
本文永久链接 – https://tonybai.com/2026/07/03/20-loop-design-patterns-every-ai-engineer-should-know
大家好,我是Tony Bai。
在前一篇中,我们分享了 OpenAI 联合创始人、现Anthropic独立研究员 Andrej Karpathy 的一线手记《LOOPS.md》。他一针见血地指出:“Prompt 是你写完一次就忘的东西,而 Loop(循环)才是你睡觉时仍在为你工作的系统。” 提示词的杠杆效应已经见顶,现在的竞争维度,是“循环工程(Loop Engineering)”。
但是,具体到工程实践中,我们该如何设计这些循环?
AI 圈知名技术专家 Rahul (@sairahul1) 梳理总结了当前工业级 AI 生产系统中最核心的 20 个“循环设计模式”(Loop Design Patterns)。
正如传统的软件工程有《设计模式》(Design Patterns)作为圣经,AI 时代的软件工程也正在迎来它自己的范式。正如Rahui所说“Agent 只是干活的工人,而 Loop 才是让工人不断自我进化的机制”。普通工程师和年薪百万的资深 AI 架构师之间,差的正是这套循环设计的功力。
从代码纠错、多角色博弈、动态规划,到让系统自我重构的终极优化循环。这 20 个模式,将彻底帮你告别单次调用的“拼运气”时代,跨入工业级 Agent 系统的大门。
以下为译文全文:

大多数 AI 工程师只知道如何构建一个 Agent(智能体)。
但极少数人知道如何构建一个在第一次尝试失败后,能够自主变得更好的系统。
而这,正是年薪百万与普通工程师之间的鸿沟。
两者的本质区别在于:
- Agent(智能体) 只是一个干活的工人。
- Loop(循环) 才是让这个工人不断改进的机制。
今天,在生产环境(Production)中运行的最强大的 AI 系统,绝不是靠单次模型调用(Single Model Call)支撑起来的。
它们全部都是“循环(Loops)”。
生成(Generate) -> 评估(Evaluate) -> 学习(Learn) -> 改进(Improve)
周而复始。
直到输出结果真正达到优秀标准。
以下是频繁出现在工业级 AI 系统中的 20 个循环设计模式。
建议收藏,你迟早会用到它们。
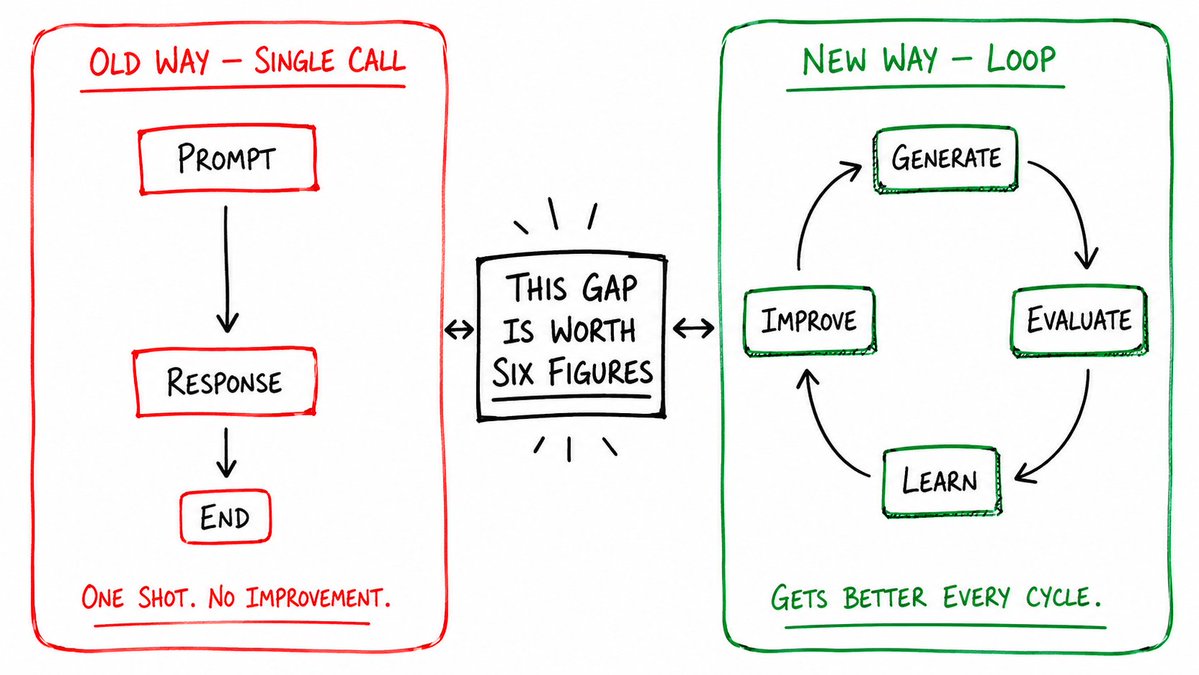
Agent vs 循环
- 老方法(单次调用):输入 Prompt -> 获得 Response -> 结束。
- 新方法(循环模式):生成 -> 批判 -> 重写 -> 打分 -> 重试 -> 记忆 -> 改进。
前者就像一个工厂临时工,干完一次就走人。
后者则像一个卓越的正式工:研究每一次失误,重新改写操作手册,让自己的工作在每一个班次都提升 3%。
目前正在交付生产级 AI 的顶尖团队,早就不再死磕怎么写出更好的提示词(Prompt)了。
他们正在构建更好的循环(Loops)。
第一类:质量提升循环 (Quality Improvement Loops)
(核心目的:在输出结果离开系统前,使其质量达到极限)
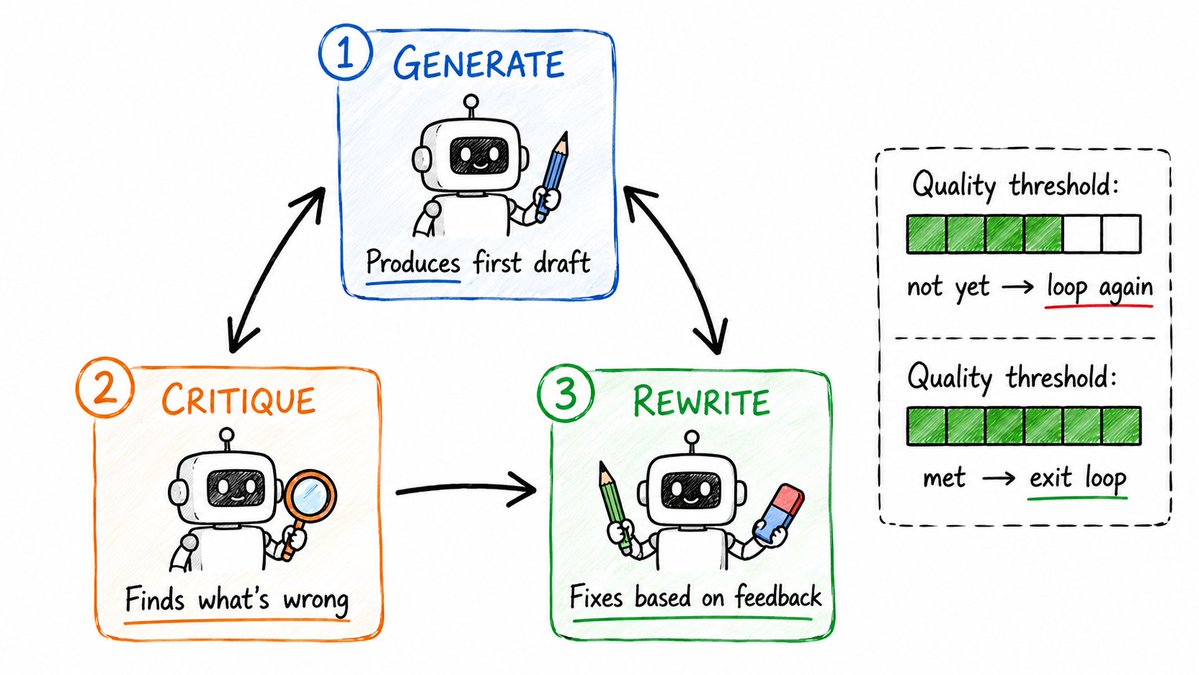
1. 生成 -> 批判 -> 重写 (Generate -> Critique -> Rewrite)
这是 AI 工程中最核心、最重要的循环。
生成输出 -> 批判者(Critic)进行审查 -> 生成者(Generator)根据反馈重写。不断重复,直到达到质量阈值。
这不是用一个模型搞定一切,而是两个角色,一条流水线。
[生成者 Generator] → 产出初稿
[批判者 Critic] → "第 3 段很模糊。缺乏论据支撑。语气不够专业。"
[生成者 Generator] → 根据批判意见进行重写
[批判者 Critic] → "有进步,但结论部分仍然偏弱。"
[生成者 Generator] → 完成最终重写
- 适用场景:文案写作、代码审查、报告撰写、战略规划书、销售开发信。
- 核心洞察:负责生成的模型,往往不是评估自身输出的最佳裁判。让一个独立的“批判者”角色去挑刺,总能找出生成者忽略的盲点。
2. “打分-重试”循环 (Score-and-Retry Loop)
生成 -> 打分。如果低于阈值,则重试。
极度简单,极度强大,却在实践中被严重低估。
score = evaluate(output)
while score < threshold:
output = generate(prompt)
score = evaluate(output)
attempts += 1
if attempts > max_retries:
return best_so_far # 达到最大重试次数,返回目前最好的结果
- 适用场景:当质量可以被客观量化时(如数据提取准确率、格式合规性、事实正确性、线索评分)。
- 核心设计:生成者并不知道自己正在被考核,只有评估者(Evaluator)掌握打分标准。这种角色上的隔离,正是该模式的精髓。
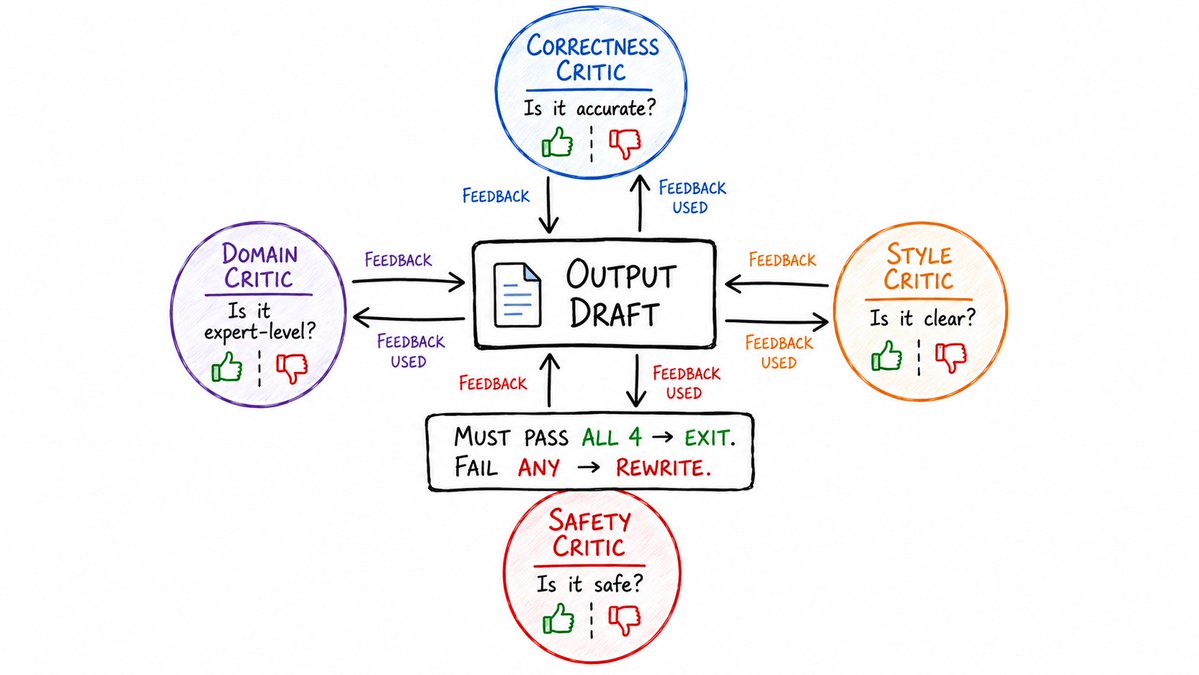
3. 多重批判者循环 (Multi-Critic Loop)
单个批判者难免会有盲点。
那就引入四个。
- 正确性批判者:信息是否事实准确?
- 风格批判者:表达是否清晰、文笔是否流畅?
- 安全批判者:内容是否合规、是否安全?
- 领域批判者:是否达到了行业专家的标准?
每个批判者独立进行评估。
最终的输出必须同时通过这四个维度的审核,才能获准出库。
- 适用场景:医疗 AI、法律文件审查、财务分析、受监管的内容生成。
4. 对抗式批判循环 (Adversarial Critique Loop)
在这个模式中,批判者的唯一任务就是摧毁(Break)生成者的答案。
不帮忙优化,只负责挑刺和否定。
对抗式批判者会提出以下灵魂拷问:
- “这里有哪些假设是不成立的?”
- “缺失了哪些关键证据?”
- “如果是一个怀疑论者会怎么反驳?”
- “这里看似自信的结论,哪些其实是错的?”
生成者随后必须进行自我辩护或重写。
只有经受住这一轮轮猛烈攻击后存活下来的答案,才是最好的答案。
- 适用场景:前沿研究综述、投资逻辑审查、战略规划、风险评估。
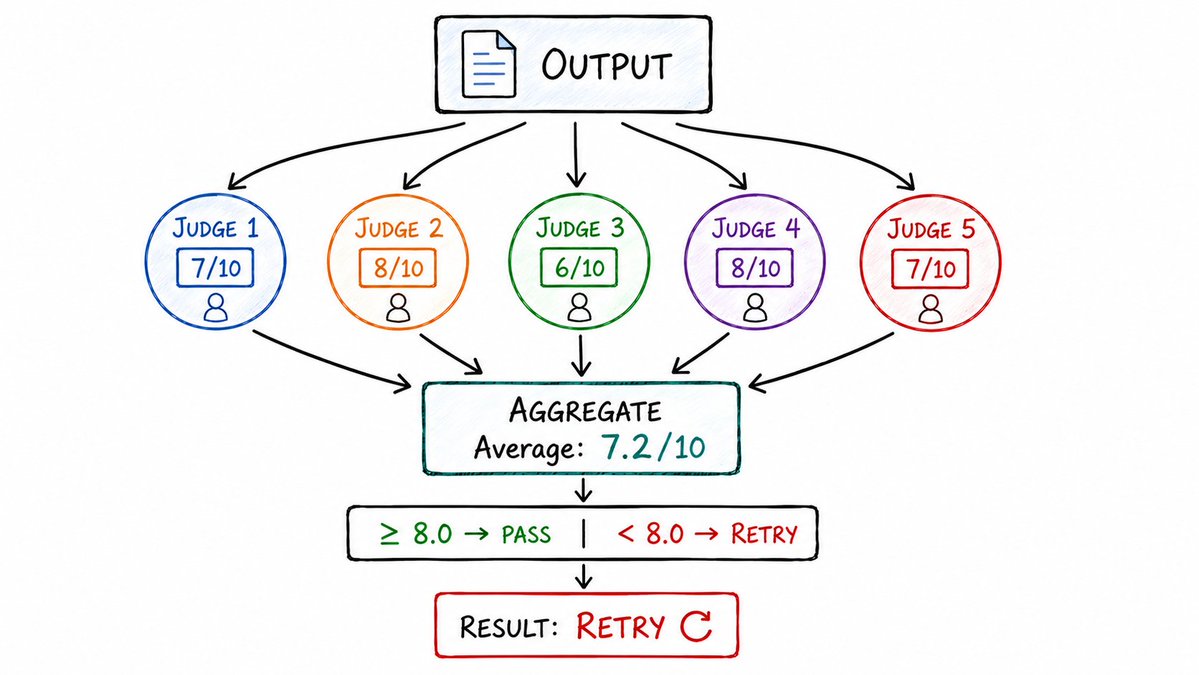
5. 评审团共识循环 (Judge Ensemble Loop)
单个裁判的打分往往伴随着噪声(Noise)。
让五个裁判联合打分,就能抹平这种噪音。
将同一个输出结果送入多个独立的评估器(Evaluators)中,汇总并计算平均分。只有在获得高度共识(High Consensus)的情况下,系统才会继续推进。
- 适用场景:单模型评估结果不稳定、任务容错率极低、边界极端情况(Edge Cases)至关重要的场景。
第二类:记忆循环 (Memory Loops)
(核心目的:从历史经验中学习,让下一次运行变得更聪明)
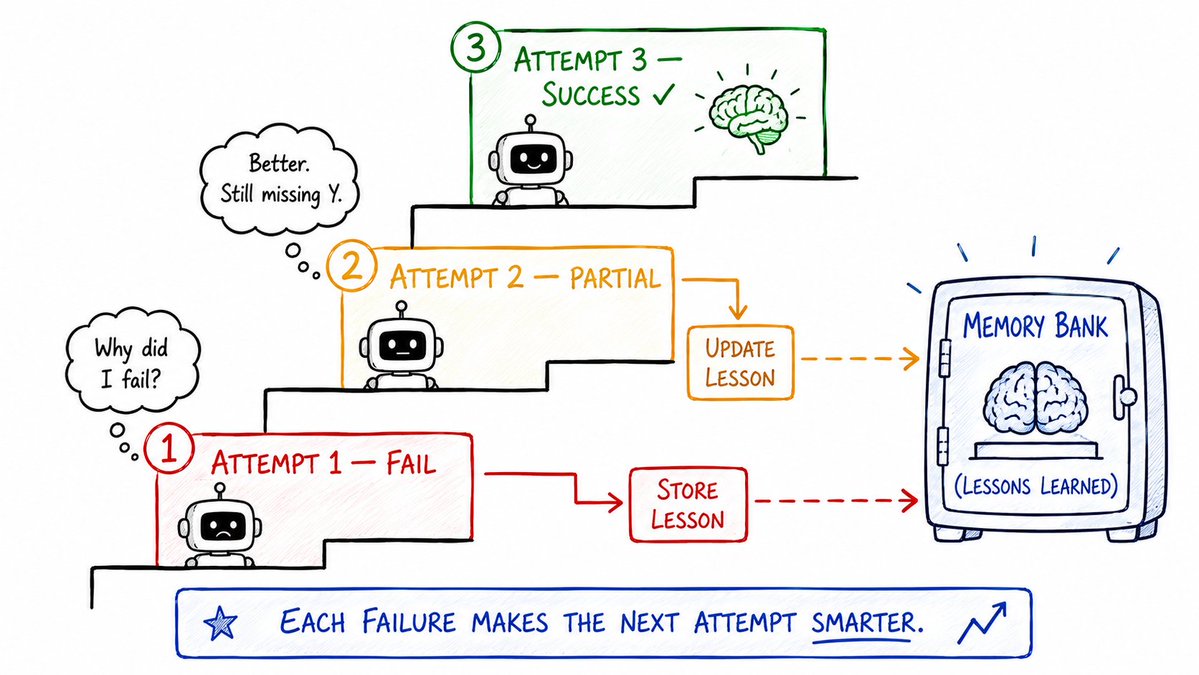
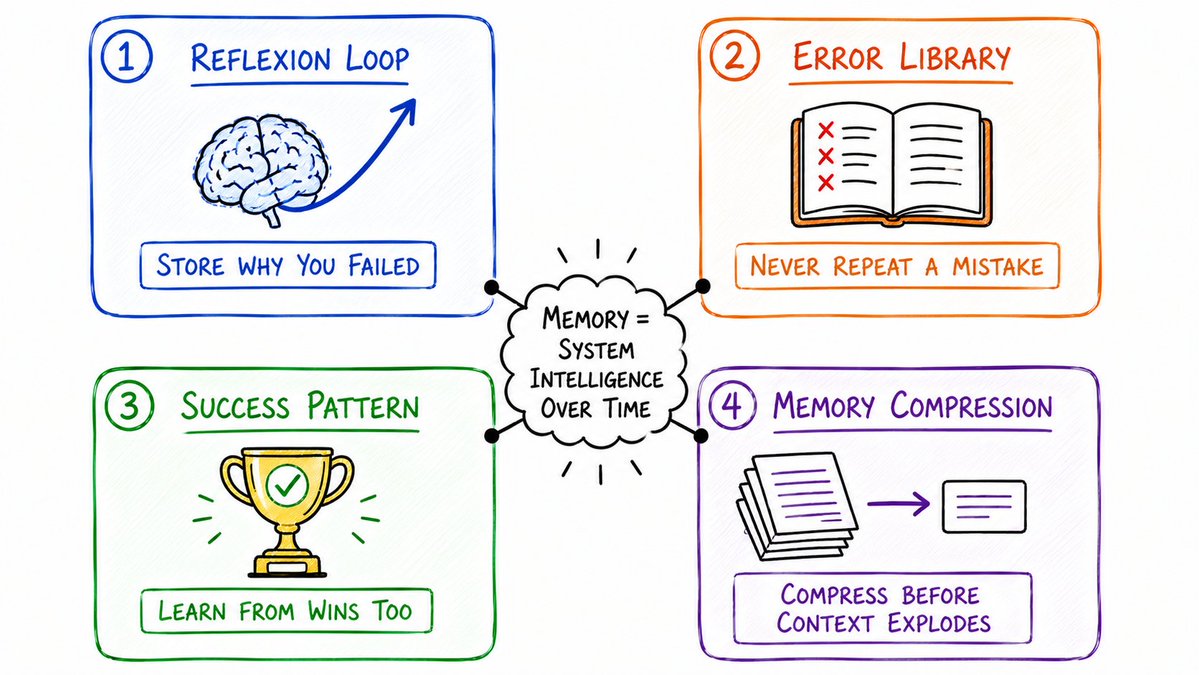
6. 反思循环 (Reflexion Loop)
这是目前存在的最重要的自我进化(Self-Improvement)设计模式。
Agent 执行失败 -> 分析失败原因 -> 将教训存入记忆库 -> 带着这段教训(写入 Context)重新尝试。
每一次迭代,都比上一次更聪明。
尝试 1: 失败了
反思: "我假设了 X 成立,但实际上 X 是错的。下次一定要先验证 X。"
尝试 2: 注入教训 → 获得部分成功
反思: "变好了。但我漏掉了步骤 Y。需要增加对 Y 的检查。"
尝试 3: 成功
这就是“会失败一次的系统”与“只会在同一个地方摔倒一次的系统”之间的本质区别。
7. 记忆更新循环 (Memory Update Loop)
在每次任务结束后,雷打不动地记录并固化三件事:
- 做出了什么决策?
- 最终带来了什么结果?
- 如果重来一次,会有什么不同的做法?
未来的每一次运行,都会自动继承这些知识库。
系统运行到第 6 个月时的表现,和第 1 个月时相比会有天壤之别,因为它已经阅读了自己长达 6 个月的成长史。
8. 错误档案库循环 (Error Library Loop)
把每一次失败都存进“错题本”。
不管是错误的回答、糟糕的输出、失败的执行,还是遇到的极端 Edge Case。
在执行任何新任务之前,系统会首先检索错题本:如果存在类似的失败记录 -> 在任务开始前,直接将已知的修正方案写入执行策略。
确保系统绝不在同一个地方跌倒两次。这是目前生产环境中最被低估的模式。
9. 成功案例库循环 (Success Pattern Loop)
大多数工程师只记得记录失败。
但你也需要记录成功。
当一个任务完成得很漂亮时:保存它的执行路径 -> 保存当时的 Context -> 保存促成成功的关键因素。
在面对类似任务时,检索并复用这些成功模式。不仅要从错误中吸取教训,更要从胜利中复制经验。
10. 记忆压缩循环 (Memory Compression Loop)
记忆会无休止地膨胀。
而无限的、杂乱的原始记忆,等同于无法使用的垃圾。
当积累了 N 条记忆项后,系统自动启动压缩机制:将大量具体的细碎记忆 -> 升华为更高级别的抽象规律(Abstractions)。
【压缩前】:
"任务 A 失败了,因为存在 X 问题"
"任务 B 失败了,因为存在 X 问题"
"任务 C 失败了,因为存在 X 问题"
【压缩后】:
"底层规律:X 会直接导致失败。执行任何任务前,务必优先检查 X。"
保持上下文窗口(Context)永远干净清爽,让关键规律随时可读,确保系统高速运行。
第三类:规划循环 (Planning Loops)
(核心目的:当现实发生变化时,能够动态调整路线)
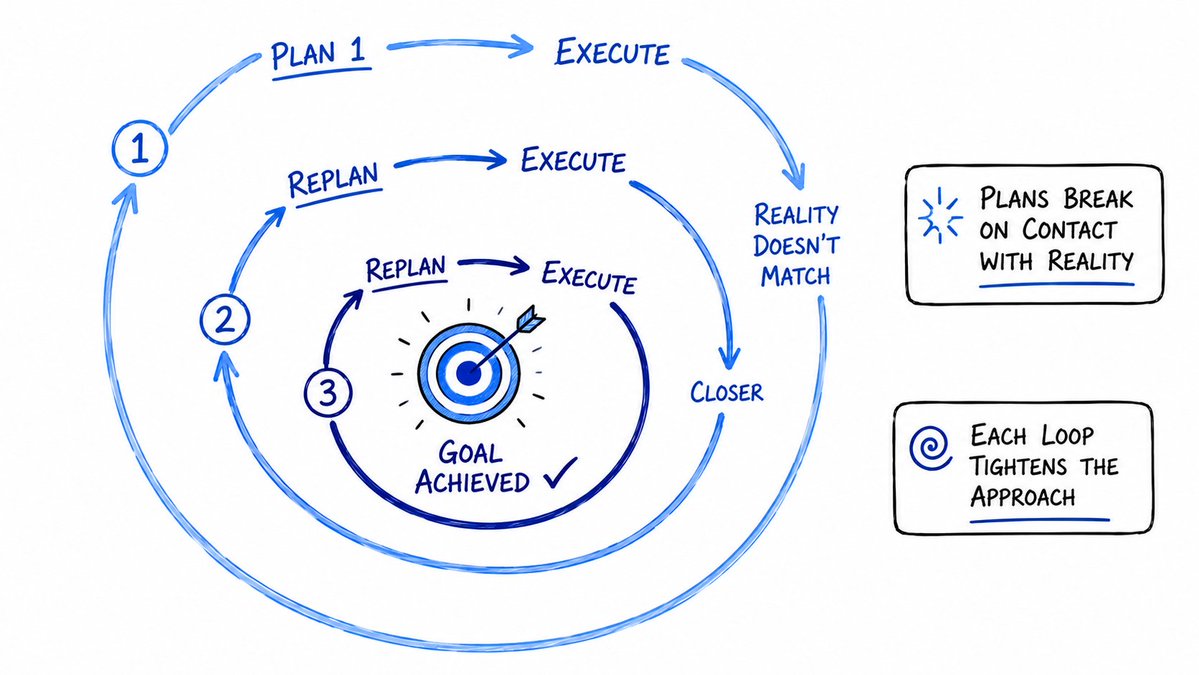
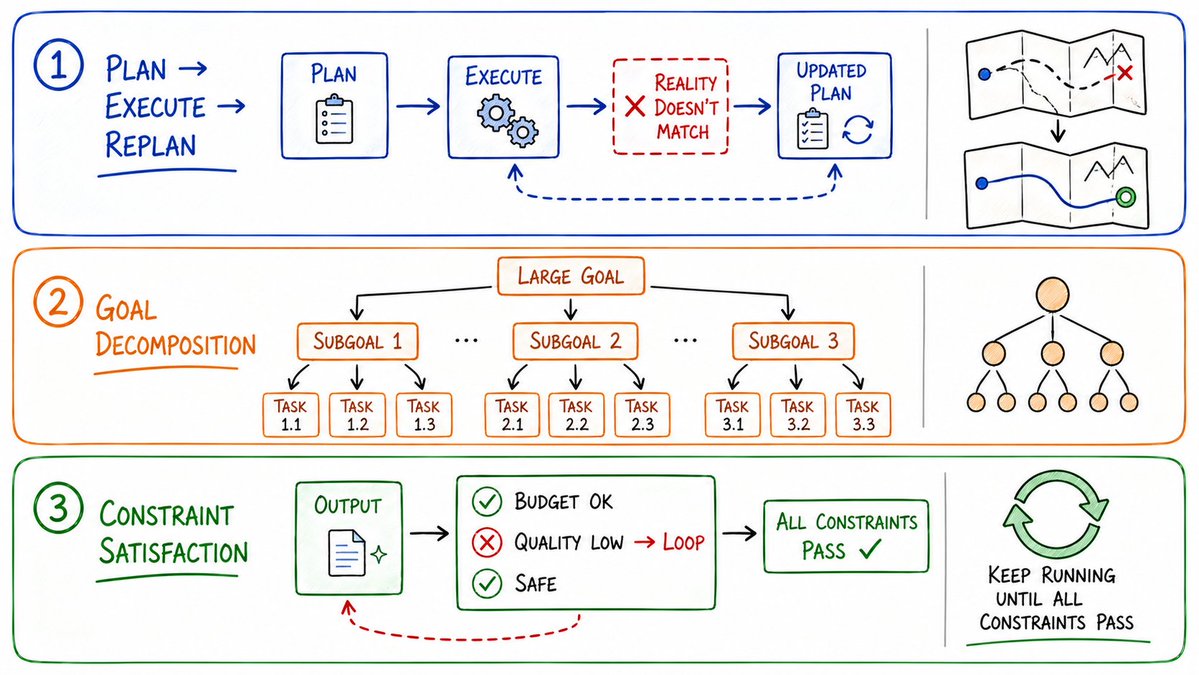
11. 规划 -> 执行 -> 重新规划 (Plan -> Execute -> Replan)
AI Agent 设计中最常见的错误,就是把最初的规划当成一成不变的圣旨。
再完美的规划,在碰撞现实的瞬间也会碎落一地。
该模式的核心路径是:
制定规划 -> 执行当前步骤 -> 观察实际结果 -> 更新规划 -> 继续前行
它不是一条线性的瀑布流(Waterfall),而是一个不断收敛的螺旋(Spiral)。每一圈迭代,都在拉近与目标的距离。
- 适用场景:外部环境动态变化、任务步骤之间存在强依赖、长周期(Long-Horizon)复杂任务。
12. 动态工作流循环 (Dynamic Workflow Loop)
绝大多数 AI 流水线(Pipelines)都是死板固定的:步骤 1 -> 步骤 2 -> 步骤 3,永远如此。
而动态工作流会根据中间结果在运行时决定自己的形状:
-
如果步骤 1 的输出是 A -> 走分支 X;
-
如果输出是 B -> 走分支 Y;
-
如果输出是 C -> 直接跳过步骤 2,执行步骤 5。
-
适用场景:多文档深度调研、多渠道客服自动路由、个性化内容自适应生成。
13. 目标分解循环 (Goal Decomposition Loop)
当一个极其庞大、模糊的目标进入系统时:
- 系统将其拆解为若干子目标(Subgoals);
- 每个子目标再细化为具体任务(Tasks);
- 每个任务继续拆解为执行步骤(Steps);
- 持续递归拆解,直到每一个最小单元都小到可以通过单次模型调用(Single Call)完美搞定。
大目标: "写一份详尽的竞品分析报告"
|
├─ 子目标 1: "定位排名前 5 的直接竞品"
├─ 子目标 2: "分析每个竞品的核心功能点"
├─ 子目标 3: "对比彼此的价格模型"
└─ 子目标 4: "找出市场空白与破局点"
|
每个子目标 → 拆解为任务 → 转化为底层的单次 API 调用
在系统有能力开始干活之前,这个拆分循环绝不停下。
14. 进度自评循环 (Progress Evaluation Loop)
每执行 N 个步骤,系统都需要强行停下来问自己:“我们当前采取的动作,真的正在拉近我们与终极目标的距离吗?”
如果是:继续执行当前策略。
如果否:果断切换策略、寻找新工具,或者重修路线图。
Agent 绝不应该只会盲目地执行命令,它必须具备进度监控(Self-monitoring)的能力。
- 适用场景:长时间运行的调研 Agent、需自主运行数天的自动化任务、自动 Debug 的编程 Agent。
15. 约束满足循环 (Constraint Satisfaction Loop)
不达目的,誓不罢休。在所有硬性约束被完全满足之前,循环永远在后台运转。
while not all_constraints_satisfied(output):
output = improve(output, unsatisfied_constraints)
# 必须通过的约束硬性指标:
constraints = [
budget_under_limit, # 预算未超支
quality_above_threshold, # 质量达标
latency_under_200ms, # 延迟低于200毫秒
tone_matches_brand, # 语气符合品牌调性
no_hallucinations # 无幻觉成分
]
这在真实的商业化生产系统中非常普遍:只要有一条业务规则(Business Rule)没有通过,这个输出在系统内部就绝对不算完工。
第四类:探索循环 (Exploration Loops)
(核心目的:通过尝试多条路径,榨出最优解)
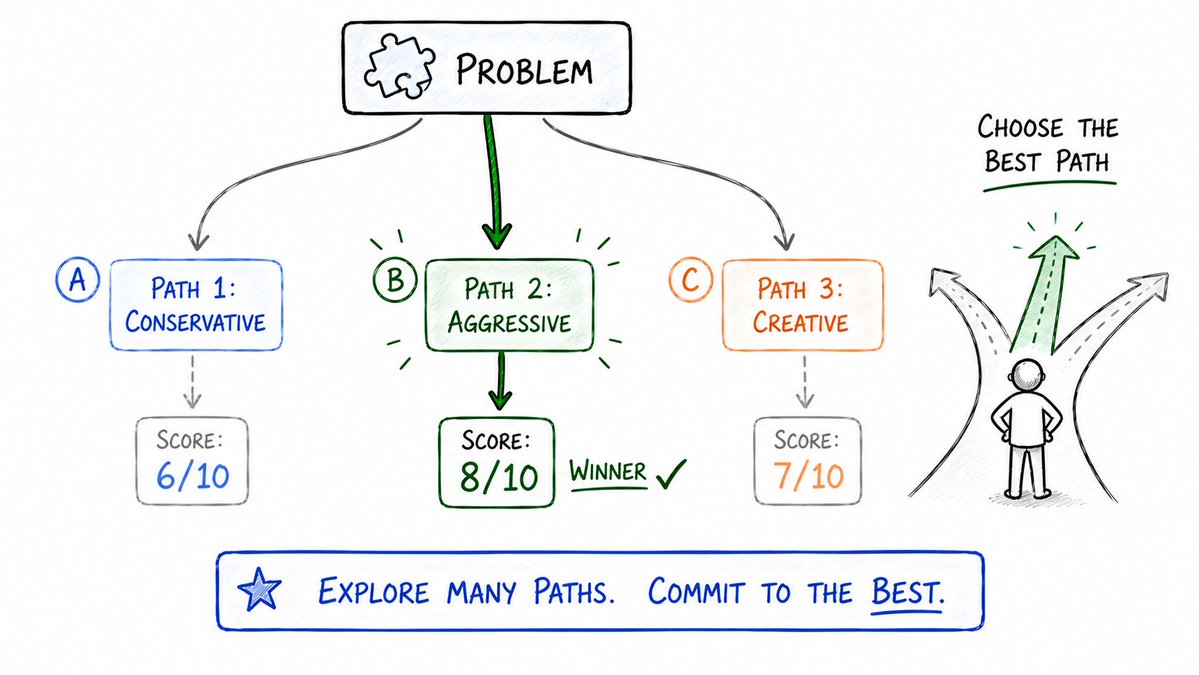
16. 分支探索循环 (Branch-and-Explore Loop)
不要把赌注押在单一条路上。
同时向多个方向展开探索。
paths = [
generate(approach="conservative"), # 保守方案
generate(approach="aggressive"), # 激进方案
generate(approach="creative") # 创意方案
]
# 对所有方案进行打分评估,挑出最优解
scores = [evaluate(p) for p in paths]
best = paths[scores.index(max(scores))]
横向对比所有尝试的产出,选择表现最好的那条分支,无情丢弃其余分支。
- 适用场景:文案多版本测试、架构决策评估、多路径 Debug 假说验证、A/B 测试生成。
17. 树搜索循环 (Tree Search Loop)
“分支探索循环”仅仅是在广度上展开了一层。
而树搜索(Tree Search)则可以根据需要向纵深无限延伸。
展开最具潜力的节点,剪掉最弱的分支。不惜代价持续探索,直到在树的深处挖出正确答案。
根节点 → 展开分支 [A, B, C]
├─ 节点 A → 展开 [A1, A2] (系统评估 A 很有前景,继续深挖)
├─ 节点 B → 剪枝剪掉 (系统评估 B 表现太差,在此止步)
└─ 节点 A1 → 展开 [A1a, A1b]
└─ A1a → 找到最优解! ✓
- 适用场景:高度复杂的推理链、多步骤的长程规划、代码库级别的重构与 Debug。
- 代价:虽然计算资源消耗极高,但它能完成单次 API 调用永远无法企及的复杂任务。
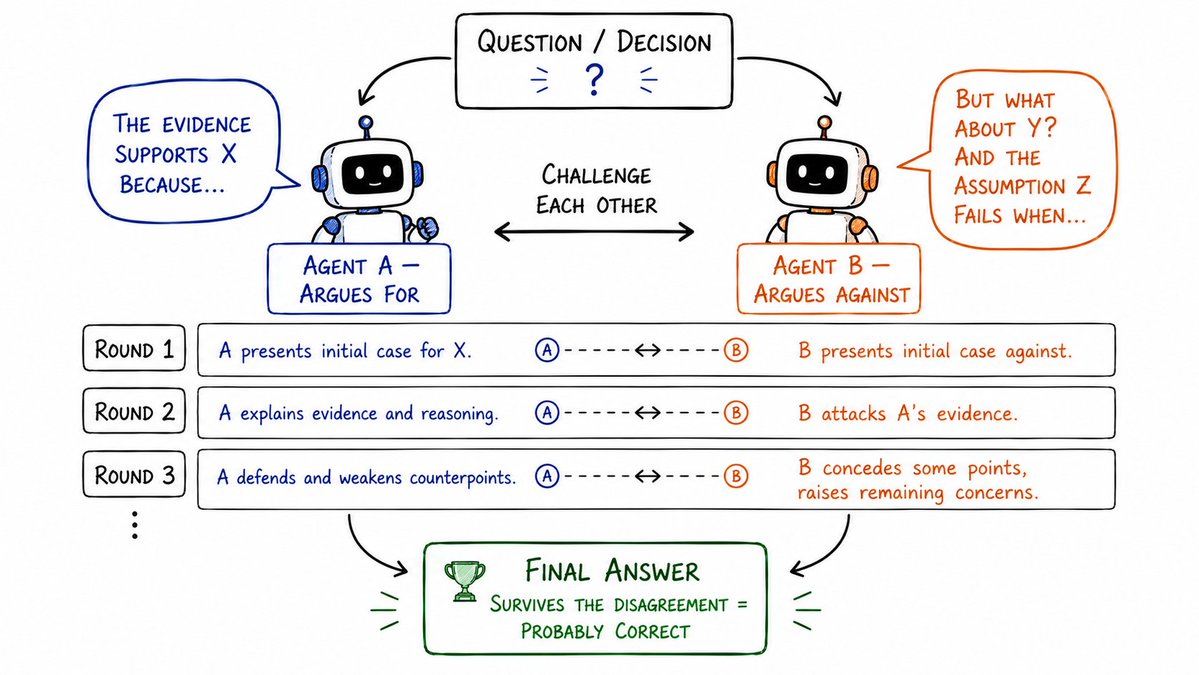
18. 辩论循环 (Debate Loop)
准备两个 Agent。针对同一个议题,站在完全相反的立场上。
Agent A 负责正方立论,Agent B 负责反方驳斥。
在每一轮辩论中,双方都在无情地挑战对方的假设、要求对方出示证据、戳破对方的逻辑漏洞。
最终的正确答案,不是在妥协和共识中产生的,而是在激烈的冲突和对抗中被逼出来的。这种对抗性的张力,能把单 Agent 盲目自信下隐藏的所有死角全部逼成显形。
- 适用场景:投资决策、战略规划论证、重大风险评估、深度学术/行业批判。
第五类:系统优化循环 (System Optimization Loops)
(核心目的:让循环本身具备自我优化的元能力)
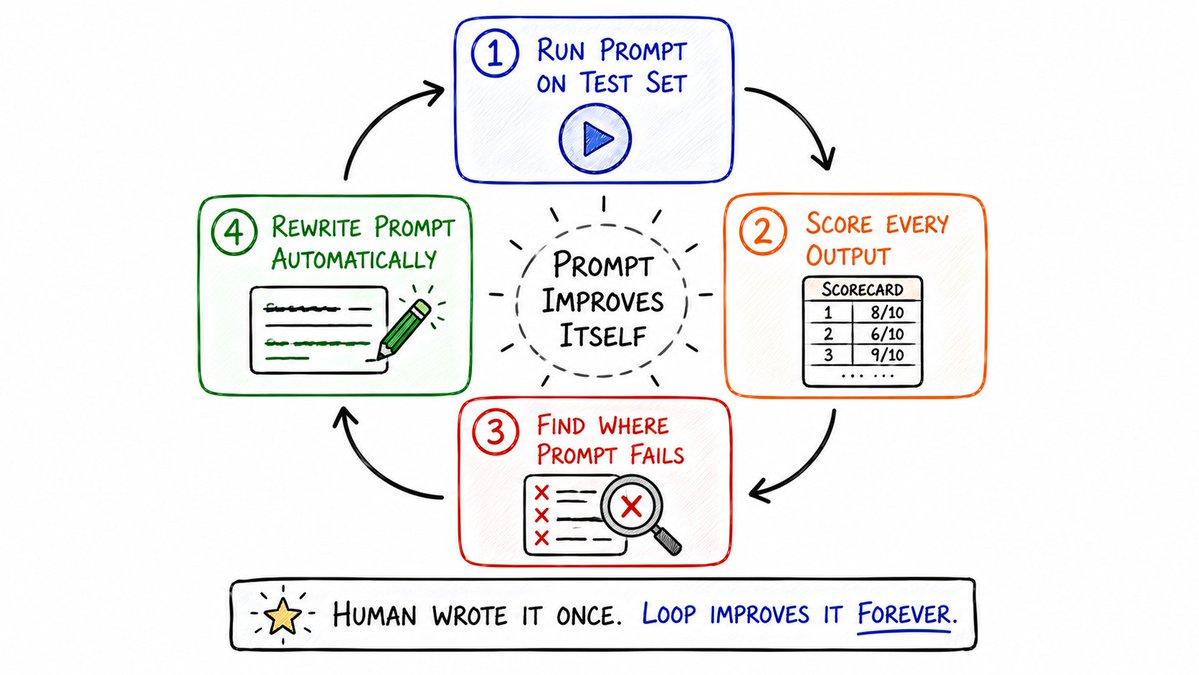
19. Prompt 自动优化循环 (Prompt Optimization Loop)
大多数普通工程师写好一个 Prompt 之后就再也不动它了。
而自动优化循环打破了这一现状。在这套系统里:
- 系统对每一次任务的输出进行打分;
- 定位到哪些场景下 Prompt 表现最差、导致了失败;
- 自动重写并升级 Prompt 以修复这些已知漏洞;
- 重新运行测试集并重新评分。
整个 Prompt 的进化过程完全自动化,不需要任何人类插手。
current_prompt = "请帮我总结这份文件。"
for iteration in range(max_iterations):
outputs = [run(current_prompt, doc) for doc in test_set]
scores = [evaluate(o) for o in outputs]
avg_score = mean(scores)
if avg_score >= target:
break # 达到目标分数,退出优化
# 筛选出低于阈值的失败案例
failures = [o for o, s in zip(outputs, scores) if s < threshold]
# 根据失败反馈,让模型自我重写升级 Prompt
current_prompt = improve_prompt(current_prompt, failures)
今天,在最顶尖的 AI 生产系统中运行的最强 Prompt,早就不是由人类手工写出来的了。
它们,是被系统自己“繁衍和进化”出来的。
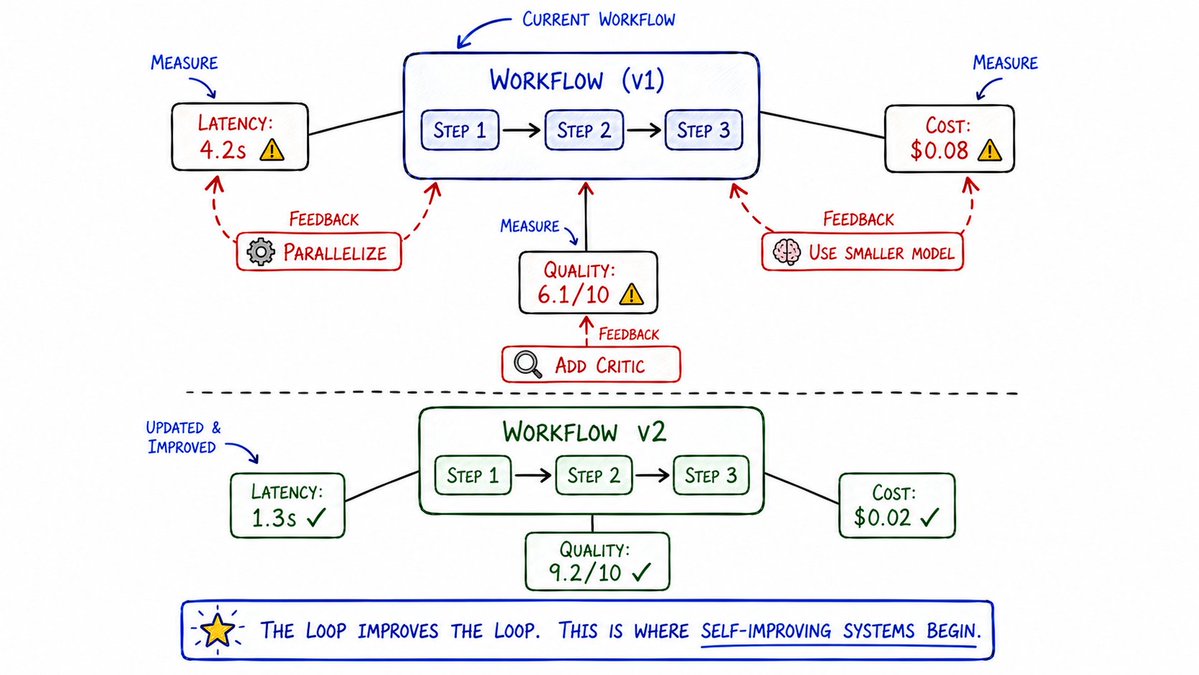
20. 工作流自我重构循环 (Workflow Optimization Loop)
这是整套框架最迷人、最硬核的部分。
它实现了“用循环去优化循环本身”(The loop improves the loop)。
系统在运行过程中,会不断、精确地测量自己的各项体征:
- 延迟(Latency):每一个原子步骤耗时多久?
- 成本(Cost):每一次调用消耗了多少 Token?
- 质量(Quality):每个核心节点输出的评分如何?
接着,它开始动刀修改自己的工作流。
嫌系统运行太慢?它会自动将两个可以并行的串行步骤改为并行(Parallelize)。
嫌运行成本太贵?它会在质量不降级的前提下,自动把某个昂贵的 GPT-4 节点替换为小尺寸模型(Cheaper Model)。
发现某段输出质量下滑?它会在这个节点输出前,自动安插一个批判者(Critic)角色进行强行拦截。
metrics = measure_workflow(outputs, latency, cost)
if metrics.latency > target_latency:
# 延迟超标,自动改写工作流,将慢步骤改为并行执行
workflow = parallelize(slow_steps)
if metrics.cost > budget:
# 预算超支,自动在非核心步骤替换为更低廉的模型
workflow = replace_with_cheaper_model(high_cost_steps)
if metrics.quality < threshold:
# 质量不达标,自动在关键出口前强行塞入一个 Critic 拦截节点
workflow = add_critic_before(final_output_step)
至此,真正具备“自我进化”能力的终极系统诞生了。
它不仅在改进它输出的数据,它在重写它自己的生命结构。
20 个模式背后的统一灵魂
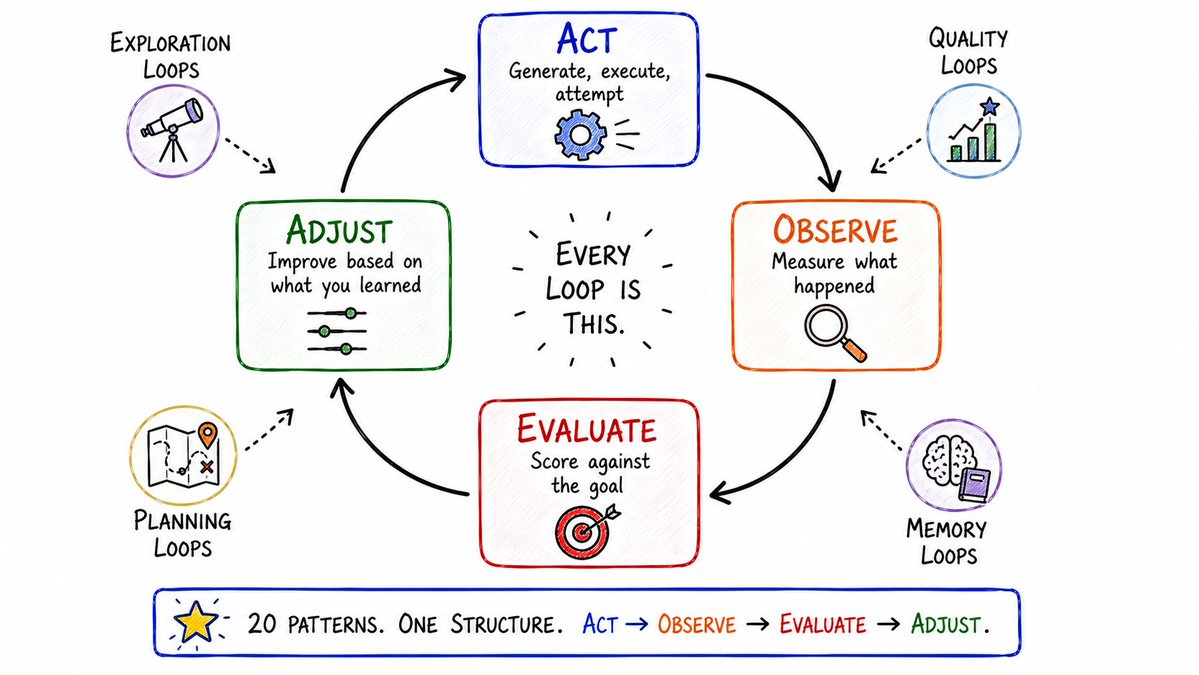
尽管这 20 个设计模式形态各异,但如果你把它们的骨架抽离出来,你会发现它们都共享着同一个底层公式:
$$\text{行动 (Act)} \rightarrow \text{观察 (Observe)} \rightarrow \text{评估 (Evaluate)} \rightarrow \text{调整 (Adjust)}$$行动 -> 观察 -> 评估 -> 调整
这就是全部的秘诀。
不要指望第一枪就能打中靶心。第一枪的产出,永远只是一个粗糙的起点。
而循环(Loop),才是将一个简陋的起点,淬炼成工业级可用产品的唯一熔炉。
大多数工程师认为智能体是未来的发展方向
大多数普通人依然坚信“Agent”就是大模型的未来。
但真相是:Agent 只是打工的工人。Loop,才是让工人每天自我进化的机制。
当前 AI 行业最底层的范式大转移,根本不是在追求更好的基础模型,而是研发思路的彻底倒转:
- 过去式:Prompt -> Response(一锤子买卖)
- 进行时:Generate -> Evaluate -> Learn -> Improve(无限循环进化)
那些真正掌握了 “循环设计(Loop Design)” 精髓的团队,从来不会浪费时间去祈祷模型给个好提示词。
他们构建的系统,在部署上线后的每一天,都在人类看不见的后台默默地自我进化。
去构建循环吧,让它在你睡觉时,替你改变世界。
小结
如果说过去两年是“提示词工程(Prompt Engineering)”的启蒙期,那么这篇关于 20 种“循环模式”的总结,则正式为我们拉开了“AI 软件系统设计学”的帷幕。
从最基础的“生成-批判”流水线,到令人震撼的“Prompt 与工作流自我重构”,这 20 个模式无一不在向我们传递一个冰冷的工程真相:即使大模型再聪明,单点突破的运气也永远敌不过系统级闭环的确定性。
不再寄希望于模型一次性吐出完美的答案,而是构建一个能在失败中反思、在记忆中学习、在约束中收敛的熔炉。当你的架构图里充满了自我诊断、自我修复和自我优化的飞轮时,你就真正掌握了 AI 时代系统工程的顶级心法。
原文链接:https://x.com/sairahul1/status/2072258045460226373
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
- 抛弃臃肿框架,回归“驾驭工程 (Harness Engineering)”的第一性原理
- 用 Go 语言手写 ReAct 循环、并发拦截与上下文压缩引擎等,复刻极简OpenClaw
- 构建坚不可摧的 Safety Middleware 与飞书人工审批防线
- 在底层实现 Token 成本审计、链路追踪与自动化跑分评估
- 从“调包侠”进化为掌控大模型边界的“AI 操作系统架构师”
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。

还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
- 告别低效,重塑开发范式
- 驾驭AI Agent(Claude Code),实现工作流自动化
- 从“AI使用者”进化为规范驱动开发的“工作流指挥家”
扫描下方二维码,开启你的AI原生开发之旅。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
- 体系化 Go 核心进阶内容: 深入「Go原理课」、「Go进阶课」、「Go避坑课」等独家深度专栏,夯实你的 Go 内功。
- 前沿 Go+AI 实战赋能: 紧跟时代步伐,学习「Go+AI应用实战」、「Agent开发实战课」、「Agentic软件工程课」、「Claude Code开发工作流实战课」、「OpenClaw实战分享」等,掌握 AI 时代新技能。
- 星主 Tony Bai 亲自答疑: 遇到难题?星主第一时间为你深度解析,扫清学习障碍。
- 高活跃 Gopher 交流圈: 与众多优秀 Gopher 分享心得、讨论技术,碰撞思想火花。
- 独家资源与内容首发: 技术文章、课程更新、精选资源,第一时间触达。
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
