
本文永久链接 – https://tonybai.com/2022/05/27/an-example-of-implement-dsl-using-antlr-and-go-part3
在前面的系列文章中,我们为气象学家们设计了一门名为Tdat的DSL,使用ANTLR的文法规则编写了Tdat的文法,基于该文法生成了Tdat的语法解析器代码并初步验证了文法的正确性,Tdat可以成功将我们编写的Tdat语法代码样例解析为一颗内存中的树结构。
此时此刻,我们编写的DSL语法代码还无法按预期工作,因为缺少执行语义。在这篇文章中,我们就来为这门DSL建立语义模型,并单独对这个语义模型进行验证。
让我们的语法示例能真正按预期run起来!
一. 什么是语义模型
通过前面的文章,我们了解到:文法只是形式化了DSL的语法结构,即在语法树中是如何表现的,而这一切与语义无关。而所谓语义,就是当用这个语法写的代码执行时,它会做什么!
相同的语法,即便生成相同的语法树,那么由于对语法树的解释方法不同,语义就会不同。下面是Martin Fowler在其《领域特定语言》一书中的一个例子:
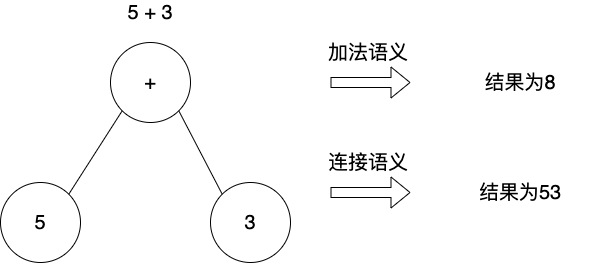
我们看到对同一语法写成的代码:5+3,如果语义模型不同,那么执行结果就不会相同:如果按加法语义解释语法树,我们得到的代码执行结果为8;如果按连接语义解释语法树,我们得到的代码执行结果为53。
那么语义模型究竟表现为何种形式呢?通常来说语义模型也是内存中的一个或一些特定的数据结构,这个数据结构存在的目的就是表述语义,对语句的执行逻辑进行制导。
比如:《使用ANTLR和Go实现DSL入门》一文中的那个csv2map例子,其语义模型就存储在CSVMapListener这个结构体中的一个map结构(见下面的cm字段)和切片结构(见下面的headers)中了:
// github.com/bigwhite/experiments/tree/master/antlr/csv2map/csv_listener.go
type CSVMapListener struct {
*parser.BaseCSVListener
headers []string
cm []map[string]string
fields []string // a slice of fields in current row
}
csv2map通过遍历生成的语法树提取信息填充构造了cm和headers这两个字段,后续的代码执行都是基于这两个字段中存储的信息。
到这里有童鞋可能会问:是不是对所有DSL都要单独提取和组装一个语义模型出来呢?至少Martin Fowler建议这么做,这样做的最大好处就是将语法解析与语义执行这两个阶段解耦,然后语义模型可以单独拿出来测试与验证,无需依赖语法解析过程。
我个人觉得对于稍大一些的non-trivial的DSL来说,将语义模型分离出来还是很必要的,否则语义执行与语法解析的耦合会让DSL的实现难于理解、难于维护,同样也难于测试验证。
对于一些简单的DSL来说,其语法树自身就可以看作是一个语义模型,在这样的情况下,语法树的遍历过程将伴随着语句语义的执行,下面就是一个典型的以语法树为语义执行模型的例子(改编自这篇文章中的例子),例子文法如下:
// Calc.g4
grammar Calc;
// Rules
start : expression EOF;
expression
: expression op=('*'|'/') expression # MulDiv
| expression op=('+'|'-') expression # AddSub
| NUMBER # Number
;
// Tokens
MUL: '*';
DIV: '/';
ADD: '+';
SUB: '-';
NUMBER: [0-9]+;
WHITESPACE: [ \r\n\t]+ -> skip;
基于该文法生成Parser代码后,我们实现一个语法树的Listener:
// calc/calc_listener_impl.go
type calcListener struct {
*parser.BaseCalcListener
stack []int
}
... ...
func (l *calcListener) ExitMulDiv(c *parser.MulDivContext) {
right, left := l.pop(), l.pop()
switch c.GetOp().GetTokenType() {
case parser.CalcParserMUL:
l.push(left * right)
case parser.CalcParserDIV:
l.push(left / right)
default:
panic(fmt.Sprintf("unexpected op: %s", c.GetOp().GetText()))
}
}
func (l *calcListener) ExitAddSub(c *parser.AddSubContext) {
right, left := l.pop(), l.pop()
switch c.GetOp().GetTokenType() {
case parser.CalcParserADD:
l.push(left + right)
case parser.CalcParserSUB:
l.push(left - right)
default:
panic(fmt.Sprintf("unexpected op: %s", c.GetOp().GetText()))
}
}
func (l *calcListener) ExitNumber(c *parser.NumberContext) {
i, err := strconv.Atoi(c.GetText())
if err != nil {
panic(err.Error())
}
l.push(i)
}
这段代码直接将Parser建立的语法树当成了二叉表达式树(binary expression tree,叶子节点是操作数,其他节点为操作符)了,然后通过表达式树求值算法(借由一个stack)实现代码的求值语义,看下面驱动求值的main函数代码:
// calc/main.go
// calc takes a string expression and returns the evaluated result.
func calc(input string) int {
// Setup the input
is := antlr.NewInputStream(input)
// Create the Lexer
lexer := parser.NewCalcLexer(is)
stream := antlr.NewCommonTokenStream(lexer, antlr.TokenDefaultChannel)
// Create the Parser
p := parser.NewCalcParser(stream)
// Finally parse the expression (by walking the tree)
var listener calcListener
antlr.ParseTreeWalkerDefault.Walk(&listener, p.Start())
return listener.pop()
}
func main() {
println(calc("1 + 2 * 3")) // 7
println(calc("12 * 3 / 6")) // 6
}
通过上述代码,我们可以很清晰地看到这个例子直接将源码解析后建立的语法树作为语义模型了,这就让语义模型与解析后的语法树的结构产生了紧耦合,一旦语法变更,语法树结构发生变化,就会直接影响语义模型的执行,语义模型的实现也要随之变更。
针对我们自己的tdat DSL,我们将采用语义模型与语法树分离的方式。下面我们就来看看tdat的语义模型。
二. 语义模型之表达式树
在本系列的第一篇文章中,我们介绍了Tdat这门DSL的语义特性,我们的语义模型就是要实现这些语义特性。我们回顾一下tdat文法中的核心产生式规则ruleLine:
ruleLine
: ruleID ':' enumerableFunc '{' windowsRange conditionExpr '}' '=>' result ';'
;
在这个产生式规则中,影响语义计算的主要规则包括:conditionExpr、windowRange、enumableFunc和result上,而最复杂的又在conditionExpr这个规则上。这个规则本质上就是一组一元、算术、比较和逻辑表达式的混合计算,
那么,我们能否像上面calc那个例子那样将语法树直接用作语义模型呢?实现层面上是可以的。我们以下面这个复杂一些的conditionExpr表达式为例:
(($speed < 5) and (($temperature + 1) < 10)) or ((roundDown($speed) <= 10.0) and (roundUp($salinity) >= 500.0))
我们来对比一下直接将语法树作为语义模型与使用表达式树结构作为语义模型的差别:
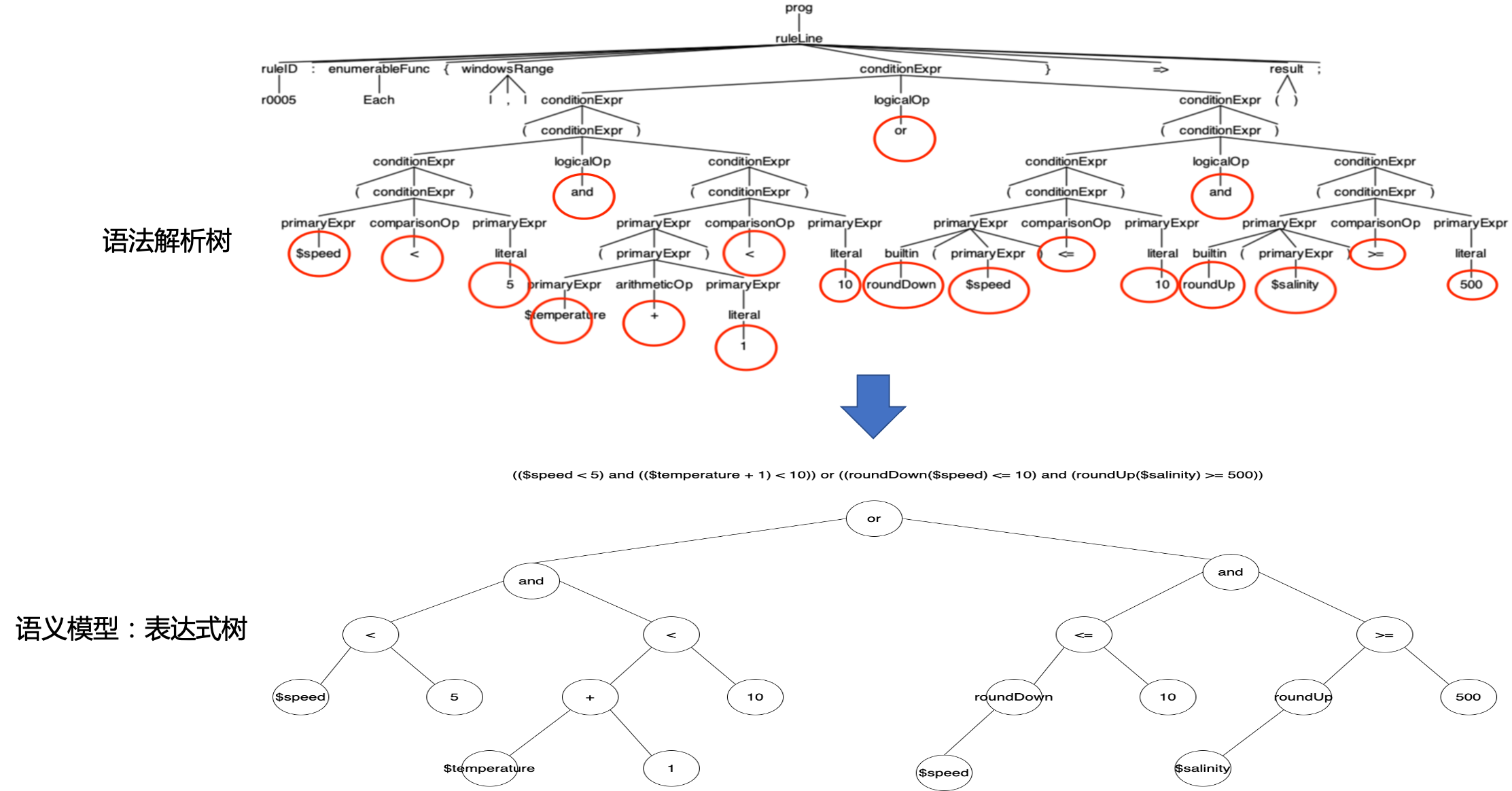
通过上图,我们看到,语法树是为了解析语法而构建的,并非为表达式树计算而构建,如果我们直接基于语法树去做语义计算,一来要多遍历一些无关的符号节点(非红圈里的节点),有额外开销,影响性能;二来这里的tdat使用的conditionExpr并非标准二叉表达式树,我们需要自己设计表达式求值的算法;最后就是Martin Fowler提到的语法解析与语义模型耦合在一起的弊端了。在语义模型不变的情况下,一旦语法结构发生变更,影响的不仅仅是语法树的结构,语义模型的求值行为也要一并改动。
因此这里我们直接将语义模型与语法树分离,我们采用上图中下方的二叉表达式树作为主要语义模型。这样我们就可以单独建立实现和测试该语义模型了。
像上图下方那样的一个典型的二叉表达式树可由一个逆波兰表达式(Reverse Polish notation)构建而成,构建算法可以参考《数据结构与算法分析:C语言描述(原书第2版》的4.2.2小节。
下面我就来简单说说这个表达式树的构建与求值实现。
我们先来建立一个二叉Tree数据结构:
// tdat/semantic/semantic.go
// semantic tree
type Tree interface {
GetParent() Tree
SetParent(Tree)
GetValue() Value
SetLeftChild(Tree) Tree
GetLeftChild() Tree
SetRightChild(Tree) Tree
GetRightChild() Tree
}
type Value interface {
Type() string
Value() interface{}
}
// Node is an implementation of Tree
// and each node can be seen as a tree
type Node struct {
V Value
l *Node // left node
r *Node // right node
p *Node // parent node
}
我们建立了一个二叉树的接口类型,并提供了用于实现该接口类型的结构体类型Node。每个Node是Tree中的一个节点,它自身也可以被看成是一个Tree。树中每个Node都有一个Value,Value也是一个接口类型,它共有四种实现:
- BinaryOperator
二元运算符,包括:二元算术运算符(+、-、*、/、%等)、关系运算符(>、<、>=、<=、==等)和二元逻辑运算符(and与or)。
- UnaryOperator
一元运算符/内置函数,包括:roundUp、roundDown、abs等,可扩展。
- Variable
用于表示数据指标,比如:speed、temperature等。
- Literal
字面值,比如:10、3.1415、”hello”,通常做右值,或与Varible通过二元算术运算符构成表达式。
BinaryOperator和UnaryOperator都属于操作符,而Variable和Literal都属于操作数。这样,一个表达式树就是以操作数为叶子节点,以操作符为其他节点的树。由于树最多是二元操作符,所以表达式树正好是一个二叉树,一元运算符的操作数默认放置在左子节点处。
上面提到过,我们可以基于逆波兰表达式来构建出这样的一棵表达式树,下面就是基于逆波兰表达式构建这棵Tree的实现:
// semantic/semantic.go
// construct a tree based on a reversePolishExpr
func NewFrom(reversePolishExpr []Value) Tree {
var s Stack[Tree]
for _, v := range reversePolishExpr {
switch v.Type() {
case "literal", "variable":
s.Push(&Node{
V: v,
})
case "binop":
rchild, lchild := s.Pop(), s.Pop()
n := &Node{
V: v,
}
n.SetLeftChild(lchild)
n.SetRightChild(rchild)
s.Push(n)
case "unaryop":
lchild := s.Pop()
n := &Node{
V: v,
}
n.SetLeftChild(lchild)
s.Push(n)
}
}
first := s.Pop()
root := &Node{}
root.SetLeftChild(first)
return root
}
在这份实现中,我们借由一个stack缓存子树结点。我们从左向右逐一读取逆波兰表达式中的操作符或操作数:
- 如果读出来的Value是操作数(literal或variable),则将该操作数打包成一个Node(可理解为子树),压到栈中;
- 如果读出来的Value是一个二元操作符,则将从栈中出栈两个节点,分别作为二元操作符节点的左右节点,合并后的子树再压到栈中;
- 如果读出来的Value是一个一元操作符,则从栈中弹出一个节点,作为一元操作符节点的左节点,合并后的子树再压到栈中。
- 栈中最后存放的就是树的最顶层操作符节点,将该节点弹出后作为Root节点的左子节点,表达式树的构造就结束了。而这个Root节点与众不同的特征是其parent为nil(遍历树时会用到)。
构建后的这棵Tree究竟长啥样呢?我们可以通过Dump函数来查看:
func printPrefix(level int) {
for i := 0; i < level; i++ {
if i == level-1 {
fmt.Printf(" |---")
} else {
fmt.Printf(" ")
}
}
}
func Dump(t Tree, order string) {
var f = func(n *Node, level int) {
if n == nil {
return
}
printPrefix(level)
if n.p == nil {
// root node
fmt.Printf("[root]()\n")
} else {
fmt.Printf("[%s](%v)\n", n.V.Type(), n.V.Value())
}
}
switch order {
default:
// preorder
preOrderTraverse(t.(*Node), 0, f, nil)
case "inorder":
inOrderTraverse(t.(*Node), 0, f, nil)
case "postorder":
postOrderTraverse(t.(*Node), 0, f, nil)
}
}
Dump基于树的遍历,提供了以前序(preOrder)、中序(inOrder)和后序(postOrder)遍历方式输出Tree的各个Node的特性。树的遍历是树的基本操作, 以前序遍历为例,看看遍历的实现:
// pre order traverse
func preOrderTraverse(t *Node, level int, enterF func(*Node, int), exitF func(*Node, int)) {
if t == nil {
return
}
if enterF != nil {
enterF(t, level) // traverse this node
}
// traverse left children
preOrderTraverse(t.l, level+1, enterF, exitF)
// traverse right children
preOrderTraverse(t.r, level+1, enterF, exitF)
if exitF != nil {
exitF(t, level) // traverse this node again
}
}
这里借鉴了ANTLR语法解析树的“思路”,在遍历每个Node时都提供enterF和exitF的回调,用于用户自定义遍历Node时的行为。了解了原理后,我们看看基于下面逆波兰表达式:
speed,50,<,temperature,1,+,4,<,and,salinity,roundDown,600,<=,ph,roundUp,8.0,>,or,or
构建的Tree的样子如下:
[root]()
|---[binop](or)
|---[binop](and)
|---[binop](<)
|---[variable](speed)
|---[literal](50)
|---[binop](<)
|---[binop](+)
|---[variable](temperature)
|---[literal](1)
|---[literal](4)
|---[binop](or)
|---[binop](<=)
|---[unaryop](roundDown)
|---[variable](salinity)
|---[literal](600)
|---[binop](>)
|---[unaryop](roundUp)
|---[variable](ph)
|---[literal](8)
一旦Tree构建完毕,我们就可以基于该Tree进行求值了。下面是求值函数Evaluate的实现:
func Evaluate(t Tree, m map[string]interface{}) (result bool, err error) {
var s Stack[Value]
defer func() {
// extract error from panic
if x := recover(); x != nil {
result, err = false, fmt.Errorf("eval error: %v", x)
return
}
}()
var exitF = func(n *Node, level int) {
if n == nil {
return
}
if n.p == nil {
// root node
return
}
v := n.GetValue()
switch v.Type() {
case "binop":
rhs, lhs := s.Pop(), s.Pop()
s.Push(evalBinaryOpExpr(v.Value().(string), lhs, rhs))
case "unaryop":
lhs := s.Pop()
s.Push(evalUnaryOpExpr(v.Value().(string), lhs))
case "literal":
s.Push(v)
case "variable":
name := v.Value().(string)
value, ok := m[name]
if !ok {
panic(fmt.Sprintf("not found variable: %s", name))
}
// use the value in map to replace variable
s.Push(&Literal{
Val: value,
})
}
}
preOrderTraverse(t.(*Node), 0, nil, exitF)
result = s.Pop().Value().(bool)
return
}
虽然这里用的是preOrderTraverse,但我们是在exitF回调中做的计算,因此这里等价于一个标准的树的后序遍历。每当遇到操作数,就入栈;当操作数为variable时,在输入参数中map中查找该variable是否存在,如存在,则将值压入栈。每当遇到操作符,则将操作数弹栈计算后,再入栈。如此,最终栈内仅保存一个值,就是这个表达式树的计算结果。
三. 验证语义模型之表达式树
前面说过,语义模型与语法树分离后,我们可以对语义模型进行单独测试,下面就是一个简单的基于表驱动的对表达式树的单元测试:
// tdat/semantic/semantic_test.go
func TestNewFrom(t *testing.T) {
//($speed < 50) and (($temperature + 1) < 4) or ((roundDown($salinity) <= 600.0) or (roundUp($ph) > 8.0))
// speed,50,<,temperature,1,+,4,<,and,salinity,roundDown,600,<=,ph,roundUp,8.0,>,or,or
var reversePolishExpr []Value
reversePolishExpr = append(reversePolishExpr, newVariable("speed"))
reversePolishExpr = append(reversePolishExpr, newLiteral(50))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("<"))
reversePolishExpr = append(reversePolishExpr, newVariable("temperature"))
reversePolishExpr = append(reversePolishExpr, newLiteral(1))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("+"))
reversePolishExpr = append(reversePolishExpr, newLiteral(4))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("<"))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("and"))
reversePolishExpr = append(reversePolishExpr, newVariable("salinity"))
reversePolishExpr = append(reversePolishExpr, newUnaryOperator("roundDown"))
reversePolishExpr = append(reversePolishExpr, newLiteral(600.0))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("<="))
reversePolishExpr = append(reversePolishExpr, newVariable("ph"))
reversePolishExpr = append(reversePolishExpr, newUnaryOperator("roundUp"))
reversePolishExpr = append(reversePolishExpr, newLiteral(8.0))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator(">"))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("or"))
reversePolishExpr = append(reversePolishExpr, newBinaryOperator("or"))
tree := NewFrom(reversePolishExpr)
Dump(tree, "preorder")
// test table
var cases = []struct {
id string
m map[string]interface{}
expected bool
}{
//($speed < 50) and (($temperature + 1) < 4) or ((roundDown($salinity) <= 600.0) or (roundUp($ph) > 8.0))
{
id: "0001",
m: map[string]interface{}{
"speed": 30,
"temperature": 6,
"salinity": 700.0,
"ph": 7.0,
},
expected: false,
},
{
id: "0002",
m: map[string]interface{}{
"speed": 30,
"temperature": 1,
"salinity": 500.0,
"ph": 7.0,
},
expected: true,
},
{
id: "0003",
m: map[string]interface{}{
"speed": 60,
"temperature": 10,
"salinity": 700.0,
"ph": 9.0,
},
expected: true,
},
{
id: "0004",
m: map[string]interface{}{
"speed": 30,
"temperature": 1,
"salinity": 700.0,
"ph": 9.0,
},
expected: true,
},
}
for _, caze := range cases {
r, err := Evaluate(tree, caze.m)
if err != nil {
t.Errorf("[case %s]: want nil, actual %s", caze.id, err.Error())
}
if r != caze.expected {
t.Errorf("[case %s]: want %v, actual %v", caze.id, caze.expected, r)
}
}
}
上面是语义模型中最复杂的部分,但不是全部,还有windowRange、enumableFunc以及result,下面我们就来建立tdat的完整的语义模型。
四. 建立完整的语义模型
前面我们已经解决掉了语义模型中最复杂的部分:conditionExpr。下面我们就把完整的语义模型实现出来,我们定义一个Model结构体来表示语义模型:
// tdat/semantic/semantic.go
type WindowsRange struct {
low int
high int
}
type Model struct {
// conditionExpr
t Tree
// windowsRange
wr WindowsRange
// enumerableFunc
ef string
// result
result []string
}
我们看到Model本质上就是conditionExpr、WindowsRange、enumerableFunc和result这几个影响执行结果的元素的聚合,因此Model的创建函数也比较简单:
func NewModel(reversePolishExpr []Value, wr WindowsRange, ef string, result []string) *Model {
m := &Model{
t: NewFrom(reversePolishExpr),
wr: wr,
ef: ef,
result: result,
}
return m
}
我们重点看一下Model的语义执行方法Exec:
// tdat/semantic/semantic.go
func (m *Model) Exec(metrics []map[string]interface{}) (map[string]interface{}, error) {
var res []bool
for i := m.wr.low - 1; i <= m.wr.high-1; i++ {
r, err := Evaluate(m.t, metrics[i])
if err != nil {
return nil, err
}
res = append(res, r)
}
andRes := res[0]
orRes := res[0]
for i := 1; i < len(res); i++ {
andRes = andRes && res[i]
orRes = orRes || res[i]
}
switch m.ef {
case "any":
if orRes {
return m.outputResult(metrics[0])
}
return nil, ErrNotMeetAny
case "none":
if andRes == false {
return m.outputResult(metrics[0])
}
return nil, ErrNotMeetNone
case "each":
if andRes == true {
return m.outputResult(metrics[0])
}
return nil, ErrNotMeetEach
default:
return nil, ErrNotSupportFunc
}
}
这里的实现并非“性能最优”,但逻辑清晰:Exec会使用表达式树对迭代窗口(从low到high)中的每个元素进行求值,求值结果放入一个切片,然后再针对这个切片,求所有元素的逻辑与(andRes)与逻辑或(orRes),再结合enumerableFunc的类型综合判断出是否要输出最新的那条metric。
关于Model的验证与表达式树差不多,限于篇幅这里就不赘述了,大家可以参考semantic_test.go中的测试case demo。
五. 小结
在这一部分内容中,我们为DSL建立了语义模型,tdat语义模型的核心是表达式树,因此我们重点讲了基于逆波兰式创建表达式树的方法、表达式树的求值方法以及表达式树的验证。最后,我们建立了一个名为semantic.Model的完整模型。
在下一篇文章中,我们将讲解如何基于DSL的语法树提取逆波兰式,并组装语义模型,把DSL的前后端串起来,让我们的语法示例可以真正run起来。
本文中涉及的代码可以在这里下载 – https://github.com/bigwhite/experiments/tree/master/antlr/tdat 。
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2022年,Gopher部落全面改版,将持续分享Go语言与Go应用领域的知识、技巧与实践,并增加诸多互动形式。欢迎大家加入!



我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 微信公众号:iamtonybai
- 博客:tonybai.com
- github: https://github.com/bigwhite
- “Gopher部落”知识星球:https://public.zsxq.com/groups/51284458844544

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。