近期learnk8s网站上发布了一些关于k8s的好文章,这里搬运并翻译了一些,供大家参考。
本文翻译自《Architecting Kubernetes clusters — choosing a worker node size》。

当您创建Kubernetes集群时,冒出的第一个问题之一是:“我应该使用哪种类型的工作节点以及需要多少个这样的节点”。
如果您正在构建在内部部署的k8s集群,是应该订购一些最近一代的新服务器,还是使用数据中心内的十几台旧机器?
或者,如果您使用Google Kubernetes Engine(GKE)等托管Kubernetes服务,您是否应该使用八个n1-standard-1或两个n1-standard-4实例来实现所需的计算能力呢?
集群容量
通常,Kubernetes集群可以被视为将一组单个节点抽象为一个大的“超级节点”。
该超级节点的总计算容量(就CPU和内存而言)是所有组成节点容量的总和。
有多种方法可以实现集群的所需目标容量。
例如,假设您需要一个总容量为8个CPU内核和32 GB RAM的集群。
例如,因为要在集群上运行的应用程序集需要如此数量的资源。
以下是设计集群的两种可能方法:
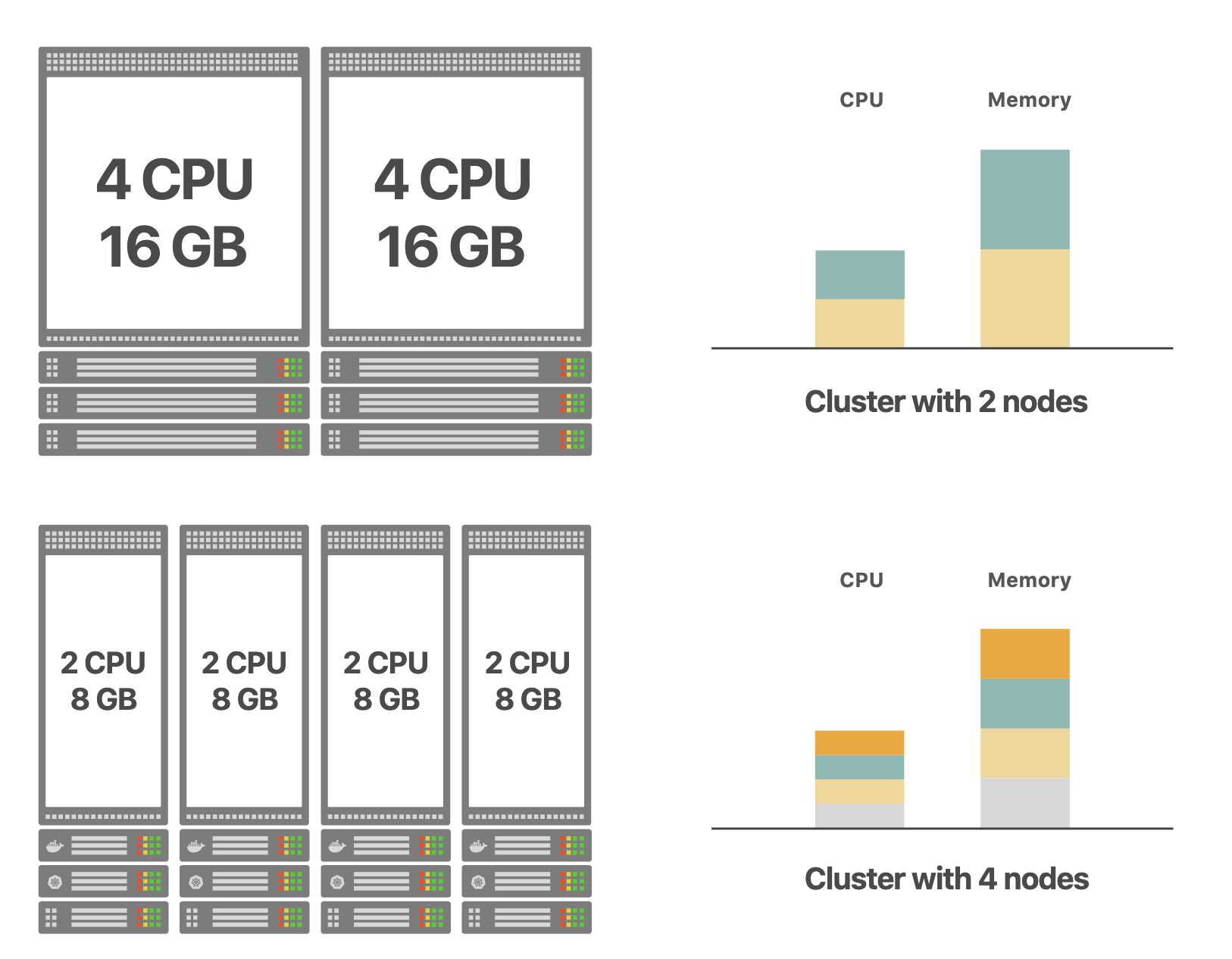
这两个选项都会产生具有相同容量的集群 – 但左侧选项使用4个较小的节点,而右侧选项使用2个较大的节点。
哪个更好?
为了解决这个问题,让我们来看看“少数大节点”和“许多小节点”这两个相反方向思路的优缺点。
请注意,本文中的“节点”始终指的是工作节点(worker node)。master节点的数量和大小的选择是完全不同的话题。
使用少量大节点
这方面最极端的情况是仅使用一个可以提供整个所需集群容量的工作节点。
如果要满足上面的示例中容量的需求,这将是一个具有16个CPU内核和16 GB RAM的单个工作节点。
让我们来看看这种方法可能具有的优势。
1. 减少管理成本
简单地说,管理少量机器比管理大量机器要更省力。
更新和补丁可以更快地应用,机器可以更容易保持同步。
此外,对于机器数量少而言,预期故障的绝对数量要小于机器数量多的情况。
但请注意,这主要适用于裸机服务器而不适用于云实例。
如果您使用云实例(作为托管Kubernetes服务的一部分或您在云基础架构上安装的Kubernetes),则将底层机器的管理外包给云提供商。
因此,管理云中的10个节点并不比管理云中的单个节点成本多得多。
2. 每个节点的成本更低
虽然更强大的机器比低端机器更昂贵,但价格上涨不一定是线性的。
换句话说,具有10个CPU内核和10 GB RAM的单台机器可能比具有1个CPU内核和1 GB RAM的10台机器便宜。
但请注意,如果您使用云实例,这可能同样不适用。
在主要云提供商Amazon Web Services,Google Cloud Platform和Microsoft Azure的当前定价方案中,实例价格是随容量线性增加的。
例如,在Google Cloud Platform上,64个n1-standard-1实例的成本与单个n1-standard-64实例完全相同- 两个选项都为您提供64个CPU内核和240 GB内存。
因此,在云中,您通常无法通过使用更大的机器来节省成本。
3. 允许运行资源消耗较大的应用程序
拥有大型节点可能只是您要在集群中运行一类应用程序的要求。
例如,如果您有一台需要8 GB内存的机器学习应用程序,你无法在仅具有1 GB内存的节点的集群上运行它。
但是,您可以在具有10 GB内存节点的群集上运行它。
看过优势后,让我们再来看看其弊端又是什么。
1. 每个节点有大量的pod
在较少的节点上运行相同的工作负载自然意味着在每个节点上运行更多的pod。
这可能成为一个问题。
原因是每个pod都会在节点上运行的Kubernetes代理上引入一些开销 – 例如容器运行时(例如Docker),kubelet和cAdvisor。
例如,kubelet对节点上的每个容器执行常规活动和就绪探测 – 更多容器意味着在每次迭代中kubelet需要做更多的工作。
cAdvisor收集节点上所有容器的资源使用统计信息,并且kubelet定期查询此信息并通过其API发布它 – 再次,这意味着每次迭代中cAdvisor和kubelet的工作量都会增加。
如果pod的数量变大,这些东西可能会开始减慢系统速度,甚至使系统变得不可靠。
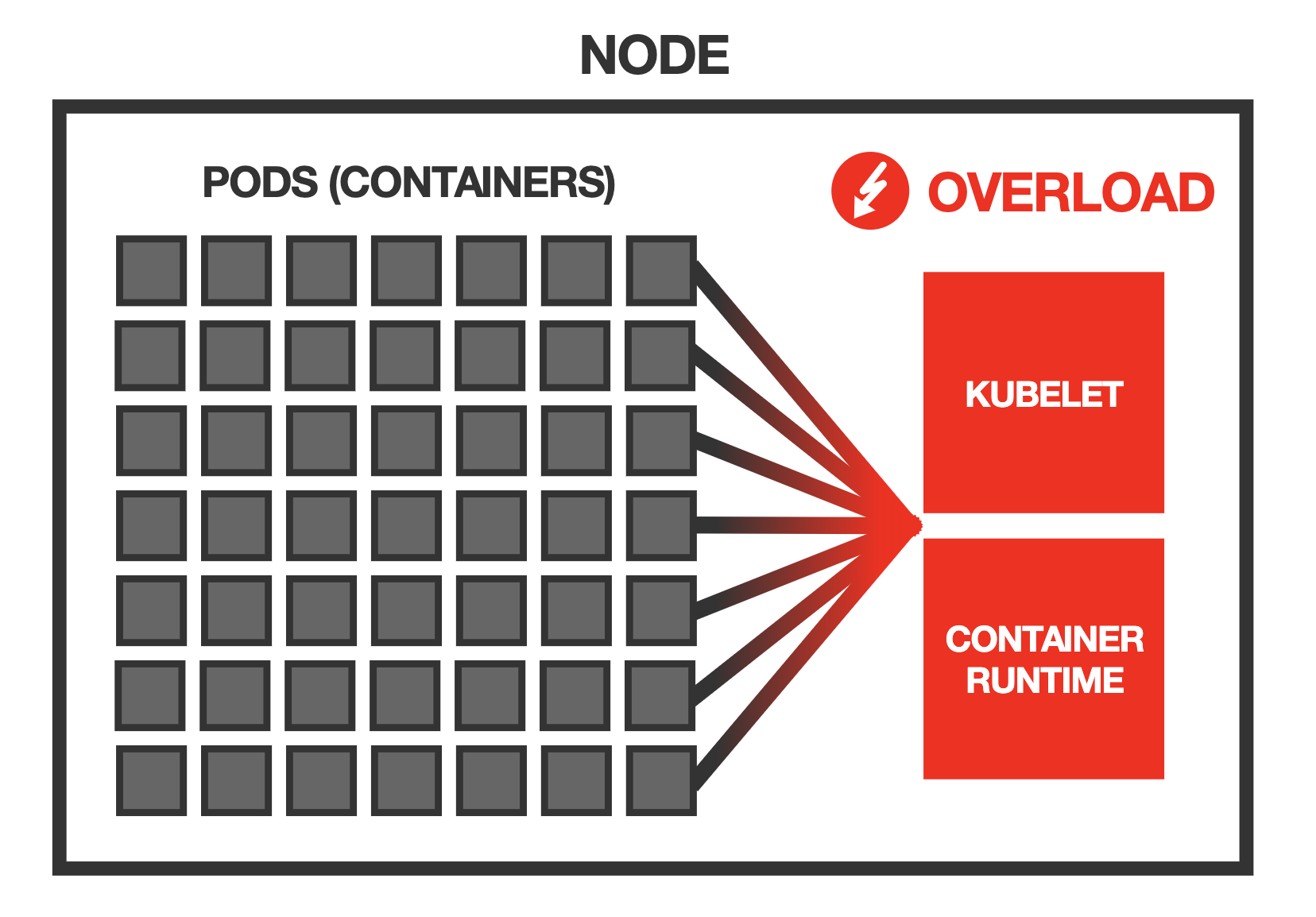
有issue称节点因常规的kubelet运行状况检查花费了太长时间来迭代节点上的所有容器而导致节点处于非就绪状态。
出于这些原因,Kubernetes 建议每个节点最多110个pod。
针对这个数字,Kubernetes已经做过测试,结果证明是可以在通常节点类型上可靠地工作的。
根据节点的性能,您可能能够成功地为每个节点运行更多的pod – 但这依然很难预测事情是否会顺利运行,又或您将遇到问题。
大多数托管Kubernetes服务甚至对每个节点的pod数量施加了严格的限制:
- 在Amazon Elastic Kubernetes Service(EKS)上,每个节点的最大pod数取决于节点类型,范围从4到737。
- 在Google Kubernetes Engine(GKE)上,无论节点类型如何,每个节点的限制为100个pod。
- 在Azure Kubernetes服务(AKS)上,默认限制是每个节点30个pod,但最多可以增加到250个。
因此,如果您计划为每个节点运行大量pod,则应该事先测试事情是否能按预期工作。
2. 有限的复制
少量节点可能会限制应用程序的有效复制程度。
例如,如果您有一个由5个副本组成的高可用性应用程序,但您只有2个节点,那么应用程序的有效复制程度将减少到2。
这是因为5个副本只能分布在2个节点上,如果其中一个失败,它可能会同时删除多个副本。
另一方面,如果您有至少5个节点,则理想情况下每个副本可以在单独的节点上运行,并且单个节点的故障最多只会删除一个副本。
因此,如果您具有高可用性要求,则可能需要对集群中的最小节点数提出要求。
3. 更大的爆破半径
如果您只有几个节点,那么失败节点的影响比您有许多节点的影响要大。
例如,如果您只有两个节点,并且其中一个节点出现故障,那么大约一半的节点会消失。
Kubernetes可以将失败节点的工作负载重新安排到其他节点。
但是,如果您只有几个节点,则风险更高,因为剩余节点上没有足够的备用容量来容纳故障节点的所有工作负载。
结果是,部分应用程序将永久停机,直到再次启动故障节点。
因此,如果您想减少硬件故障的影响,您可能希望选择更多的节点。
4. 大比例增量
Kubernetes 为云基础架构提供了一个Cluster Autoscaler,允许根据当前需求自动添加或删除节点。
如果使用大型节点,则会有大的缩放增量,这会使缩放更加笨重。
例如,如果您只有2个节点,则添加其他节点意味着将群集容量增加50%。
这可能比您实际需要的多得多,这意味着您需要为未使用的资源付费。
因此,如果您计划使用集群自动缩放,则较小的节点允许更流畅且经济高效的缩放行为。
在讨论了使用”很少几个大节点”的方案的优缺点之后,让我们转向”许多小节点”的场景。
使用大量小节点
这种方法包括从许多小节点而不是几个大节点中形成集群。
这种方法的优点和缺点是什么?
使用许多小节点的优点主要对应于使用少量大节点的缺点。
1. 较小的爆破半径
如果您有更多节点,则每个节点上的pod自然会更少。
例如,如果您有100个pod和10个节点,则每个节点平均只包含10个pod。
因此,如果其中一个节点发生故障,则影响仅限于总工作负载的较小比例。
有可能只有一些应用程序受到影响,并且可能只有少量副本,因此整个应用程序都会保持运行状态。
此外,剩余节点上的备用资源很可能足以容纳故障节点的工作负载,因此Kubernetes可以重新安排所有pod,并且您的应用程序可以相对快速地返回到完全正常运行的状态。
2. 允许高可复制性
如果您有高可用性需求的应用程序和足够的可用节点,Kubernetes调度程序可以将每个副本分配给不同的节点。
您可以通过节点亲缘关系,pod亲和力/反亲和力以及taint和tolerations来影响调度程序对pod放置位置的选择。
这意味着如果某个节点出现故障,则最多只有一个副本受影响且您的应用程序仍然可用。
看到使用许多小节点的优点,那它有什么缺点呢?
1. 节点数量大
如果使用容量较小的节点,则自然需要更多节点来实现给定的集群容量。
但是大量节点对Kubernetes控制平面来说可能是一个挑战。
例如,每个节点都需要能够与每个其他节点通信,这使得可能的通信路径数量以节点数量的平方的量级增长 – 所有节点都必须由控制平面管理。
Kubernetes控制器管理器中的节点控制器定期遍历集群中的所有节点以运行运行状况检查 – 更多节点意味着节点控制器的负载更多。
更多节点意味着etcd数据库上的负载也更多 – 每个kubelet和kube-proxy都会导致etcd的观察者(watch)客户端(通过API服务器),etcd必须广播对象更新。
通常,每个工作节点都会给主节点上的系统组件增加一些开销。
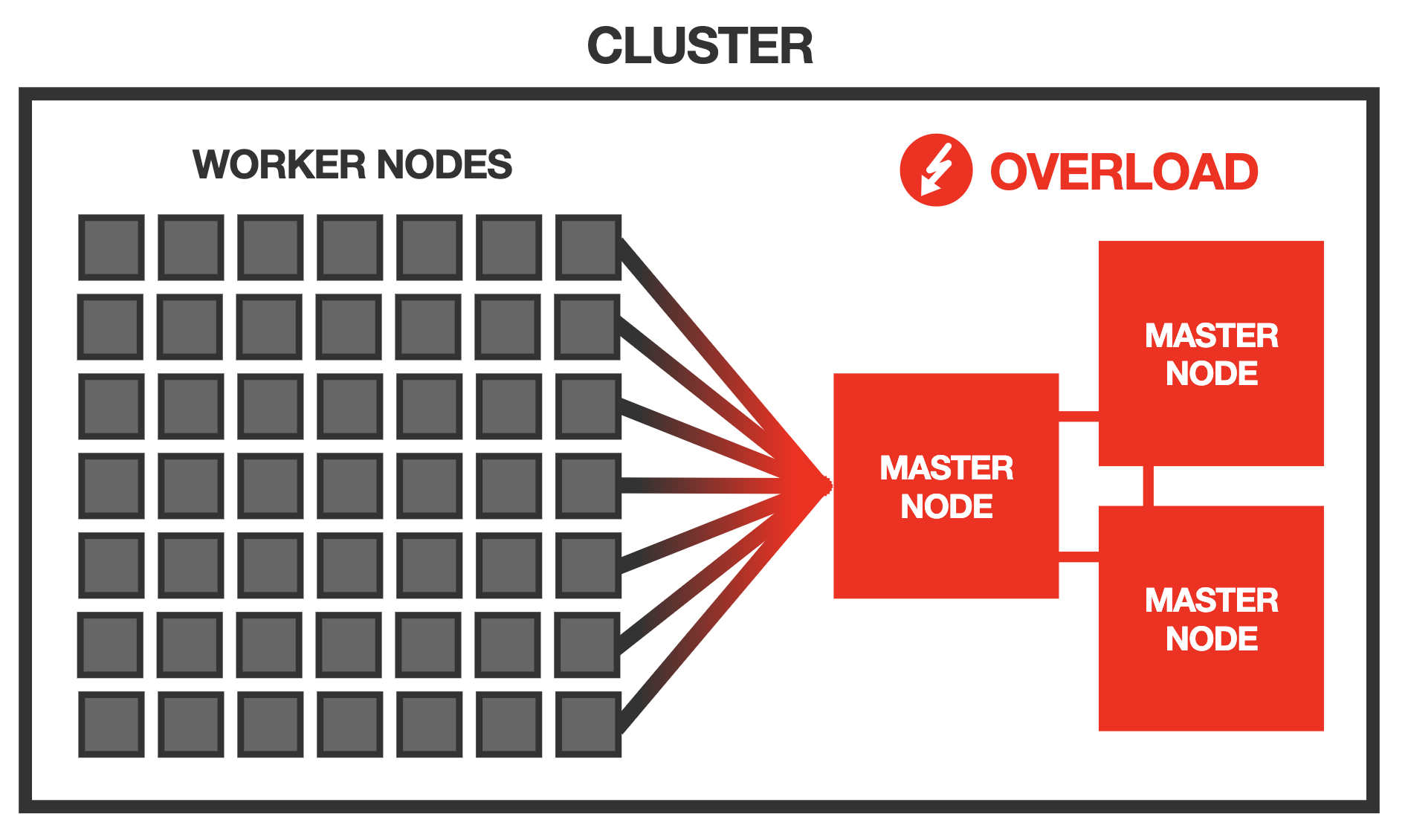
据官方统计,Kubernetes声称支持最多5000个节点的集群。
然而,在实践中,500个节点可能已经构成了较大的挑战。
通过使用性能更高的主节点,可以减轻大量工作节点的影响。
这就是在实践中所做的 – 这里是kube-up在云基础架构上使用的主节点大小:
- Google云端平台
- 5个工作节点→ n1-standard-1主节点
- 500个工作节点→ n1-standard-32主节点
- 亚马逊网络服务
- 5个工作节点→ m3.medium主节点
- 500个工作节点→ c4.8xlarge主节点
如您所见,对于500个工作节点,使用的主节点分别具有32和36个CPU核心以及120 GB和60 GB内存。
这些都是相当大的机器!
因此,如果您打算使用大量小节点,则需要记住两件事:
- 您拥有的工作节点越多,您需要的性能就越高
- 如果您计划使用超过500个节点,则可能会遇到一些需要付出一些努力才能解决的性能瓶颈
像Virtual Kubelet这样的新项目允许绕过这些限制,并允许具有大量工作节点的集群。
2. 更多系统开销
Kubernetes在每个工作节点上运行一组系统守护进程 – 包括容器运行时(例如Docker),kube-proxy和包含cAdvisor的kubelet。
cAdvisor包含在kubelet二进制文件中。
所有这些守护进程一起消耗固定数量的资源。
如果使用许多小节点,则这些系统组件使用的资源部分比例会更大。
例如,假设单个节点的所有系统守护程序一起使用0.1个CPU内核和0.1 GB内存。
如果您拥有10个CPU核心和10 GB内存的单个节点,那么守护程序将占用集群容量的1%。
另一方面,如果您有1个CPU核心和1 GB内存的10个节点,则后台程序将占用集群容量的10%。
因此,在第二种情况下,10%的账单用于运行系统,而在第一种情况下,它只有1%。
因此,如果您希望最大化基础架构支出的回报,那么您可能更喜欢更少的节点。
3. 降低资源利用率
如果您使用较小的节点,那么最终可能会有大量资源片段太小而无法分配给任何工作负载,因此保持未使用状态。
例如,假设您的所有pod都需要0.75 GB的内存。
如果你有10个1 GB内存的节点,那么你可以运行10个这些pod – 你最终会在每个节点上有一块0.25 GB的内存,你不能再使用它了。
这意味着,集群总内存的25%被浪费了。
另一方面,如果您使用具有10 GB内存的单个节点,那么您可以运行13个这样的pod – 而只有0.25 GB的单块内存剩下无法使用。
在这种情况下,您只会浪费2.5%的内存。
因此,如果您想最大限度地减少资源浪费,使用更大的节点可能会提供更好的结果。
4. 小节点上的Pod限制
在某些云基础架构上,小节点上允许的最大pod数量比您预期的要限制得多。
Amazon Elastic Kubernetes Service(EKS)就是这种情况,其中每个节点的最大pod数取决于实例类型。
例如,对于一个t2.medium实例,pod的最大数量是17,因为t2.small它是11,而t2.micro它是4。
这些都是非常小的数字!
任何超出这些限制的pod都无法由Kubernetes调度程序安排,这些pod会一直保持在Pending状态。
如果您不了解这些限制,则可能导致难以发现的错误。
因此,如果您计划在Amazon EKS上使用小节点,请检查相应的每节点pods数,并多算几次计算节点是否可以容纳所有pod。
结论
那么,您应该在集群中使用少量大型节点还是许多小型节点?
一如既往,没有明确的答案。
您要部署到集群的应用程序类型可能会指导您的决策。
例如,如果您的应用程序需要10 GB内存,则可能不应使用小节点 – 集群中的节点应至少具有10 GB内存。
或者,如果您的应用程序需要10倍的复制性以实现高可用性,那么您可能不应该只使用2个节点 – 您的集群应该至少有10个节点。
对于中间的所有场景,它取决于您的具体要求。
以上哪项优缺点与您相关?哪个不是?
话虽如此,没有规则规定所有节点必须具有相同的大小。
没有什么能阻止您在集群中使用不同大小节点混合在一起的方案。
Kubernetes集群的工作节点可以是完全异构的。
这可能会让您权衡两种方法的优缺点。
最后,证明布丁好坏就在于吃 – 最好的方法是试验并找到最适合你的组合!
我的网课“Kubernetes实战:高可用集群搭建、配置、运维与应用”在慕课网上线了,感谢小伙伴们学习支持!
我爱发短信:企业级短信平台定制开发专家 https://tonybai.com/
smspush : 可部署在企业内部的定制化短信平台,三网覆盖,不惧大并发接入,可定制扩展; 短信内容你来定,不再受约束, 接口丰富,支持长短信,签名可选。
著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
我的联系方式:
微博:https://weibo.com/bigwhite20xx
微信公众号:iamtonybai
博客:tonybai.com
github: https://github.com/bigwhite
微信赞赏:

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。