
本文永久链接 – https://tonybai.com/2022/05/25/an-example-of-implement-dsl-using-antlr-and-go-part2
在本系列的第一篇文章《手把手教你使用ANTLR和Go实现一门DSL语言:设计DSL语法与文法》中,我们已经为气象学家们设计了一门DSL,建立了语法样例,并用ANTLR4文法将DSL定义了出来。按照外部DSL设计与实现的工作流,在这一篇中,我们将对上一篇设计的DSL文法进行验证,看看ANTLR基于我们设计的文法是否能成功生成解析器代码,并且基于生成的解析器是否可以成功处理我们编写的语法样例。
ANTLR文法验证可分为两个阶段,我们分别来看一下。
一. 验证ANTLR是否能解析我们定义的文法(Tdat.g4)
验证ANTLR是否能解析我们的文法Tdat.g4的过程也是通过antlr4尝试生成DSL语法解析器代码的过程,如果顺利生成目标代码,没有报错,则说明我们的Tdat.g4文法至少是符合ANTLR4对文法的要求的。一旦成功,ANTLR就会在特定目录下生成你期望的语法的解析器(parser)代码,比如下面命令将Tdat.g4文法生成目标代码为Go的解析器实现,生成的Go代码位于当前目录下的parser目录下。
$antlr4 -Dlanguage=Go -o parser Tdat.g4
在这个过程中,除了语法错误(比如没用分号结尾,缺少冒号等),我们常会遇到两类错误。
一类是Parser rule的间接左递归问题,比如下面这个例子:
// Demo2.g4
grammar Demo2;
expr1 : expr2;
expr2 : expr1 '+' expr3
| '(' expr2 ')'
;
expr3 : INT;
INT: DIGIT+;
DIGIT: [0-9];
使用antlr基于上面Demo2.g4生成parser代码,我们会得到下面错误提示:
$antlr4 -Dlanguage=Go -o parser Demo2.g4
error(119): Demo2.g4::: The following sets of rules are mutually left-recursive [expr1, expr2]
以Demo2.g4为例,所谓“间接左递归”,就是expr1产生式中包含expr2,而expr2的产生式规则中又包含了expr1,这种情况Antlr是无法处理的。那么我们需要消除这种“间接左递归”,最直接的方法就是将文法改为“直接左递归”,如下面改后的文法:
grammar Demo2;
expr1 : expr1 '+' expr3
| '(' expr1 ')'
;
expr3 : INT;
INT: DIGIT+;
DIGIT: [0-9];
这里把expr2这一中间rule去掉了!expr1的产生式中直接包含自己,这种直接左递归是antlr可以支持的。
另一类是词法规则生成式相同导致的归约歧义。这里antlr不会给出error,而会以warning形式提醒开发者。比如下面例子:
grammar Demo1;
prog: expr
| expr1
;
expr: DIGIT AND DIGIT;
expr1: DIGIT MASK DIGIT;
AND : '&' ;
MASK : '&' ;
DIGIT: [0-9];
antlr处理这个文法时,会提示如下warning:
warning(184): Demo1.g4:14:0: One of the token MASK values unreachable. & is always overlapped by token AND
意思是MASK这个词法规则总是会被AND这个词法规则所遮蔽,或者说通过这个文法总是能识别到expr,而无法识别并归约到expr1这个规则。这个问题与具体文法设计相关,解决方法可参考ANTLR提供的词法规则说明。
不过,即便基于你的文法成功生成Parser代码,也不代表你的文法没有逻辑错误。我们需要通过一些语法样例来验证生成的Parser是否能正确解析我们的语法样例。
二. 验证生成的Parser代码是否能正确解析我们的语法样例
第二阶段的验证有两种方法,最简单的就是使用antlr提供的工具grun。这里我将grun的相关命令打包到一个Makefile中:
// Makefile for debugging Tdat.g4
antlr4_exe = java -jar /usr/local/lib/antlr-4.10.1-complete.jar
grun_exe = java org.antlr.v4.gui.TestRig
target =
all:
go build
gen:
$(antlr4_exe) -Dlanguage=Go -o parser Tdat.g4
gen_visitor:
$(antlr4_exe) -Dlanguage=Go -visitor -o parser Tdat.g4
gen_java:
$(antlr4_exe) Tdat.g4
gui: gen_java
javac *.java
$(grun_exe) Tdat prog $(target) -gui
trace: gen_java
javac *.java
$(grun_exe) Tdat prog $(target) -trace
tokens: gen_java
javac *.java
$(grun_exe) Tdat prog $(target) -tokens
tree: gen_java
javac *.java
$(grun_exe) Tdat prog $(target) -tree
clean:
rm -fr *.java *.class tdat
由于grun依赖于基于Tdat.g4生成的java parser代码,所以每个调试命令,如debug、trace、tokens等都需要依赖对应的Java的代码生成。
对于同归属于视觉动物的人类来说,我推荐你先使用图形化选项(gui)对语法样例的解析进行调试,我们以下面的最简单的samples/sample1.t为例:
// samples/sample1.t
r0001: Each { || $speed > 30 } => ("speed", "temperature", "salinity");
我们执行下面命令:
$make gui target=samples/sample1.t
java -jar /usr/local/lib/antlr-4.10.1-complete.jar Tdat.g4
javac *.java
java org.antlr.v4.gui.TestRig Tdat prog samples/sample1.t -gui
... ...
上述命令会打开一个新窗口,显示解析后的语法树:
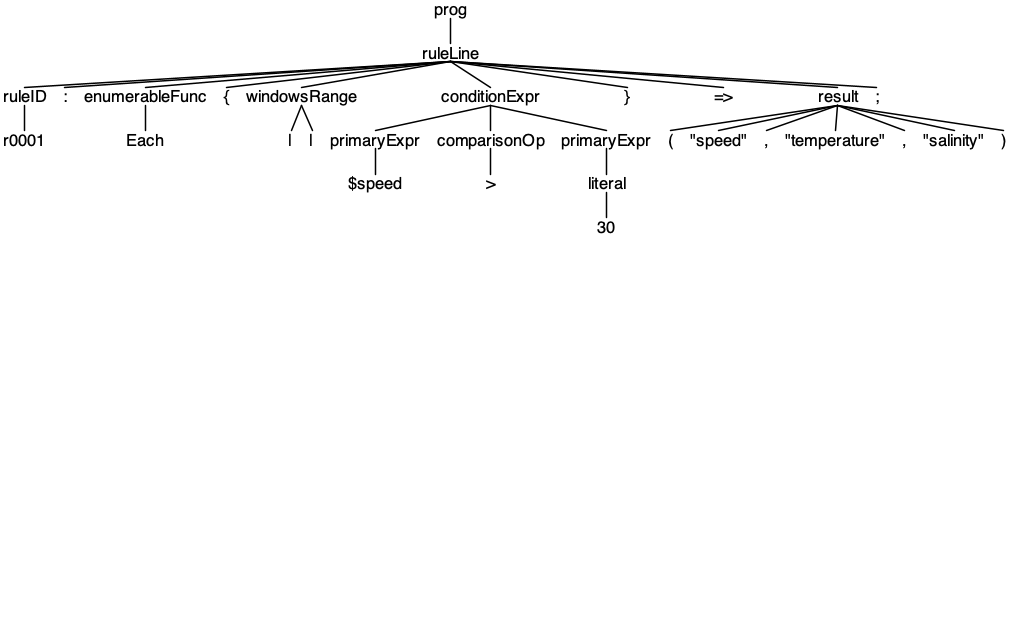
很幸运!基于Tdat.g4文法生成的Parser可以正确解析sample1.t。
某些时候我们需要查看字符序列被解析为词法元素token的过程,以验证字符序列是否都被正确识别,我们可以通过make tokens来实现:
$make tokens target=samples/sample1.t
java -jar /usr/local/lib/antlr-4.10.1-complete.jar Tdat.g4
javac *.java
java org.antlr.v4.gui.TestRig Tdat prog samples/sample1.t -tokens
[@0,12:16='r0001',<ID>,3:0]
[@1,17:17=':',<':'>,3:5]
[@2,19:22='Each',<'Each'>,3:7]
[@3,24:24='{',<'{'>,3:12]
[@4,26:26='|',<'|'>,3:14]
[@5,27:27='|',<'|'>,3:15]
[@6,29:34='$speed',<METRIC>,3:17]
[@7,36:36='>',<'>'>,3:24]
[@8,38:39='30',<INT>,3:26]
[@9,41:41='}',<'}'>,3:29]
[@10,43:44='=>',<'=>'>,3:31]
[@11,46:46='(',<'('>,3:34]
[@12,47:53='"speed"',<STRING>,3:35]
[@13,54:54=',',<','>,3:42]
[@14,56:68='"temperature"',<STRING>,3:44]
[@15,69:69=',',<','>,3:57]
[@16,71:80='"salinity"',<STRING>,3:59]
[@17,81:81=')',<')'>,3:69]
[@18,82:82=';',<';'>,3:70]
[@19,84:83='<EOF>',<EOF>,4:0]
通过上述的每一行,我们都可以看到一个token被解析出来,匹配的是哪条词法规则。以第一行为例:”r0001″被解析出来,成功匹配ID这个token规则。
如果要结合parser规则一并查看匹配规则的步骤,可以用trace命令,通过这个命令的详细输出我们可以对parser规则匹配异常的情况进行诊断:
$make trace target=samples/sample1.t
java -jar /usr/local/lib/antlr-4.10.1-complete.jar Tdat.g4
javac *.java
java org.antlr.v4.gui.TestRig Tdat prog samples/sample1.t -trace
enter prog, LT(1)=r0001
enter ruleLine, LT(1)=r0001
enter ruleID, LT(1)=r0001
consume [@0,12:16='r0001',<33>,3:0] rule ruleID
exit ruleID, LT(1)=:
consume [@1,17:17=':',<1>,3:5] rule ruleLine
enter enumerableFunc, LT(1)=Each
consume [@2,19:22='Each',<6>,3:7] rule enumerableFunc
exit enumerableFunc, LT(1)={
consume [@3,24:24='{',<2>,3:12] rule ruleLine
enter windowsRange, LT(1)=|
consume [@4,26:26='|',<9>,3:14] rule windowsRange
consume [@5,27:27='|',<9>,3:15] rule windowsRange
exit windowsRange, LT(1)=$speed
enter conditionExpr, LT(1)=$speed
enter primaryExpr, LT(1)=$speed
consume [@6,29:34='$speed',<34>,3:17] rule primaryExpr
exit primaryExpr, LT(1)=>
enter comparisonOp, LT(1)=>
consume [@7,36:36='>',<24>,3:24] rule comparisonOp
exit comparisonOp, LT(1)=30
enter primaryExpr, LT(1)=30
enter literal, LT(1)=30
consume [@8,38:39='30',<35>,3:26] rule literal
exit literal, LT(1)=}
exit primaryExpr, LT(1)=}
exit conditionExpr, LT(1)=}
consume [@9,41:41='}',<3>,3:29] rule ruleLine
consume [@10,43:44='=>',<4>,3:31] rule ruleLine
enter result, LT(1)=(
consume [@11,46:46='(',<11>,3:34] rule result
consume [@12,47:53='"speed"',<37>,3:35] rule result
consume [@13,54:54=',',<10>,3:42] rule result
consume [@14,56:68='"temperature"',<37>,3:44] rule result
consume [@15,69:69=',',<10>,3:57] rule result
consume [@16,71:80='"salinity"',<37>,3:59] rule result
consume [@17,81:81=')',<12>,3:69] rule result
exit result, LT(1)=;
consume [@18,82:82=';',<5>,3:70] rule ruleLine
exit ruleLine, LT(1)=<EOF>
exit prog, LT(1)=<EOF>
上面这个r0001的逻辑比较简单,我们再来一个复杂的:
//samples/sample2.t
r0002: None { |,30| $temperature > 5 } => ("speed", "temperature", "salinity");
r0005: Each { |,| (($speed < 5) and (($temperature + 1) < 10)) or ((roundDown($speed) <= 10) and (roundUp($salinity) >= 500))} => ();
我们用gui形式输出语法树:
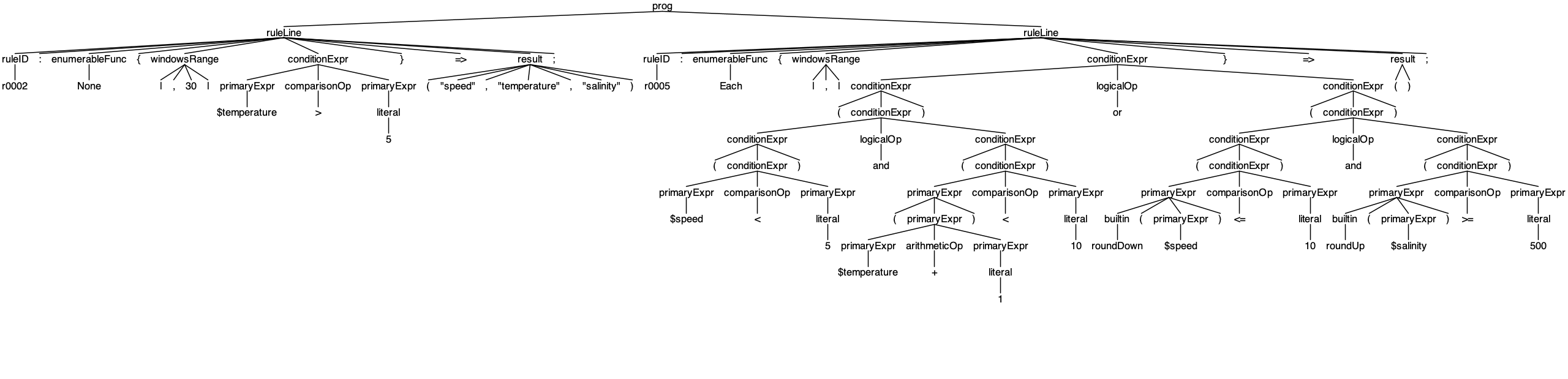
我们看到,虽然sample2.t中的源码逻辑变复杂了,但我们生成的Parser依旧可以成功将其解析为语法树。
如果你觉得grun提供的这些工具的输出都不符合你的胃口,那么好吧,你可以自己动手基于Listener方式自己写你的调试工具,最简单的逻辑:我们遍历一遍Parser生成的语法树,看看语法树每个节点是否符合我们的预期。
Antlr的Go runtime提供了一个TraceListener的结构,从名字上来看似乎是可以遍历语法树,对Node做trace的。但试用后发现总出panic,不知道是不是用法的问题。
不过自己写一个也不麻烦,我们建立一个trace_listener.go,这个listener将遍历语法树所有节点并按我们期望的格式输出相关信息:
package main
import (
"fmt"
"tdat/parser"
"github.com/antlr/antlr4/runtime/Go/antlr"
)
type TraceListener struct {
*parser.BaseTdatListener
p *parser.TdatParser
t antlr.Tree
}
func NewTraceListener(p *parser.TdatParser, t antlr.Tree) *TraceListener {
return &TraceListener{
p: p,
t: t,
}
}
func (l *TraceListener) EnterEveryRule(ctx antlr.ParserRuleContext) {
printLevelPrefix(ctx)
i := ctx.GetRuleIndex()
ruleName := l.p.RuleNames[i]
fmt.Printf("==> %s 《 %s 》\n", ruleName, ctx.GetText())
}
func (l *TraceListener) ExitEveryRule(ctx antlr.ParserRuleContext) {
printLevelPrefix(ctx)
i := ctx.GetRuleIndex()
ruleName := l.p.RuleNames[i]
fmt.Println("<==", ruleName)
}
antlr的listener默认对语法树进行前序遍历,antlr go runtime中的ParseTreeListener接口包含EnterEveryRule和ExitEveryRule两个方法:
type ParseTreeListener interface {
VisitTerminal(node TerminalNode)
VisitErrorNode(node ErrorNode)
EnterEveryRule(ctx ParserRuleContext)
ExitEveryRule(ctx ParserRuleContext)
}
在遍历过程中,这两个方法分别会在进入某节点以及结束遍历某节点时被调用,我们可以在我们的Listener接口实现中重写这两个方法来提取遍历的树的所有节点的信息。
现在我们提供一个main函数来驱动这个调试过程:
func main() {
println("input file:", os.Args[1])
input, err := antlr.NewFileStream(os.Args[1])
if err != nil {
panic(err)
}
lexer := parser.NewTdatLexer(input)
stream := antlr.NewCommonTokenStream(lexer, 0)
p := parser.NewTdatParser(stream)
tree := p.Prog()
antlr.ParseTreeWalkerDefault.Walk(NewTraceListener(p, tree), tree)
}
编译运行上面程序:
$make
go build
$./tdat samples/sample1.t
input file: samples/sample1.t
==> prog 《 r0001:Each{||$speed>30}=>("speed","temperature","salinity"); 》
==> ruleLine 《 r0001:Each{||$speed>30}=>("speed","temperature","salinity"); 》
==> ruleID 《 r0001 》
<== ruleID
==> enumerableFunc 《 Each 》
<== enumerableFunc
==> windowsRange 《 || 》
<== windowsRange
==> conditionExpr 《 $speed>30 》
==> primaryExpr 《 $speed 》
<== primaryExpr
==> comparisonOp 《 > 》
<== comparisonOp
==> primaryExpr 《 30 》
==> literal 《 30 》
<== literal
<== primaryExpr
<== conditionExpr
==> result 《 ("speed","temperature","salinity") 》
<== result
<== ruleLine
<== prog
这里我用了一种带缩进的格式来查看整个遍历过程以及遍历的每个节点的信息,如果你有你期望输出的格式,可以修改上面的EnterEveryRule和ExitEveryRule方法的实现,总之,怎么方便怎么高效就怎么来!
一些童鞋会问,文法确定了,语法确定了,Parser也可以成功生成,那么还会有解析错误的情况么?这个肯定是有的,笔者在开发的过程中就遇到因词法规则顺序的问题导致语法规则匹配错误的情况,下面就是一个例子:
// Demo.g4
grammar Demo;
prog
: prule1
| prule2
;
prule1
: 'repeat' INT
;
prule2
: 'repeat' NONZEROINT
;
NONZEROINT
: [1-9](DIGIT)*
;
INT
: DIGIT+
;
fragment
DIGIT
: [0-9] // match single digit
;
LINE_COMMENT
: '//' .*? '\r'? '\n' -> skip
;
COMMENT
: '/*' .*? '*/' -> skip
;
WS
: [ \t\r\n]+ -> skip
;
我们用下面语法测试基于上面Demo.g4生成的Parser:
//sample1.t
repeat 15
我们期望其匹配到的规则为prule1,但实际情况是:
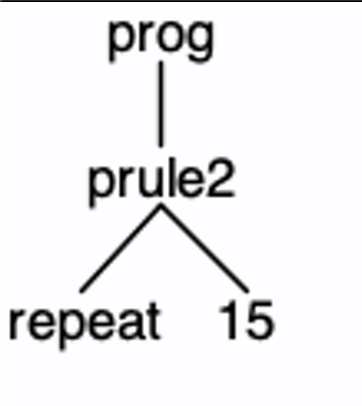
grun -gui的输出结果是Parser匹配到了prule2!这是怎么回事呢?我们用grun -tokens再来看看词法规则匹配的情况:
$grun Demo prog samples/sample1.t -tokens
[@0,1:6='repeat',<'repeat'>,2:0]
[@1,8:9='15',<NONZEROINT>,2:7]
[@2,11:10='<EOF>',<EOF>,3:0]
我们发现15这个数字匹配到了NONZEROINT这个词法规则,而不是INT。这是因为ANTLR默认优先匹配排在前面的词法规则。于是在parser规则层面匹配到prule2就不足为奇了。
这只是一个“故意制造”的例子,即便不用Parser,我们也能“肉眼”识别文法中的问题。但在真实的复杂的语法解析器验证时,这样的未按预期匹配的情况也是很常见的,而且是肉眼难于分辨的,我们需要利用grun提供的工具去仔细诊断。
三. 小结
在这一篇中,我们通过ANTLR提供的工具对编写的文法规则进行了验证,并进一步验证了基于该文法生成的Parser是否可以解析我们设计的所有语法样例。
好了,现在我们已经可以成功将语法样例解析并转换为内存中的一颗语法树了?那么有了这棵树后,我们怎么实现需求中的表达式求值、指标计算与输出呢?
在下一篇文章中,我将和大家一起学习如何从语法树中提取我们的语义模型,并对语义模型进行测试验证。
本文中涉及的代码可以在这里下载 – https://github.com/bigwhite/experiments/tree/master/antlr/tdat 。
“Gopher部落”知识星球旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2022年,Gopher部落全面改版,将持续分享Go语言与Go应用领域的知识、技巧与实践,并增加诸多互动形式。欢迎大家加入!




我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/。smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。2020年4月8日,中国三大电信运营商联合发布《5G消息白皮书》,51短信平台也会全新升级到“51商用消息平台”,全面支持5G RCS消息。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 – https://github.com/bigwhite/gopherdaily
我的联系方式:
- 微博:https://weibo.com/bigwhite20xx
- 微信公众号:iamtonybai
- 博客:tonybai.com
- github: https://github.com/bigwhite
- “Gopher部落”知识星球:https://public.zsxq.com/groups/51284458844544

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。