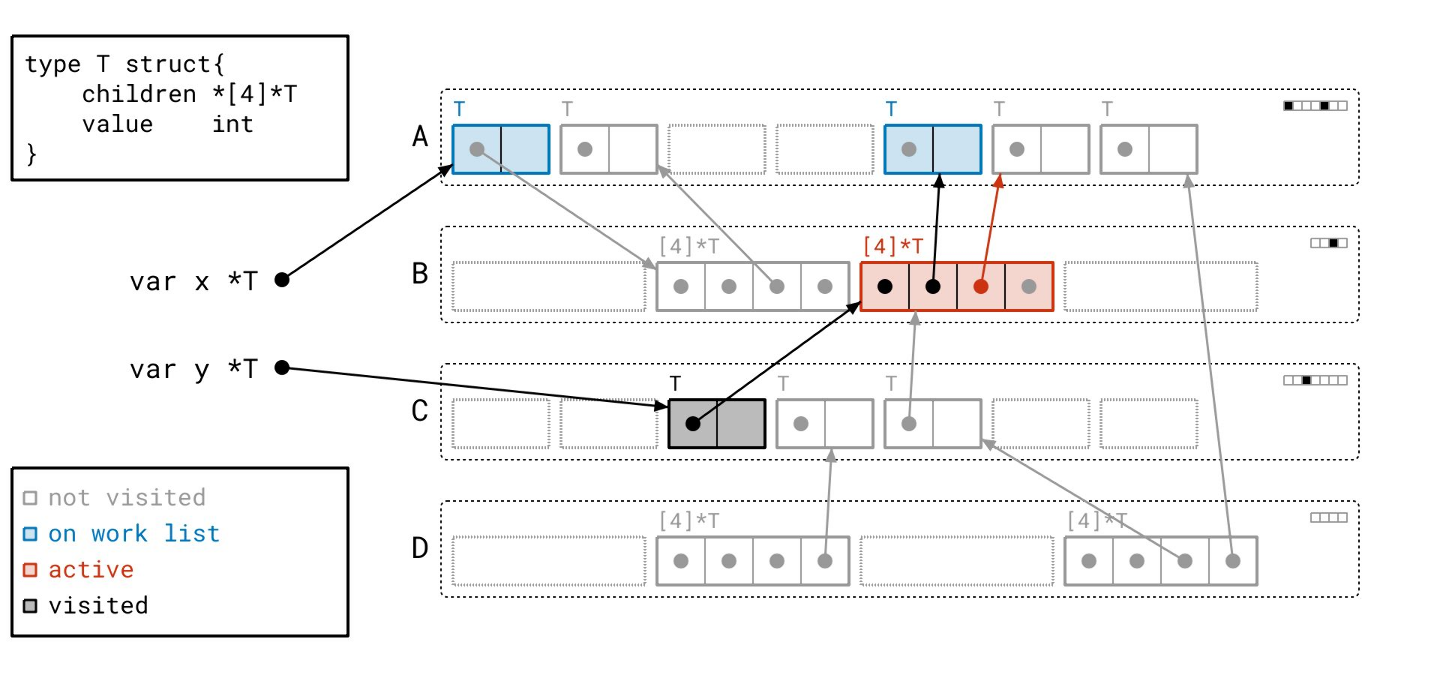
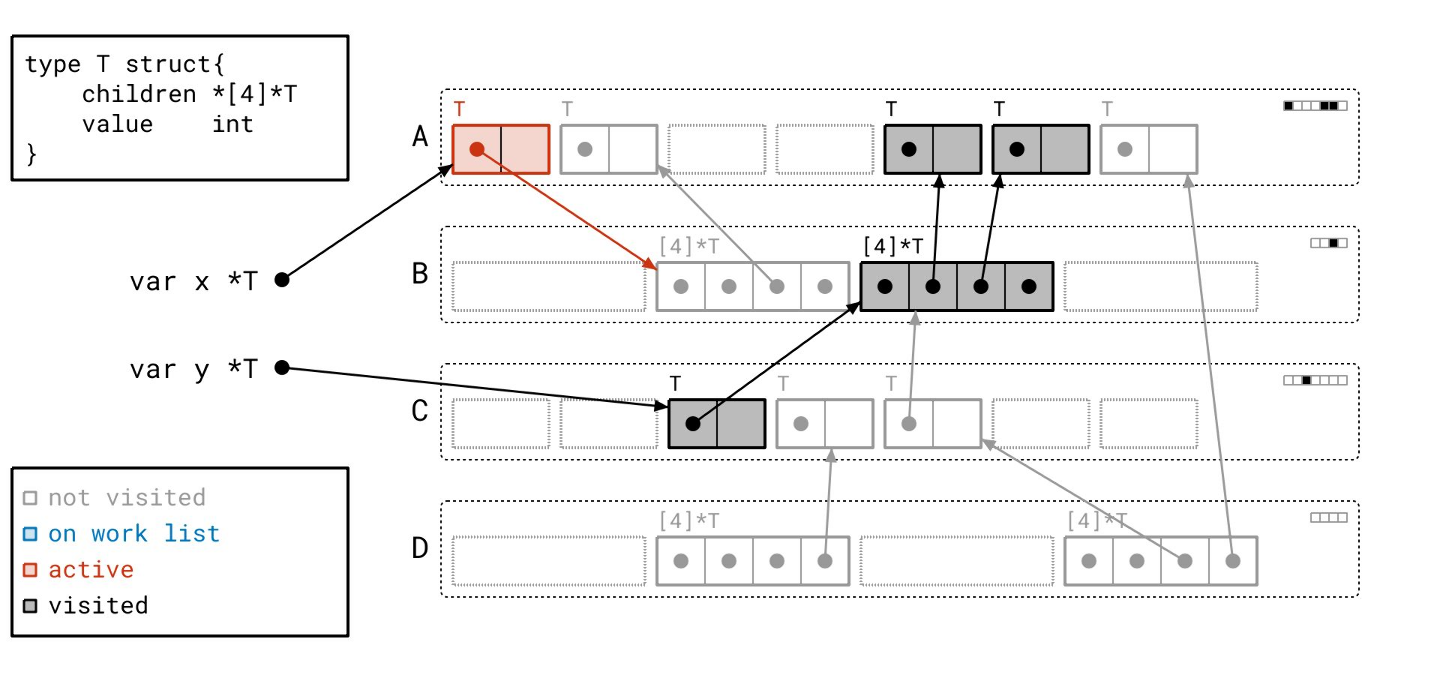
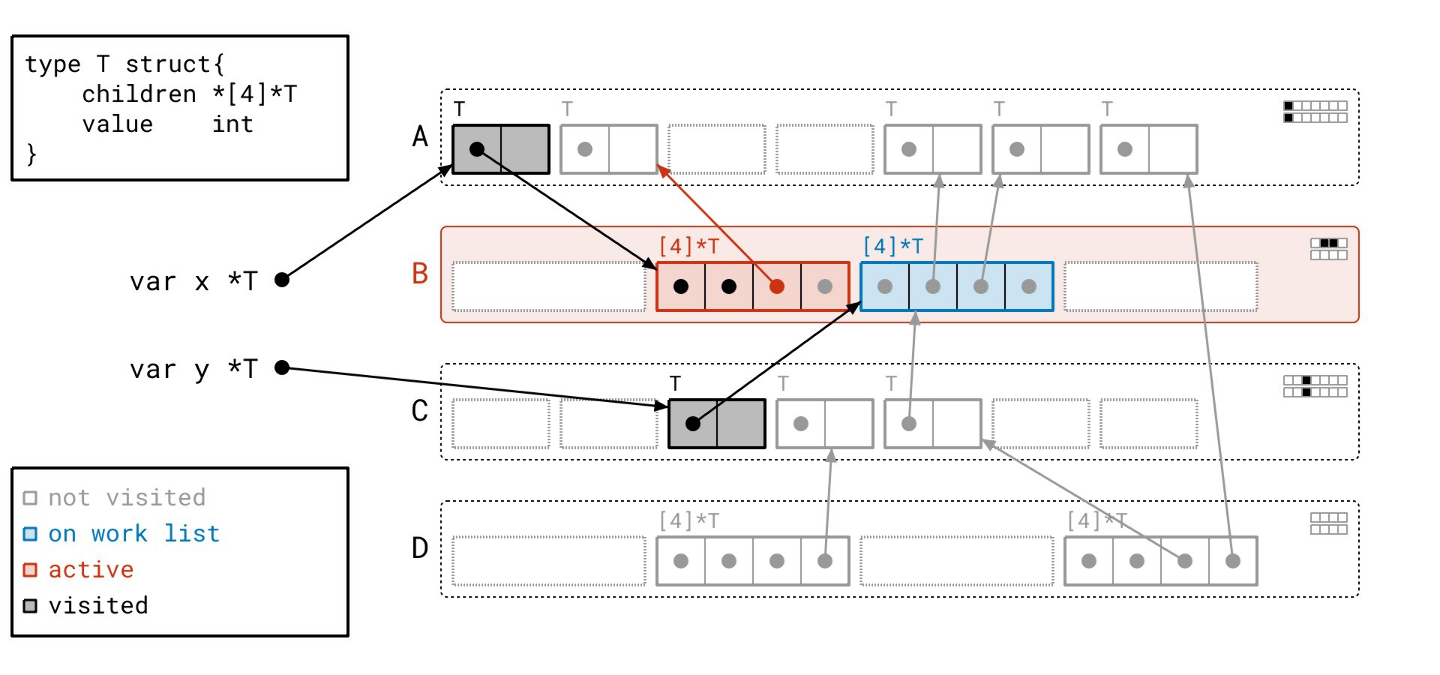
接下来我们找到了另一个数组对象…
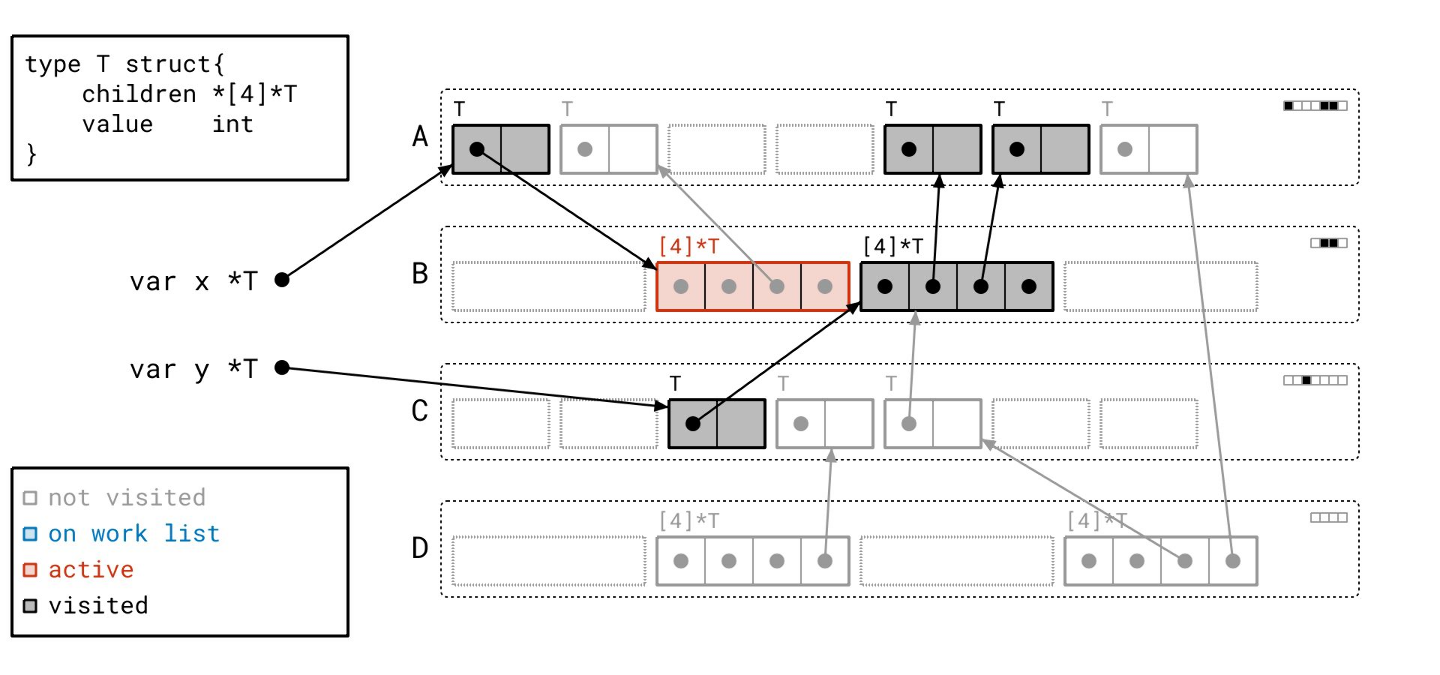
并遍历它…
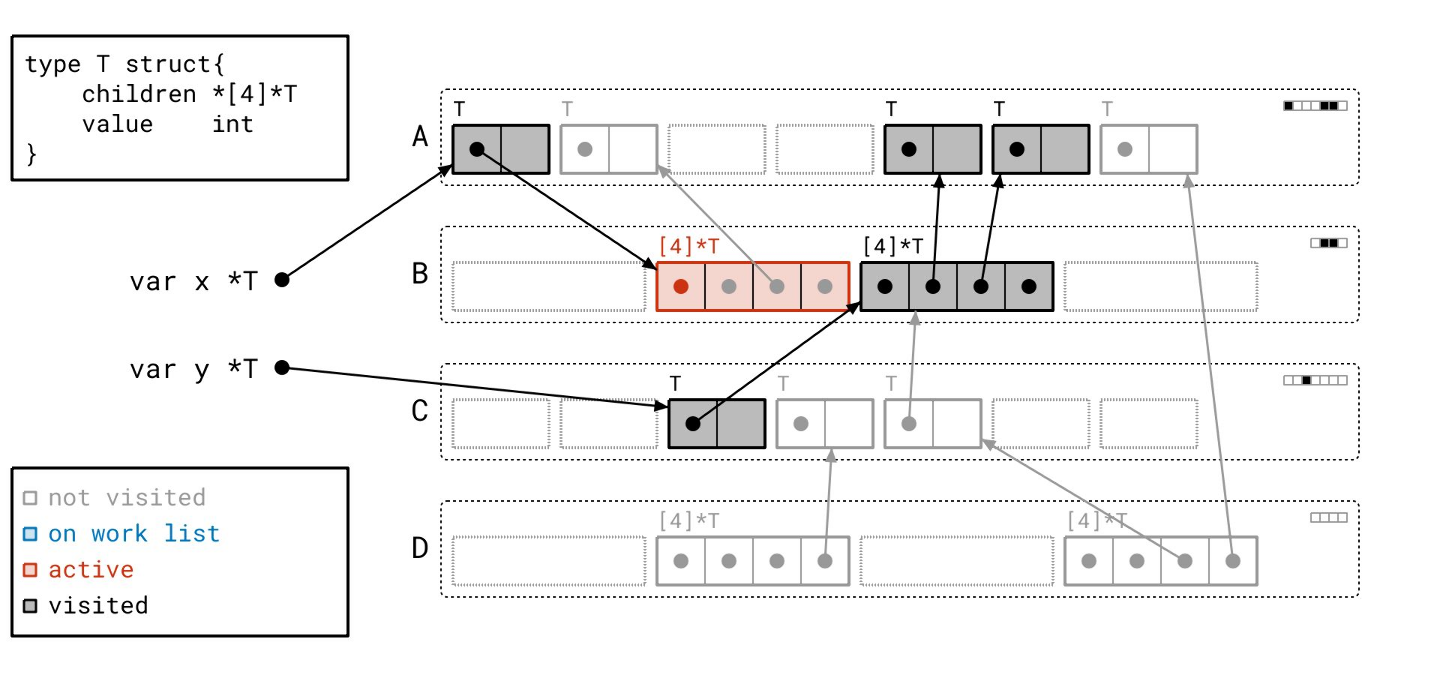
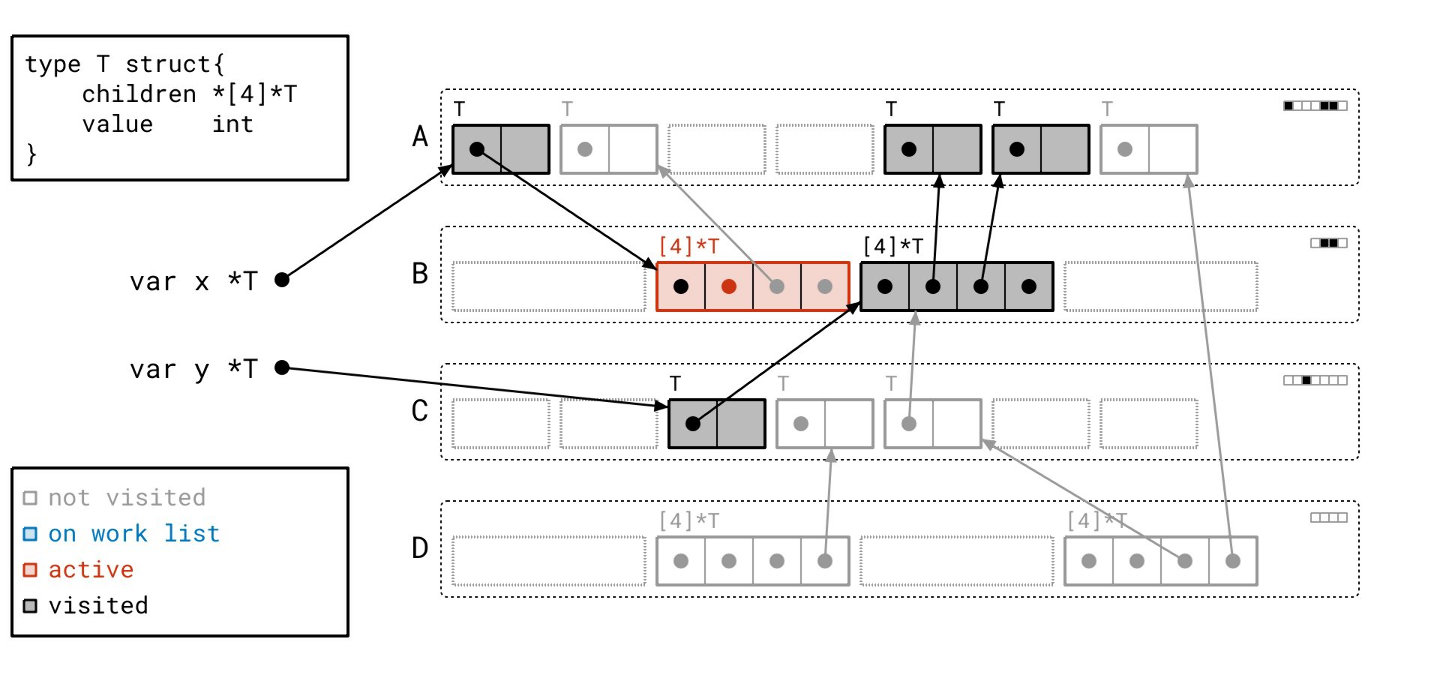
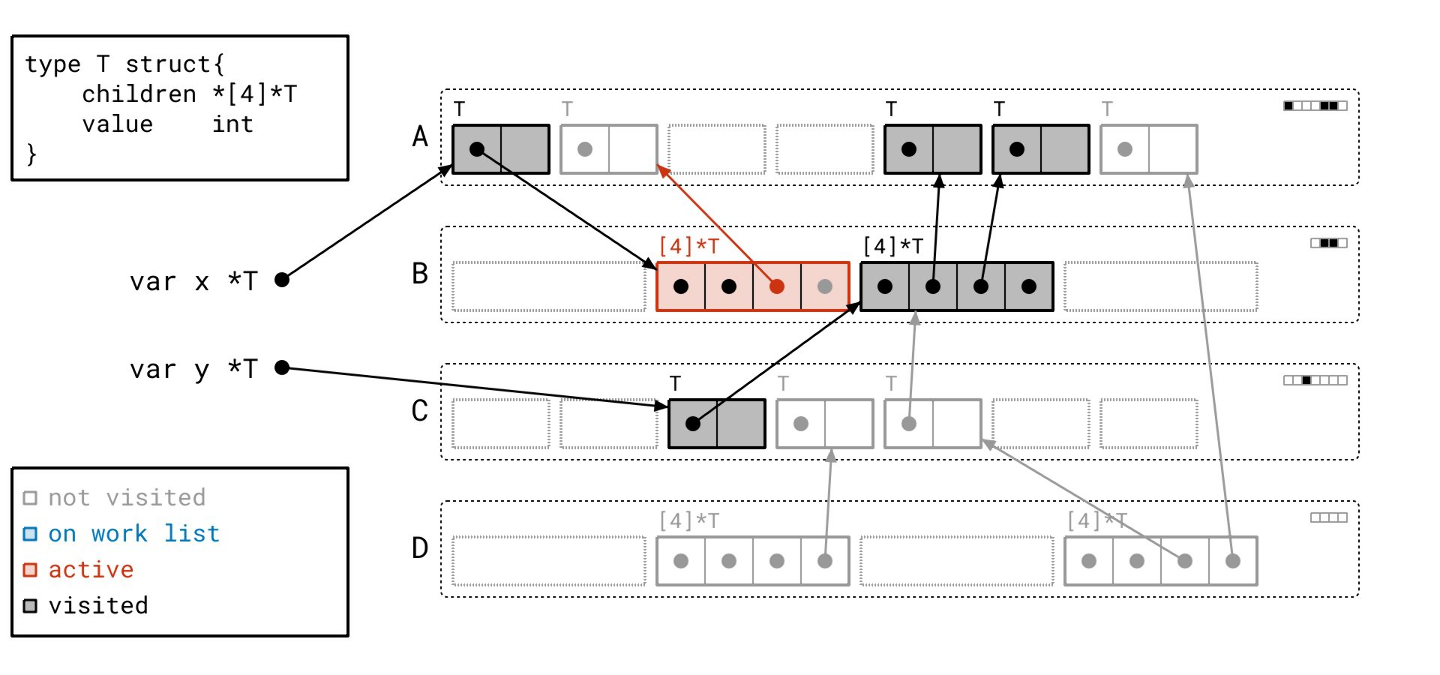
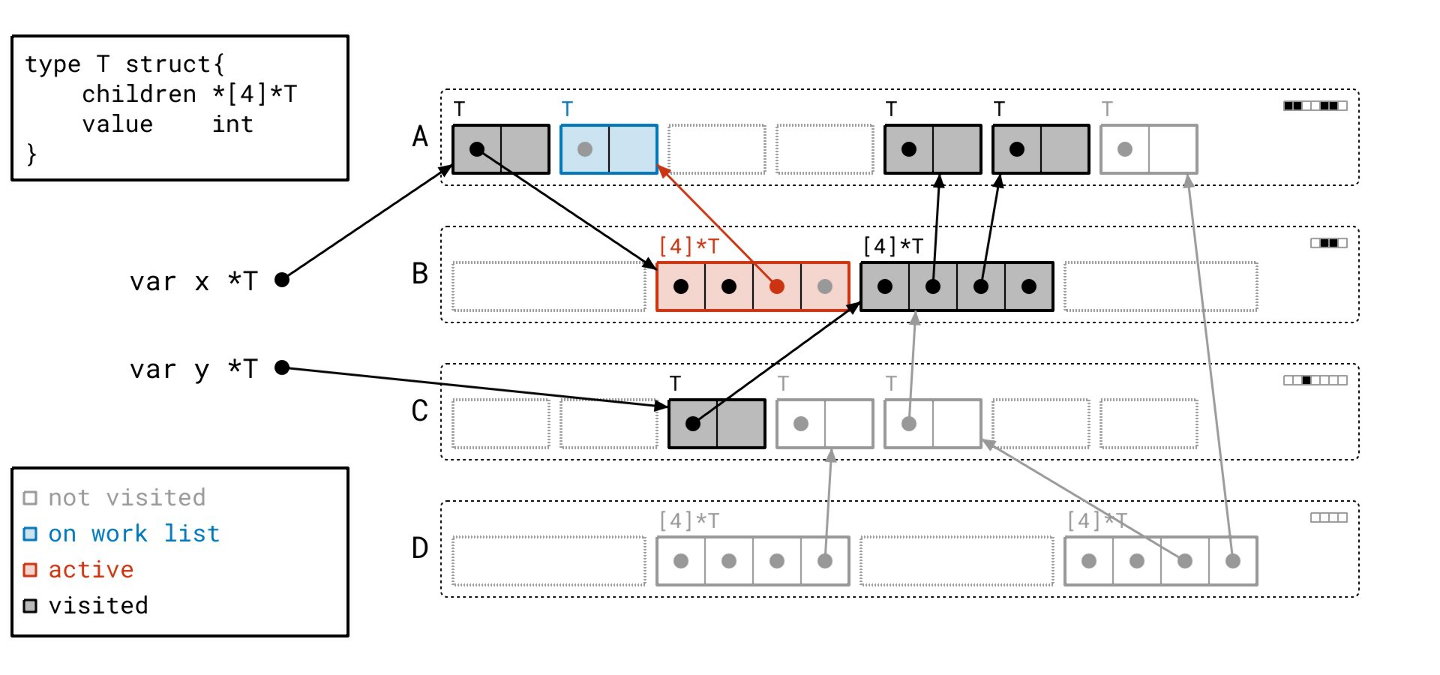
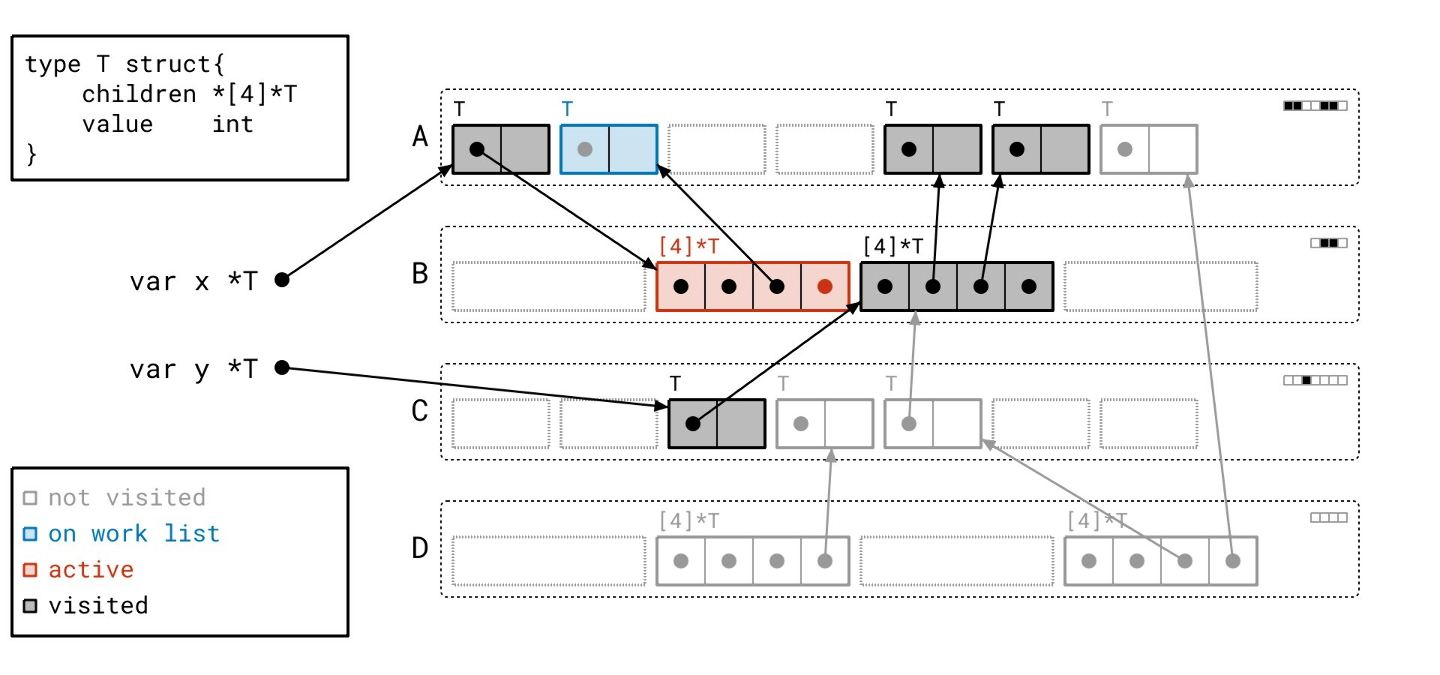
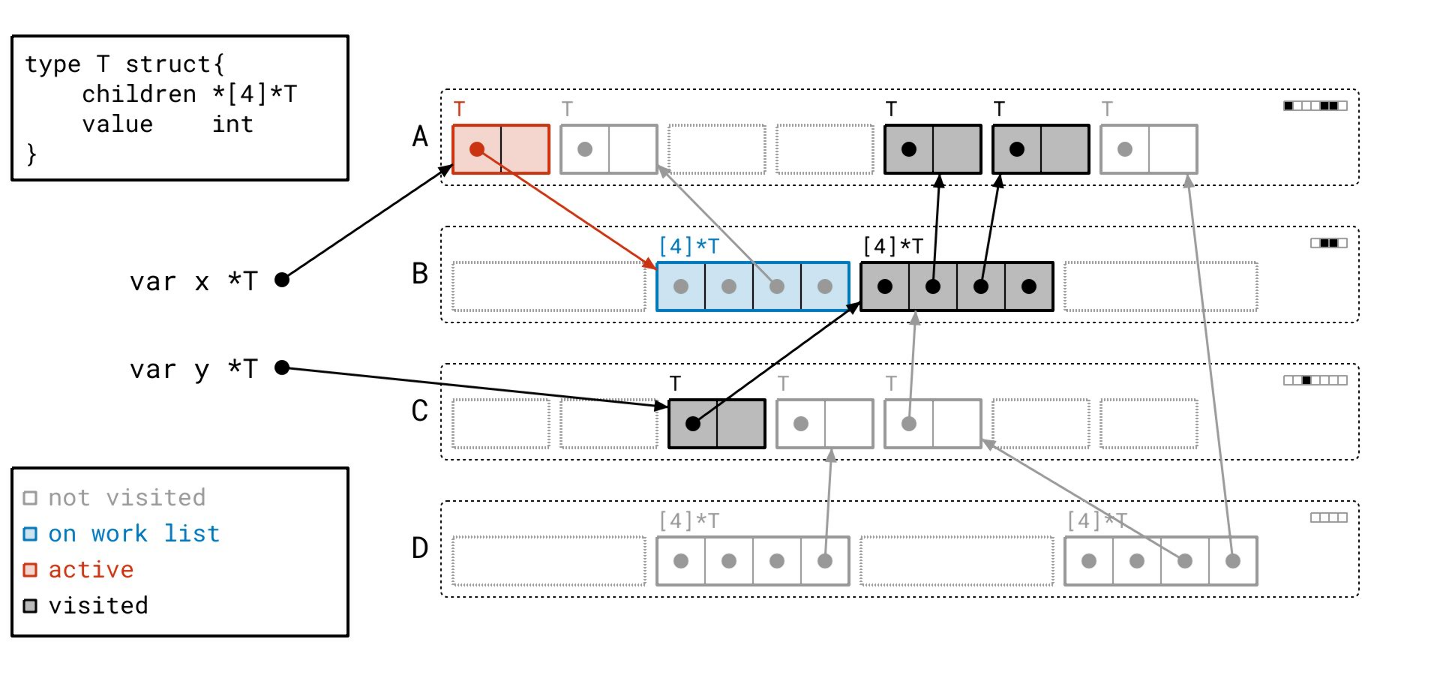
我们的工作列表上只剩最后一个对象了…
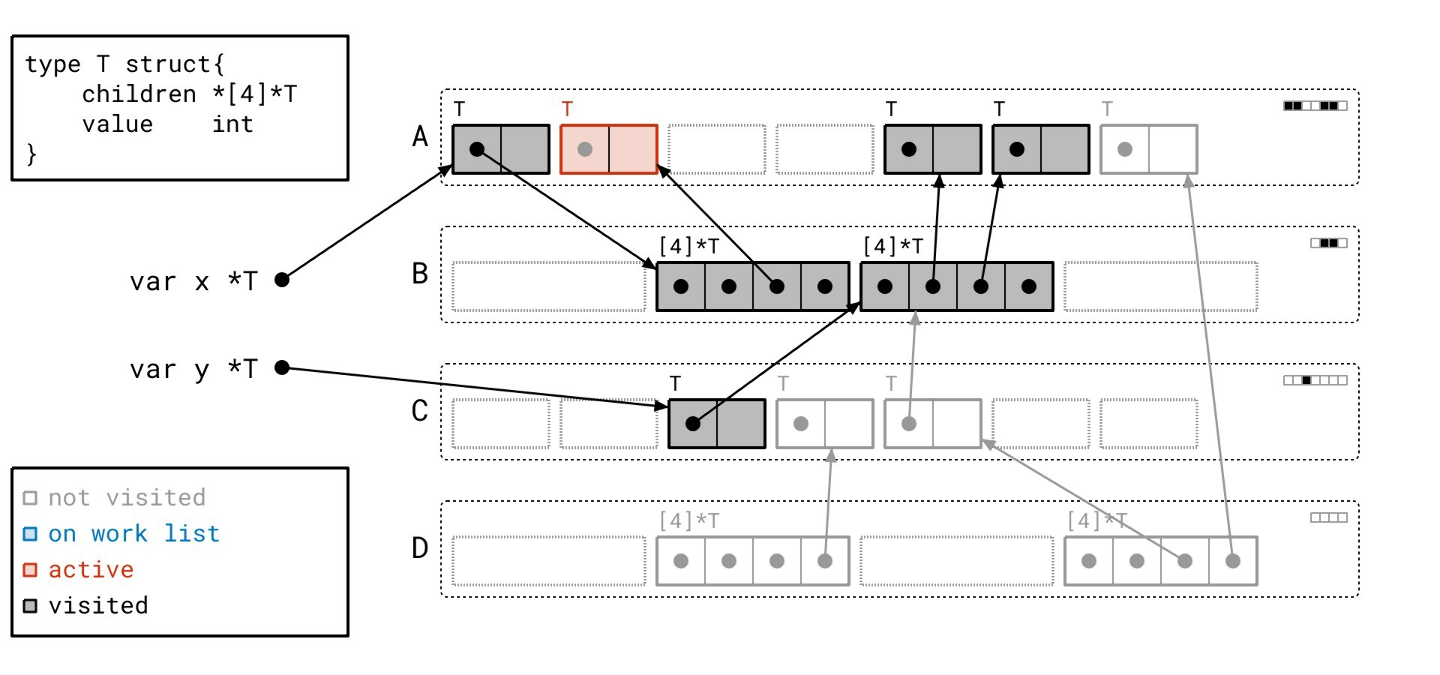
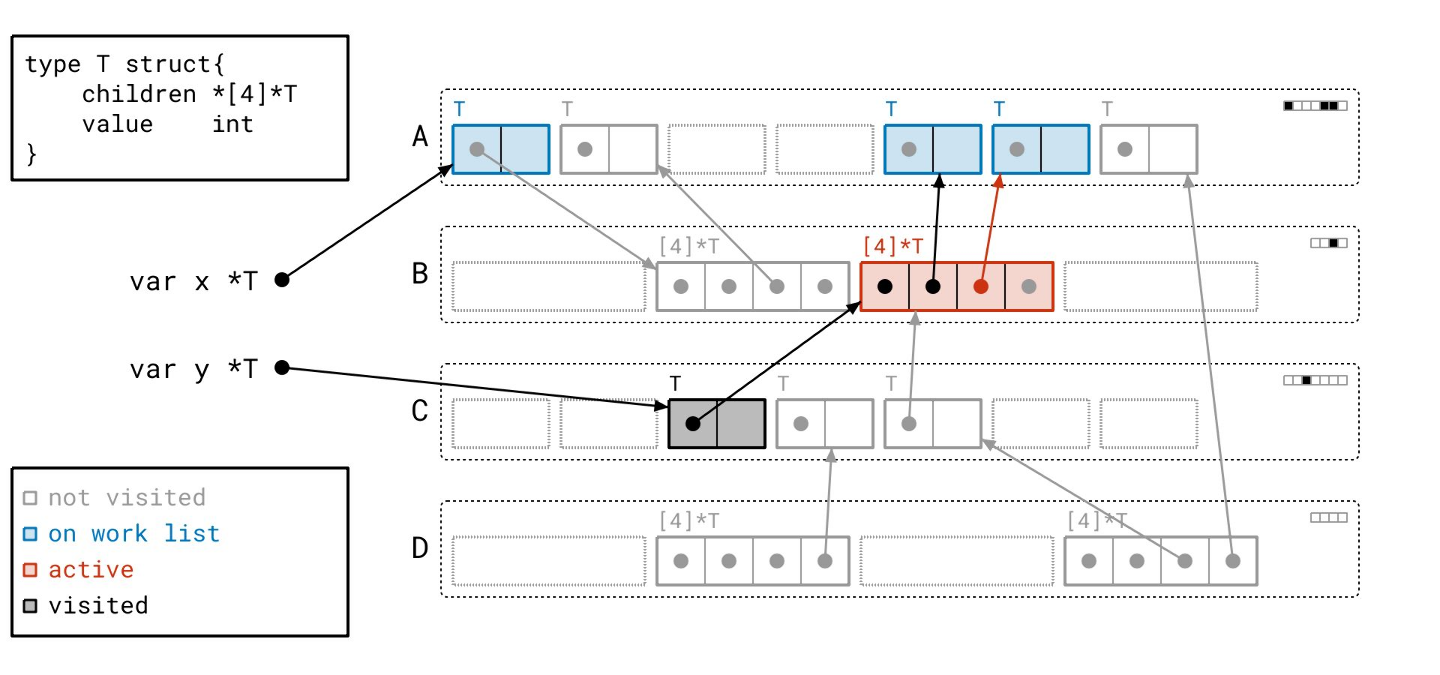
让我们扫描它…
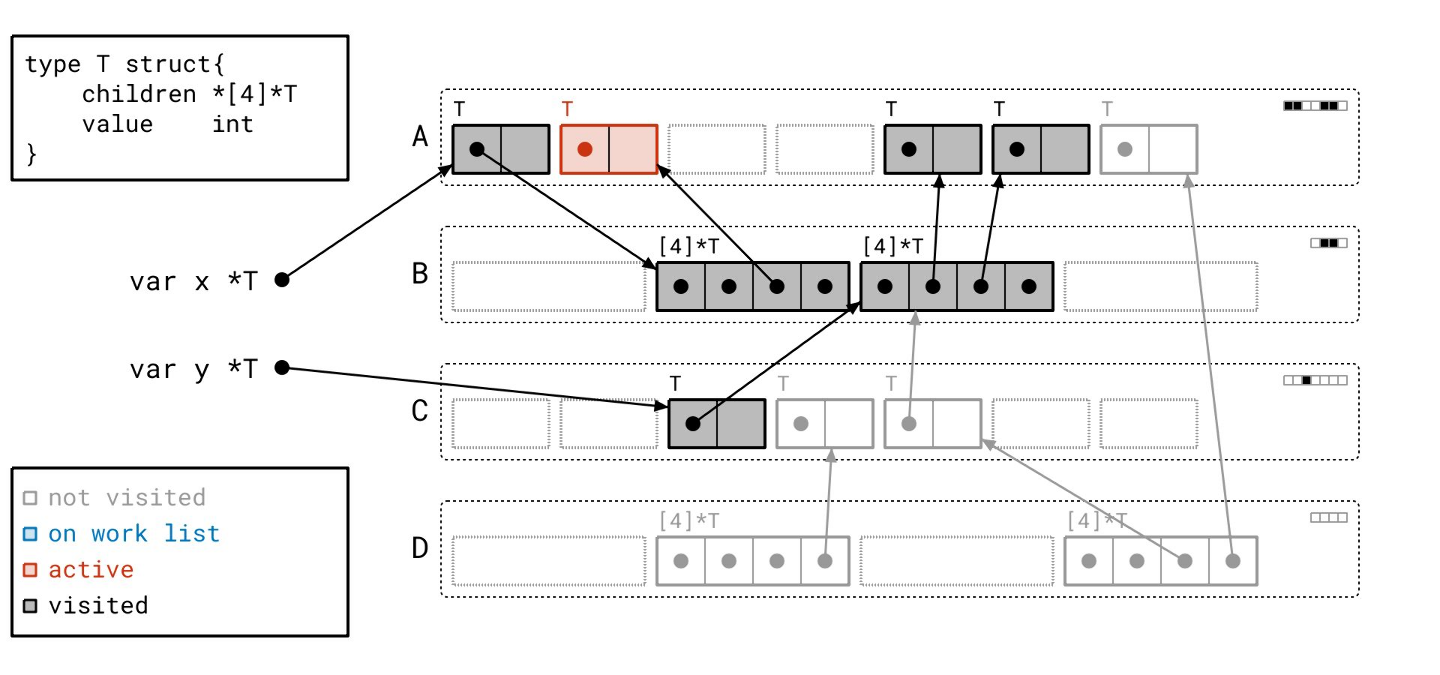
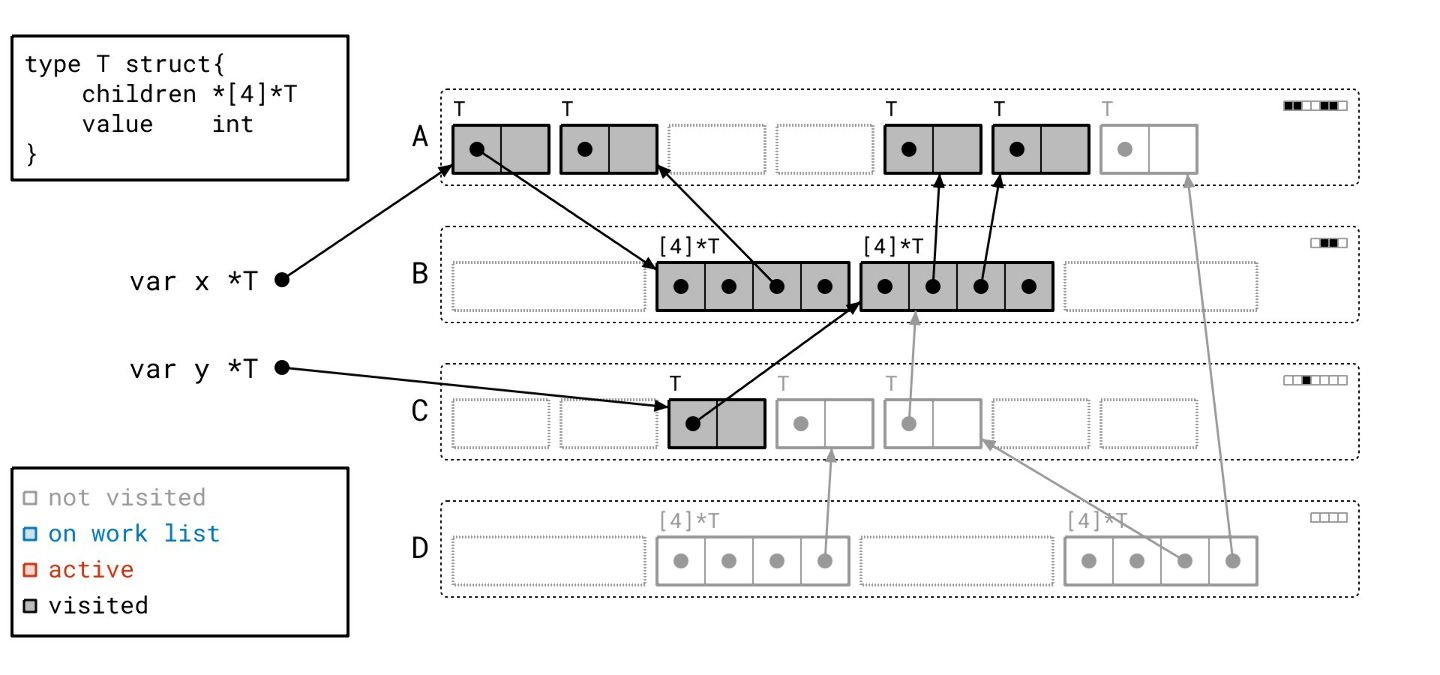
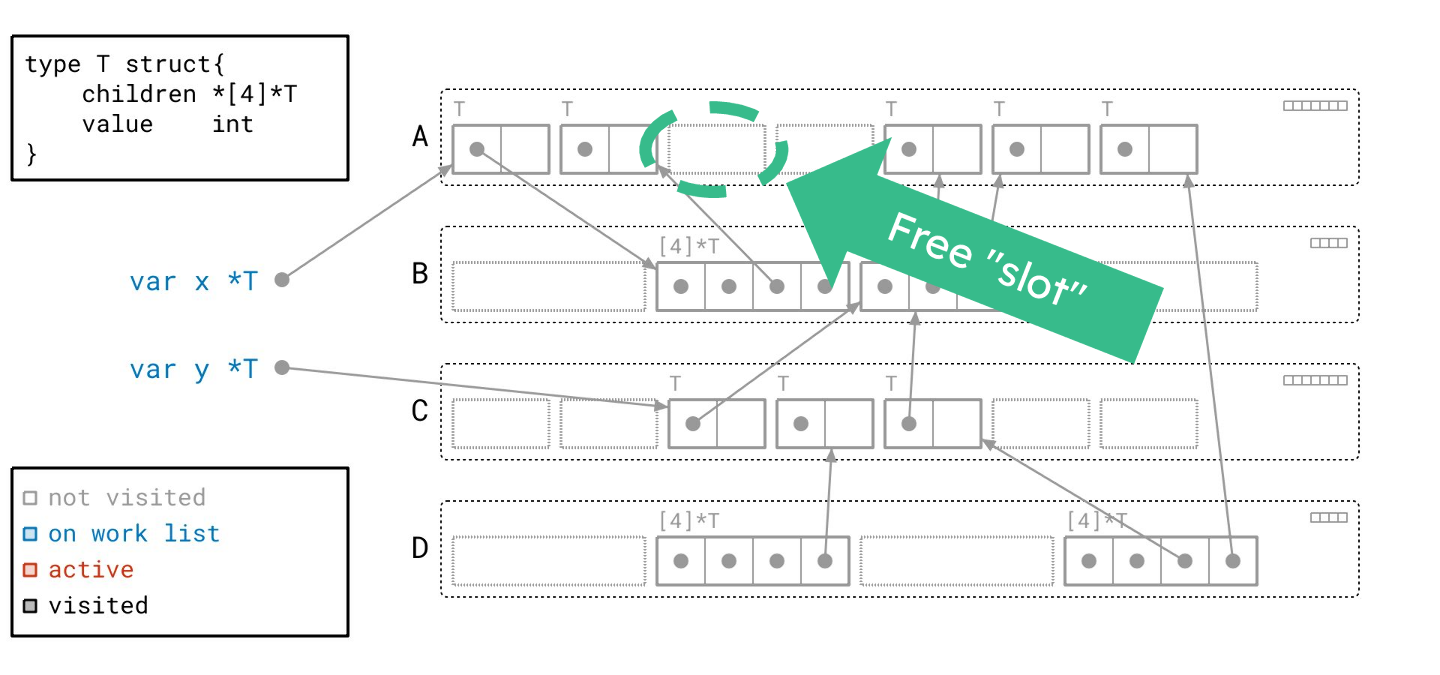
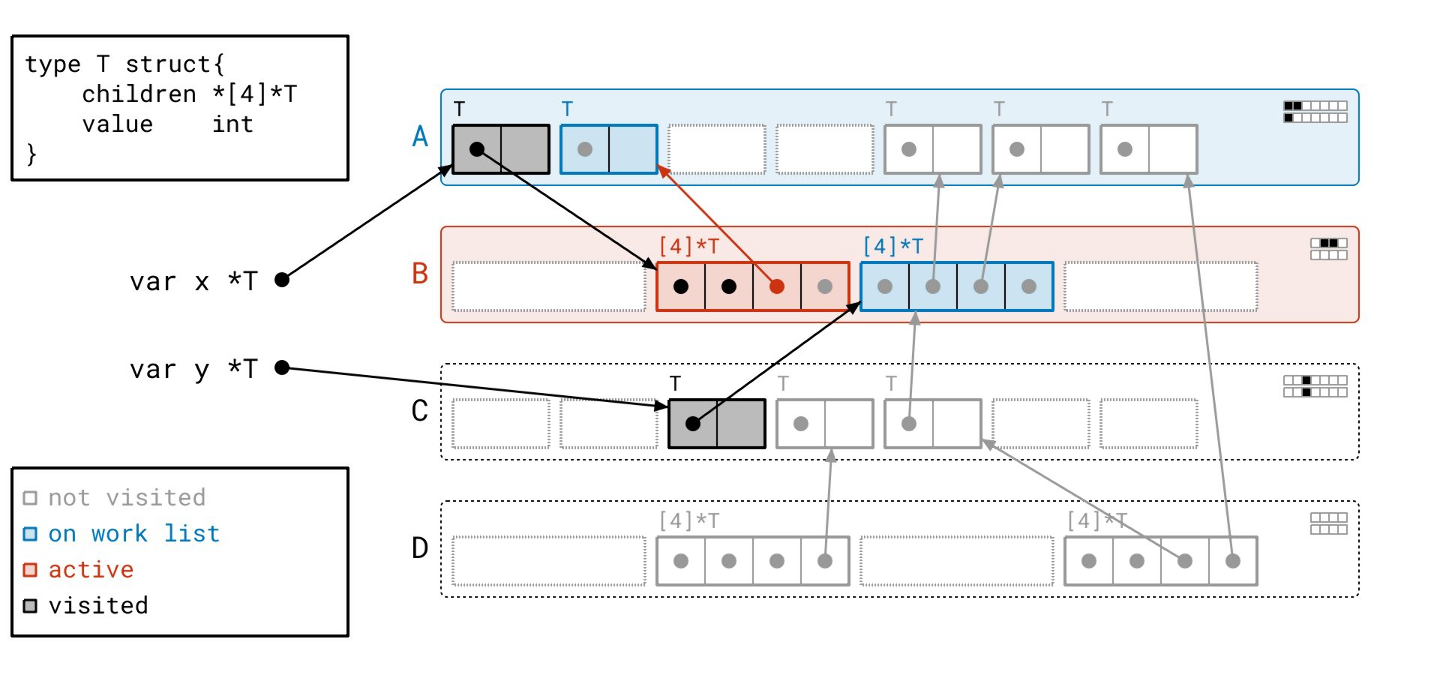
标记阶段完成了!我们没有任何正在处理的工作,工作列表也空了。所有用黑色绘制的对象都是可达的,所有用灰色绘制的对象都是不可达的。让我们一次性清除所有不可达的对象。
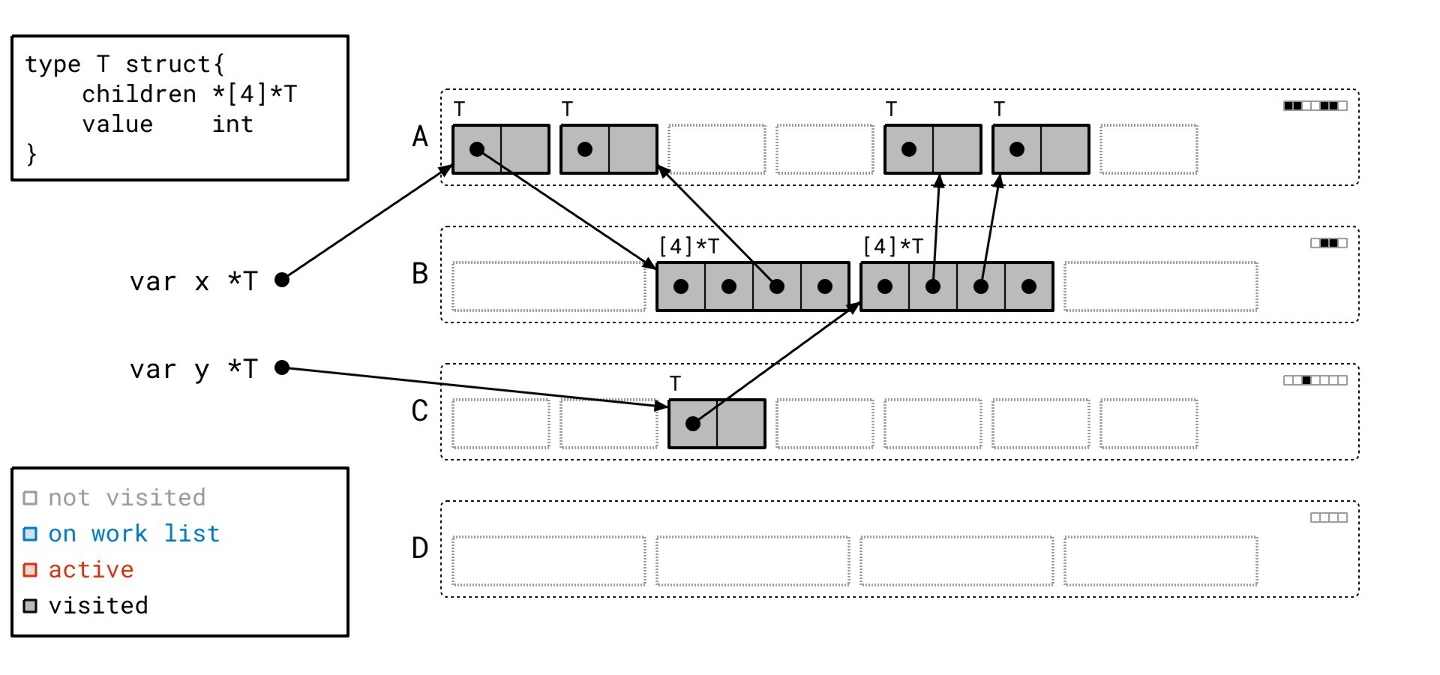
我们已将那些对象转换为空闲槽位,准备好容纳新的对象。
问题所在
经过上面一番摸索,我认为我们已经掌握了 Go 垃圾回收器的实际工作原理。目前看来,这个过程运行良好,那么问题出在哪里呢?
事实证明,在某些程序中,执行这个特定算法会花费大量时间,而且几乎会给所有 Go 程序带来显著的开销。Go 程序将 20% 甚至更多的 CPU 时间用于垃圾回收的情况并不少见。
让我们来分析一下这些时间都花在了哪里。
垃圾回收成本
在宏观层面上,垃圾回收器的成本由两部分组成。一是运行频率,二是每次运行所做的工作量。将这两者相乘,就得到了垃圾回收的总成本。
Total GC cost = Number of GC cycles × Average cost per GC cycle
即 总 GC 成本 = GC 周期数 × 每个 GC 周期的平均成本
多年来,我们一直在研究这个等式中的这两个术语。要了解更多关于垃圾回收器运行频率的信息,请参阅 Michael 在 2022 年 GopherCon EU 大会上的关于内存限制的演讲。 Go 垃圾回收器的指南也对此主题进行了很多阐述,如果你想深入了解,值得一看。
但现在,我们只关注第二部分,即每个周期的成本。
多年来,我们不断研究 CPU Profile分析结果,试图提高性能,从中我们了解到 Go 的垃圾回收器有两大特点。
第一,大约 90% 的垃圾回收器成本都花在了标记上,只有大约 10% 是在清除。事实证明,清除比标记更容易优化,多年来 Go 已经拥有了一个非常高效的清除器。
第二,在那段用于标记的时间里,有相当大一部分(通常至少有 35%),都浪费在了访问堆内存上。这本身已经够糟糕了,更糟糕的是,它完全阻碍了现代 CPU 真正高速运行的关键机制。
“微架构灾难”
在这种情况下,“堵塞工作机制(gump up the works)”意味着什么?现代 CPU 的具体构造相当复杂,所以我们用一个类比来说明。
想象 CPU 在一条路上行驶,这条路就是你的程序。CPU 想要加速到很高的速度,为此它需要能看清前方的路,并且道路必须畅通。但图遍历算法对 CPU 来说,就像在城市街道里开车。CPU 看不到拐角后的情况,也无法预测接下来会发生什么。为了前进,它必须不断地减速、转弯、在红绿灯前停下、避开行人。你的引擎有多快几乎无关紧要,因为你根本没有机会真正跑起来。
让我们通过再次审视我们的例子来使这一点更具体。我在这里的堆上叠加了我们所走的路径。每个从左到右的箭头代表我们做的一段扫描工作,虚线箭头则显示了我们在不同扫描工作之间是如何跳转的。
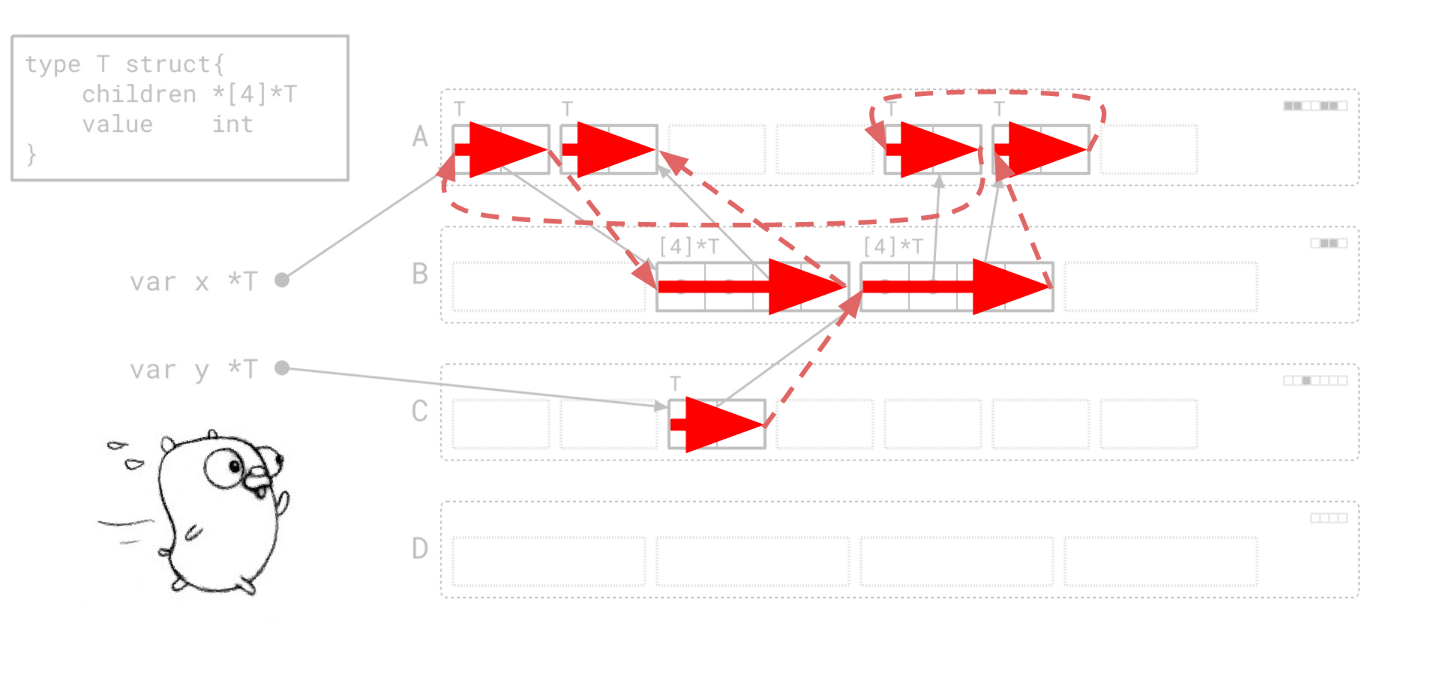
上图展示了我们的图泛洪示例中,垃圾回收器在堆中执行的路径。
请注意,我们正在内存中到处跳转,在每个地方只做一点点工作。特别是,我们频繁地在页之间,以及页的不同部分之间跳转。
现代 CPU 做了大量的缓存。访问主内存可能比访问缓存中的内存慢上 100 倍。CPU 缓存中填充的是最近访问过的内存,以及与最近访问过的内存相邻的内存。但是,并不能保证两个相互指向的对象在内存中也彼此靠近。图泛洪算法并没有考虑到这一点。
补充一点:如果我们只是在等待从主内存中获取数据,情况可能还没那么糟。CPU 会异步地发出内存请求,所以即使是慢的请求也可以重叠,只要 CPU 能看得足够远。但在图遍历中,每一小段工作都是不可预测的,并且高度依赖于上一段工作,所以 CPU 被迫几乎在每一次独立的内存获取后都进行等待。
不幸的是,对我们来说,这个问题只会越来越严重。业界有句格言:“等两年,你的代码会变得更快。”
但 Go,作为一个依赖于标记-清除算法的垃圾回收语言,却面临着相反的风险。“等两年,你的代码会变得更慢。” 现代 CPU 硬件的趋势正在给垃圾回收器的性能带来新的挑战:
-
非一致性内存访问 (Non-uniform memory access)。 首先,内存现在往往与 CPU 核心的子集相关联。其他 CPU 核心访问该内存的速度比前者慢。换句话说,主内存访问的成本取决于哪个 CPU 核心正在访问它 。这种成本是不一致的,因此我们称之为非一致内存访问,简称 NUMA。
-
内存带宽减少 (Reduced memory bandwidth)。 每个 CPU 的可用内存带宽随着时间推移呈下降趋势。这意味着虽然我们拥有更多的 CPU 核心,但每个核心能够提交的数据量相对较少。 对主内存的请求导致未缓存的请求等待时间比以前更长。
-
越来越多的 CPU 核心 (Ever more CPU cores)。 上面,我们看的是一个顺序的标记算法,但真正的垃圾回收器是并行执行此算法的。这在核心数量有限的情况下扩展得很好,但即使经过精心设计,用于扫描的共享对象队列也会成为一个瓶颈。
-
现代硬件特性 (Modern hardware features)。 新硬件拥有像向量指令这样的酷炫功能,让我们能一次性操作大量数据。虽然这有可能大幅提升速度,但目前还不清楚如何才能实现这一点。因为标记工作包含很多不规则且通常是小块的工作。
绿茶(Green Tea)
最后,我们来看看绿茶算法,这是我们对标记扫描算法的一个新的尝试。绿茶算法的核心思想非常简单:
操作页面,而不是对象。
听起来很简单,对吧?然而,为了弄清楚如何安排对象图遍历的顺序以及我们需要跟踪哪些内容才能使其在实践中有效运作,我们做了大量的工作。
更具体地说,这意味着:
- 我们不再扫描对象,而是扫描整个页。
- 我们不再在工作列表上跟踪对象,而是跟踪整个页。
- 我们最终(在一个扫描周期结束时)仍然需要标记对象,但我们会跟踪每个页面本地标记的对象,而不是跟踪整个堆中的标记对象。
绿茶示例
让我们通过再次审视我们的示例堆,来看看这在实践中意味着什么,但这次运行的是“绿茶”而不是直接的图泛洪。
和之前一样,请跟随带注释的幻灯片进行浏览。
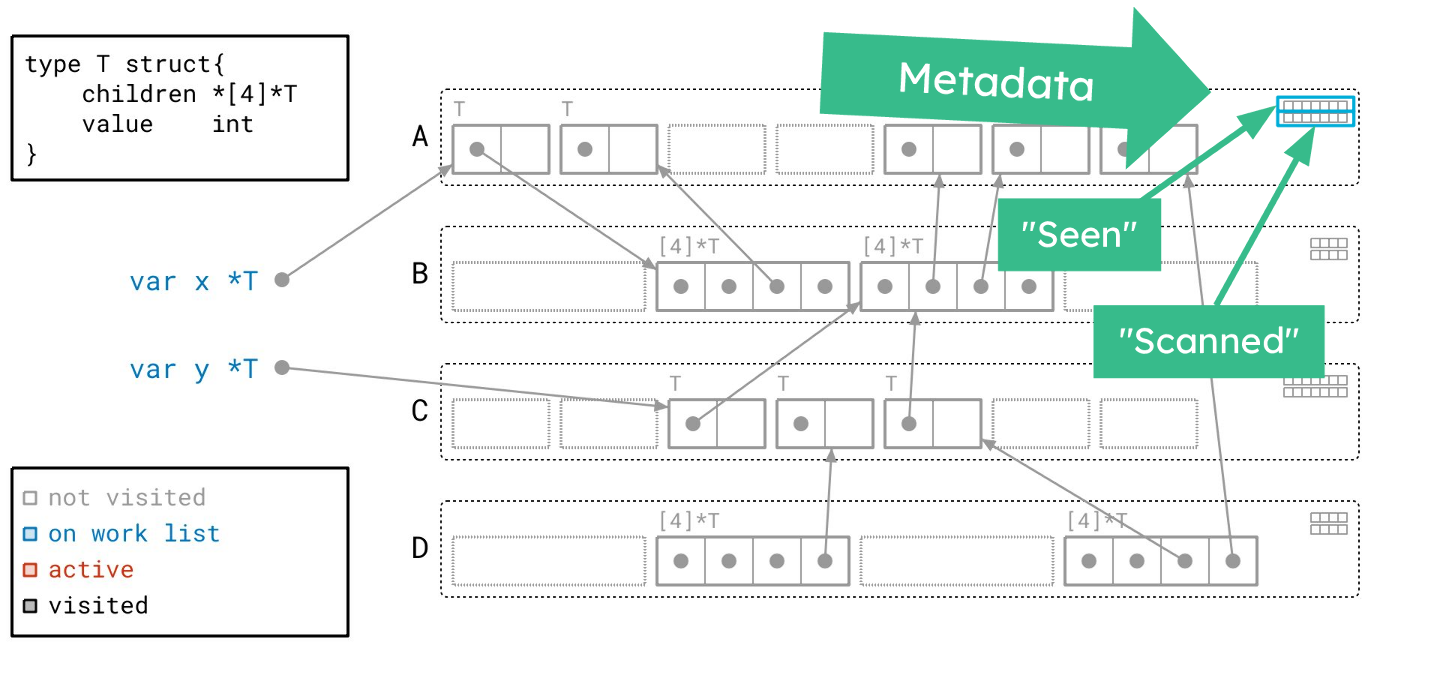
这和之前的堆是一样的,但现在每个对象有两个比特的元数据而不是一个。同样,每个比特或框,对应于页中的一个对象槽位。总的来说,我们现在有 14 个比特对应于页 A 中的七个槽位。
顶部的比特代表和以前一样的东西:我们是否见过一个指向该对象的指针。我称之为“已见” (seen) 位。底部的比特集是新的。这些“已扫描” (scanned) 位跟踪我们是否已经扫描了该对象。
这块新的元数据是必需的,因为在“绿茶”中,工作列表跟踪的是页,而不是对象。我们仍然需要在某种程度上跟踪对象,这就是这些比特的目的。
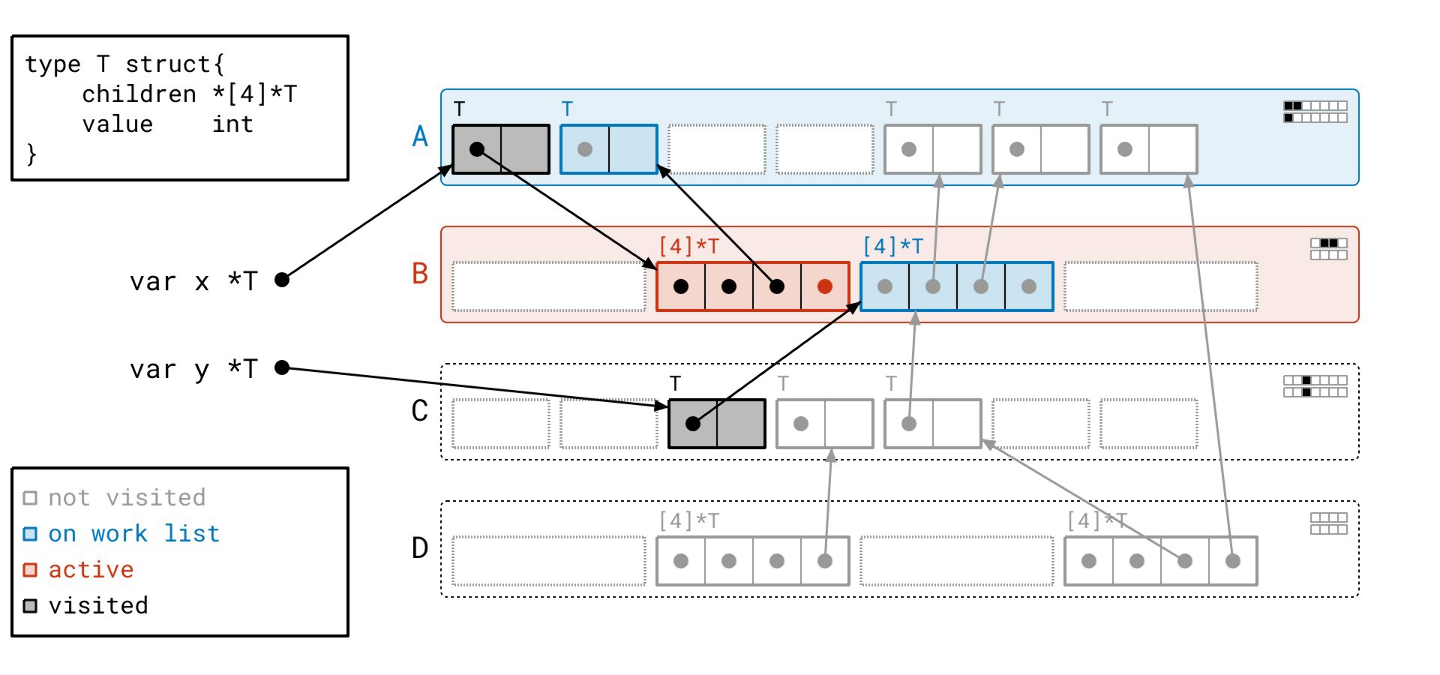
我们和以前一样开始,从根开始遍历对象。
但这一次,我们不是把一个对象放到工作列表上,而是把整个页——在这里是页 A——放到工作列表上,通过将整个页用蓝色阴影表示。
我们找到的对象也是蓝色的,表示当我们从工作列表中取出这个页时,我们将需要查看那个对象。请注意,对象的蓝色调直接反映了页 A 中的元数据。其对应的“已见”位被设置,但其“已扫描”位没有。
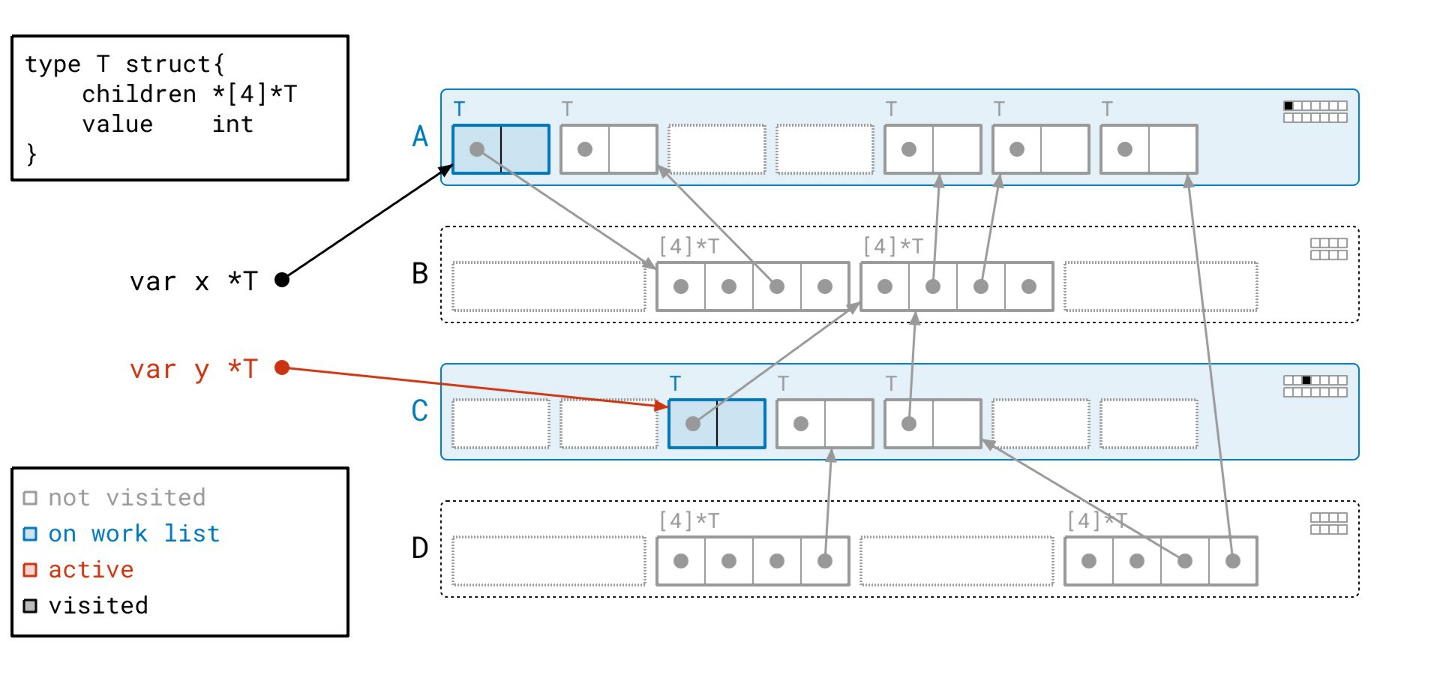
我们跟随下一个根,找到另一个对象,再次将整个页——页 C——放到工作列表上,并设置该对象的“已见”位。
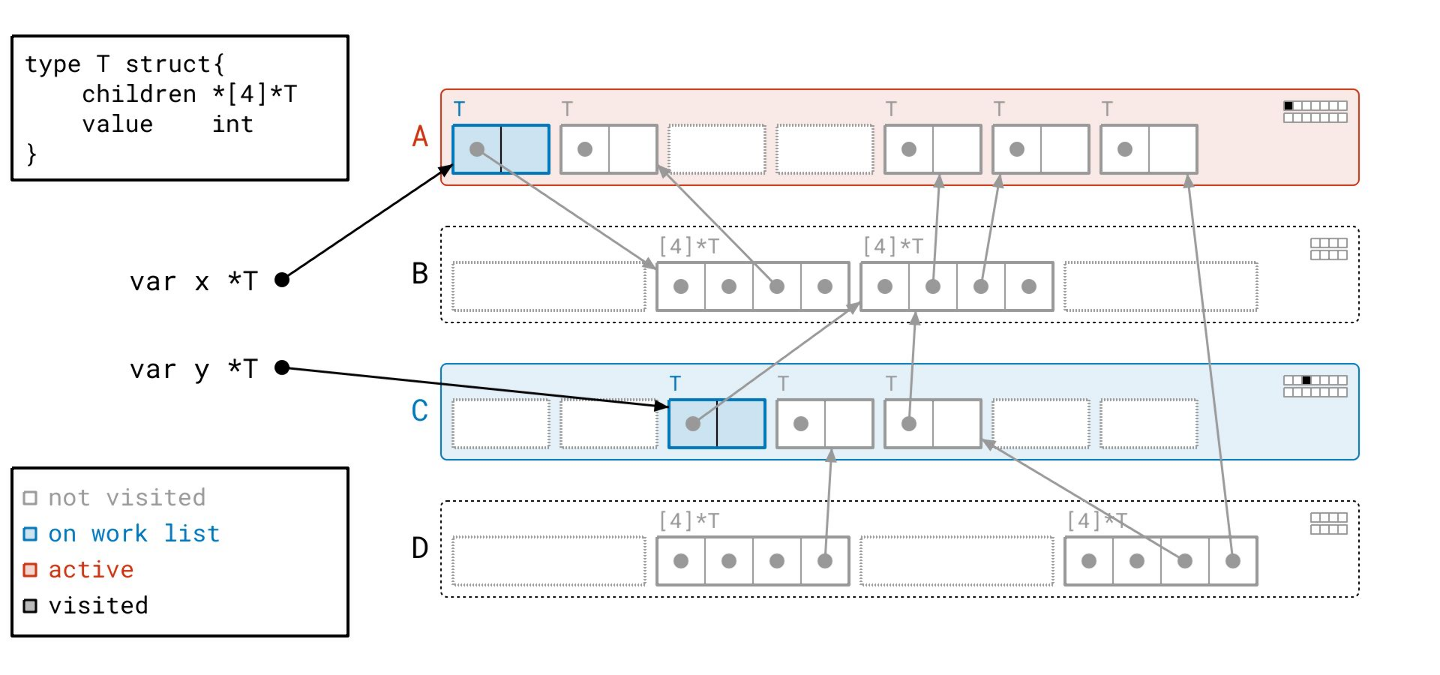
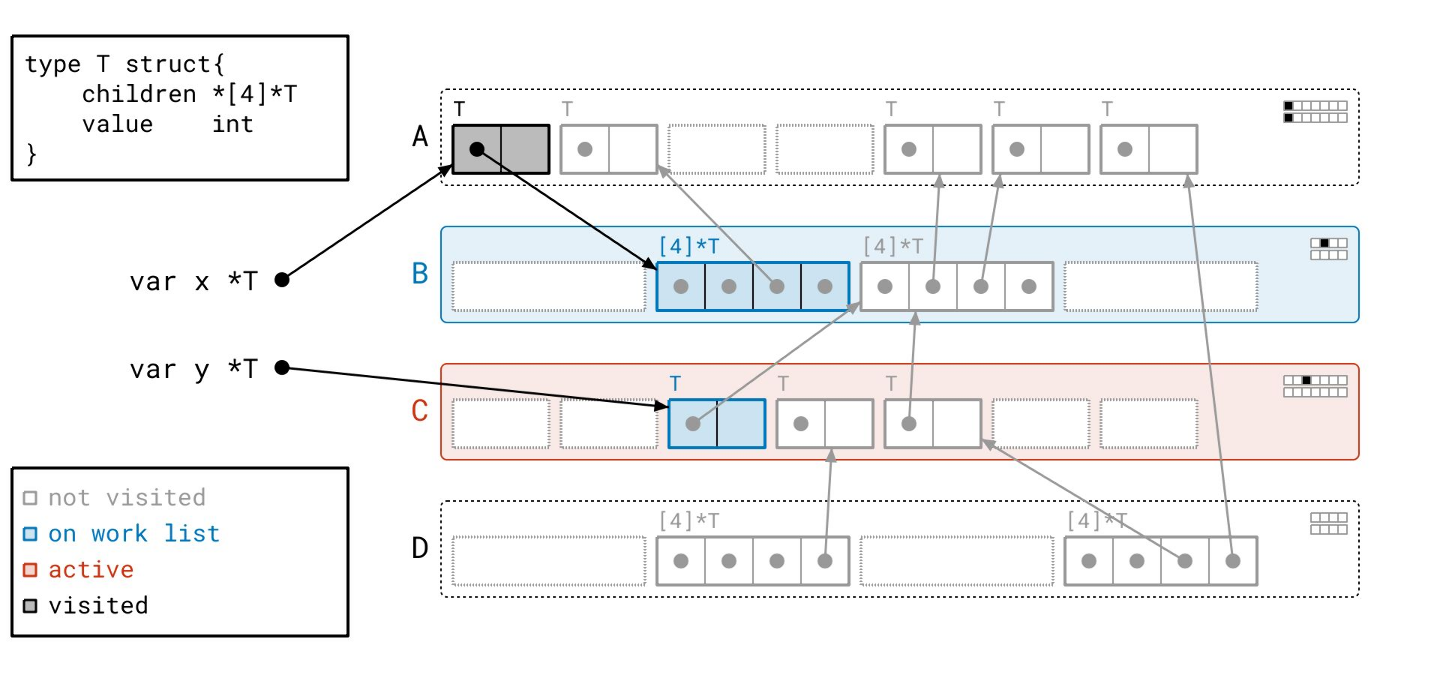
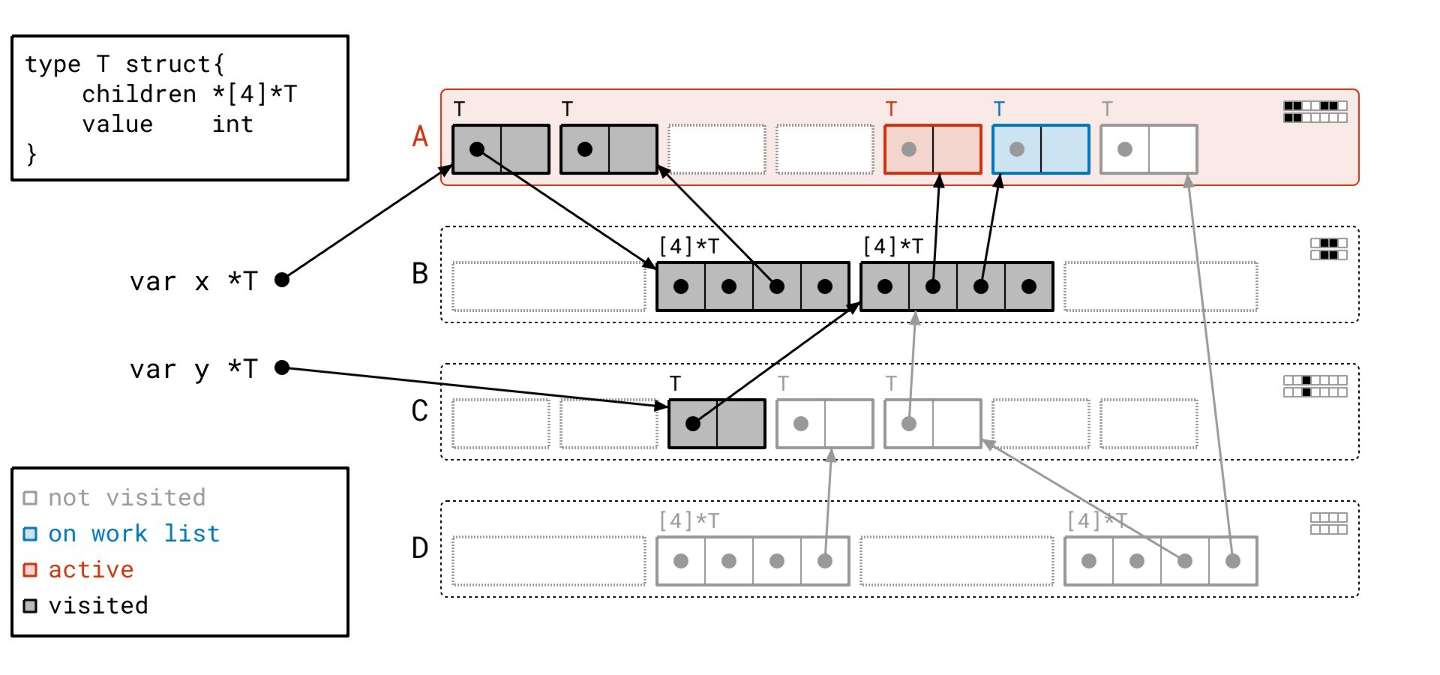
我们处理完根了,所以我们转向工作列表,并从工作列表中取出页 A。
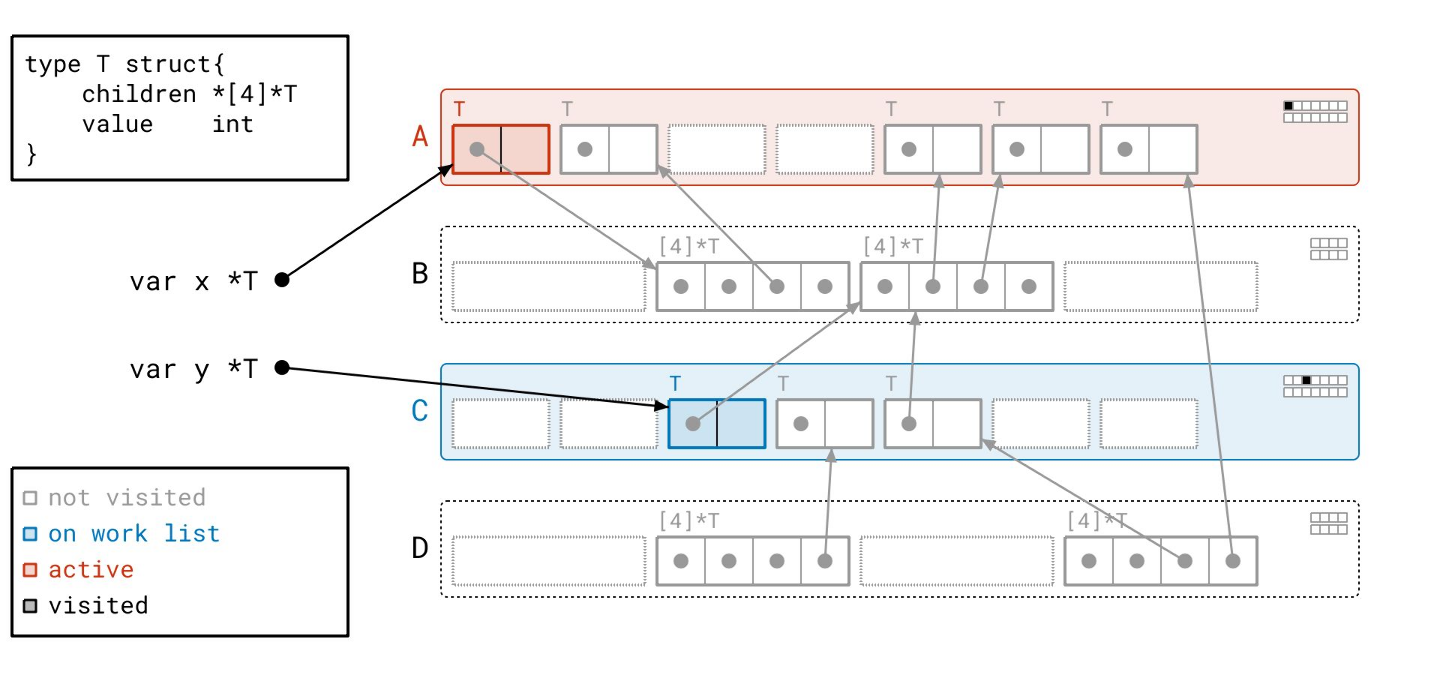
通过“已见”和“已扫描”位,我们可以知道页 A 上有一个对象需要扫描。
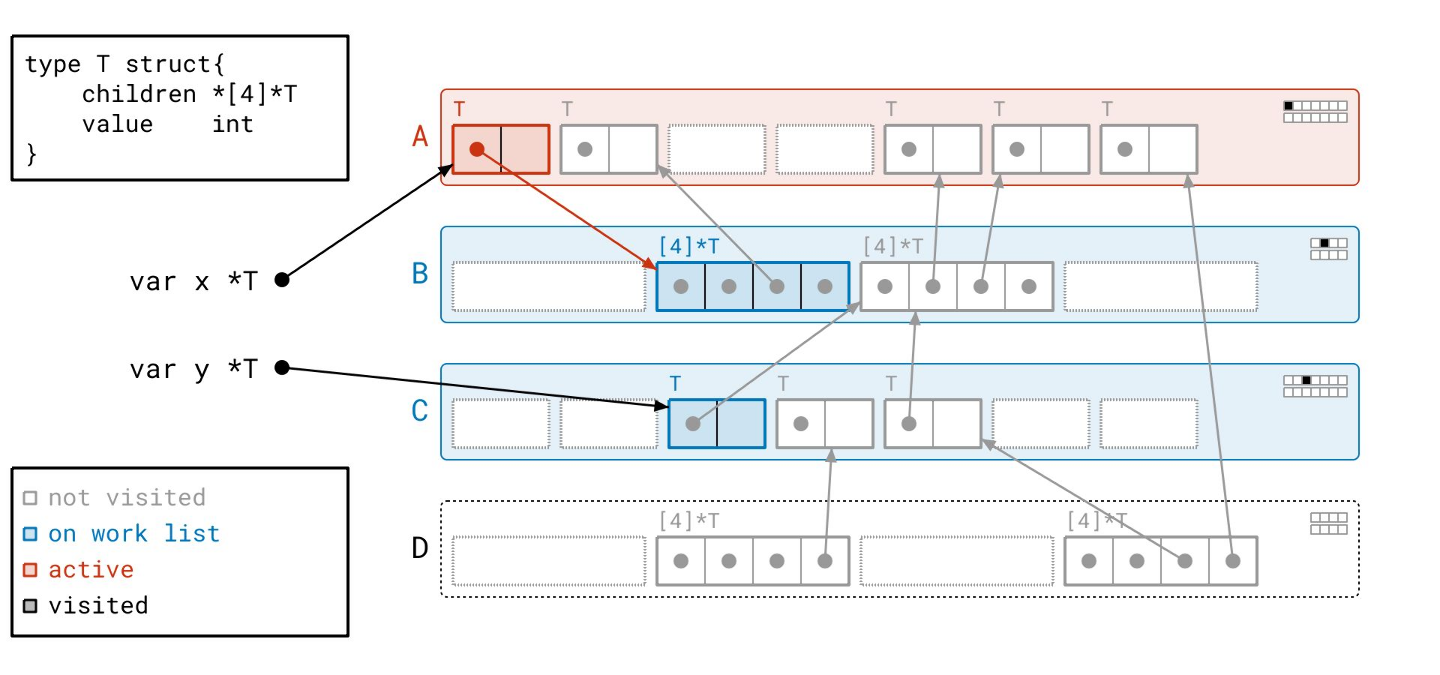
我们扫描那个对象,跟随它的指针。结果,我们将页 B 添加到工作列表,因为页 A 中的第一个对象指向了页 B 中的一个对象。
我们处理完页 A 了。接下来我们从工作列表中取出页 C。
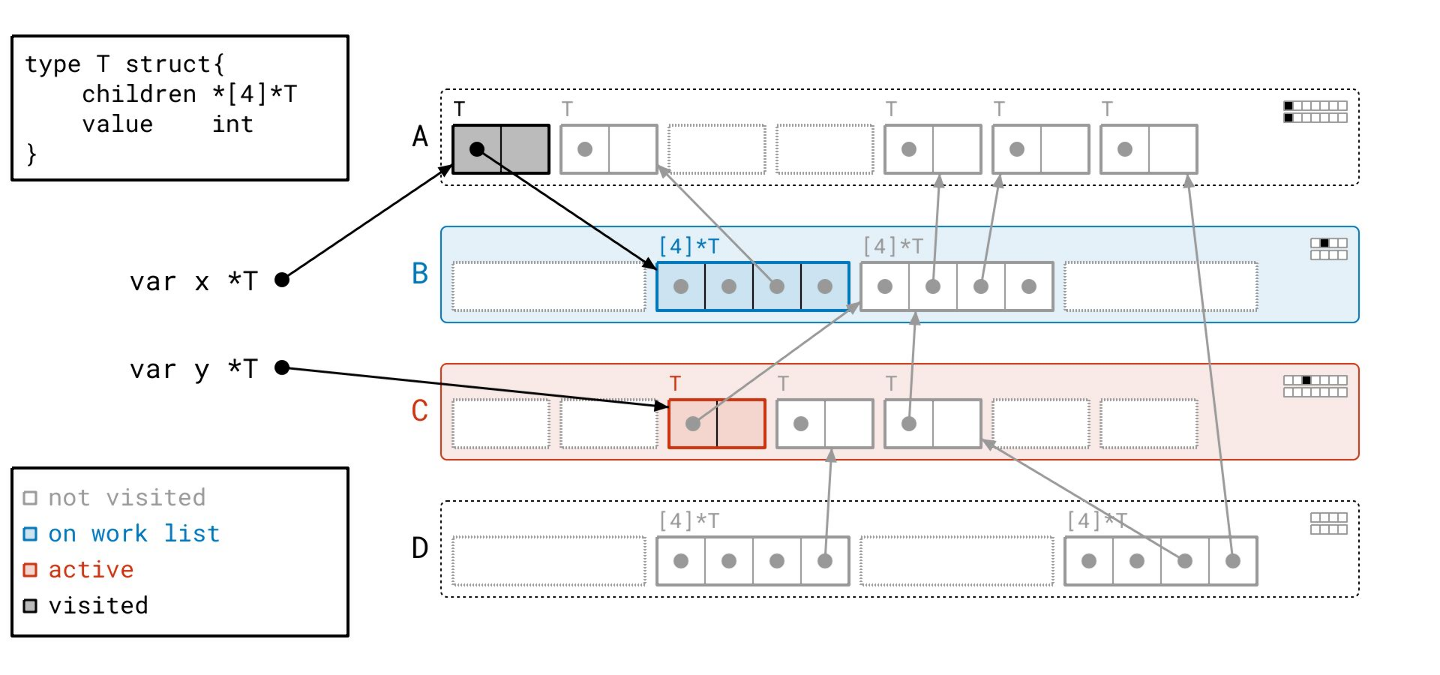
与页 A 类似,页 C 上有一个单独的对象需要扫描。
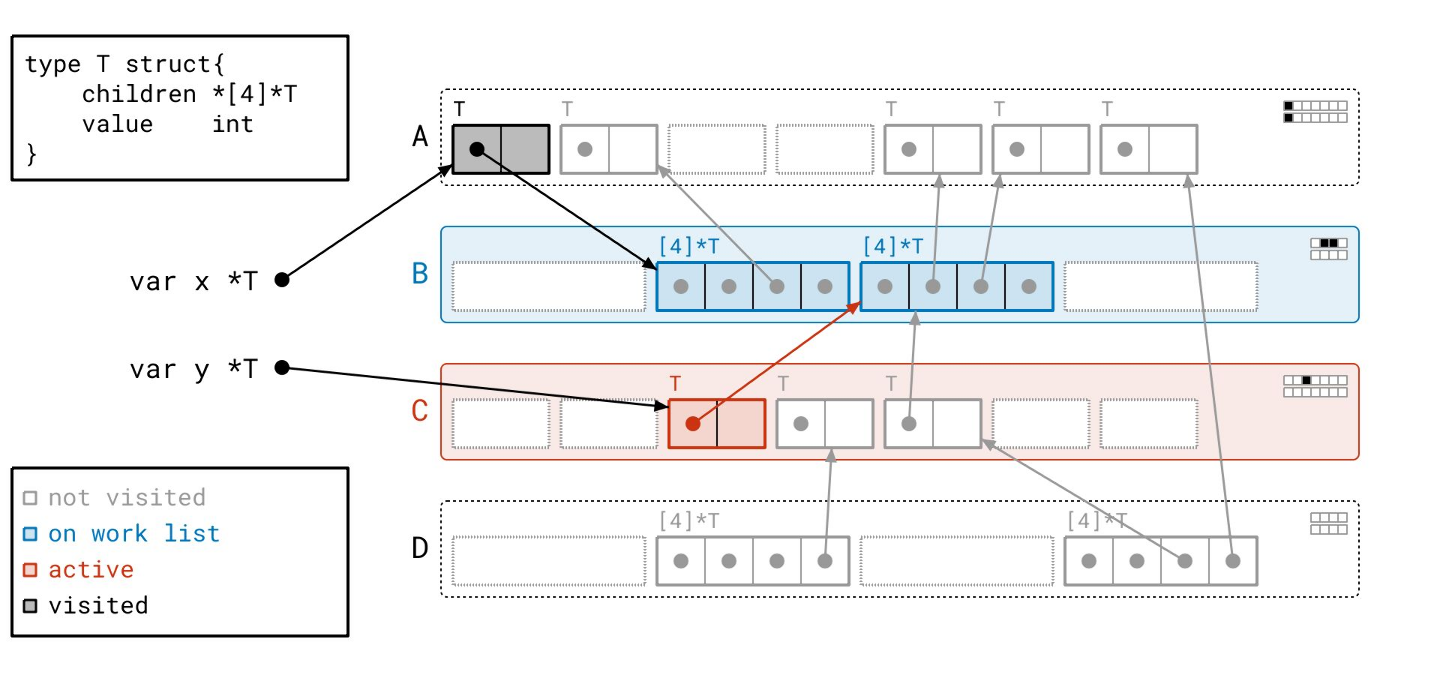
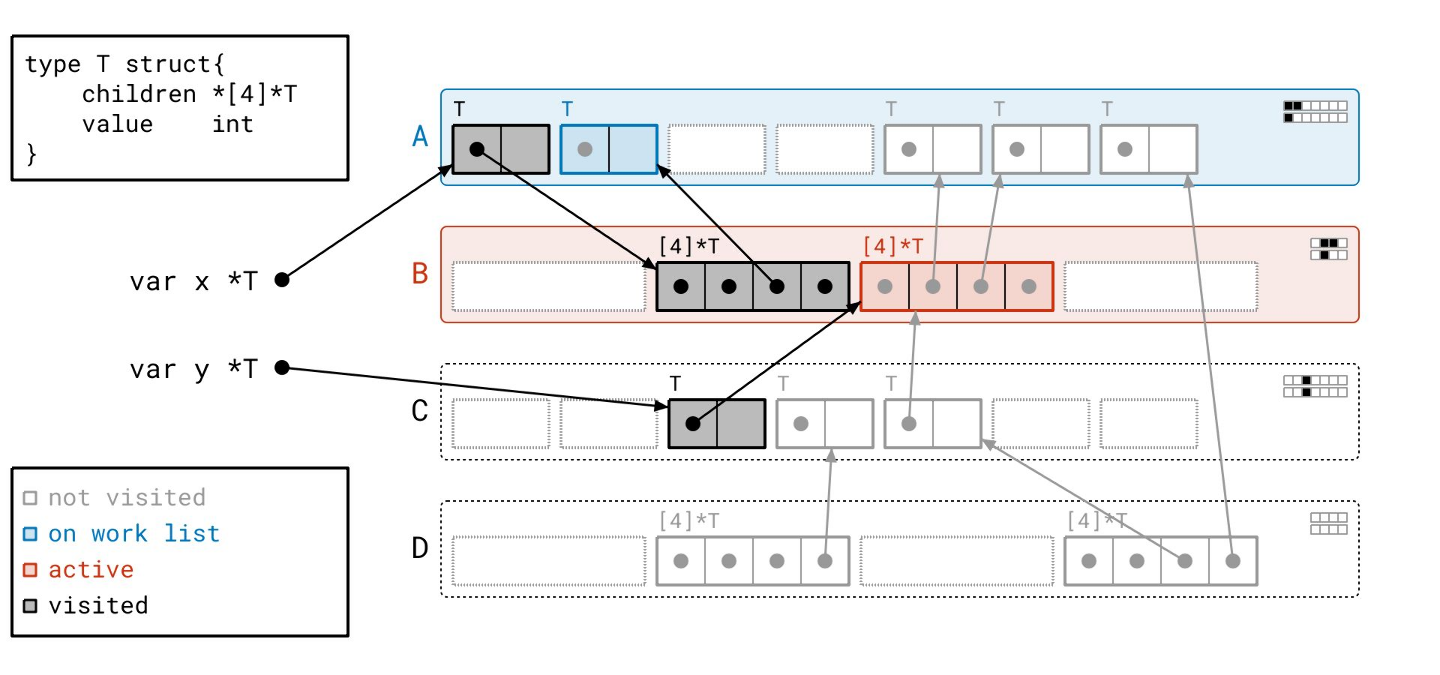
我们在页 B 中找到了一个指向另一个对象的指针。页 B 已经在工作列表上了,所以我们不需要向工作列表添加任何东西。我们只需为目标对象设置“已见”位。
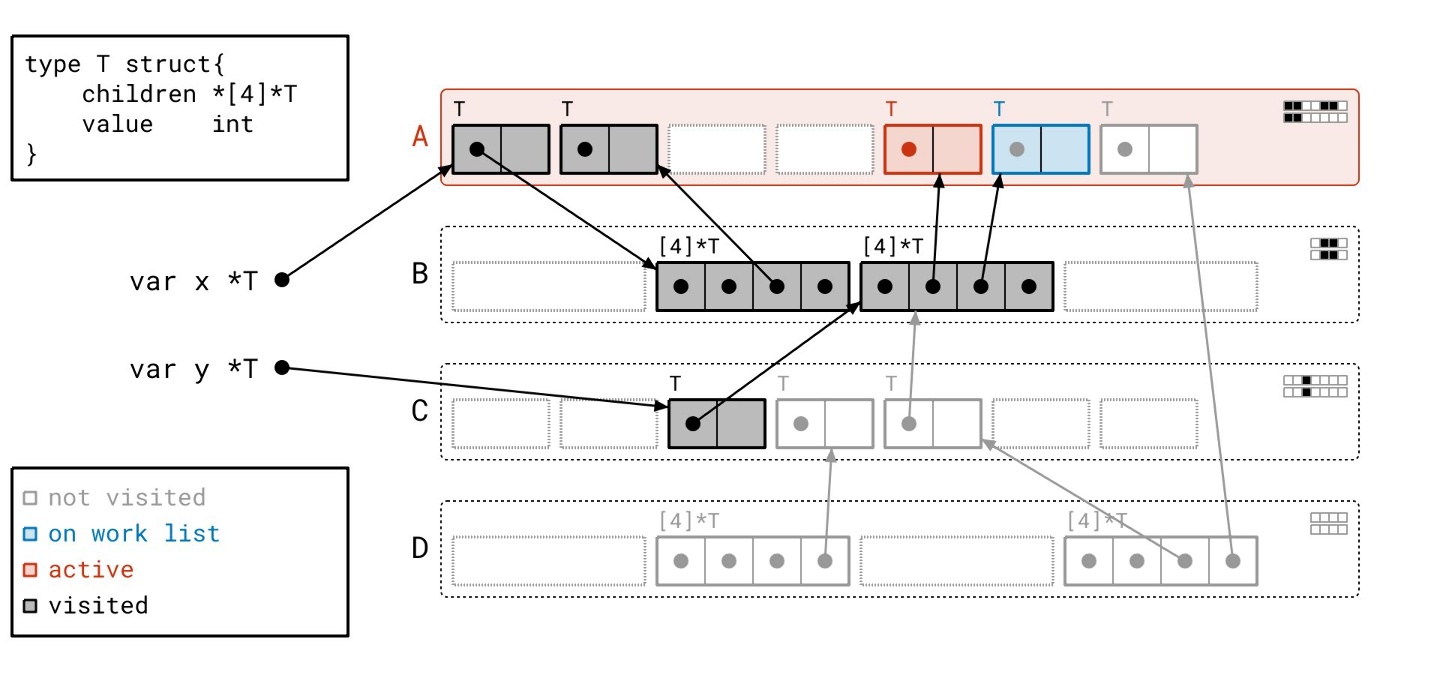
现在轮到页 B 了。我们在页 B 上累积了两个待扫描的对象,我们可以按内存顺序,连续处理这两个对象!
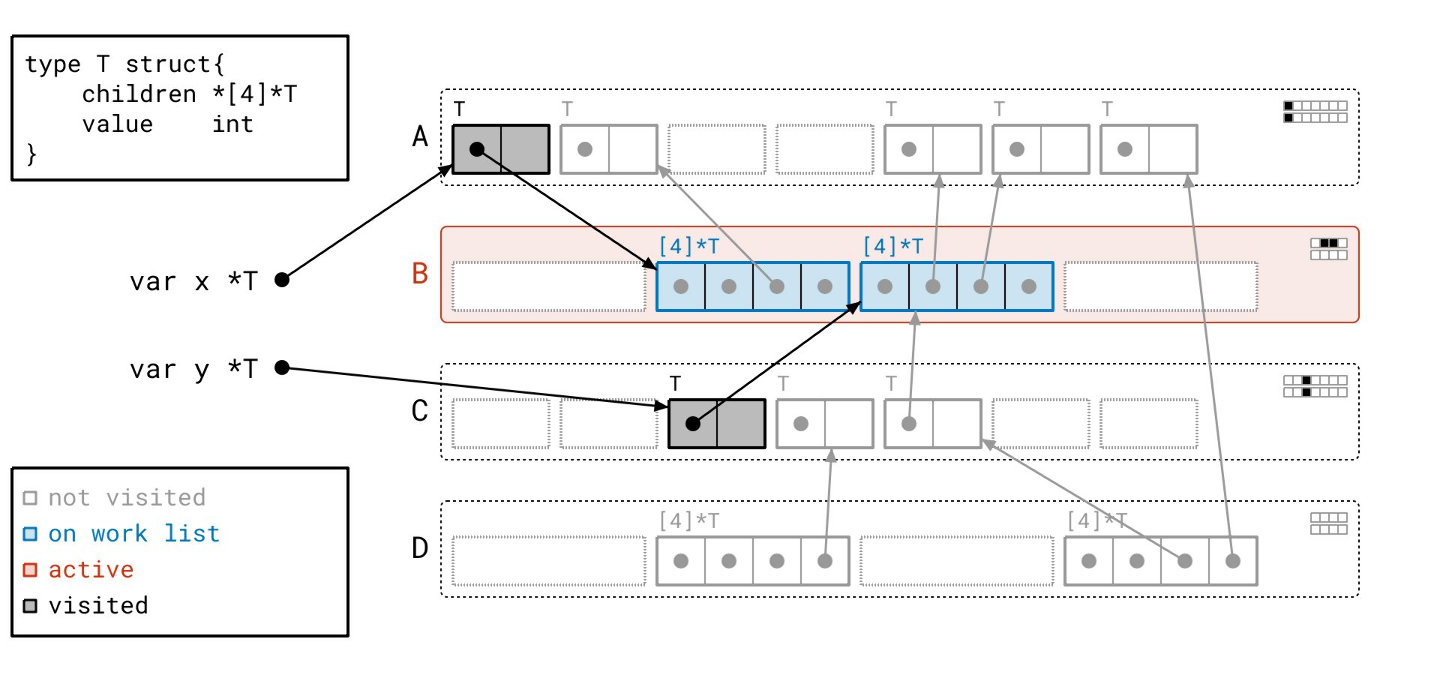
我们遍历第一个对象的指针…
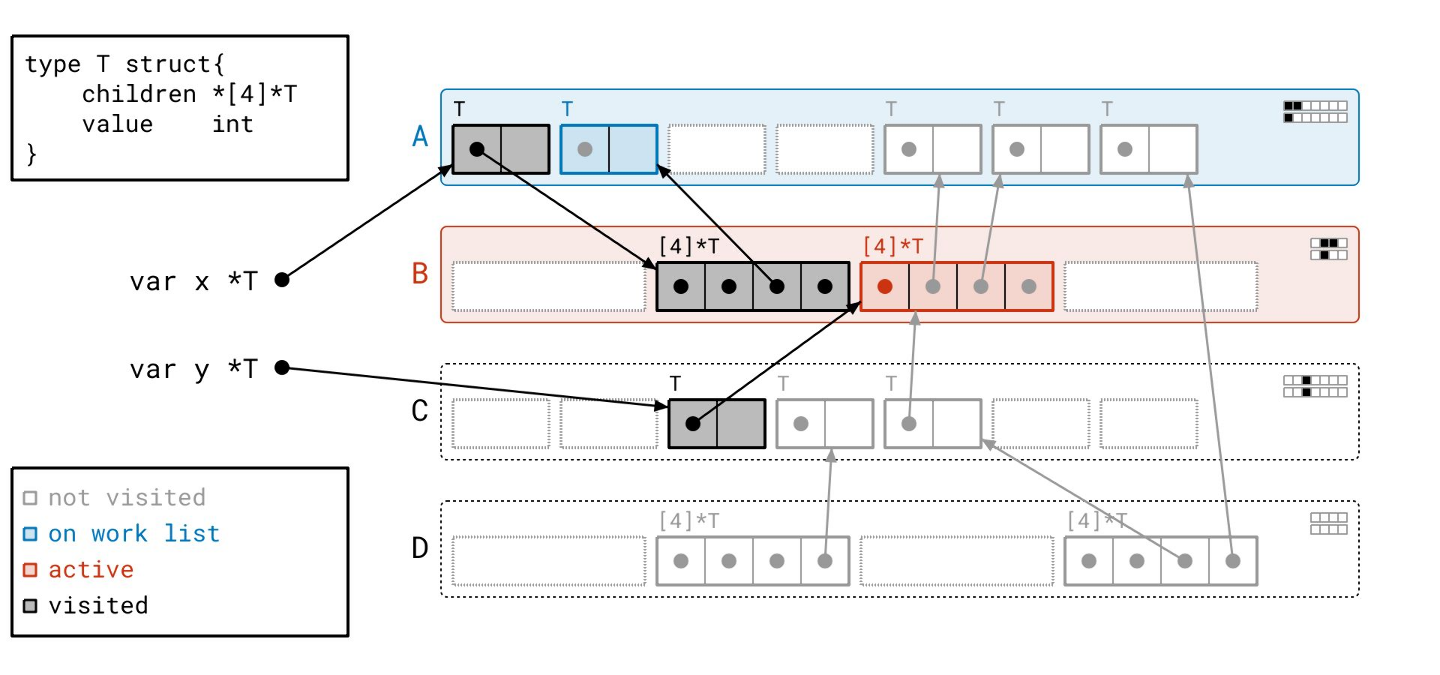
我们在页 A 中找到了一个指向一个对象的指针。页 A 之前在工作列表上,但此时不在了,所以我们把它放回工作列表。与原始的标记-清除算法不同,在原始算法中,任何给定的对象在整个标记阶段最多只会被添加到工作列表一次;而在“绿茶”中,一个给定的页在标记阶段可能会多次出现在工作列表上。
我们在扫描完第一个之后,立即扫描页中的第二个“已见”对象。
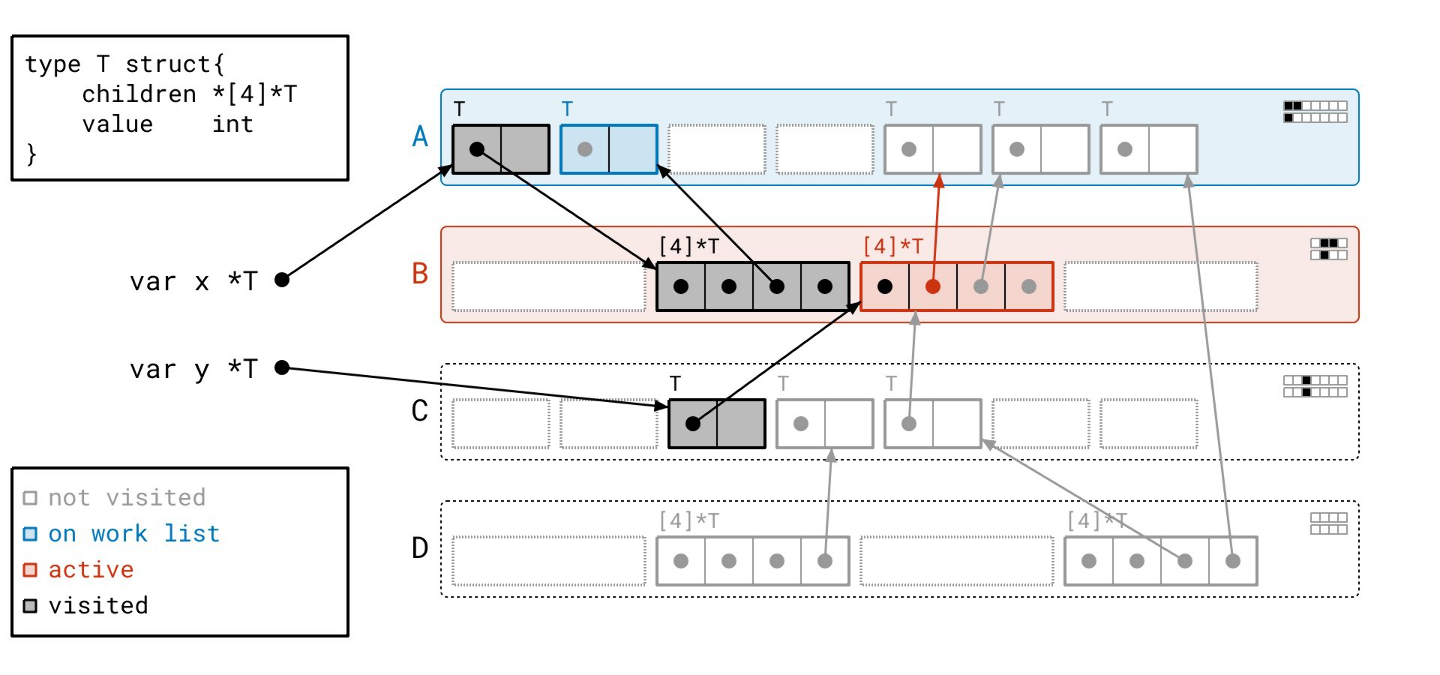
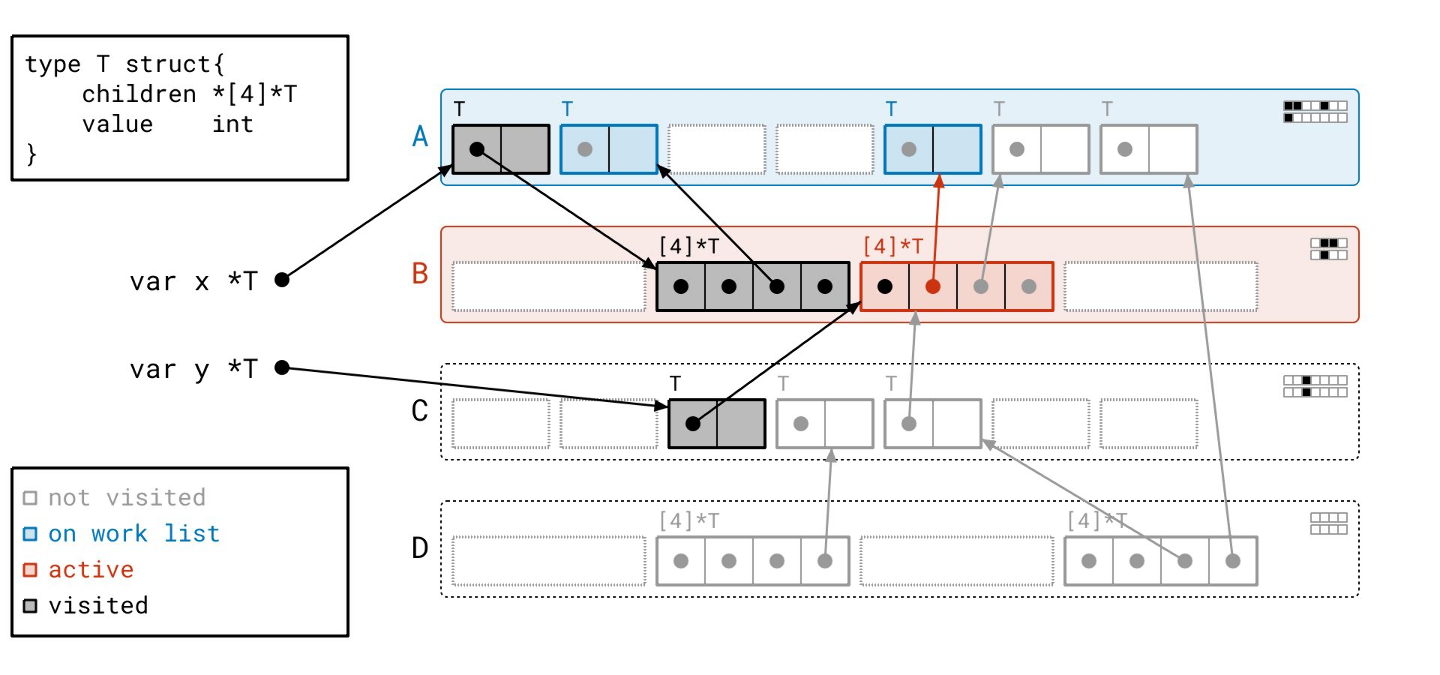
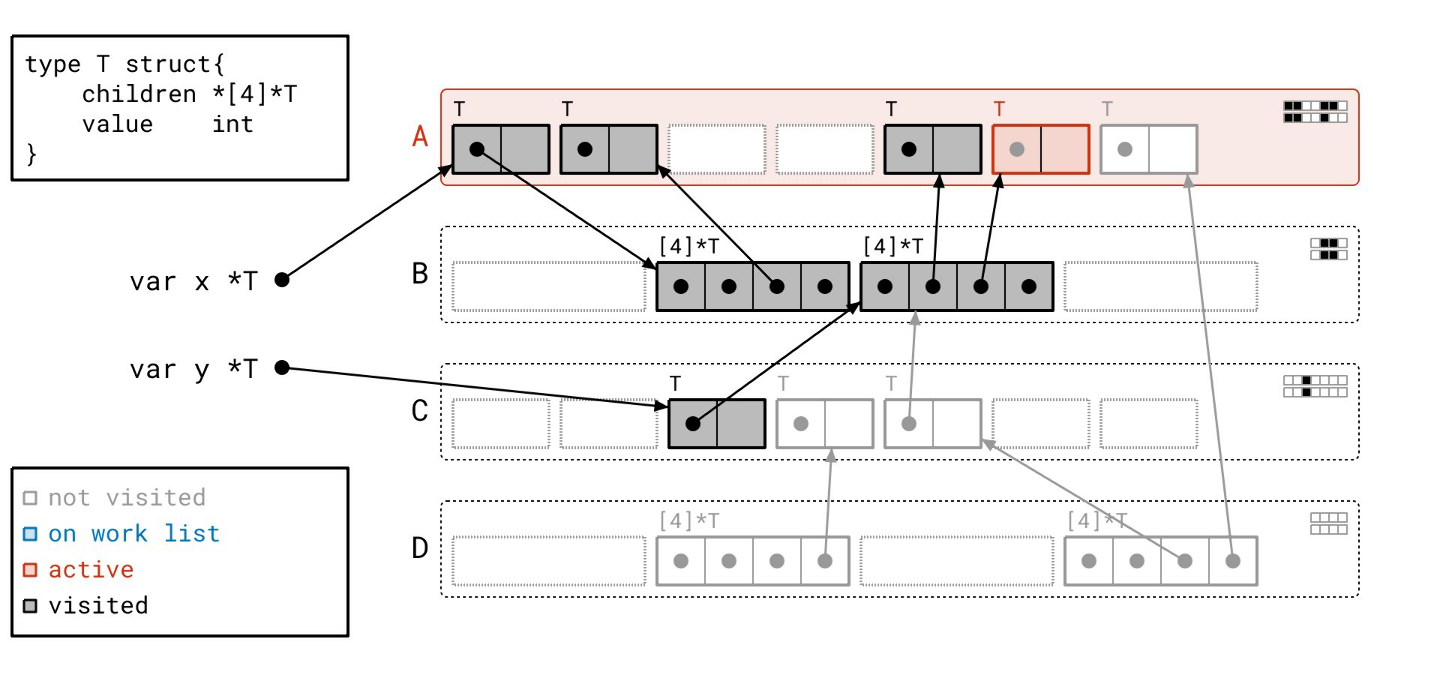
我们在页 A 中又找到了几个对象…
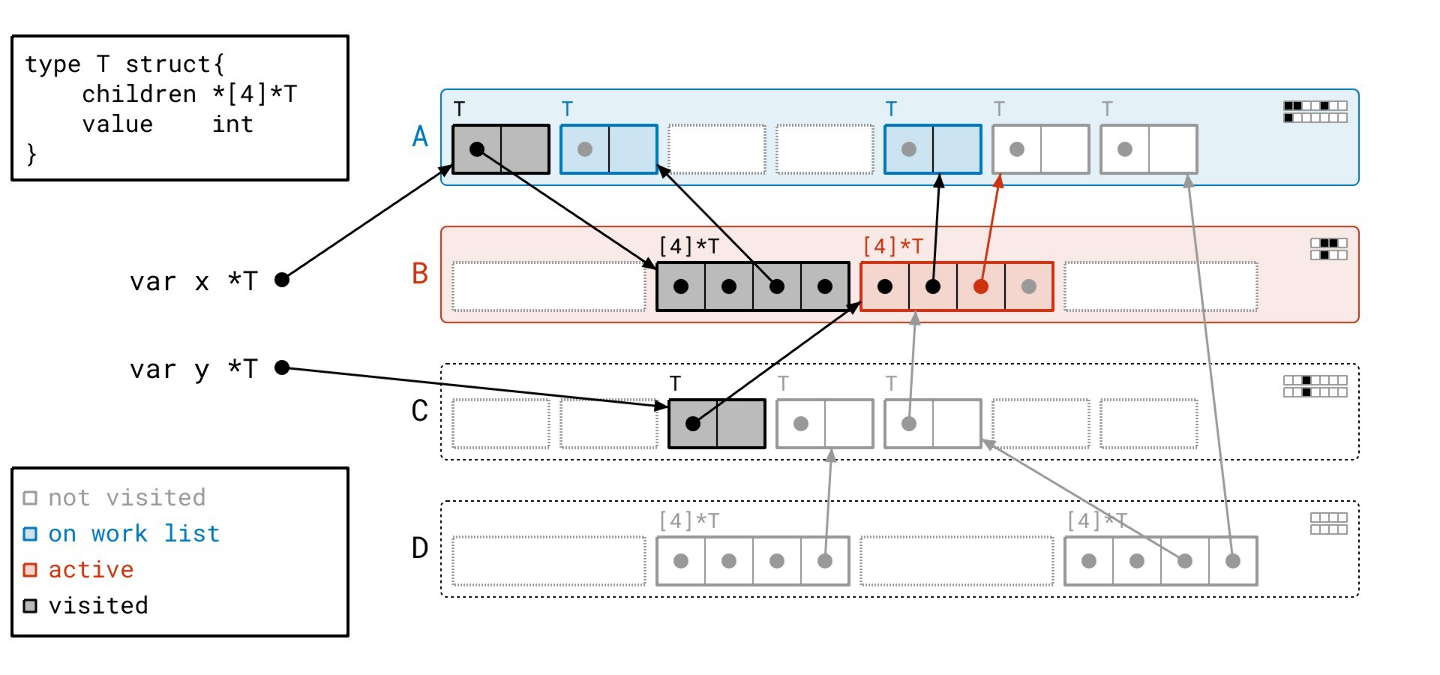
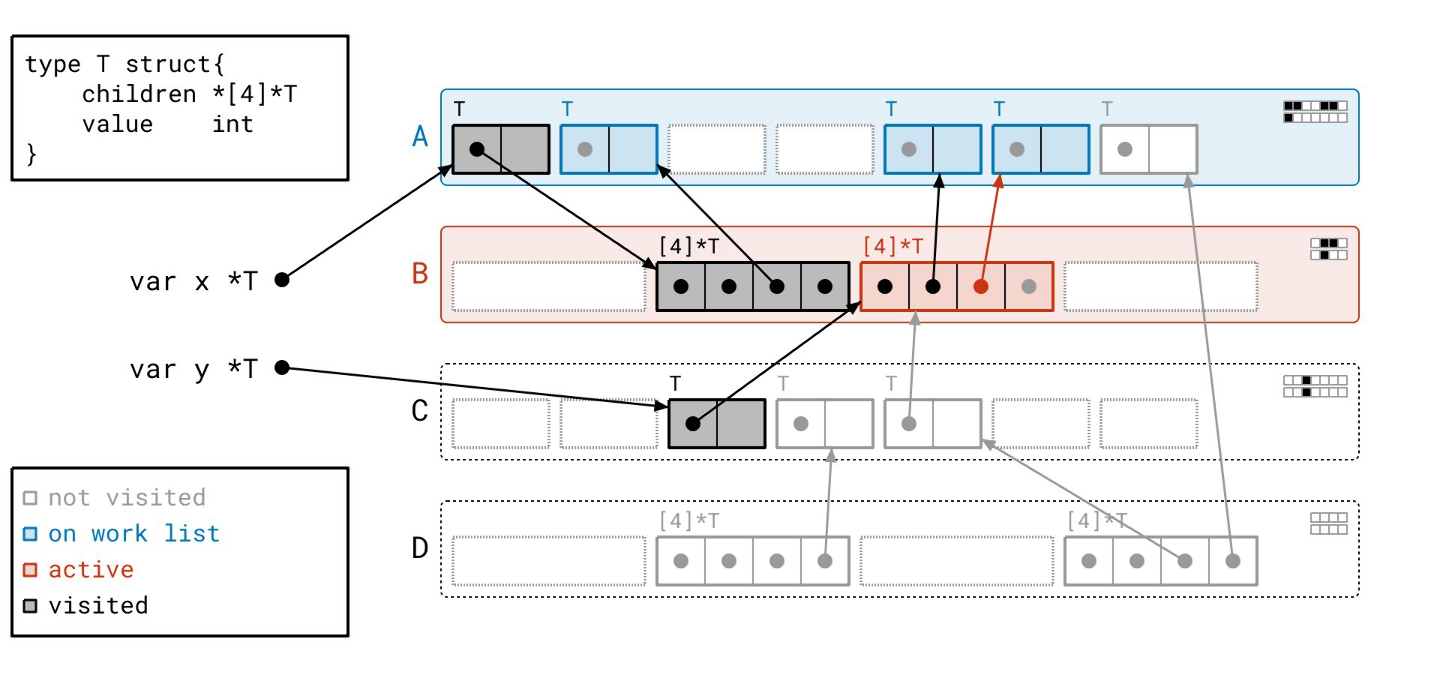
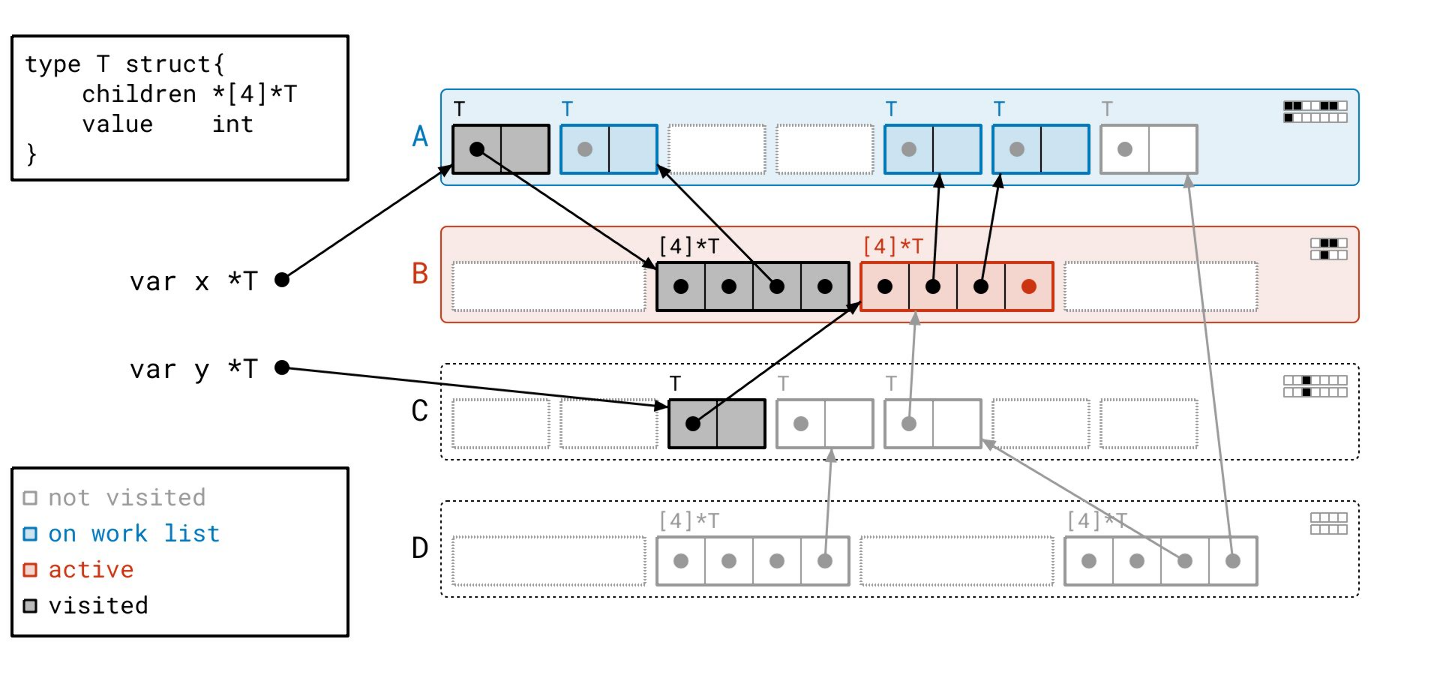
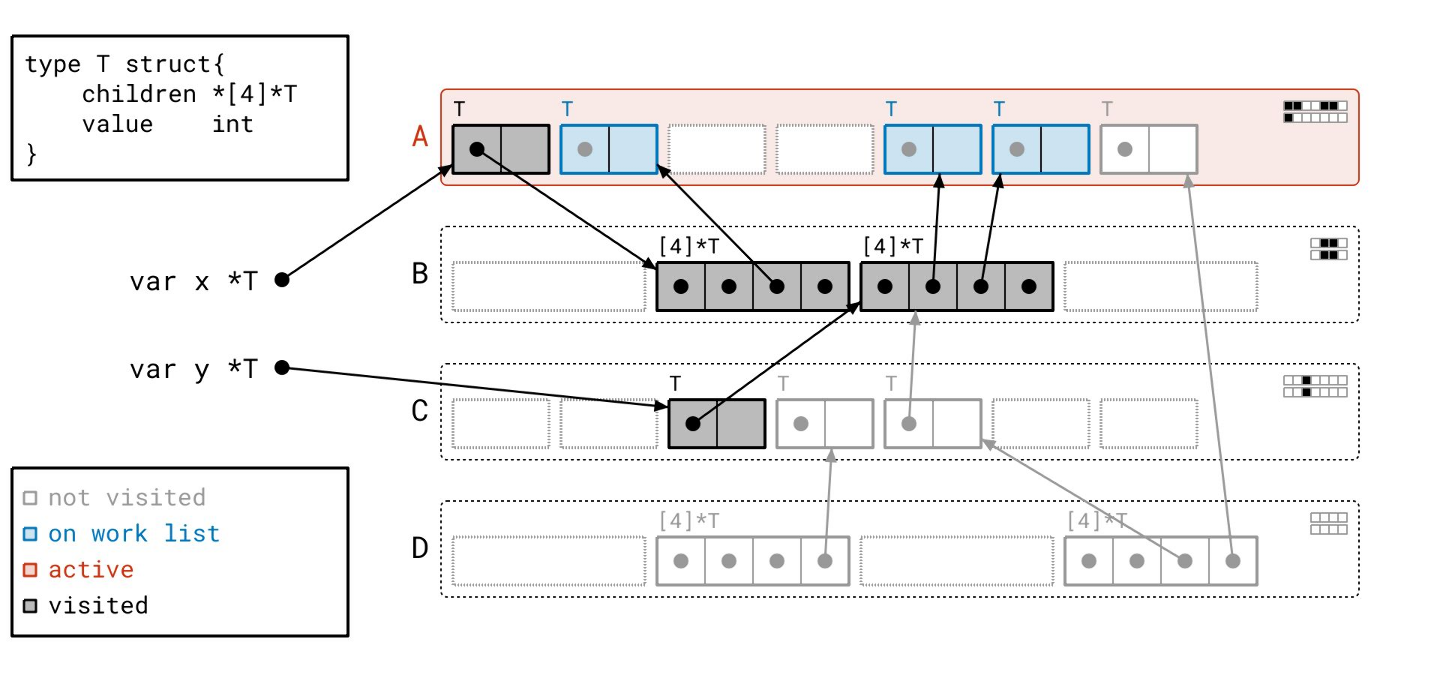
我们扫描完页 B 了,所以我们从工作列表中取出页 A。
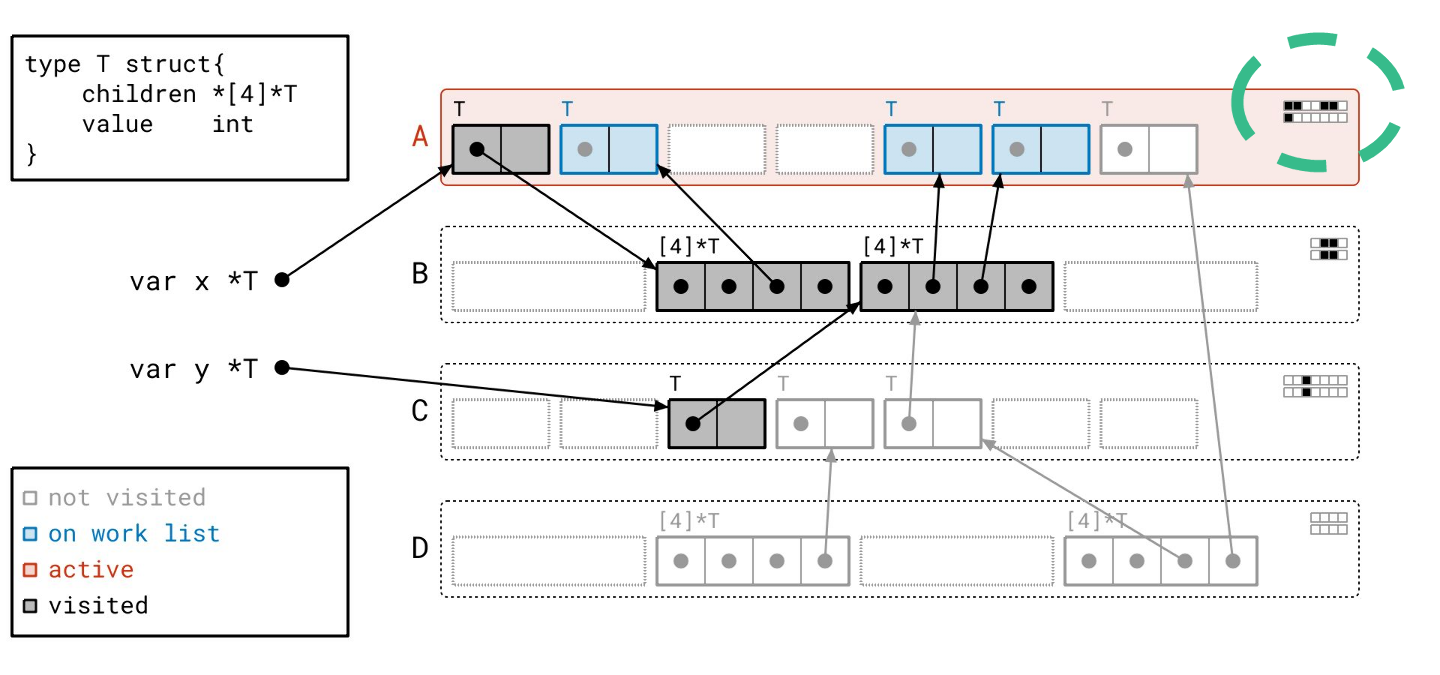
这次我们只需要扫描三个对象,而不是四个,因为我们已经扫描过第一个对象了。我们通过查看“已见”和“已扫描”位之间的差异,来知道要扫描哪些对象。
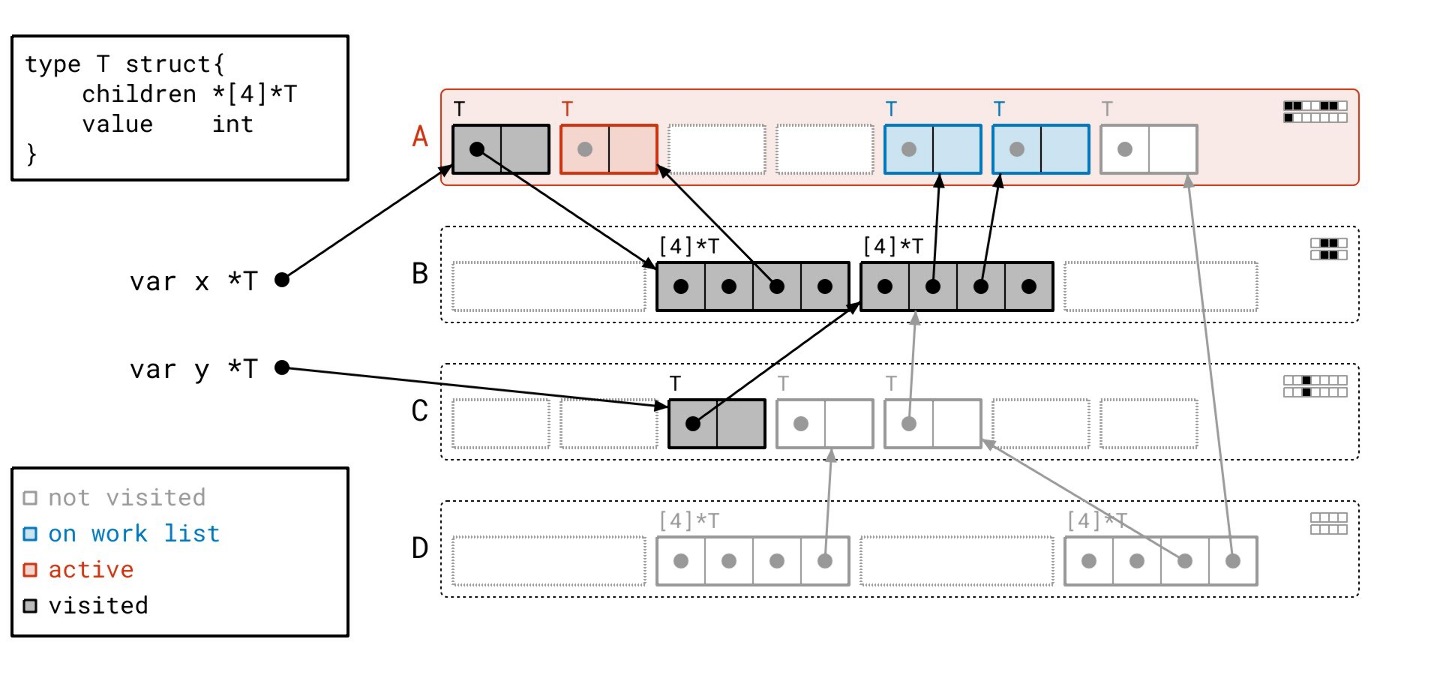
我们将按顺序扫描这些对象。
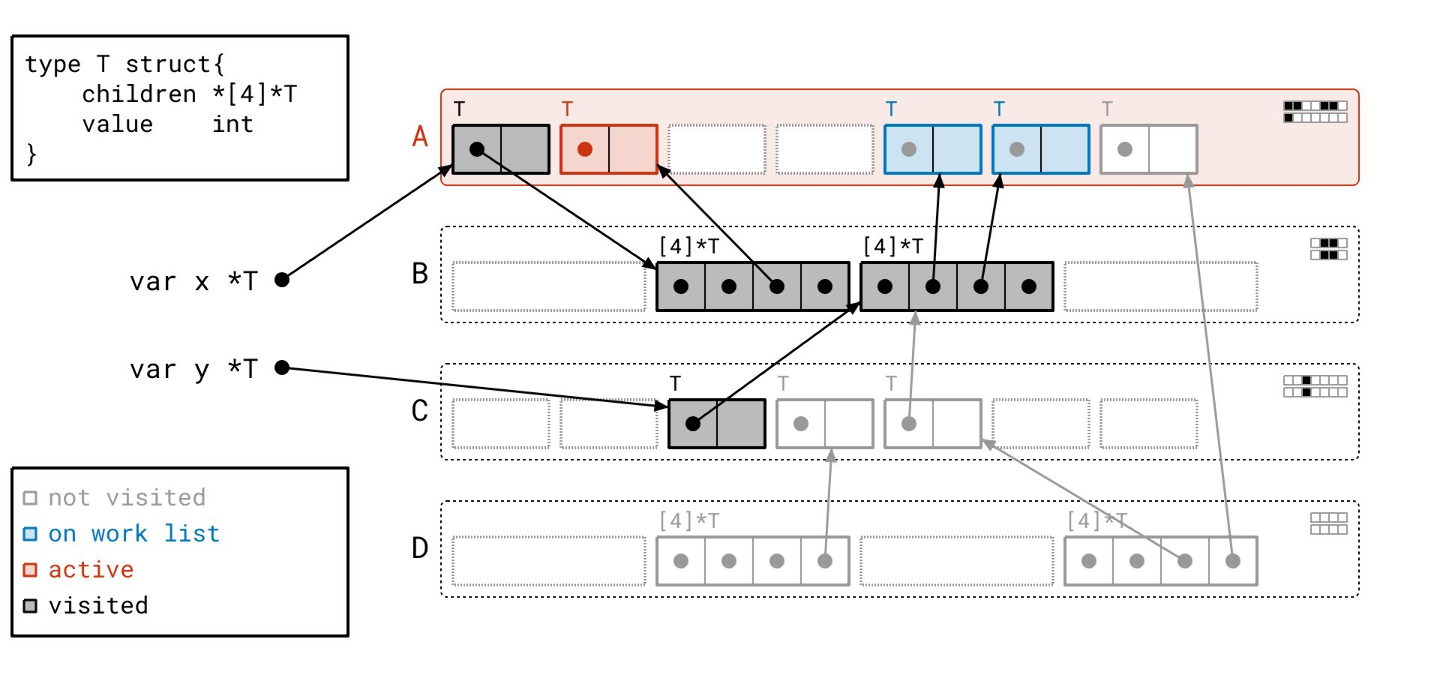
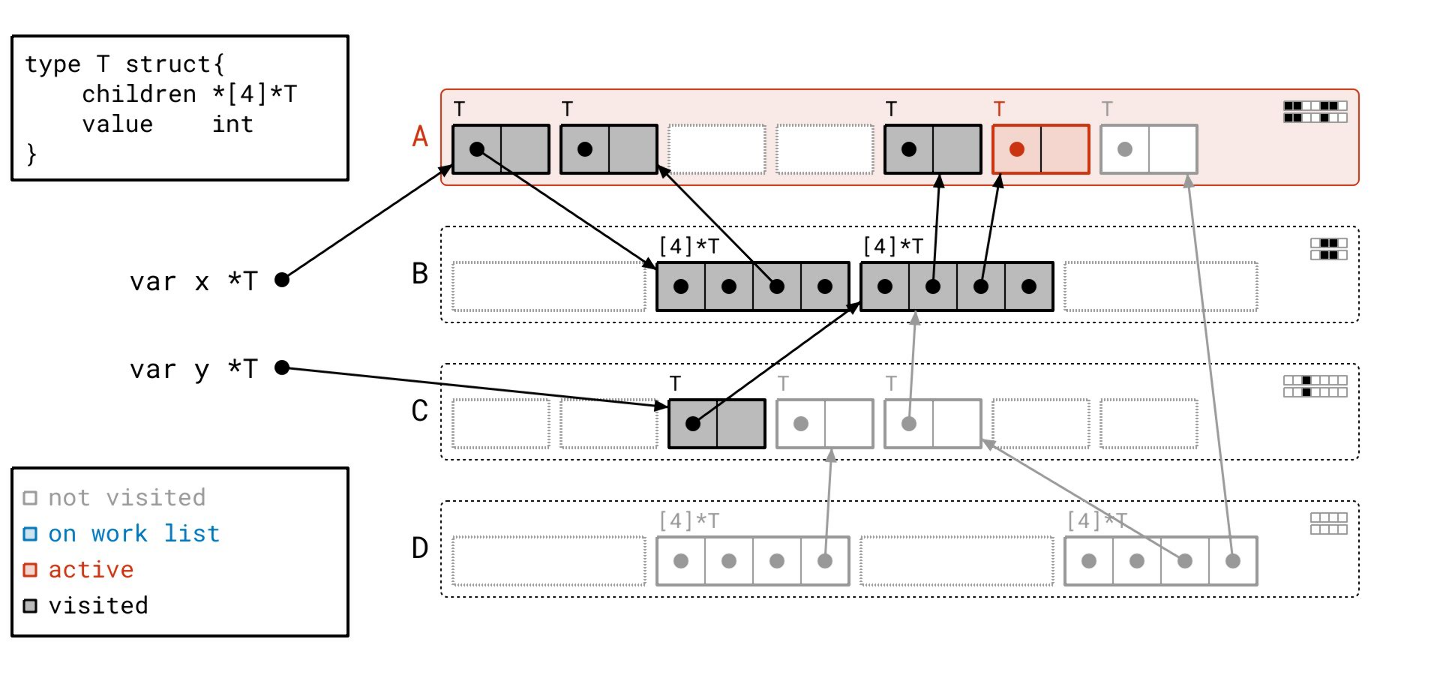
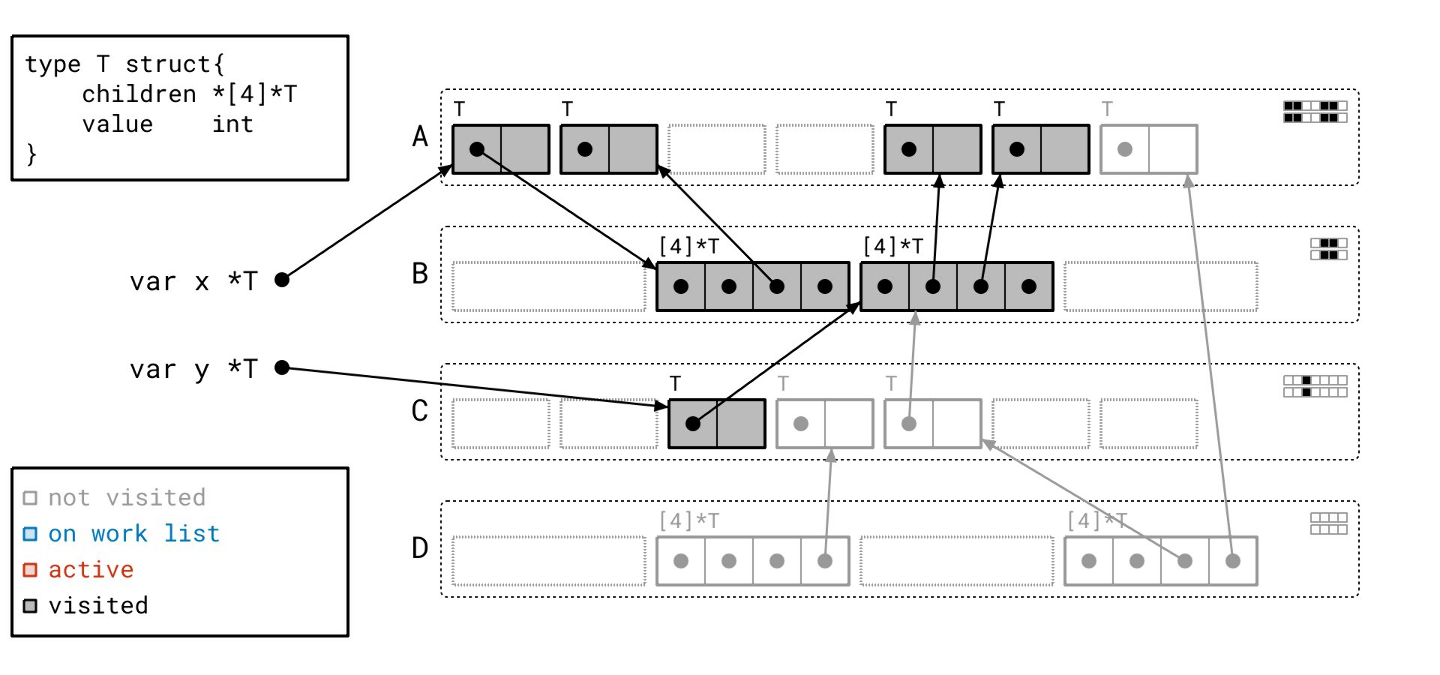
我们完成了!工作列表上没有更多的页了,我们也没有正在处理的东西。请注意,现在元数据都很好地对齐了,因为所有可达的对象都既被“已见”又被“已扫描”。
你可能在我们的遍历过程中也注意到了,工作列表的顺序与图遍历有点不同。图遍历是“后进先出”或类似栈的顺序,而这里我们对工作列表上的页使用的是“先进先出”或类似队列的顺序。
这是有意为之的。当页在队列中等待时,我们让“已见”对象在每个页上累积,这样我们就可以一次性处理尽可能多的对象。这就是我们能一次性处理页 A 上那么多对象的原因。有时候,懒惰是一种美德。
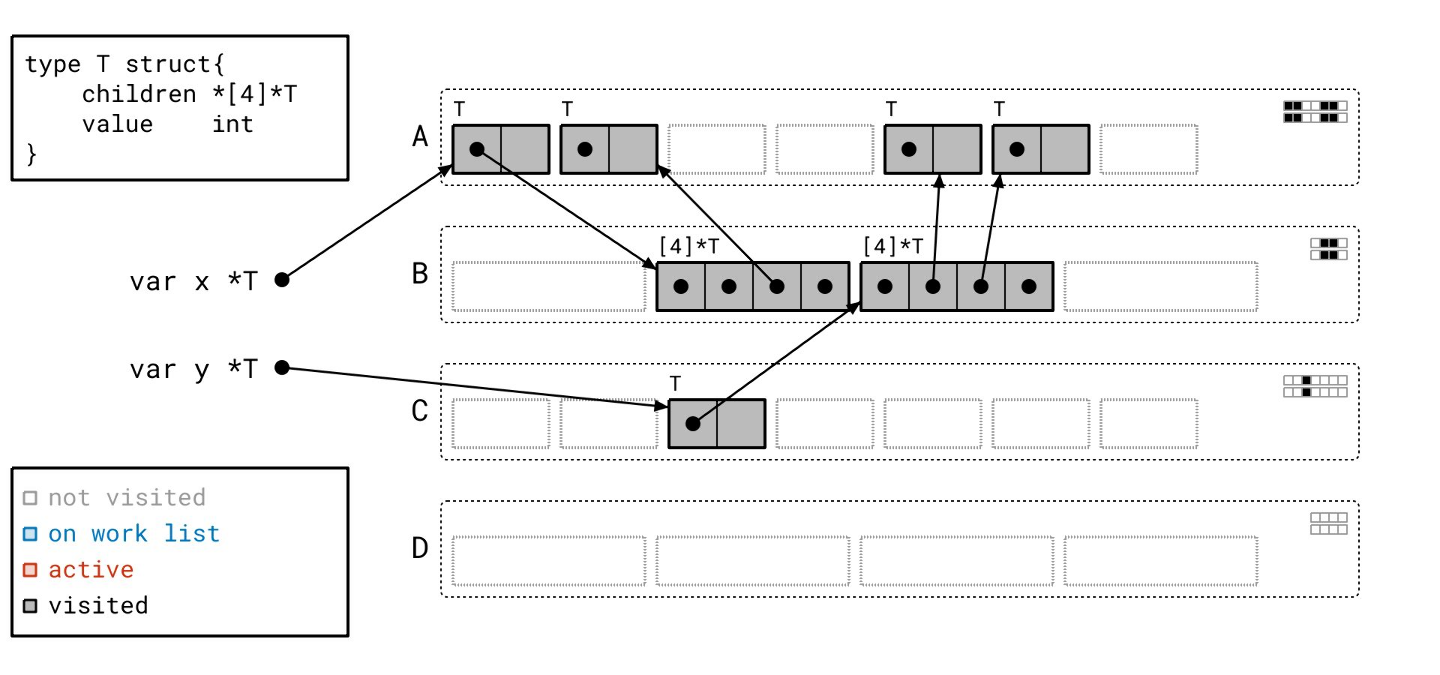
最后,我们可以像以前一样,清除掉未访问的对象。
驶上高速公路
让我们回到我们开车的比喻。我们终于要上高速公路了吗?
让我们回顾一下之前的图泛洪图片。
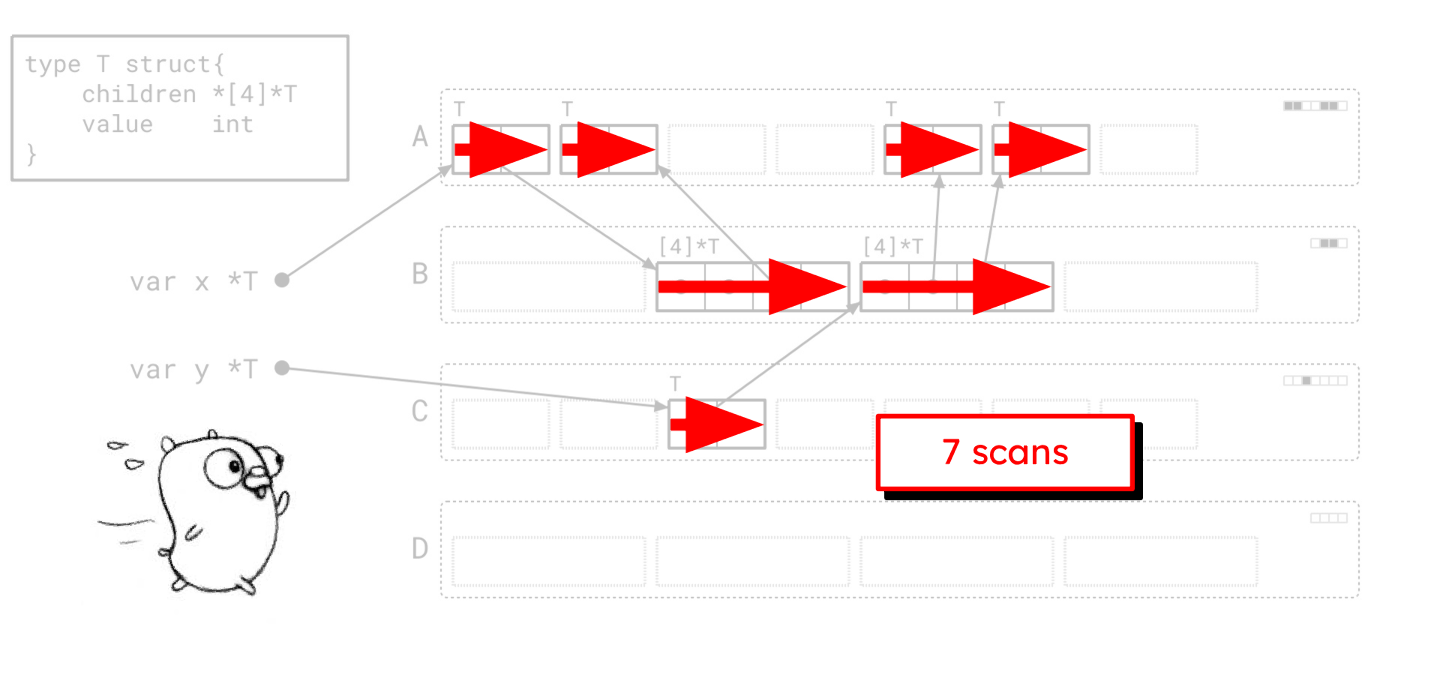
原始图遍历在堆中穿行的路径需要 7 次独立的扫描。
我们到处跳跃,在不同的地方做着零碎的工作。“绿茶”所走的路径看起来非常不同。
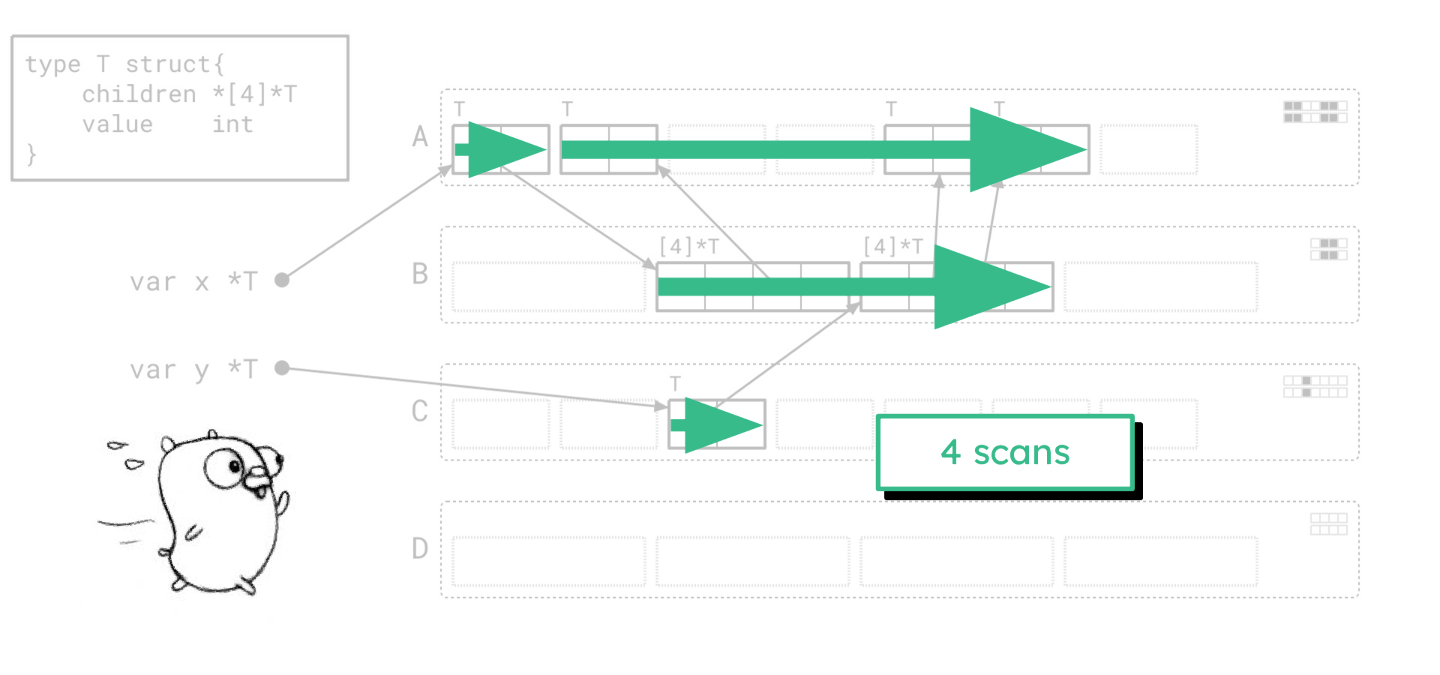
“绿茶”所走的路径仅需要 4 次扫描。
相比之下,绿茶在 A 和 B 页面上从左到右的移动次数较少,但每次移动时间更长。 这些箭头越长越好,箭头堆积越多,这种效果就越强。这就是绿茶的魅力所在。
这也是我们驰骋高速公路的机会。
这一切都使得它与微架构更加契合。现在,我们可以更精确地扫描彼此靠近的对象,从而更有可能利用缓存并避免使用主内存。同样,每页的元数据也更有可能被缓存。跟踪页面而非对象意味着工作列表更小,而工作列表压力的降低意味着争用更少,CPU 停顿也更少。
说到高速公路,我们可以把我们比喻意义上的引擎开到以前从未开过的档位,因为现在我们可以使用向量硬件了!
向量加速
如果你对向量硬件只有粗浅的了解,可能会不明白我们在这里如何使用它。但除了常见的算术和三角运算之外,最新的向量硬件还支持两项对绿茶算法非常有用的功能:超宽寄存器和复杂的位运算。
大多数现代 x86 CPU 都支持 AVX-512 指令集,它拥有 512 位宽的向量寄存器。如此宽的寄存器足以在 CPU 上仅使用两个寄存器来存储整个页面的所有元数据,从而使 Green Tea 能够仅用几条直线指令就完成整个页面的扫描。向量硬件长期以来一直支持对整个向量寄存器进行基本的位运算,但从 AMD Zen 4 和 Intel Ice Lake 开始,它还支持一种新的位向量“瑞士军刀”指令,使得 Green Tea 扫描过程中的关键步骤能够在几个 CPU 周期内完成。这些改进共同作用,使我们能够大幅提升 Green Tea 的扫描循环速度。
对于之前的图泛洪来说,这根本不可能,因为我们需要在各种大小的对象之间来回扫描。有时只需要两条元数据,有时却需要一万条。向量硬件根本无法满足这种可预测性和规律性要求。
如果你想深入了解一些细节,请继续阅读!否则,请随时跳到下面的【评估】小节。
AVX-512 扫描内核
要了解 AVX-512 GC 扫描是什么样子,请看下面的图。
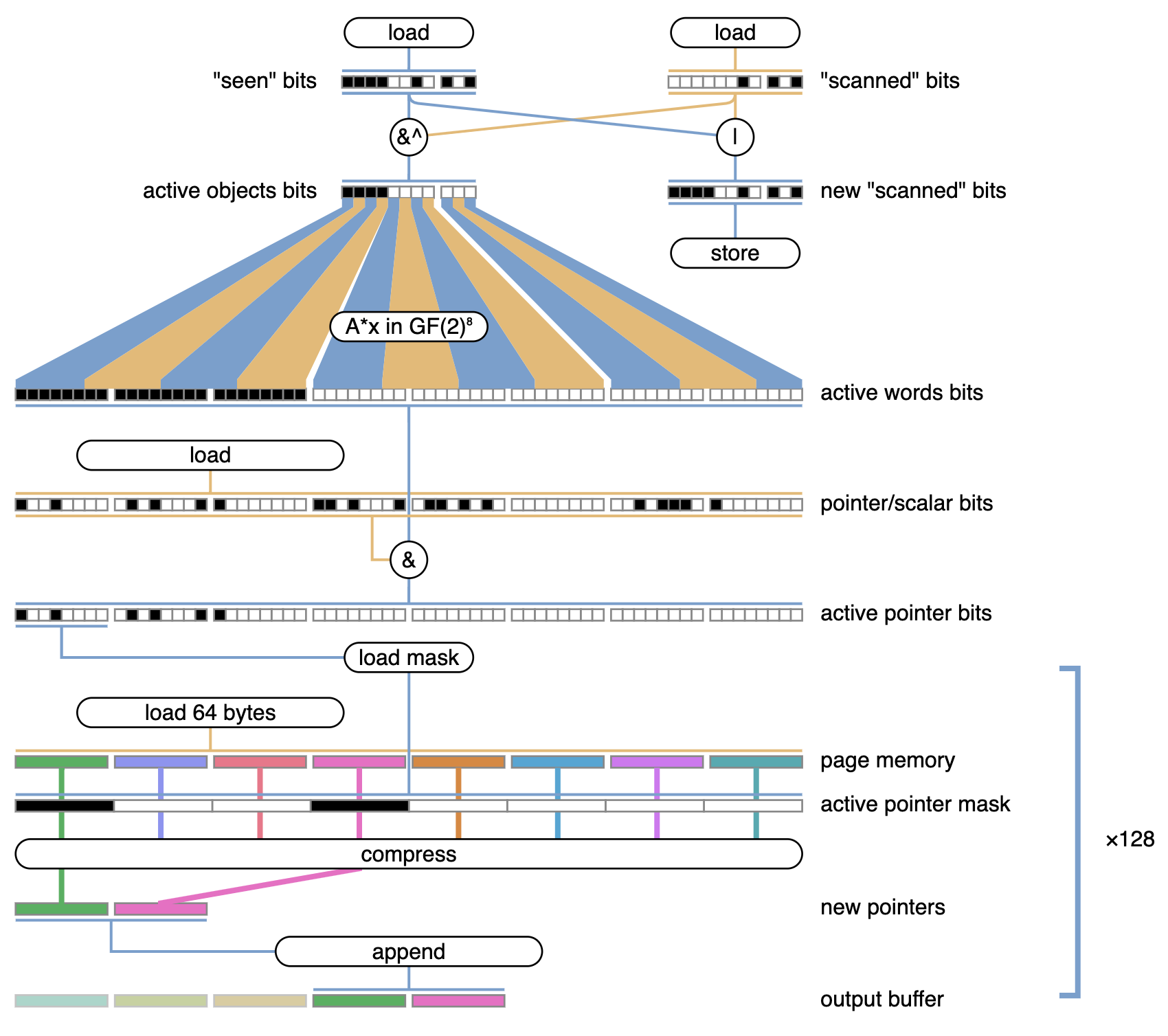
用于扫描的 AVX-512 矢量内核 这里面涉及的内容很多,我们可能光是解释它的运作原理就能写一整篇博客文章。现在,我们先从宏观层面来概括一下:
- 首先,我们获取页面的“已查看”和“已扫描”位。请记住,页面中的每个对象对应一位,并且页面中的所有对象大小相同。
- 接下来,我们比较这两个位集。它们的并集成为新的“扫描”位,而它们的差集则是“活动对象”位图,它告诉我们在本次页面扫描过程中(与之前的扫描相比)需要扫描哪些对象。
- 我们计算两个位图的差值并进行“扩展”,这样就不是每个对象占用一位,而是页面中的每个字(8 字节)占用一位。我们称之为“活动字”位图。例如,如果页面存储 6 个字(48 字节)的对象,则活动对象位图中的每位将被复制到活动字位图中的 6 位。如下所示:
0 0 1 1 ... → 000000 000000 111111 111111 ...
-
接下来,我们获取页面的指针/标量位图。同样,这里的每一位都对应页面的一个字(8 字节),并告诉我们该字是否存储指针。这些数据由内存分配器管理。
-
现在,我们取指针/标量位图和活动字位图的交集。结果就是“活动指针位图”:该位图告诉我们尚未扫描的任何活动对象中包含的整个页面中每个指针的位置。
-
最后,我们可以遍历页面内存并收集所有指针。逻辑上,我们遍历活动指针位图中的每个置位,加载该字处的指针值,并将其写回缓冲区。该缓冲区稍后将用于标记已访问的对象并将页面添加到工作列表中。利用向量指令,我们只需几条指令即可一次处理 64 字节。
让这一切变快的部分原因是 VGF2P8AFFINEQB 指令,它是“Galios Field新指令” x86 扩展的一部分,也是我们上面提到的位操作“瑞士军刀”。它是真正的明星,因为它让我们能够非常高效地完成扫描内核中的第 (3) 步。它执行逐位的仿射变换,将向量中的每个字节本身视为一个 8 位的数学向量,并将其与一个 8×8 的比特矩阵相乘。这一切都是在Galios Field GF(2) 上完成的,这意味着乘法是AND,加法是XOR。这样做的好处是,我们可以为每个对象大小定义几个 8×8 的比特矩阵,来精确地执行我们需要的 1:n 比特扩展。
完整的汇编代码,请看这个文件。“扩展器”为每个大小类别使用不同的矩阵和不同的排列,所以它们在一个由代码生成器编写的单独文件中。除了扩展函数,代码量其实不多。大部分代码都被极大地简化了,因为我们可以在纯粹位于寄存器中的数据上执行大部分上述操作。而且,希望很快这段汇编代码将被 Go 代码所取代!
感谢 Austin Clements 设计了这个过程。它非常酷,而且非常快!
评估
那么,这就是Green Tea的工作原理。它到底有多大帮助呢?
效果可能相当显著。即使不考虑向量增强,我们的基准测试套件也显示垃圾回收的 CPU 成本降低了 10% 到 40%。例如,如果应用程序 10% 的时间都花在了垃圾回收器上,那么根据工作负载的具体情况,整体 CPU 消耗将降低 1% 到 4%。垃圾回收 CPU 时间降低 10% 大致是典型的改进幅度。
(有关这些细节,请参阅 GitHub issue。)
我们在谷歌内部推广了绿茶,并且大规模推广后也看到了类似的效果。
我们仍在推出向量增强功能,但基准测试和早期结果表明,这将额外带来 10%的 GC CPU 降低。
虽然大多数工作负载都能在一定程度上受益,但也有一些工作负载不会受益。
Green Tea 算法基于这样的假设:我们可以一次性在单页上累积足够多的对象进行扫描,从而抵消累积过程的成本。如果堆结构非常规则(对象大小相同,且在对象图中的深度也相近),那么这个假设显然成立。但是,有些工作负载通常要求我们每次只能扫描一个对象。这可能比图泛洪更糟糕,因为我们可能在尝试累积对象到页面上的过程中,反而做了更多工作,最终却失败了。
Green Tea 算法针对仅包含单个待扫描对象的页面进行了特殊处理。这有助于减少性能回退,但并不能完全消除它们。
然而,要超越图泛洪算法,所需的单页累积数据量远比你想象的要少。这项研究的一个意外发现是,每次仅扫描页面 2% 的数据就能取得比图泛洪算法更好的性能。
可用性
“绿茶”已经在最近的 Go 1.25 版本中作为实验性功能提供,并且可以通过在构建时将环境变量 GOEXPERIMENT 设置为 greenteagc 来启用。这不包括前述的向量加速。
我们预计在 Go 1.26 中将“绿茶”作为默认的垃圾回收器,但你仍然可以通过 GOEXPERIMENT=nogreenteagc 在构建时选择退出。Go 1.26 还将在较新的 x86 硬件上增加向量加速,并根据我们收集的反馈包含一系列的调整和改进。
如果可以,我们鼓励你尝试使用 Go 的最新tip版本!如果你更喜欢使用 Go 1.25,我们也同样欢迎您的反馈。请参阅这个 GitHub 评论,其中包含一些关于我们感兴趣的诊断信息、如果你可以分享的话,以及首选的反馈渠道的细节。
旅程
在结束这篇博文之前,让我们花点时间谈谈我们走到今天的历程,以及这项技术背后的人的因素。
绿茶的核心理念看似简单,就像某个人灵光一闪的灵感火花。
但事实并非如此。“绿茶”是许多人多年来共同努力和构思的成果。Go 团队的多位成员都参与了构思,包括 Michael Pratt、Cherry Mui、David Chase 和 Keith Randall。当时在英特尔工作的 Yves Vandriessche 的微架构见解也对设计探索起到了至关重要的作用。为了使这个看似简单的理念得以实现,我们尝试了许多方法,也处理了许多细节问题。
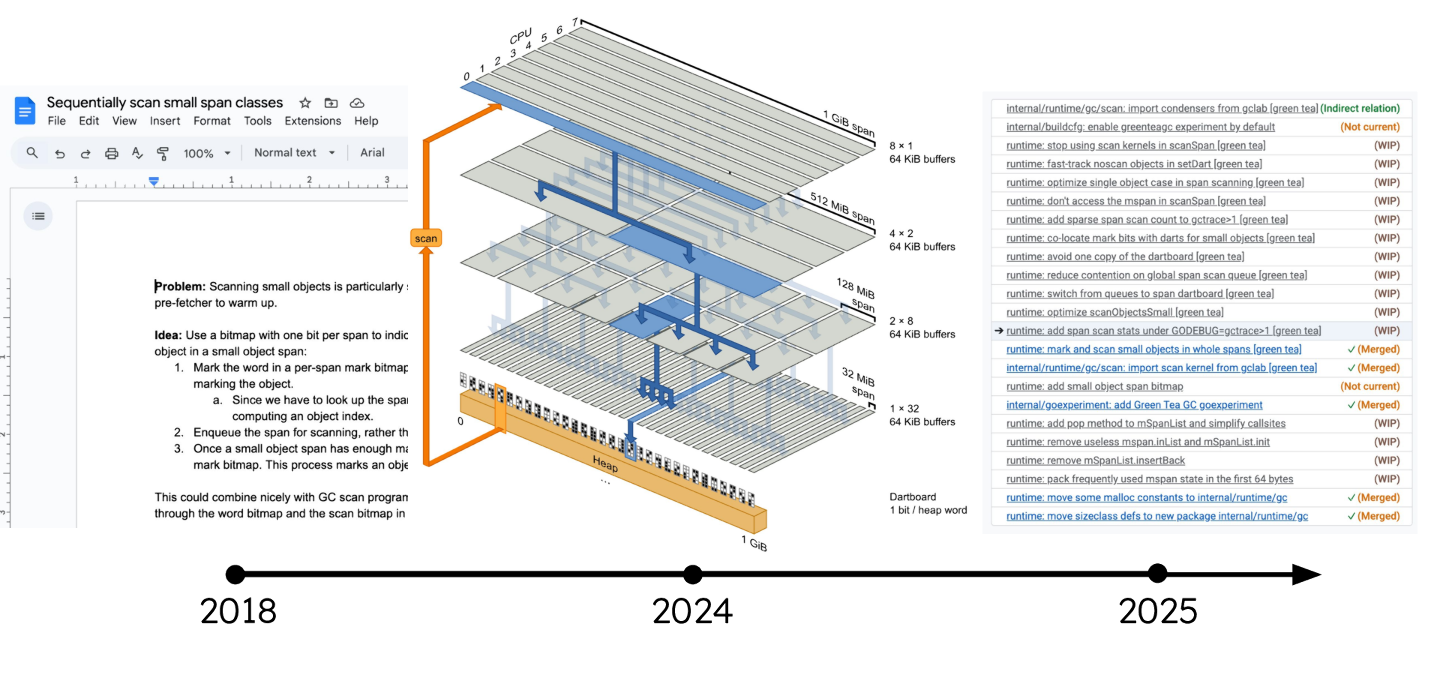
时间线描绘了我们在达到今天这种状态之前,尝试过的一些类似想法 这个想法的萌芽可以追溯到2018年。有趣的是,团队里的每个人都认为最初的想法是别人提出的。
绿茶这个名字是在2024年得来的。当时,奥斯汀在日本四处寻觅咖啡馆,喝了无数抹茶,并由此构思出了早期版本的原型!这个原型证明了绿茶的核心理念是可行的。从此,我们便开始了绿茶的研发之路。
在 2025 年,随着 Michael 将绿茶项目实施并投入生产,其理念进一步发展和变化。
这需要大量的协作探索,因为绿茶算法不仅仅是一个算法,而是一个完整的设计空间。我们认为,单凭我们中的任何一个人都无法独自驾驭它。仅仅有想法是不够的,你还需要弄清楚细节并加以验证。现在我们已经做到了,终于可以开始迭代了。
“绿茶”的未来是光明的。
再次,请通过设置 GOEXPERIMENT=greenteagc 来尝试它,并让我们知道它的效果如何!我们对这项工作感到非常兴奋,并希望听到你的声音!
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
- 想写出更地道、更健壮的Go代码,却总在细节上踩坑?
- 渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
- 想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

想系统学习Go,构建扎实的知识体系?
我的新书《Go语言第一课》是你的首选。源自2.4万人好评的极客时间专栏,内容全面升级,同步至Go 1.24。首发期有专属五折优惠,不到40元即可入手,扫码即可拥有这本300页的Go语言入门宝典,即刻开启你的Go语言高效学习之旅!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
