
本文永久链接 – https://tonybai.com/2026/06/19/agentic-coding-and-persistent-returns-to-expertise
大家好,我是Tony Bai。
在生成式 AI 狂飙的今天,程序员群体正陷入一种前所未有的分化和焦虑中:
- 初级开发觉得前路茫茫,因为大模型写出的业务代码比他们更快、更整洁;
- 资深架构师虽然暂时安全,但也时刻担心随着大模型逻辑推理能力的指数级进化,自己的行业经验终有一天会被无情商品化。
“AI 究竟是专家经验的放大器,还是专家经验的掘墓人?”
为了彻底用科学数据回答这个终极命题,大模型领域无可争议的“编码之王” Claude 的母公司 Anthropic,于近日发布了一份具有里程碑意义的实证研究报告:《Agentic coding and persistent returns to expertise》。
这份白皮书的含金量极高。研究人员在确保隐私安全的前提下,深度追踪并分析了从 2025 年 10 月到 2026 年 4 月期间,全球开发者使用 Claude Code 的 40 万次真实交互会话(Sessions)。
报告揭示出的事实极其震撼、甚至有些反直觉:大模型并没有让专家的经验贬值,反而让“专家经验”在 AI 时代迎来了前所未有的暴利和溢价;与此同时,那些只会写语法糖、没有领域常识(Domain Knowledge)的普通程序员,正在被无情地边缘化。
下面,我们就用白皮书里的硬核数据,层层剥开这场残酷的 AI 权力重构。

权力的边界:人类负责“定目标”(70%),AI 负责“搬砖”(80%)
在这份大样本分析中,Anthropic 首先定义了人机协作在智能体编码(Agentic Coding)时代的新型分工模型(The division of labor)。
研究人员通过机器学习分类器,对 40 万次会话中的每一个动作进行了属性归类。他们惊奇地发现,人类与 Claude Code 在开发过程中展现出了极度清晰的边界:
- 人类主导“规划决策(What to do)”:在决定系统要构建什么功能、采用什么业务逻辑、遵循什么系统规范时,人类做出了 70% 的决策。
- AI 主导“执行决策(How to do it)”:在决定调用什么命令、修改哪些文件、使用什么具体语法、以及运行什么测试脚本时,Claude 承担了 80% 的工作。
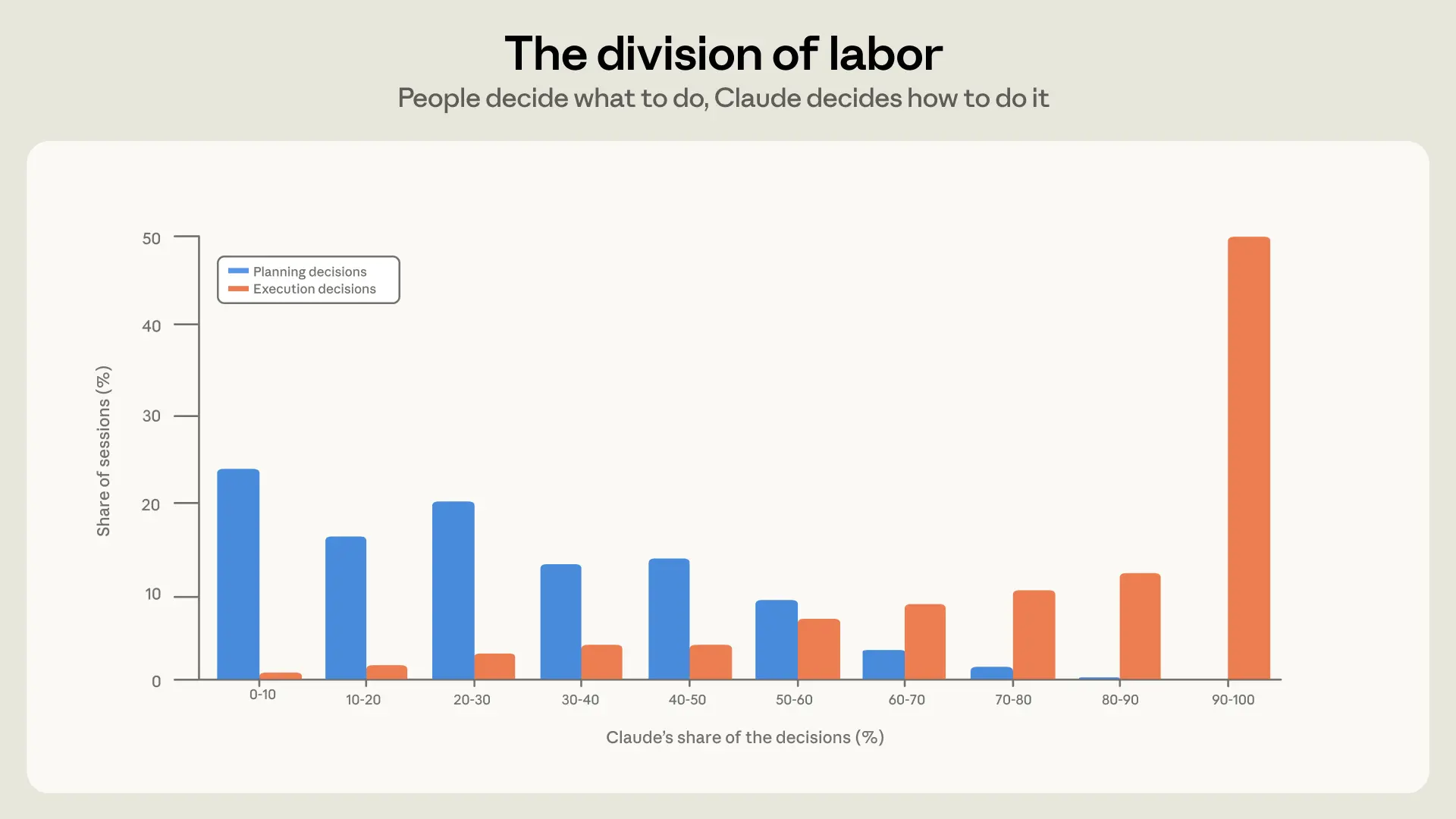
图:人机分工实证:人类牢牢掌控着 70% 的架构和业务规划决策,而 AI 则在底层包揽了 80% 的具体代码执行
这证实了:在真实的工业级开发中,大模型并不是在“取代”程序员,而是成为了一个不知疲倦、效率极高的“执行义肢”。人类出脑子(Framer),AI 出体力(Executor),这种分工正在成为现代软件开发的黄金标准。
专家溢价:为什么 AI 越强,资深专家的身价越贵?
这是整篇白皮书中最核心、也最震撼的发现:AI 的出现,极大地拉大了“专家”与“新手”之间的产出差距。
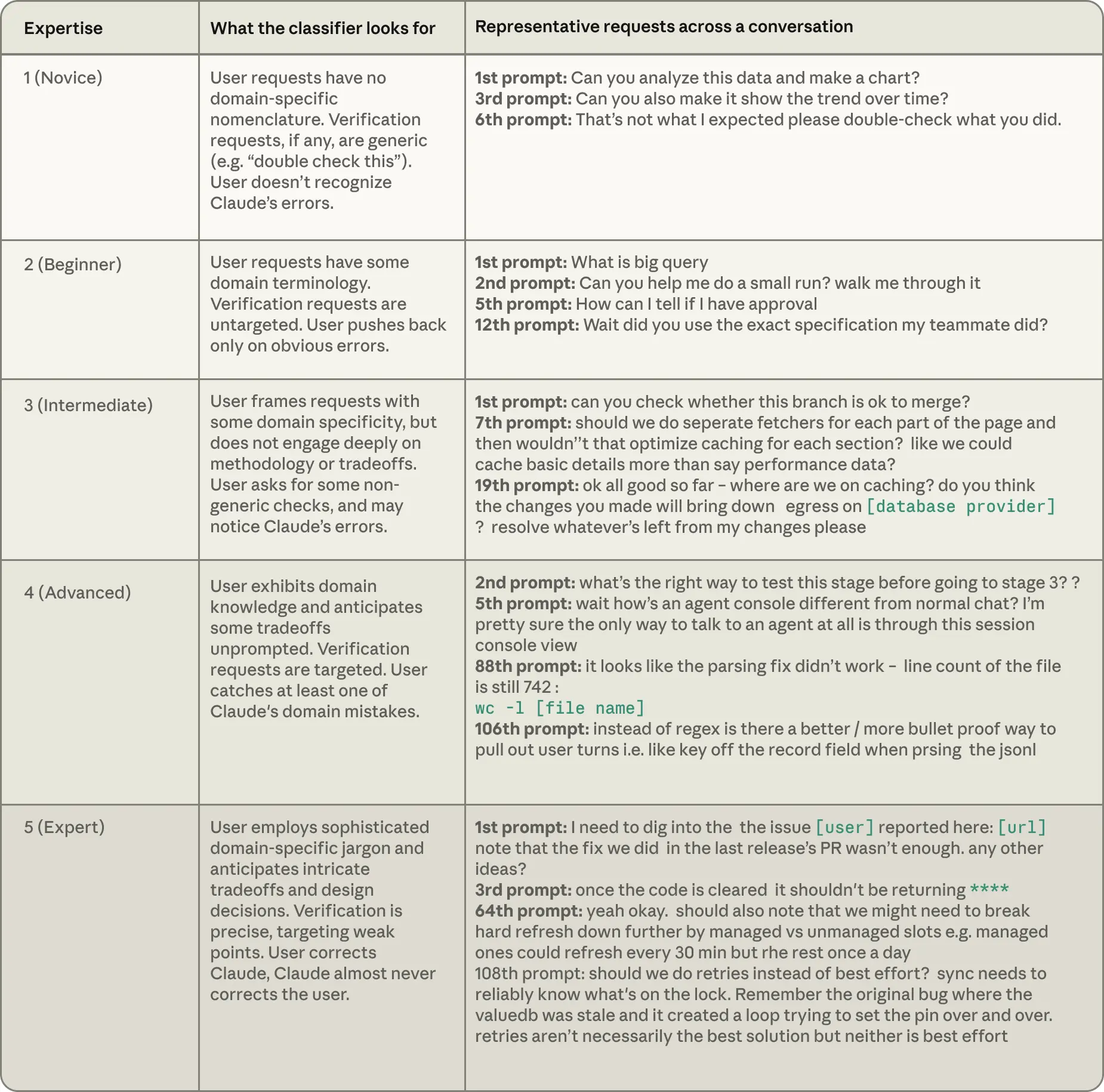
为了精确筛选和分析这 40 万次人机对话,Anthropic 在底层构建了一个极其严密的**“五级经验分类器”**。他们通过机器学习,根据人类输入提示词的专业度,对用户的工程段位进行了无情分类。
这套分类器不仅是学术工具,更是我们每个普通开发者自测“AI 时代身价”的终极试金石:
-
L1 – 萌新(Novice):
- 标准:完全不使用任何领域专业术语,对 AI 的报错毫无感知,只能进行通用的验证。
- 典型 Prompt:“你能帮我分析这些数据并画个图吗?” / “帮我看看趋势,求求你了。”
-
L2 – 初学者(Beginner):
- 标准:开始使用少量的专业术语,但验证请求漫无目的,只有在 AI 犯了极其低级、显而易见的错误时才会进行反驳。
- 典型 Prompt:“BigQuery 是什么?” / “你能跑个简单的 Demo 带我过一遍吗?” / “等下,你用的是我队友给的那个精确规范(Specification)吗?”
-
L3 – 中级(Intermediate):
- 标准:能够用一定的领域专业性来框定问题,但无法深入探讨底层设计权衡。能进行一些非通用的检查,并开始主动捕捉 AI 的错误。
- 典型 Prompt:“帮我看看这个分支能安全合并(Merge)吗?” / “如果我们在前端页面的每个部分建立单独的文件夹,会不会优化各个 Section 的缓存(Caching)?”
-
L4 – 高级(Advanced):
- 标准:展现出强烈的领域知识,能够在不依赖 AI 提示的情况下,提前预判 AI 在该领域极易犯的特定错误。验证针对性极强,至少能揪出一次 AI 犯的底层逻辑错误。
- 典型 Prompt:“在进入第三阶段之前,测试这一步的最佳方法是什么?” / “正则(Regex)在这里太脆了,有没有更稳固(More bullet proof)的方法,在解析 JSON 时基于 record 字段来进行键值提取?”
-
L5 – 专家(Expert):
- 标准:使用极度复杂的行业黑话,能精准预测复杂的架构设计权衡。验证精准打击系统最薄弱的关节。能够无情纠正 AI 的错误,而 AI 几乎无法纠正专家的逻辑。
- 典型 Prompt:“上个版本 PR 的修复根本不够,我们需要更深地排查用户反馈的这个 Bug。yeah,我们也许需要把‘强制刷新(hard refresh)’根据‘托管/非托管插槽(slots)’做进一步的拆分。 sync 必须可靠地知道锁(lock)的状态,还记得由于 valueDb 变脏(stale)而导致不断尝试设 Pin 的死循环 Bug 吗?”
在这套分类下,专家与新手在使用同一个 Claude Code 时,展现出了两个维度的“遥遥领先”:
1. 成功率的云泥之别(91% vs 15%)
根据白皮书的统计:在面临高难度的软件工程任务时,新手的完全成功率只有可怜的 15%(在最宽松的指标下也只有 39%);而 L5 级别的领域专家,其成功率直接飙升到了 91%!
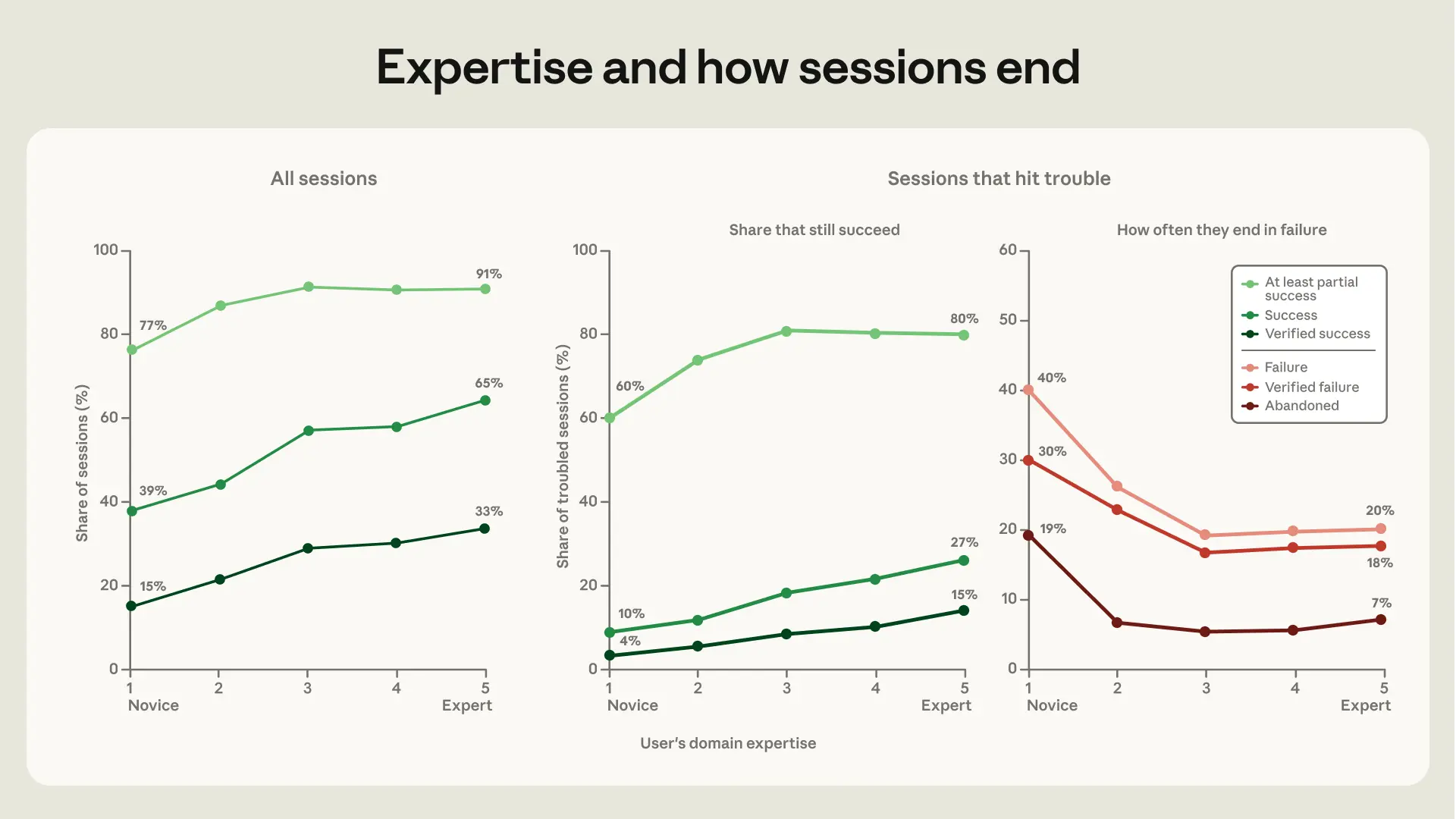
图:随着用户专业度的提升(L1 到 L5),AI 辅助下的项目成功率从 15% 呈指数级飙升至 91%
2. 吞吐量红利(AI 愿意为专家干更多的活)
数据表明,当新手发出一条指令时,Claude Code 平均只会执行 4.9 次行动,吐出 607 个单词。
而当 L5 级别的专家发出一条指令时,Claude 会如同遇到知音一样,在后台自动触发一系列复杂的链式反应,平均执行 11.7 次高级行动,狂喷 3,200 个单词的高质量代码!
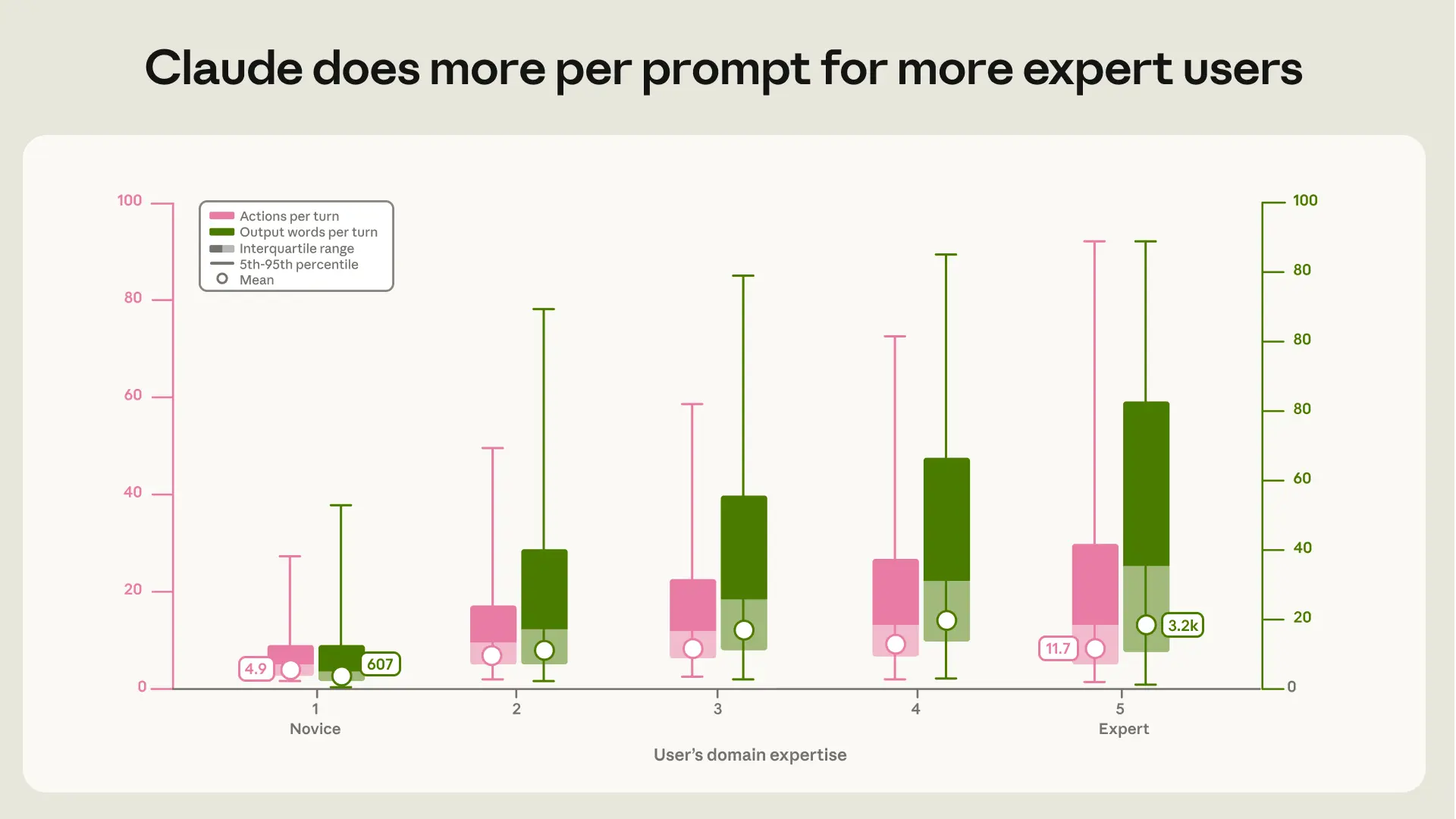
为什么会这样?
因为 AI 智能体在面对模糊、没有领域常识的提问时,会迅速陷入“误解 -> 生成垃圾代码 -> 被编译器报错 -> 再次生成垃圾 -> 用户放弃(Abandon)”的死循环。
而面对专家时,由于专家给出了极其精确的**“业务边界限制(Guardrails)”和“情境品味(Situated Taste)”**,AI 能够顺着正确的方向无限hill-climbing(爬坡),发挥出大模型最极致的推理深度。
同时,当 AI 犯错时,新手无能为力,只能眼睁睁看着它胡说八道;而专家能够瞬间识别出 AI 的漏洞,给出一句精准的“纠偏提示”,牵着 AI 的手跨过泥潭。
边界消除:会写代码的审计师,正在干掉不会审计的程序员
如果说“专家在软件开发里更赚钱”还在我们的意料之中,那么白皮书指出的第三个趋势,则无情地打破了传统程序员的行业垄断:非软件行业的专家,正在用 AI “降维打击”传统的初级码农。
请仔细看白皮书给出的各行各业在使用 Claude 编写代码时的成功率:
- 软件与数学专家:成功率 94%。
- 管理人员(Management):成功率 95%!
- 法律人员(Legal):成功率 97%!
- 商业与金融专家(Business & Finance):成功率 90%!
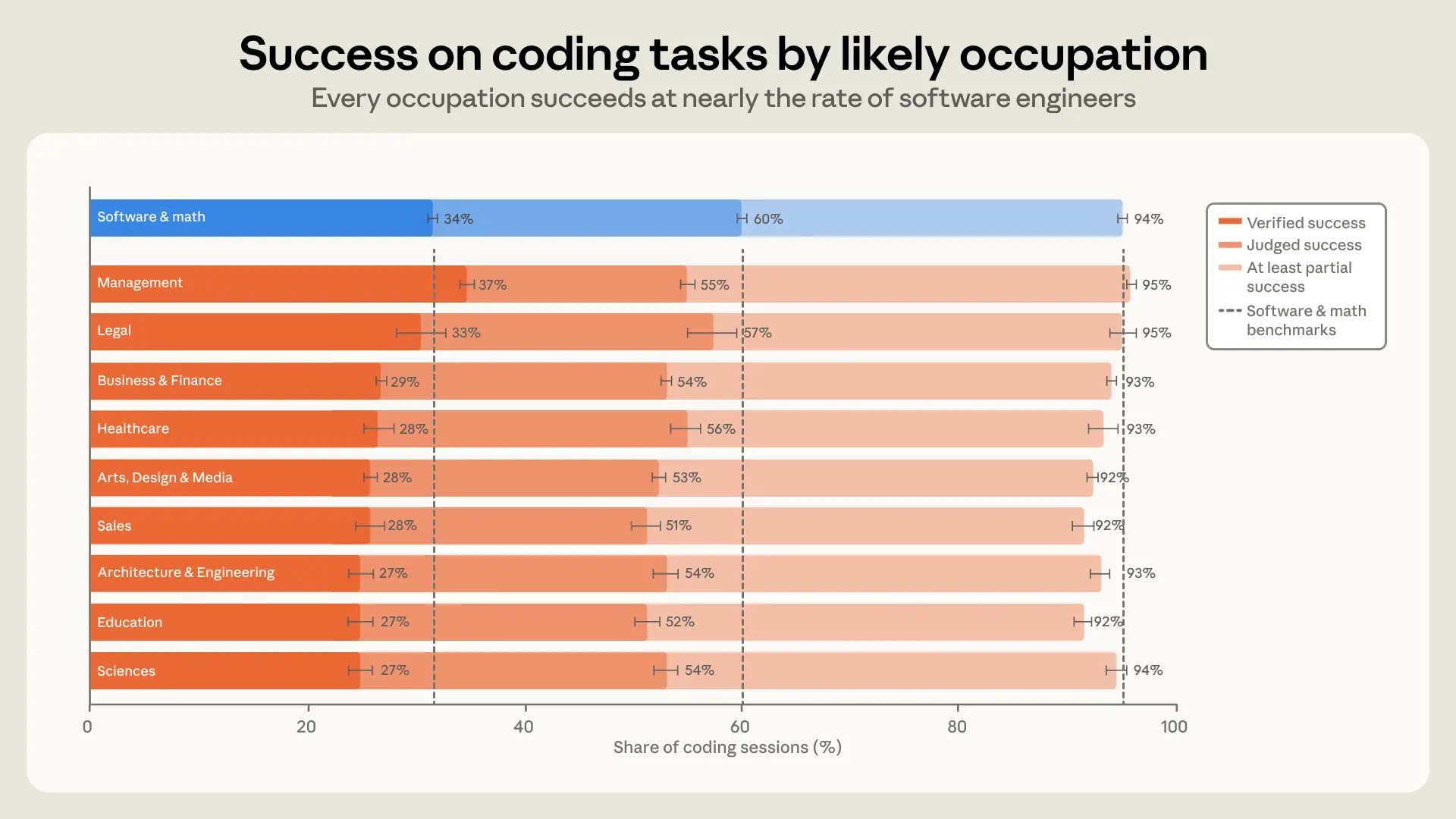
我们从图中可以看出惊人的行业跨界:凭借深刻的领域经验(Domain Expertise),金融、法律和管理人员在 AI 辅助下的编码成功率,几乎与专业软件工程师持平,甚至有所超越。
这绝对是一个核弹级的发现:决定代码质量的,不再是你的“编程语法熟练度”,而是你对“业务逻辑和领域常识的理解深度”。
- 一个完全不会写 Python 语法的资深会计师,通过 Claude Code,能够极其精确地描述出月末账目对账(Month-end reconciliation)的业务规则、税法限制以及漏单退回逻辑。Claude 能够根据他提供的完美业务逻辑,在几秒钟内生成一段毫无瑕疵的 Python 财务自动化工具。
- 而一个懂 Python 语法、却对财务审计一窍不通的初级程序员,他写出来的代码,在业务层面上大概率是充满漏洞的垃圾(Slop)。
“业务逻辑与情境品味(Situated Taste),正在成为 AI 时代最坚固的技术壁垒。而单纯的语法编写,已经彻底沦为了廉价的机器工。”
价值重构:如何成为不被“垃圾代码”淹没的 10%?
Anthropic 在报告的后半部分,进行了一项极其严谨的经济学评估:他们通过对比自由职业市场(Freelance job postings)的实际标价,来评估 40 万次 Claude 会话产生的经济价值。
数据显示,在短短 7 个月内,由 Claude Code 完成的任务的平均经济价值,暴涨了约 25%!
这说明,随着模型对工具调用、测试和自动化部署的演进,AI 正在以前所未有的速度吞噬那些“低价值的、纯编写的工作”。
这也给所有的软件工程师指明了一条唯一的出路:
- 从“如何写(How)”迅速向“写什么(What)”转型:如果你的日常工作只是把产品经理的 PRD 翻译成代码语法,你和 AI 相比没有任何竞争优势。你必须去深入理解业务,理解数据库底层设计,去成为那个“定标和画框的人”。
- 建立“纠偏与审计”能力**:大模型会源源不断地生成看似完美的代码。未来的高级工程师,其核心工作将是“代码审计师(Code Auditor)”。你必须能在几秒钟内,看出 AI 生成的千行代码中,那个隐藏在锁竞争或并发状态下的微小 Bug。
- 深耕一个具体的垂直领域:不要做“通用的、只会写增删改查(CRUD)的程序员”。去深入医疗、金融、安全、芯片物理、或者高性能网络。
小结
大模型并没有让专家的经验贬值,反而像一把高压水枪,正在迅速冲刷掉代码工程中的淤泥,让真正拥有“业务品味”和“领域常识”的金子,闪耀出前所未有的夺目光芒。
AI 降低了普通人写代码的门槛,但也让“垃圾代码”遍地都是。
在这个平庸泛滥的时代,决定你身价的,不再是你敲击键盘的速度,而是你脑海中沉淀的那些、无法被文本化的行业直觉与工程审美。
在这场人机共生的伟大战役中,我们既要学会借用神明的光芒,也要时刻警惕不要沦为神殿下盲目的祭品。
资料链接:https://www.anthropic.com/research/claude-code-expertise
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
- 告别低效,重塑开发范式
- 驾驭AI Agent(Claude Code),实现工作流自动化
- 从“AI使用者”进化为规范驱动开发的“工作流指挥家”
扫描下方二维码,开启你的AI原生开发之旅。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
- 体系化 Go 核心进阶内容: 深入「Go原理课」、「Go进阶课」、「Go避坑课」等独家深度专栏,夯实你的 Go 内功。
- 前沿 Go+AI 实战赋能: 紧跟时代步伐,学习「Go+AI应用实战」、「Agent开发实战课」、「Agentic软件工程课」、「Claude Code开发工作流实战课」、「OpenClaw实战分享」等,掌握 AI 时代新技能。
- 星主 Tony Bai 亲自答疑: 遇到难题?星主第一时间为你深度解析,扫清学习障碍。
- 高活跃 Gopher 交流圈: 与众多优秀 Gopher 分享心得、讨论技术,碰撞思想火花。
- 独家资源与内容首发: 技术文章、课程更新、精选资源,第一时间触达。
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
