
本文永久链接 – https://tonybai.com/2022/05/10/introduction-of-implement-dsl-using-antlr-and-go
一. 引子
设计与实现一门像Go这样的通用编程语言的确很难!那是世界上少数程序员从事的事业,但是实现一门领域特定语言(Domain Specific Language, DSL)似乎是可行的。
就像著名的语言解析器生成工具ANTLR作者Terence Parr在《编程语言实现模式》一书中说的那样:
Yes, building a compiler for a general-purpose programming language requires a strong computer science background. But, most of us don’t build compilers. So, this book focuses on the things that we build all the time: configuration file readers, data readers, model-driven code generators, source-to-source translators, source analyzers, and interpreters. (翻译为中文:是的,为通用编程语言构建一个编译器需要强大的计算机科学背景。但是,我们中的大多数人并不构建编译器。所以,这本书的重点是我们一直在构建的东西:配置文件阅读器、数据阅读器、模型驱动的代码生成器、源码到源码的翻译器、源码分析器和解释器。)

最近因业务需要,我们要在车端实现一个车辆数据处理的规则引擎SDK。这个SDK供车端数据服务使用,用于车辆数据上报前的预处理(如下图)。
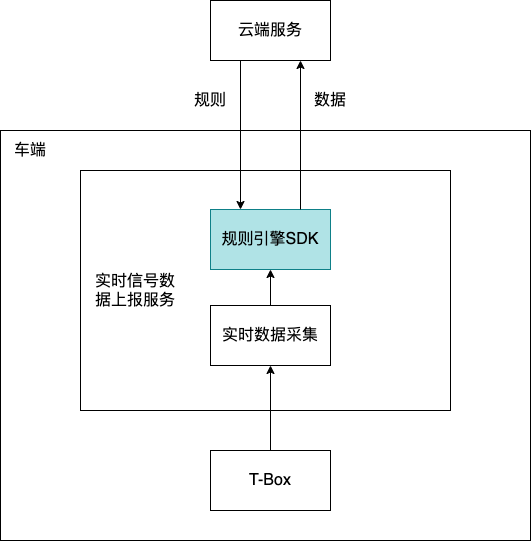
这么做,一来是因为隐私数据因隐私法规要求不可上传云端,另外特定业务场景下云端处理海量汽车的窗口数据开销太大,相反在车端处理便容易很多。随着车端算力的不断增强,这种车云结合也是车联网发展的趋势。车端有了数据处理的规则引擎后,通过云端下发规则的方式,车端便可以实现对数据处理逻辑的精准管控与快速安全的热更新(无需OTA)。
针对引擎的规则的描述至少有两种技术方案,一种是使用以标准数据交换格式(比如:Json、yaml、xml等)承载的配置文件,一种则是自定义的领域特定语言(DSL)。我们选择了后者,为的是表达简单精炼、更贴近领域、表达范围安全可控以及抽象层次更高等。
按照Martin Fowler的《领域特定语言》一书的介绍,DSL大体分为外部DSL与内部DSL。其中内部DSL是直接采用现有通用编程语言,比如python、lua、go的语法特性实现的DSL;而外部DSL则需要自己创建一门新语言,并实现语言的编译器或解析器,比如:SQL、ant、make等。
对于在车端的执行的规则而言,使用通用编程语言语法描述的规则具有一定的不安全性,不符合我们的要求。我们只有外部DSL这一条路可走。这就需要我们自行设计DSL语法、DSL语言的解析器以及执行相应语义的执行器,如下图所示:
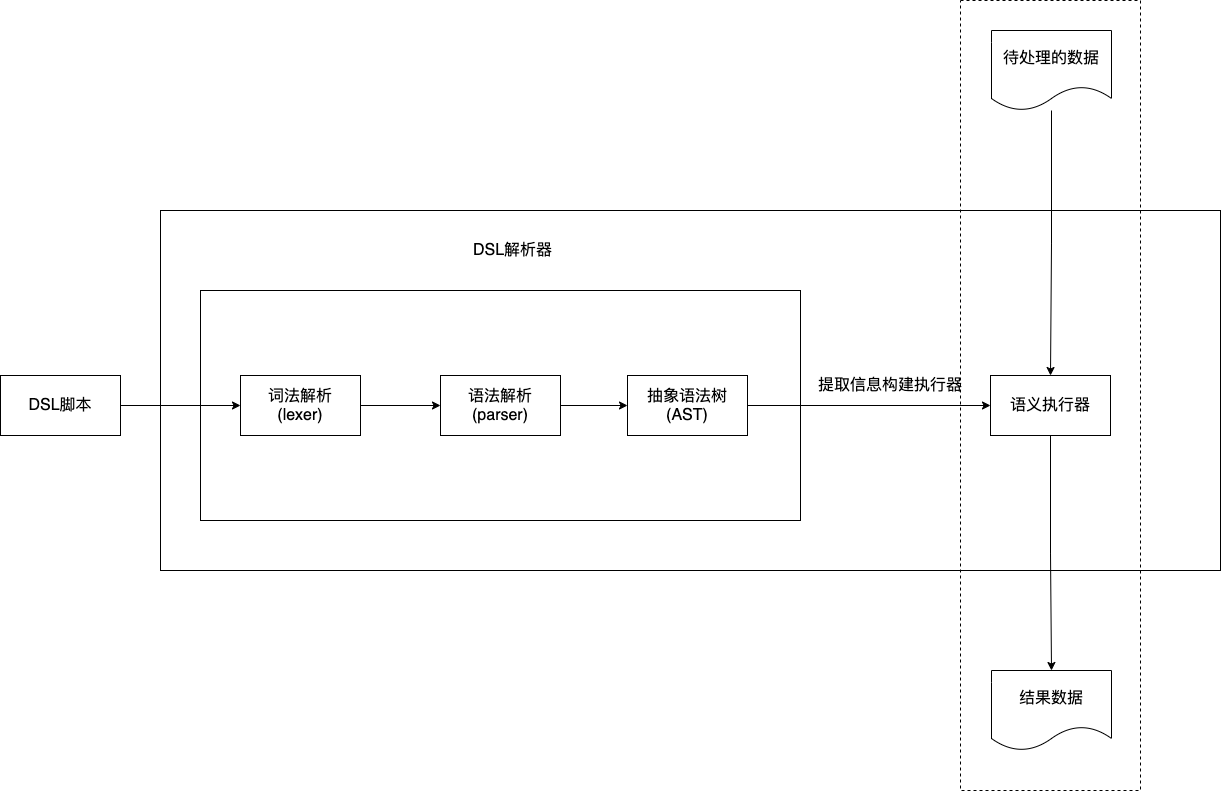
看到上面示意图中的词法分析、语法分析,你肯定会想起大学时学过的难忘的一门课:编译原理。还记得当时你是如何通过这门课的考核的吗^_^。编译原理是计算机专业学生挂科率较高的一门专业课,它不仅抽象,听起来还十分枯燥。笔者并非计算机专业科班出身,但读本科时一直在旁听计算机系姜守旭老师的形式语言以及编译原理课,虽然当时有些云里雾里,但课程内核我还是有所把握。
好了!现在编译原理课的概念与方法又要派上用场了!我们需要利用编译原理课上学到的知识来手工实现上图中的词法分析器、语法分析器…。
等等!我们非要手工实现么?难道就没有工具能帮助我们吗?编译技术经过这么多年的发展,像词法分析、语法分析这两个阶段已经可以由工具自动帮你完成了。也就是说我们可以通过工具自动生成可以对DSL脚本进行词法分析(lexer)与语法分析(parser)的代码。
对于编译器领域的新手,就像我,或者已经将编译原理知识还给老师的童鞋,我个人还是建议先使用辅助工具自动生成lexer和parser。在这一过程中,可以重温编译知识并深刻体会上下文无关文法(context-free grammar)的解析过程。当对这一问题域有深刻认知后,如果觉得自动生成的代码不够漂亮、不够灵活或性能不佳,再考虑手写lexer和parser也不迟。
如果我没记错,Go最初的lexer和parser就是自动生成的,后来才换成Go语言之父之一的Robert Griesemer手写维护的Parser。
那么我们选择哪个语法解析器的生成工具呢?我们继续往下看。
二. 选择ANTLR
市面上可用于自动生成lexer和parser代码的工具有很多种。知名度高,应用较为广泛的包括:Lex和Yacc(GNU对应的版本的叫Flex和Bison)和ANTLR等。这里面lex和yacc(gnu版本:flex和bison)是固定组合。
lex和yacc在20世纪70年代中旬诞生于著名的贝尔实验室,lex的原作者是Mike Lesk和Eric Schmidt(没错,就是Google前CEO),而yacc的原作者为Stephen C. Johnson。同样在贝尔实验室供职的C++之父Bjarne Stroustrup就是用yacc实现了第一个C++编译器cfront的前端的(C代码)。
lex是词法分析器,负责将源码(字符流)解析为一个个词法元素(token);而yacc则将这些token作为输入,构建出一个程序结构,通常是一个抽象语法树(如下图)。
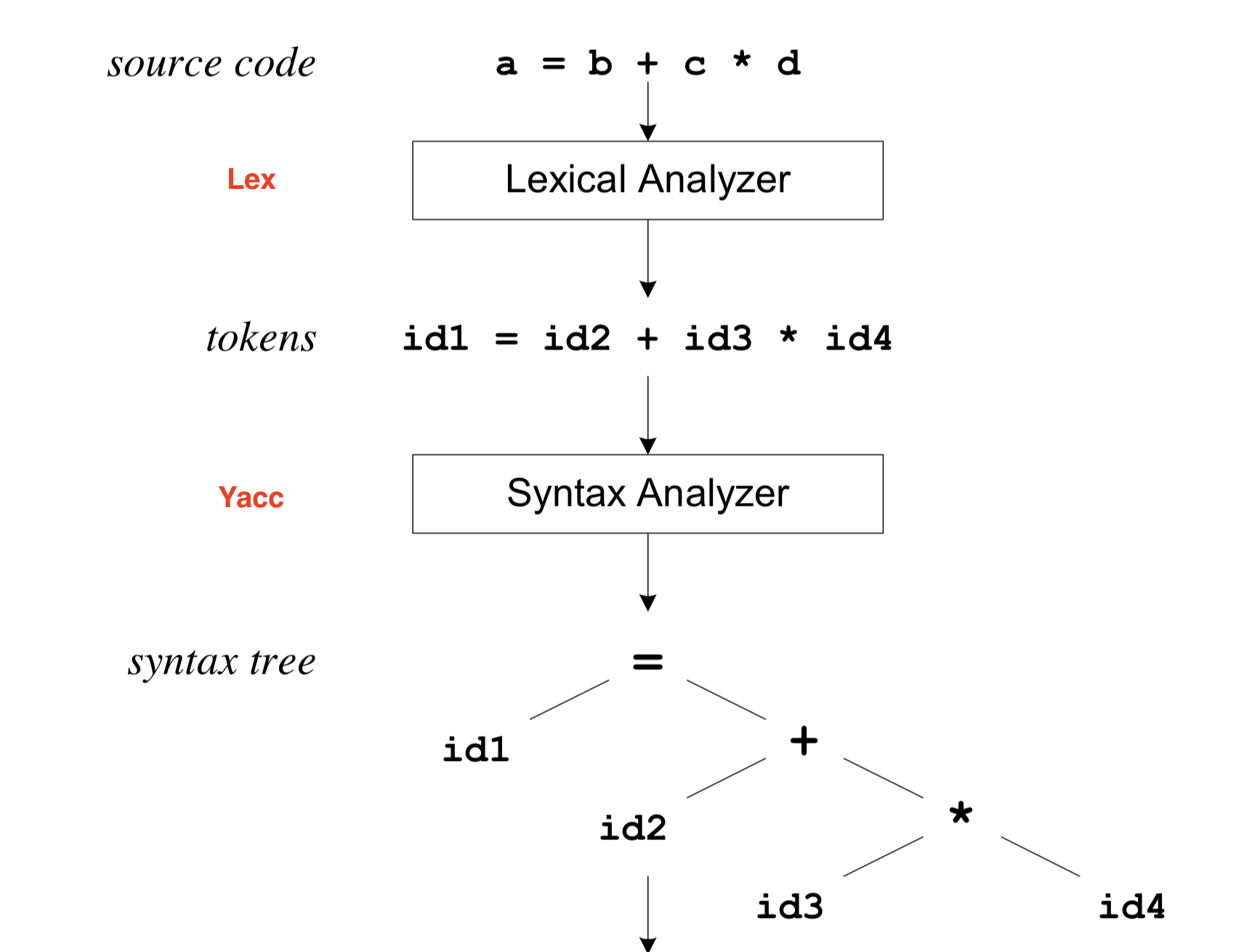
图片来自lex和yacc教程
不过由于lex和yacc诞生较早,支持生成的目标语言较少。经典的贝尔实验室的yacc最初只支持生成C语言的解析器代码。Gnu版本的Bison支持输出C、C++和Java。但和很多后起之秀相比,比如ANTLR,yacc(和bison)在目标语言可选择的广泛性、调试工具多样性以及整个社区的运作方面就显得相形见绌了。
ANTLR是由Terence Parr教授(目前跳槽去Google了)在上世纪90年代初期使用Java语言开发的一个强大的语法分析器生成工具,至今ANTLR依然在积极开发,并且有着一个稳定的社区。ANTLR支持生成C#, Java, Python, JavaScript, C++, Swift, Go, PHP等几乎所有主流编程语言的目标代码,并且ANTLR官方自己维护了Java、C++、Go等目标语言的runtime库(见下图):
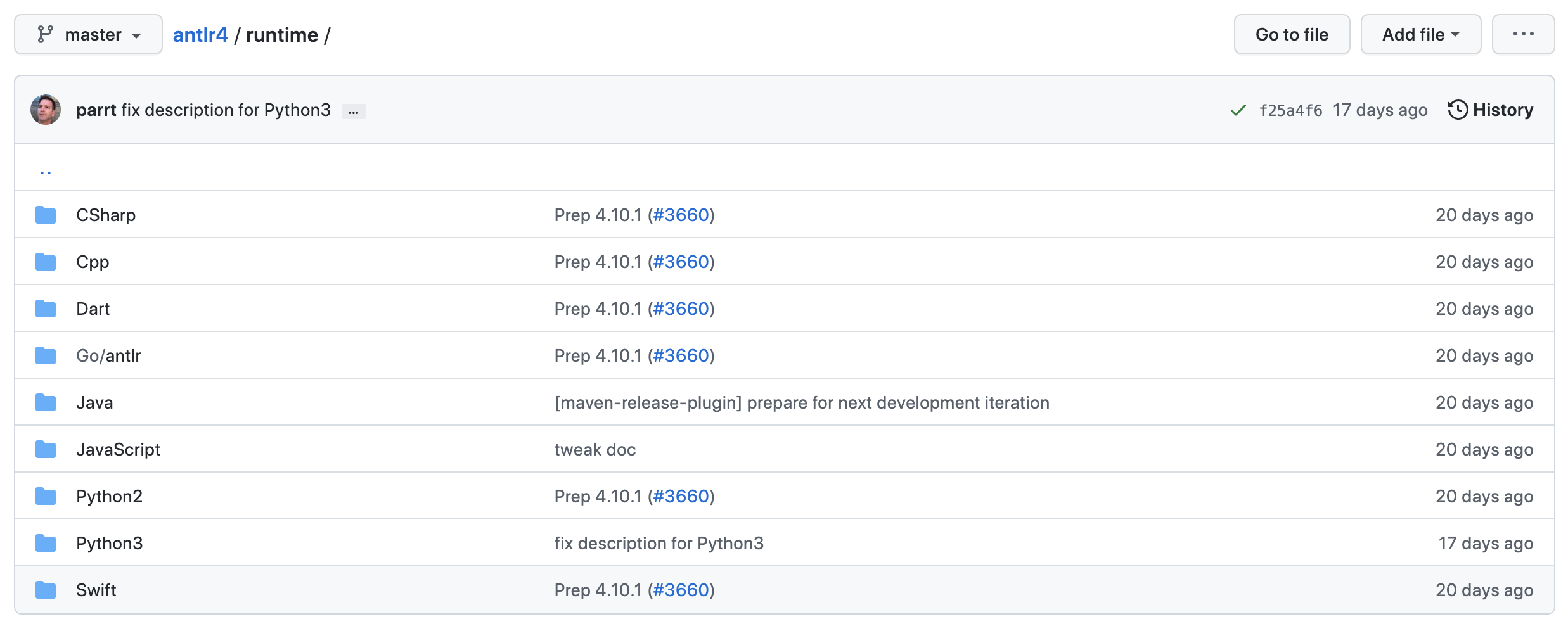
ANTLR可以生成各种主流通用编程语言的parser,并且在grammars-v4仓库中提供了这些语言的antlr4语法rule文件(antlr规则文件以g4为文件名后缀),这些rule样例文件可作为我们自己设计文法时的重要参考。
这里我们选择使用ANTLR来生成DSL的Parser。
三. 如何基于ANTLR定义DSL语法
外部DSL与通用编程语言相比,体量虽小,但也是一门语言,我们在自动生成或手工编写其解析器之前需要定义出该DSL的语法。更准确地说是DSL的形式化语法。
那么,如何定义/形式化一门语言呢?和自然语言一样,编程语言也都是有结构的。定义语言就是要把这些结构,包括成分与排列顺序规则,精确地描述出来。我们小学学习语文的时候,大家都学会句型分析,什么主谓宾定状补等。一个汉语完整句子的完整结构如下:
// ()内的语法成分是可选的
(定语)主语 + (状语)谓语(补语) + (定语)宾语(补语)
要使用汉语表达正确的意思,就要满足这样的结构。要定义DSL语言,我们也要精确定义出DSL的结构。
那么我们用什么方式来描述这种DSL的语法结构呢?在学习形式语言或编译原理课程时,想必大家肯定接触过BNF(Backus-Naur Form),即巴科斯范式。巴科斯范式是以美国人巴科斯(Backus)和丹麦人诺尔(Naur)的名字命名的一种形式化的语法表示方法,是用来描述语法的一种形式体系,是一种典型的元语言。自从编程语言Algol 60(Naur,1960)使用BNF符号定义语法以来,这种符号规则体系被证明适合作为形式化编程语言的语法,之后人们也开始习惯于使用此类元语言去定义语言语法。
BNF元语言的典型表达形式如下:
<symbol> ::= expression
<symbol> ::= expression1 | expression2
- 这个式子左侧放在尖括号中的symbol是一个非终结符号,而expression这个表达式由一个或多个终结符号或非终结符号的序列组成,这个式子也被称为产生式(production)。
- 产生式中的“::=”这个符号含义是“被定义为”,左边的非终结符号可以被推导为右边的表达式,右边的表达式也可以归约为左边的非终结符号。
- 如果右侧有多种表达式形式可作为symbol的归约选择,可以使用”|”符号分隔。
- 从未出现在左边的符号是终结符号。另一方面,出现在左侧的符号为非终结符号,并且总是被包围在一对<>之间。
随着BNF的广泛应用,一些以简化BNF或特定应用为目的的扩展BNF元语言被创建出来,其中典型的包括EBNF、ABNF等。
最早的EBNF是由Niklaus Wirth开发的, 它包含了Wirth语法符号中的一些概念和不同的语法和符号. 1996年,国际标准化组织通过了EBNF标准ISO/IEC 14977:1996。
EBNF使用了与BNF不同的符号且对BNF进行了增强,EBNF甚至可以定义自己的语法(如下):
letter = "A" | "B" | "C" | "D" | "E" | "F" | "G"
| "H" | "I" | "J" | "K" | "L" | "M" | "N"
| "O" | "P" | "Q" | "R" | "S" | "T" | "U"
| "V" | "W" | "X" | "Y" | "Z" | "a" | "b"
| "c" | "d" | "e" | "f" | "g" | "h" | "i"
| "j" | "k" | "l" | "m" | "n" | "o" | "p"
| "q" | "r" | "s" | "t" | "u" | "v" | "w"
| "x" | "y" | "z" ;
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;
symbol = "[" | "]" | "{" | "}" | "(" | ")" | "<" | ">"
| "'" | '"' | "=" | "|" | "." | "," | ";" ;
character = letter | digit | symbol | "_" ;
identifier = letter , { letter | digit | "_" } ;
terminal = "'" , character , { character } , "'"
| '"' , character , { character } , '"' ;
lhs = identifier ;
rhs = identifier
| terminal
| "[" , rhs , "]"
| "{" , rhs , "}"
| "(" , rhs , ")"
| rhs , "|" , rhs
| rhs , "," , rhs ;
rule = lhs , "=" , rhs , ";" ;
grammar = { rule } ;
我们看到EBNF使用”=”替代BNF中的”::=”,并且终结符号必须放在双引号内,避免了BNF自身使用的符号(<, >, |, ::=)无法在语言中使用。此外,BNF语法只能在一行中定义一条产生式规则,而EBNF使用一个终止字符,即分号字符”;”来标识着一条产生规则的结束,这样EBNF的一条产生式规则可以跨越多行。 此外,EBNF还提供了许多增强的机制,比如:定义重复的数量、支持注释等。
我们看到无论是BNF还是EBNF,它们都有一个共同特点,那就是产生式规则左侧仅有一个非终结符号,这样定义出的语法(文法)称为上下文无关(Context-Free Grammar,CFG)文法。以下面产生式规则为例:
S = aSb
我们看到S始终都可以被推导为aSb,而无需考虑S在什么位置,上下文是什么。如果你还云里雾里,我们可以对比**上下文相关文法(Context-Sensitive Grammar,CSG)**来理解。下面就是一个上下文相关文法的产生式规则:
aSb = abScd
在这个产生式的左侧,S不再是“孤单”的,而是左右各有一个“保镖”:a和b。a和b就是S的上下文,也就说S只有在“左有a且右有b”的上下文环境下才能被推导为abScd。
可以看出上下文相关文法更具通用性,因为一些语言(比如自然语言)可以用上下文相关文法定义,但却无法用上下文无关文法定义。但计算机编程语言更多使用上下文无关文法就可以定义。因此,后续我们定义的文法都是上下文无关文法。
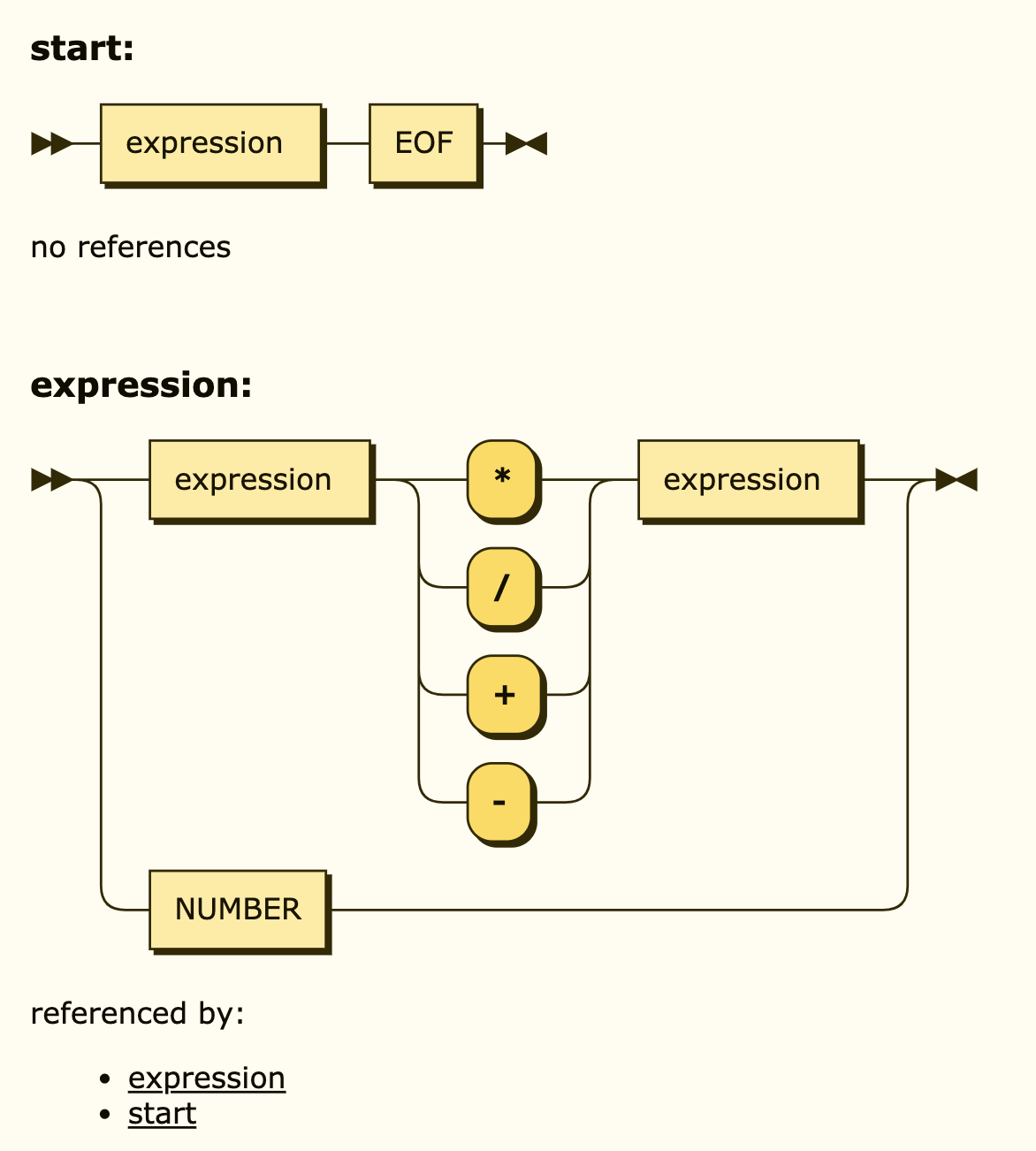
ANTLR使用的是一种类EBNF的语法,通过ANTLR语法定义的DSL的语法规则放置在后缀为”.g4″的规则文件中,下面是一个ANTLR语法描述的简单计算器的DSL语法(该例子来自这里):
// Calc.g4
grammar Calc;
// Rules
start : expression EOF;
expression
: expression op=('*'|'/') expression # MulDiv
| expression op=('+'|'-') expression # AddSub
| NUMBER # Number
;
// Tokens
MUL: '*';
DIV: '/';
ADD: '+';
SUB: '-';
NUMBER: [0-9]+;
WHITESPACE: [ \r\n\t]+ -> skip;
-
一个antlr描述的语法规则由grammar关键字开始,后接这份语法的名字,这个名字要与文件名保持一致。比如上面例子中的语法名字为Calc,那么承载这份语法定义的文件名就应该为Calc.g4,否则通过antlr工具生成目标代码时会报错!
-
antlr支持在语法定义文件中使用注释,支持单行注释//和多行注释/* … */。
-
antlr语法定义文件本质上就是一个产生式规则的集合,其主体结构如下:
grammar MyG; rule1 : «stuff» ;
rule2 : «more stuff» ; …
-
antlr本身就是一种类EBNF元语言,它使用冒号(:)作为产生式左侧非终结符号与右侧推导表达式的分隔符,使用与EBNF相同的分号(;)作为一条产生式规则的结束符,这样antlr可以支持一个产生式规则跨多行定义,就像上面例子中的非终结符号expression;
-
antlr又将非终结符号做了细分,一种是首字母小写的单词代表的语法解析器规则(parser rule),另外一种是首字母大写的单词(通常整个单词都大写)代表的词法分析器规则(lexical/token rule)。前者用于定义语法结构,就像上例中的expression,后者则定义词汇符号,比如上例中的NUMBER。
-
上面例子中start作为整个Calc语法的起始规则;语法从start开始,自上而下展开。因此一个antlr dsl规则文件都应该有一个起始规则,名字可任意起;
-
如果产生式右侧有多个可选表达式,可以用竖线(|)分开;
-
expression产生式每个可选表达式后面的井号及后面的单词用于指示这条推导表达式在目标代码中的方法名,主要是服务于生成的目标代码。
比如:上述例子中的expression产生式“等价于”下面语法:
expression
: muldiv
| addsub
| NUMBER
;
muldiv
: expression op=('*'|'/') expression
;
addsub:
| expression op=('+'|'-') expression
;
但是这个所谓的“等价”语法定义是有问题的,当我们用antlr基于该语法文件试图生成目标代码时会提示:
error(119): Calc.g4::: The following sets of rules are mutually left-recursive [expression, muldiv, addsub]
antlr命令行工具提示Calc.g4中存在互斥的左递归问题。Antlr可以自动处理直接左递归,即在一个产生式规则中存在的左递归(对应到代码层面,就是在代表自己的函数Expr中递归调用Expr),比如:
expr: expr op=('*'|'/') expr ;
如果是跨产生式规则的左递归,又称间接左递归(对应到代码层面就是在Expr函数中调用另外一个函数AddSub,而AddSub函数又调用了Expr函数),比如下面规则:
expr: addsub;
addsub: expr op=('+'|'-') expr;
Antlr无法自动解决这种间接左递归,需要你优化DSL语法,消除间接左递归。
如果你不习惯antlr定义dsl的语法,你可以通过https://bottlecaps.de/convert/这个在线工具将antlr4语法转换为EBNF语法(如下,可能不是标准EBNF):
start ::= expression EOF
expression
::= expression ( '*' | '/' | '+' | '-' ) expression
| NUMBER
_ ::= WHITESPACE
/* ws: definition */
<?TOKENS?>
NUMBER ::= [0-9]+
WHITESPACE
::= [ \r\n\t]+
EOF ::= $
该工具还支持在线生成语法对应的状态转换图,如下图:
好了,到这里我们铺垫了很多很多了,下面我们来基于antlr进行一次实战!
四. ANTLR安装、代码生成与语法调试
1. 安装和配置ANTLR
ANTLR是一个Java开发的命令行工具包(截至发此文时,最新版本为4.10.1),其安装步骤很简单。在官方醒目的位置有安装步骤,这里摘抄下来^_^:
// 适用于MacOS(已安装JDK)
$ cd /usr/local/lib
$ sudo curl -O https://www.antlr.org/download/antlr-4.10.1-complete.jar
// 通过下面命令将antlr jar包加入classpath并定义antlr4别名
// 或编辑shell的环境文件,比如.zshrc/.bashrc等,将下面内容添加到环境文件中并source生效
// grun别名将启动antlr提供的DSL语法调试工具,非常实用
$ export CLASSPATH=".:/usr/local/lib/antlr-4.10.1-complete.jar:$CLASSPATH"
$ alias antlr4='java -jar /usr/local/lib/antlr-4.10.1-complete.jar'
$ alias grun='java org.antlr.v4.gui.TestRig'
安装后,执行下面命令,如果输出内容与下面相同,则说明安装成功。
$antlr4
ANTLR Parser Generator Version 4.10.1
... ...
接下来我们就来生成一个示例DSL的目标Parser代码。
2. 生成一个CSV格式解析器的框架代码
本文是一篇入门文章,所以我挑选了一个大家都十分熟悉的数据格式CSV(逗号分隔的数据文件格式),我们为这种数据格式生成一种可以实现解析和转换的DSL的parser。《ANTLR4权威指南》一书的8.1小节有一个CSV的例子,我们就“拿来主义”,为这个CSV语法生成对应的Parser代码框架。
书中给出的CSV语法规则文件如下:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/CSV.g4
grammar CSV;
csvFile: hdr row+ ;
hdr : row ;
row : field (',' field)* '\r'? '\n' ;
field
: TEXT
| STRING
|
;
TEXT : ~[,\n\r"]+ ;
STRING : '"' ('""'|~'"')* '"' ; // quote-quote is an escaped quote
书中这个例子给出CSV格式是带有header行的,即认为CSV文件的第一行是header。之后的行才是数据。而数据既可以是直接文本也是带有双引号的字符串。
我们基于这个规则文件生成对应的Go代码:
$antlr4 -Dlanguage=Go -o parser CSV.g4
通过-Dlanguage选项告诉antlr要生成的目标代码语言,通过-o指定生成代码存放的目录,这里我们告诉antlr将生成的Go代码放在parser目录下,由于生成的Go包名默认为parser,因此指定parser目录与Go的包导入路径机制是契合的。但是目前antlr不会根据传给-o的目录名去修改生成代码的包名。比如:-o parser1,生成代码在parser1目录下,但代码的包名依旧为parser,这点要注意。
$tree ./parser
.
├── CSV.g4
└── parser
├── CSV.interp
├── CSV.tokens
├── CSVLexer.interp
├── CSVLexer.tokens
├── csv_base_listener.go
├── csv_lexer.go
├── csv_listener.go
└── csv_parser.go
3. 代码探索
下面我们对照CSV.g4中的语法规则,简单探索一下antlr生成的Go代码。
如上面parser目录下的布局,antlr4默认情况下共生成了四个Go源文件:
- csv_lexer.go:提供词法分析器实现
- csv_parser.go:提供语法分析器的实现
- csv_listener.go:定义了CSVListener接口
- csv_base_listener.go:提供了一个CSVListener接口的默认实现BaseCSVListener,其方法实现默认都为空,即什么也不做。
这里重点看一下CSVListener接口:
// CSVListener is a complete listener for a parse tree produced by CSVParser.
type CSVListener interface {
antlr.ParseTreeListener
// EnterCsvFile is called when entering the csvFile production.
EnterCsvFile(c *CsvFileContext)
// EnterHdr is called when entering the hdr production.
EnterHdr(c *HdrContext)
// EnterRow is called when entering the row production.
EnterRow(c *RowContext)
// EnterField is called when entering the field production.
EnterField(c *FieldContext)
// ExitCsvFile is called when exiting the csvFile production.
ExitCsvFile(c *CsvFileContext)
// ExitHdr is called when exiting the hdr production.
ExitHdr(c *HdrContext)
// ExitRow is called when exiting the row production.
ExitRow(c *RowContext)
// ExitField is called when exiting the field production.
ExitField(c *FieldContext)
}
这是antlr根据CSV.g4中的文法生成的Listener,你一定要对照着CSV.g4中的文法来看这个接口的方法集合。我们看到,对于每个CSV.g4中的解析器规则(parser rule),比如:csvFile、hdr、row、field,CSVListener中都有一对与之对应的方法。以hdr为例,EnterHdr对应进入hdr产生式规则时调用的方法,ExitHdr则对应离开hdr产生式规则时调用的方法。后续我们自定义遍历抽象语法树的CSVListener实现,就是要根据需要实现对应的方法即可。这个对照我们稍后的例子中代码,你会有更深刻的体会。
此外,antlr生成的代码不多,但我们看到生成的CSVParser和CSVLexer两个结构中分别内嵌了antlr.BaseParser和antlr.BaseLexer,也就是说核心的实现都在antlr提供的go runtime中。
此外这里还要说一下parser解析完文法后生成的语法树的访问方式。antlr提供两种语法树的遍历方式,一种是listener,一种是visitor,但antlr默认只是生成了listener的代码。如果要生成visitor代码,可以在命令行使用-visitor选项:
$antlr4 -Dlanguage=Go -visitor -o parser CSV.g4
生成的源文件中就会多出csv_visitor.go和csv_base_visitor.go,前者定义了CSVVisitor接口,后者提供了CSVVisitor的基本实现:BaseCSVVisitor:
$tree parser
parser
├── CSV.interp
├── CSV.tokens
├── CSVLexer.interp
├── CSVLexer.tokens
├── csv_base_listener.go
├── csv_base_visitor.go
├── csv_lexer.go
├── csv_listener.go
├── csv_parser.go
└── csv_visitor.go
当然antlr4命令行提供了各种精细的控制开关来控制是否生成listener或visitor:
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener
-visitor generate parse tree visitor
-no-visitor don't generate parse tree visitor (default)
在后面我们将使用listener方式遍历抽象语法树提取我们需要的信息。在深入代码之前,我们再来看看antlr提供的调试工具。
4. 文法调试工具
我们基于antlr4提供的规则手工编写DSL的语法规则,难免会出现各种各样的问题,比如:有二义性、规则顺序导致的错误推导等。antlr提供了十分强大且方便的调试工具grun:
$grun -h
java org.antlr.v4.gui.TestRig GrammarName startRuleName
[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname]
[-trace] [-diagnostics] [-SLL]
[input-filename(s)]
Use startRuleName='tokens' if GrammarName is a lexer grammar.
Omitting input-filename makes rig read from stdin.
由于grun是java实现的,我们只能在目标代码为Java的情况下对g4文件的解析进行调试。所以使用grun工具的前提是先生成Java目标代码:
$antlr4 CSV.g4
然后调用grun以及其提供的各种选项对解析过程进行调试。
- 图形化调试
通过下面结合了-gui选项的grun命令:
$grun CSV csvFile demo1.csv -gui
grun可以在新窗口中输出抽象语法树的全貌:
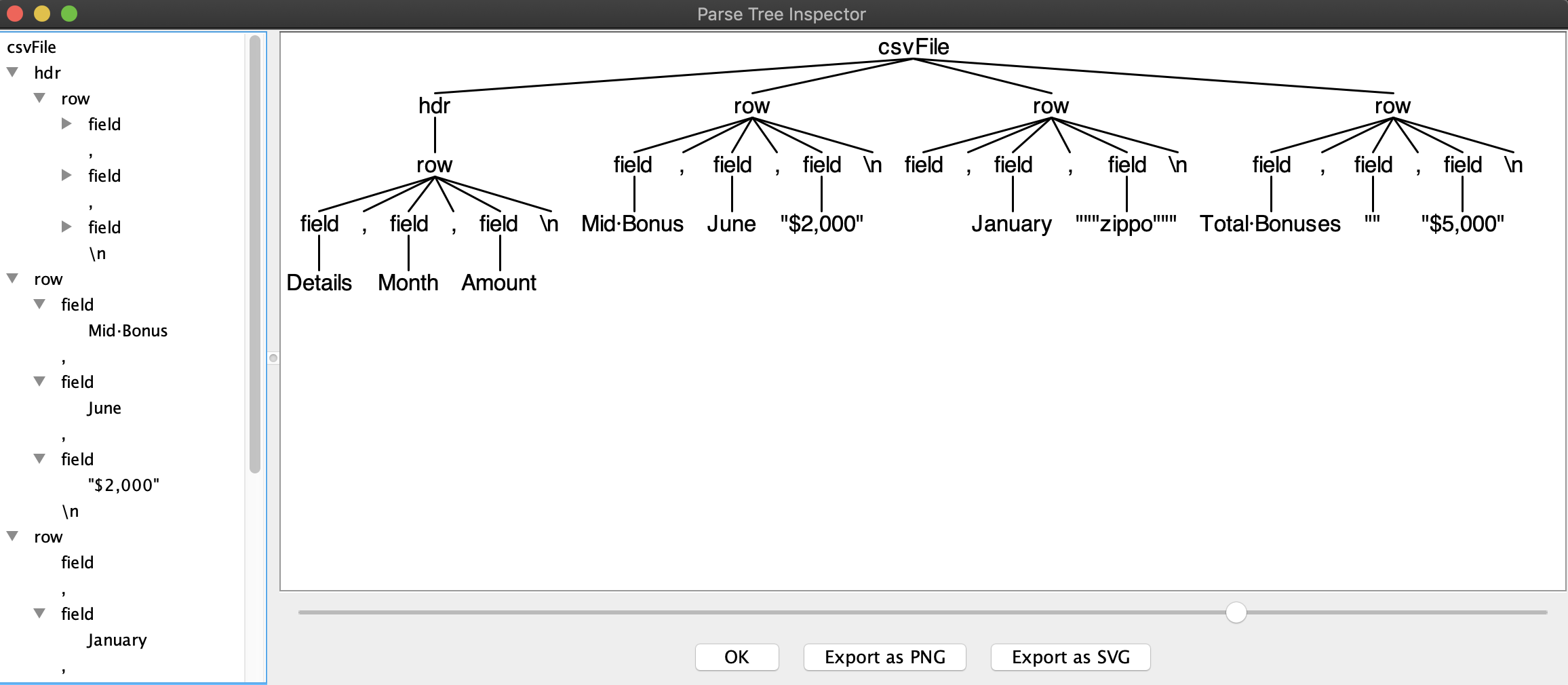
通过这样一个图形,我们可以清晰看出规则匹配是否如我们预期。
- Tree型调试
通过下面结合了-tree选项的grun命令:
$grun CSV csvFile demo1.csv -tree
grun可以在命令行输出树型匹配结构,这个就等价于图形化调试截图中的左侧窗口。如果你就喜欢命令行方式的输出,可以试试这个。
(csvFile (hdr (row (field Details) , (field Month) , (field Amount) \n)) (row (field Mid Bonus) , (field June) , (field "$2,000") \n) (row field , (field January) , (field """zippo""") \n) (row (field Total Bonuses) , (field "") , (field "$5,000") \n))
- 词法解析调试
grun还单独提供了针对词法分析阶段的调试命令行选项:-tokens:
使用下面命令:
$grun CSV csvFile demo1.csv -tokens
grun可以输出如下词法分析阶段的详细过程,通过这个输出,我们可以看出输入数据中的字符序列匹配情况,是否如预期的匹配到对应的词法规则上去了,比如CSV.g4中的两个词法规则:TEXT和STRING:
[@0,0:6='Details',<TEXT>,1:0]
[@1,7:7=',',<','>,1:7]
[@2,8:12='Month',<TEXT>,1:8]
[@3,13:13=',',<','>,1:13]
[@4,14:19='Amount',<TEXT>,1:14]
[@5,20:20='\n',<'\n'>,1:20]
[@6,21:29='Mid Bonus',<TEXT>,2:0]
[@7,30:30=',',<','>,2:9]
[@8,31:34='June',<TEXT>,2:10]
[@9,35:35=',',<','>,2:14]
[@10,36:43='"$2,000"',<STRING>,2:15]
[@11,44:44='\n',<'\n'>,2:23]
[@12,45:45=',',<','>,3:0]
[@13,46:52='January',<TEXT>,3:1]
[@14,53:53=',',<','>,3:8]
[@15,54:64='"""zippo"""',<STRING>,3:9]
[@16,65:65='\n',<'\n'>,3:20]
[@17,66:78='Total Bonuses',<TEXT>,4:0]
[@18,79:79=',',<','>,4:13]
[@19,80:81='""',<STRING>,4:14]
[@20,82:82=',',<','>,4:16]
[@21,83:90='"$5,000"',<STRING>,4:17]
[@22,91:91='\n',<'\n'>,4:25]
[@23,92:91='<EOF>',<EOF>,5:0]
此外,grun提供的-trace和-diagnostics均可以从不同角度为文法规则的正确性提供跟踪诊断信息。
为了方便使用,我将grun调试功能嵌入到Makefile中,通过make gui、make tokens、make tree等命令即可实现不同形式的调试。Makefile代码参见本文提供的代码示例csv2map。
五. 为示例增加语义
通过grun的调试,只能说明我们定义的文法(CSV.g4)是正确的,是可以解析输入的数据(demo1.csv)的。但解析成功后的数据要怎么处理呢?这就需要我们为示例增加处理语义。
在这个例子中,我们模仿《antlr权威指南》书中的例子将demo1.csv的数据形式转换为另一种map形式输出,举例来说,就是将下面的csv数据:
Details,Month,Amount
Mid Bonus,June,"$2,000"
,January,"""zippo"""
Total Bonuses,"","$5,000"
转换为下面map形式:
[{Details=Mid Bonus, Month=June, Amount="$2,000"},
{Details=, Month=January, Amount="""zippo"""},
{Details=Total Bonuses, Month="", Amount="$5,000"}]
虽然前面生成了parser目录下的parser包,但是还远远不够,我们还需手工增加上述语义行为。
首先,我们先来创建一个go module,方便后续依赖版本管理和程序构建:
$go mod init csvparser
然后通过go mod tidy拉取必要的依赖包,主要是github.com/antlr/antlr4/runtime/Go/antlr这个antlr go runtime包。之后我们就可以创建main.go了,下面是该parser的main函数:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/main.go
func main() {
csvFile := os.Args[1]
is, err := antlr.NewFileStream(csvFile)
if err != nil {
fmt.Printf("new file stream error: %s\n", err)
return
}
// Create the Lexer
lexer := parser.NewCSVLexer(is)
stream := antlr.NewCommonTokenStream(lexer, antlr.TokenDefaultChannel)
// Create the Parser
p := parser.NewCSVParser(stream)
// Finally parse the expression
l := &CSVMapListener{}
antlr.ParseTreeWalkerDefault.Walk(l, p.CsvFile())
fmt.Printf("%s\n", l.String())
}
我们通过命令行传入要解析的csv格式的文件,通过antlr包提供的NewFileStream创建输入数据流,并将该数据流传给新创建的lexer,经过lexer的解析后,我们得到token stream,经过前面的铺垫,我们知道token stream是要传给新创建的Parser。Parser会在内存中建立抽象语法树(见上面抽象语法树那张图)。
之后,也是最重要的就是遍历语法树,提取我们需要的信息了。前面说过,antlr基于CSV.g4仅仅是生成了一个CSVListener的接口以及一个空的BaseCSVListener的实现。但BaseCSVListener不能满足我们的要求,我们需要一个可以提取语法树中重要信息的CSVListener接口的实现,我这里称之为CSVMapListerner:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/csv_listener.go
type CSVMapListener struct {
*parser.BaseCSVListener
headers []string
cm []map[string]string
fields []string // a slice of fields in current row
}
我们看到,CSVMapListener首先嵌入了BaseCSVListener,“继承”了BaseCSVListener的所有方法实现,这使得CSVMapListener满足CSVListener接口。
CSVMapListener中的cm字段用于存储从抽象语法树中提取到的CSV数据信息,它本身是一个元素类型为map[string]string的切片;headers用于存储从抽象语法树中读取到的CSV文件的头信息;而fields则是代表CSV每一行数据的抽象。
我们不需要override BaseCSVListener的所有方法,我们只需在几个方法中保存提取到的信息即可。
整个CSV文件的关键数据单元是row,每当我们进入产生式规则row时,都需要为后续解析出的row信息准备好存储空间:
func (cl *CSVMapListener) EnterRow(c *parser.RowContext) {
cl.fields = []string{} // create a new field slice
}
对应到CSVMapListener,就是override EnterRow方法,在该方法中创建一个新的fields slice。
在产生式规则row完成时,将fields信息存储起来,即override ExitRow方法,见下面代码:
func (cl *CSVMapListener) ExitRow(c *parser.RowContext) {
// get the rule index of parent context
if i, ok := c.GetParent().(antlr.RuleContext); ok {
if i.GetRuleIndex() == parser.CSVParserRULE_hdr {
// ignore this row
return
}
}
// it is a data row
m := map[string]string{}
for i, h := range cl.headers {
m[h] = cl.fields[i]
}
cl.cm = append(cl.cm, m)
}
由于header也是一个row,我们不能将header当成普通row存储在cm中,所以在ExitRow中有一个是否是header row的判断。如果是header row,则啥也不做;否则创建一个map[string]string实例,将row信息存储在该map中,并append到cm的切片中保存起来。
如果row是header,我们只需要override ExitHdr方法,将fields信息保存到headers字段中备用,如下面代码:
func (cl *CSVMapListener) ExitHdr(c *parser.HdrContext) {
cl.headers = cl.fields
}
下面的ExitField方法是提取row中每个field文本信息的:将每个field的文本信息追加到fields切片中保存起来:
func (cl *CSVMapListener) ExitField(c *parser.FieldContext) {
cl.fields = append(cl.fields, c.GetText())
}
经过上述这些override方法后,我们就可以从抽象语法树中提取到我们需要的信息了,对应到main函数中的代码,我们将新创建一个CSVMapListener的实例,并将其传给antlr.ParseTreeWalkerDefault.Walk方法,后者会在特定时刻自动回调我们上面的override的方法来提取我们需要的信息:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/main.go
l := &CSVMapListener{}
antlr.ParseTreeWalkerDefault.Walk(l, p.CsvFile())
一旦信息都被提取到CSVMapListener的cm字段和headers字段中后,我们便可以按要求输出这些信息:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/csv_listener.go
func (cl *CSVMapListener) String() string {
var s strings.Builder
s.WriteString("[")
for i, m := range cl.cm {
s.WriteString("{")
for _, h := range cl.headers {
s.WriteString(fmt.Sprintf("%s=%v", h, m[h]))
if !cl.lastHeader(h) {
s.WriteString(", ")
}
}
s.WriteString("}")
if i != len(cl.cm)-1 {
s.WriteString(",\n")
continue
}
}
s.WriteString("]")
return s.String()
}
这个比较简单,就不赘述了。
以上main.go中的代码都是基于antlr的Parser的经典“套路”,大部分Parser都可以使用这些代码。你的重点在自定义Listener的实现上,就像本例中的CSVMapListener。
六. 小结
到这里我们就实现了一个可以解析CSV文件并将其中数据转换为特定格式输出的DSL解析器了。这个示例仅仅是说明了基于Antlr构建DSL解析器的原理与基本步骤。
简单回顾一下,基于Antlr实现DSL,第一要基于Antlr提供的类EBNF规则设计出DSL的文法,第二要基于antlr生成的代码实现一个DSL的Listener从抽象语法树提取你所需要的信息并构建执行语义。
在这个过程中,我们可以使用antlr提供的强大的调试工具来帮助我们解决问题,尤其是dsl文法中的问题。
本文中涉及的代码可以在这里下载。
七. 参考资料
- lex和yacc官网 – http://dinosaur.compilertools.net
- lex和yacc教程 – http://capsl.udel.edu/courses/cpeg421/2008/slides/lex-yacc_tutorial.pdf
- ANTLR官网 – https://www.antlr.org
- 《编程语言实现模式》 – https://book.douban.com/subject/10482195/
- 《ANTLR4权威指南》 – https://book.douban.com/subject/27082372/
- 龙书《编译原理:原理、技术与工具》 – https://book.douban.com/subject/3296317/
- Parsing with ANTLR 4 and Go – https://blog.gopheracademy.com/advent-2017/parsing-with-antlr4-and-go/
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2022年,Gopher部落全面改版,将持续分享Go语言与Go应用领域的知识、技巧与实践,并增加诸多互动形式。欢迎大家加入!





我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 微信公众号:iamtonybai
- 博客:tonybai.com
- github: https://github.com/bigwhite
- “Gopher部落”知识星球:https://public.zsxq.com/groups/51284458844544

微信赞赏:

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。