
本文永久链接 – https://tonybai.com/2026/05/26/why-nvidia-chose-go-to-rewrite-their-ai-infrastructure
当大家都在谈论 CUDA、Python 和 AI 框架时,NVIDIA 的工程团队正在悄悄用 Go 构建支撑整个 AI 云平台的底层基础设施。从 GPU 函数平台 NVCF,到 AI 集群运行时 AICR,再到已经有 1.8k Star 的分布式存储 AIStore,Go 语言已经成为 NVIDIA 内部 AI 基础设施的核心技术栈。这不是偶然,而是一个精心设计的技术选型。
大家好,我是Tony Bai。
2026 年 4 月,NVIDIA 悄悄开源了一个 repo:github.com/nvidia/nvcf。
没有大张旗鼓的发布会,没有 Jensen Huang 的皮夹克登场。但如果你打开这个 repo 看一眼语言构成,数字会让你一惊:
Go 占比 88.5%。
这不是一个小工具,这是驱动 build.nvidia.com、NVIDIA DGX Cloud 推理服务和全球 GPU 云合作伙伴(CoreWeave、Oracle Cloud 等)整个控制平面的核心平台。
然后你再看 AICR(AI Cluster Runtime):Go 51.1%。
再看 AIStore(面向 AI 的分布式存储):Go 75.2%,1.8k Star,10,219 次 commit,是一个有深度的系统级项目。
NVIDIA 在用 Go 构建 AI 时代的基础设施。而且这个趋势正在加速。

NVCF:GPU 云函数平台的全面开源
它是什么
NVCF 全称 NVIDIA Cloud Functions,是一个用于部署、管理和运行 GPU 加速工作负载的平台。你可以把它理解为”GPU 版的 AWS Lambda”——但更贴近生产级 AI 推理场景的设计。
你注册一个 Docker 容器或 Helm Chart,指定 GPU 类型,NVCF 负责处理一切:路由、队列、自动扩缩容、多租户隔离。GPU 云合作商在自己的 Kubernetes 集群上运行 NVIDIA Cluster Agent(NVCA),算力接入 NVCF 控制平面。
2026 年 4 月,NVIDIA 以 Apache 2.0 协议开源了整个平台的完整代码,包括控制平面、调用平面、计算平面、CLI、Helm Charts 和数据库迁移脚本——全部在一个 monorepo 里。之前的 NVIDIA/nvidia-cloud-functions 和 NVIDIA/nvcf-go 两个 repo 已归档,这个新 repo 是唯一的真相来源。
三平面架构:Go 是粘合剂
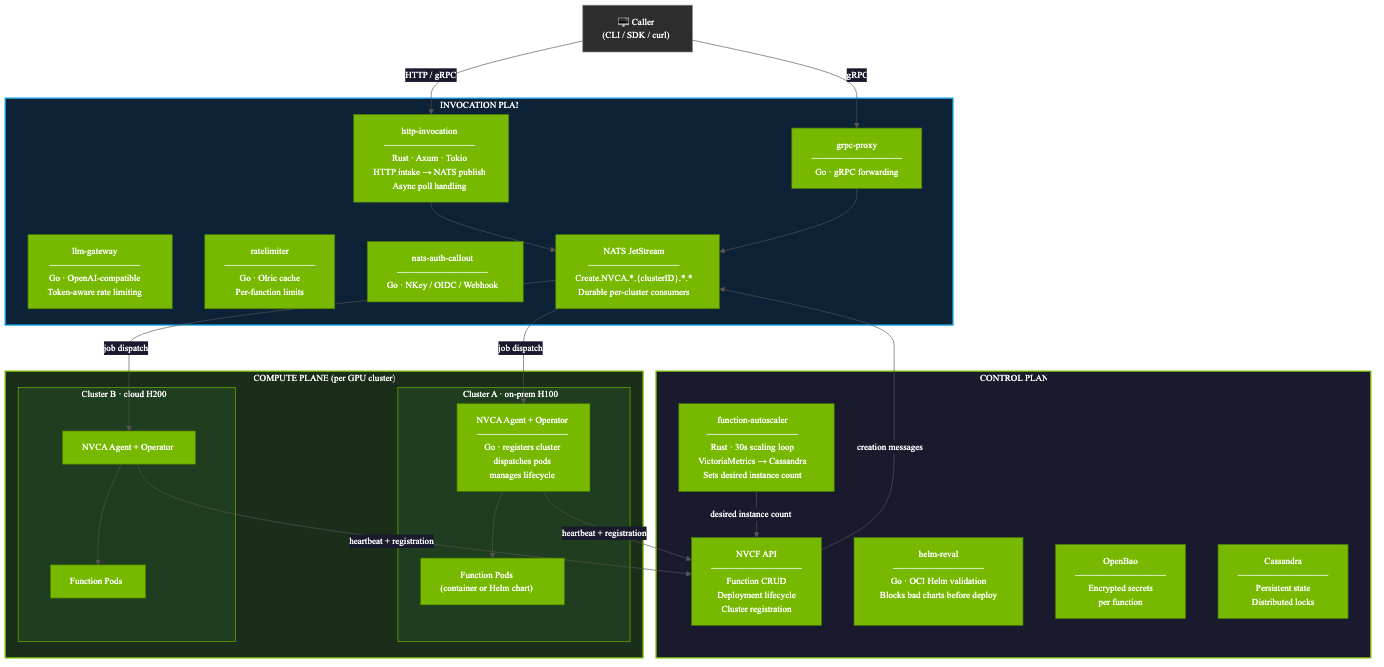
NVCF 的整体架构围绕三个独立可扩展的平面展开,通过 NATS JetStream 连接。
控制平面(Control Plane)
运行在专用 Kubernetes 集群上,负责函数生命周期管理、自动扩缩容决策和密钥管理。核心服务:
- function-autoscaler(Rust):30 秒扩缩容循环,从 VictoriaMetrics 读取利用率,决策写入 Cassandra
- helm-reval(Go):在计算平面部署前验证 OCI 引用的 Helm Chart
- OpenBao(Apache 2.0 的 Vault fork):函数密钥静态加密,运行时通过 ess-agent sidecar 注入
- Cassandra:持久化状态和自动扩缩容的分布式锁
调用平面(Invocation Plane)
所有请求的必经之路,Go 在这里是绝对主角:
- http-invocation(Rust/Axum):接收 HTTP/gRPC 请求,发布到 NATS JetStream
- llm-gateway(Go):OpenAI 兼容 API,内嵌 Olric 缓存实现 token 感知的速率限制
- grpc-proxy(Go):转发 gRPC 调用到函数实例
- ratelimiter(Go):使用 Olric 分布式缓存的函数级速率限制
- nats-auth-callout(Go):支持 NKey、OIDC 和 Webhook 策略的 NATS 认证
计算平面(Compute Plane)
每个 GPU 集群运行一个 NVCA(NVIDIA Cluster Agent)Operator。NVCA 将集群注册到控制平面,消费 NATS 消息,管理 Pod 生命周期。
一次请求的完整生命周期
从调用方的 POST /v2/nvcf/pexec/functions/{id} 开始,到响应返回,完整链路如下:
- http-invocation 检查速率限制(via ratelimiter gRPC)
- 请求发布到 NATS stream: Create.NVCA..{clusterID}..*
- NVCA queue manager 消费消息
- 创建 ICMSRequest Kubernetes CR(通过 NATS sequence 去重)
- MiniService controller 协调:创建 Pod 或应用 Helm Chart
- 函数 Pod 通过 WorkerService gRPC 回连:ConnectOnce
- 响应返回调用方
- 完成时:Terminate.NVCA.{clusterID} 触发 Pod 删除和 GC
Scale-to-Zero 的关键设计:NATS 作为持久化请求缓冲区
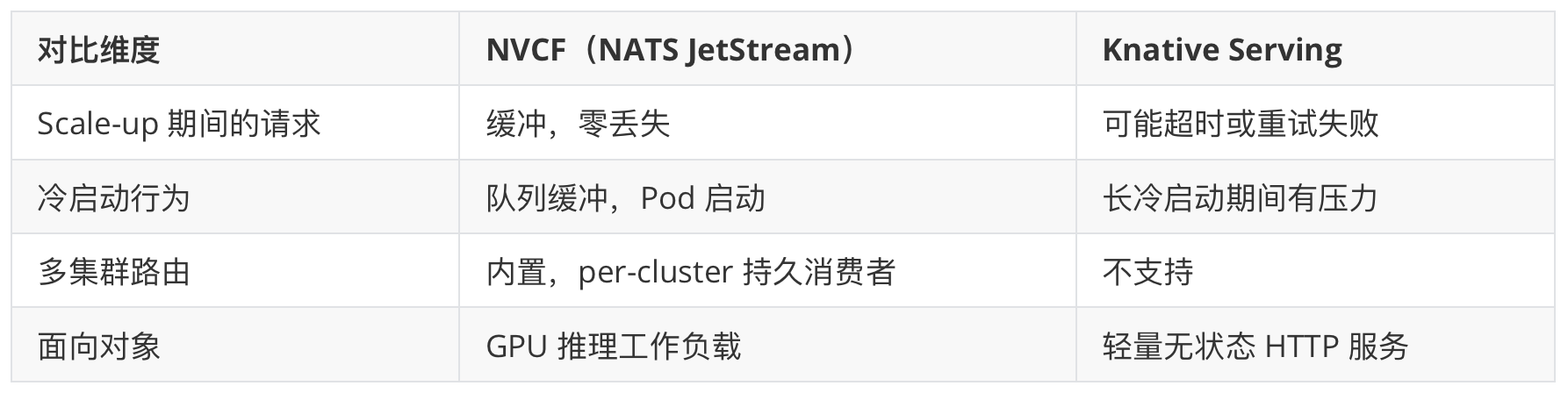
NVCF 解决的最有趣的工程问题,是 GPU 工作负载的 Scale-to-Zero。
传统方案(如 Knative)在 Scale-up 期间请求会面临超时压力或重试。对于加载大型模型可能需要数十秒乃至数分钟的 GPU 推理来说,这个问题会非常严重。
NVCF 的解法是把 NATS JetStream 当做一个持久化请求缓冲区:
- 自动扩缩容器将期望实例数降为 0,没有 Pod 运行
- 新请求到达,发布到 NATS JetStream,消息被持久化
- 自动扩缩容器检测到队列深度 > 0,将期望实例数提升到 1+
- NVCA 收到创建消息,启动 Pod
- Pod 通过 WorkerService gRPC 连接,拉取缓冲的消息
- 响应通过一直保持打开状态的 http-invocation 连接返回
请求永远不会被丢弃。 调用方在冷启动时等待更长时间,但请求一定会完成。这是 NATS 持久化消息的直接价值。
AICR:AI 集群运行时,Go 写的”集群配方书”
为什么需要 AICR
搭建一个 GPU 加速的 Kubernetes 集群是出了名的难。内核版本、驱动、容器运行时、Operator、Kubernetes 版本——任何一个环节的细微差异都可能导致难以诊断的问题,而且极难复现。
这些知识以前只存在于 NVIDIA 内部的验证流水线和运维手册里。AICR 把这些知识公开了。
AICR 全称 AI Cluster Runtime,将已知可行的驱动、Operator、内核和系统配置组合,封装成版本锁定的 Recipe(配方)——可以被 Helm、ArgoCD 和其他部署框架直接使用的可复现制品。
核心概念:Recipe 系统
一个 Recipe 是针对特定环境的版本锁定配置。你描述你的目标(云厂商、GPU 型号、操作系统、工作负载意图),Recipe 引擎将其与一个经过验证的 Overlay 库进行匹配——从基础默认值到云厂商、加速器、操作系统、工作负载特定调优,自底向上分层组合。
每个 AICR Recipe 具备三个特性:
- Optimized(优化):针对特定硬件、云、OS 和工作负载意图调优
- Validated(已验证):发布前通过自动化约束和兼容性检查
- Reproducible(可复现):相同输入产生完全一致的部署结果
CLI 展示:五分钟上手
# 安装 CLI(Go 编译的单一二进制)
curl -sfL https://raw.githubusercontent.com/NVIDIA/aicr/main/install | bash -s --
# 采集集群当前状态快照
aicr snapshot --output snapshot.yaml
# 为你的环境生成经过验证的 Recipe
aicr recipe --service eks --accelerator h100 --os ubuntu \
--intent training --platform kubeflow -o recipe.yaml
# 对比 Recipe 与集群实际状态,找出差异
aicr validate --recipe recipe.yaml --snapshot snapshot.yaml
# 渲染为部署就绪的 Helm Charts
aicr bundle --recipe recipe.yaml -o ./bundles
bundles/ 目录包含按组件分类的 Helm Chart,每个组件附带 values 文件、checksum 和 README。你可以用 helm install 部署,提交到 GitOps 仓库,或使用内置的 ArgoCD 部署器。
安全供应链:SLSA Level 3
AICR 在供应链安全上走得很远:SLSA Level 3 可溯源性、签名 SBOM、cosign 镜像证明、每次发布都有 checksum 验证。这已经是不少大型企业对内部工具的要求,NVIDIA 在开源项目里直接做到了。
技术栈细节
代码以 Go 为主(51.1%),使用 golangci 做 lint,goreleaser 做发布,ko 做容器镜像构建。项目已经发布了 54 个版本,活跃度很高。目前支持 Amazon EKS、GKE 和 Kind(自管理),GPU 覆盖 H100 和 GB200,工作负载支持 Kubeflow 训练和 Dynamo 推理。
AIStore:完全用 Go 写的 AI 分布式存储
如果说 NVCF 和 AICR 还是相对新鲜的项目,那 AIStore 则是一个已经经受了时间考验的系统级工程——1.8k Star,240 个 Fork,10,219 次 commit,46 位贡献者。
项目地址:github.com/NVIDIA/aistore
核心定位
AIStore(AIS)是一个专为 AI 应用构建的轻量分布式存储栈。它是一个弹性集群,可以在运行时扩缩容,支持从单台 Linux 机器到任意规模的裸机集群的任意部署方式。
AIS 的核心差异点:它能原生操作集群内数据和远程数据,而不是把远程数据当成缓存。这对 AI 训练工作负载来说是关键区别——你不需要先把 S3 数据拉下来再训练,AIS 可以透明地处理数据层。
技术亮点一览
- 多云后端支持:无缝访问 AWS S3、GCS、Azure、OCI,支持跨账号、跨 endpoint 的同名 bucket 共存。
- 线性扩展性:官方博客和 KubeCon 演讲中展示了跨任意数量集群节点的均衡 I/O 分布和线性扩展能力。
- ETL Offload:在数据附近执行 I/O 密集型数据转换,可以内联(作为每次读请求的一部分实时处理)或离线(批量处理,结果写入目标 bucket)。
- Get-Batch:单次调用检索多个对象或归档文件。专为 ML/AI 流水线设计,一次操作获取整个训练批次,按用户指定的顺序组装成 TAR(或其他序列化格式)。这个功能甚至有配套的 arxiv 论文(2602.22434)。
- 负载感知节流:基于多维度负载向量(CPU、内存、磁盘、文件描述符、goroutine)的动态请求节流,保护 AIS 集群在压力下的稳定性。
- 30+ 批处理操作:包括 archive、blob-download、copy-bucket、dsort、etl-bucket、lru-eviction、rebalance、rechunk 等,全部可以通过 CLI 启动、监控和控制。
为什么用 Go
AIStore 75.2% 的代码是 Go,其 Go API 直接被 CLI 和 benchmarking 工具使用。选择 Go 的逻辑很清晰:
- 系统级性能:Go 的 goroutine 模型天然适合高并发 I/O 密集型工作负载,而分布式存储正是这种场景
- 单一二进制发布:CLI 工具和服务端都能编译成静态链接的单一二进制,部署极其简单
- 生态成熟:Kubernetes operator、gRPC、NATS、Prometheus——这些基础设施领域的核心库在 Go 生态中都有成熟实现
- 代码可维护性:相比 C++,Go 在保持接近底层性能的同时大幅降低了复杂系统的维护成本
为什么是 Go?NVIDIA 的技术选型逻辑
把这三个项目放在一起看,NVIDIA 选择 Go 的逻辑变得清晰:
AI 基础设施的特殊需求
AI 基础设施不同于传统 Web 服务。它需要处理:
- GPU 资源的精细调度和隔离
- 大规模并发请求的队列管理
- 跨多集群的协调
- 模型文件的海量 I/O
- 长时间运行的异步任务
这些场景对并发模型的要求极高。Go 的 goroutine 和 channel 机制,让工程师可以用清晰的代码表达复杂的并发逻辑,而不需要像 C++ 那样手动管理线程。
云原生生态的”母语”
Kubernetes、Docker、containerd、Prometheus、NATS、Helm——云原生基础设施栈几乎是用 Go 写的。NVIDIA 的三个项目全部深度集成 Kubernetes,深度依赖 Operator 模式、Controller Runtime、Helm Chart。选择 Go 意味着可以直接使用这些生态的核心库,而不是跨语言调用的额外复杂度。
运维友好的单一二进制
aicr、ais CLI 工具都是 Go 编译的单一静态二进制。在需要快速部署到新集群、在 CI/CD 流水线中运行、或者在边缘节点上操作时,这个特性极其实用。
Rust + Go 的互补分工
值得注意的是,NVCF 并不是全 Go。高性能热路径(http-invocation、function-autoscaler)用了 Rust,而控制逻辑、网关、代理、认证——这些需要快速迭代、逻辑清晰的组件——用 Go。
这个分工很有意思:Rust 负责极致性能的关键路径,Go 负责需要快速演化的系统逻辑。两种语言各司其职,而不是用一种语言通吃所有场景。
小结:这意味着什么
对 Go 开发者
NVIDIA 的这几个 repo 是绝佳的真实世界大型 Go 项目参考:
- NVCF:学习 Kubernetes Operator 模式、gRPC、NATS 集成、多平面分布式系统设计
- AICR:学习 CLI 工具设计(goreleaser + cobra)、Helm 生成、GitOps 集成模式
- AIStore:学习高性能分布式系统的 Go 实现,包括内存管理(memsys 包)、分布式一致性、S3 兼容 API 实现
这三个项目都是 Apache 2.0 或 MIT 开源,代码质量高,有完整的测试和文档。
对 AI 平台工程师
NVIDIA 正在开源 AI 基础设施的核心组件。NVCF 的开源意味着你可以:
- 在私有 GPU 集群上运行与 NVIDIA 云服务相同的调度和路由逻辑
- 审计每一行代码,而不是把平台当成黑盒
- 修改自动扩缩容逻辑、添加 NATS 认证策略、扩展 MiniService controller
AICR 则给了你一个”NVIDIA 认证”的集群配置参考——如果你正在搭建自管理 GPU 集群,AICR 的 Recipe 系统告诉你什么组合是经过验证的。
对技术决策者
当 NVIDIA——一家以 CUDA C++ 闻名的公司——在 AI 基础设施层面系统性地选择 Go,这个信号足够强烈。Go 已经不只是”Google 的语言”或者”云原生工具链的语言”,它正在成为 AI 时代基础设施的核心技术栈之一。
资料链接:
- https://blog.kubesimplify.com/nvcf-is-now-open-source-inside-nvidia-s-gpu-function-platform
- https://github.com/nvidia/nvcf
- https://github.com/NVIDIA/aicr NVIDIA AI Cluster Runtime
- https://github.com/NVIDIA/aistore AIStore: scalable storage for AI applications
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
- 抛弃臃肿框架,回归“驾驭工程 (Harness Engineering)”的第一性原理
- 用 Go 语言手写 ReAct 循环、并发拦截与上下文压缩引擎等,复刻极简OpenClaw
- 构建坚不可摧的 Safety Middleware 与飞书人工审批防线
- 在底层实现 Token 成本审计、链路追踪与自动化跑分评估
- 从“调包侠”进化为掌控大模型边界的“AI 操作系统架构师”
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
- 体系化 Go 核心进阶内容: 深入「Go原理课」、「Go进阶课」、「Go避坑课」等独家深度专栏,夯实你的 Go 内功。
- 前沿 Go+AI 实战赋能: 紧跟时代步伐,学习「Go+AI应用实战」、「Agent开发实战课」、「Agentic软件工程课」、「Claude Code开发工作流实战课」、「OpenClaw实战分享」等,掌握 AI 时代新技能。
- 星主 Tony Bai 亲自答疑: 遇到难题?星主第一时间为你深度解析,扫清学习障碍。
- 高活跃 Gopher 交流圈: 与众多优秀 Gopher 分享心得、讨论技术,碰撞思想火花。
- 独家资源与内容首发: 技术文章、课程更新、精选资源,第一时间触达。
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
