
本文永久链接 – https://tonybai.com/2026/06/17/deepmind-automation-agent-harness-ai-self-coding
大家好,我是Tony Bai。
过去的几个月,整个 AI 开发圈最火的词,无疑是 Agent Harness(智能体驾驭系统)。
从 Claude Code 到 OpenClaw,再到我自己的极客时间专栏,我们所有走在 AI 原生开发前沿的工程师,都在不遗余力地布道一个核心思想:大模型本身只是一个“毛坯大脑”,你必须为它手工打造一套精密的“外部骨骼(Harness)”,它才能真正干活。
我们研究 ReAct 循环、设计上下文压缩引擎、构建安全中间件……我们以为,掌握这套“驾驭工程学”,就是我们在 AI 时代的终极护城河。
但就在今年年初,AI 领域的“神殿”——Google DeepMind——直接掀了桌子。
他们发布了一篇名为**《AutoHarness: a code harness for LLM agents by automatically synthesizing a code harness》**的重磅论文,用极其详实的数据和实验,向全世界宣布了一个既震撼又令人脊背发凉的事实:
别再苦哈哈地手写 Harness 了,我们已经能让 AI 自己为自己编写“规则护栏”了。
这篇论文同时也像一面镜子,照出了即便是最顶级的 AI Agent,在没有“护栏”的情况下有多么“愚蠢”;更像一声警钟,预示着我们人类工程师在 AI 产业链中的角色,即将迎来又一次深刻的变迁。

78% 的败因,竟是“犯规”
在展示 AutoHarness 有多强大之前,DeepMind 的科学家们先用一个极其残酷的案例,揭示了为什么 Harness 是“必需品”。
在上一次的 Kaggle 线上国际象棋大赛中,被寄予厚望的 Gemini 2.5 Flash 模型,其 78% 的对局失败,竟然不是因为技不如人,而是因为它试图走出“非法步骤(Illegal Moves)”!
比如,它会尝试让“马”走直线,或者把“兵”横着走。
这个案例,完美地暴露了所有大模型的“原罪”:它们拥有惊人的“语言理解能力”,却没有足够的“规则遵守能力”。
AI 知道成千上万种开局策略,但它不知道在当前的棋盘状态下,哪些格子是它能走的,哪些是不能的。它只是在基于概率,模仿它在训练数据中见过的、最像“正确答案”的文本。
传统的解决方案是什么?
- 模型微调(Fine-tuning):用海量的棋局数据去微调模型。代价极高,速度极慢,而且可能会损害模型在其他任务上的泛化通用能力。
- 手工编写 Harness:由人类工程师为每一款游戏,硬编码一套“规则校验器”。工作量巨大,且极度脆弱,换个游戏就得重写。
让 AI 成为自己的“规则老师”
面对这个两难的困境,DeepMind 的思路堪称“降维打击”:
既然 AI 这么会写代码,为什么不让它自己根据环境的反馈,为自己写一个“规则校验器(Code Harness)”呢?
AutoHarness 的核心流程,就像一个优雅的“自我进化”闭环:
- 初始探索:让一个基础模型(比如 Gemini 2.5 Flash)在游戏环境中自由发挥,生成一个初始版的 Python 策略代码,包含 propose_action() 和 is_legal_action() 两个函数。
- 试错与反馈:在 10 个并行的游戏环境中,同时运行这段代码。一旦 AI 走出了“非法步骤”,或者代码执行出错,系统会立刻终止,并将失败的步骤和环境给出的错误信息,一起打包发给一个“批评家(Critic)”。
- 代码精炼:批评家将错误信息进行整理,连同原始的“问题代码”,一起喂给一个“精炼器(Refiner)”。“精炼器”的角色同样由一个 LLM 担任,它的任务是:“看,你写的这段代码犯了这些错,现在请你把它改对。”
- 循环进化:精炼器生成一段新的、有望修复 Bug 的代码,然后再次投入到游戏环境中进行测试。如此循环往复。
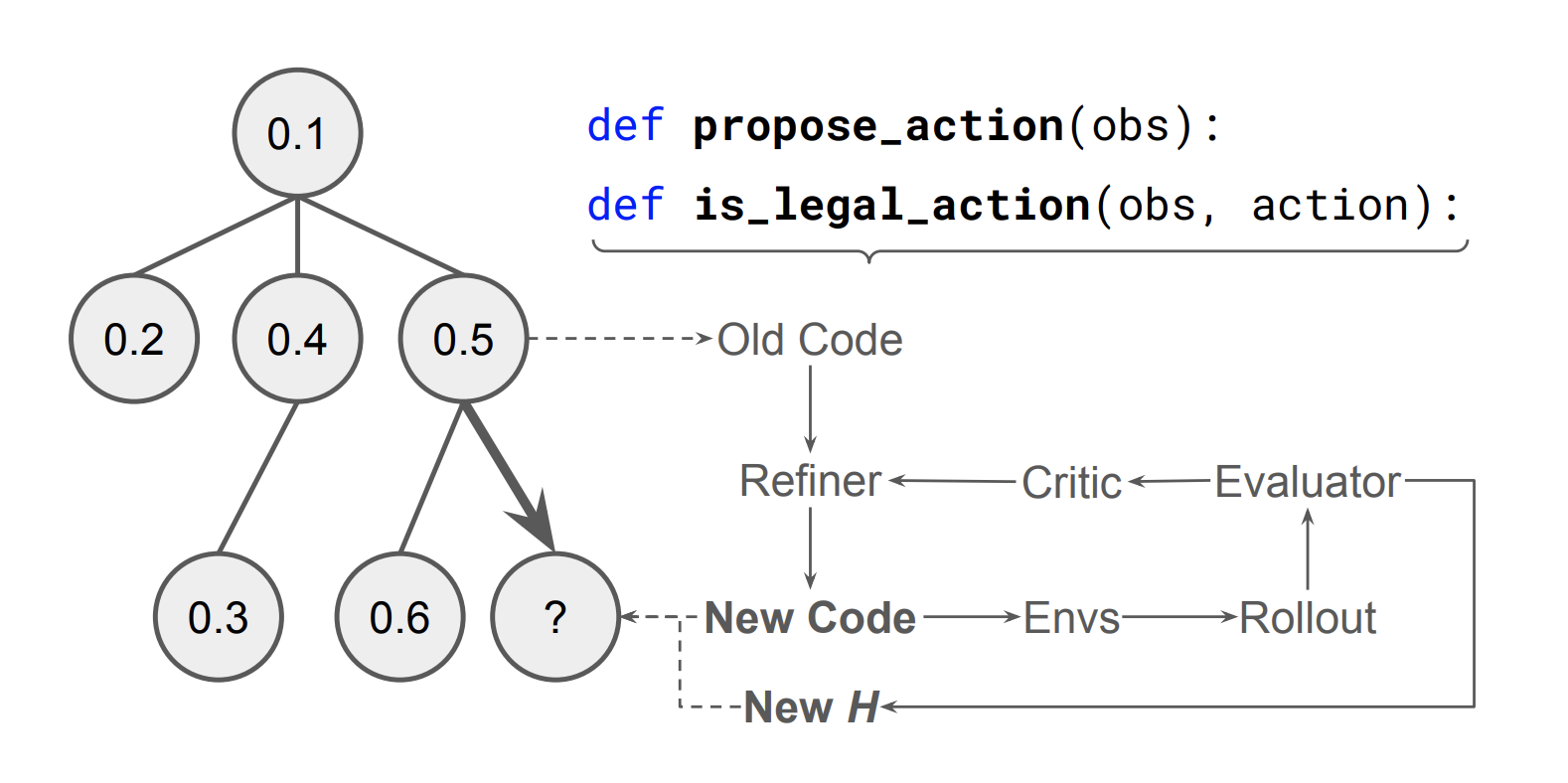
图:Code-as-harness learning process
这个过程,本质上是一个基于“树搜索”和“迭代式代码精炼”的自动化编程过程。
结果有多惊人?
- 在 145 个不同的文本游戏中,AutoHarness 平均只需要 14.5 次迭代,就能为 Gemini 2.5 Flash 生成一个达到 100% 准确率的“合法走步”校验器。
- 在国际象棋(Chess)和奥赛罗(Othello)这种极其复杂的游戏中,AutoHarness 也能在几十次迭代后,完美掌握所有规则。
以弱胜强:当“AI+护栏”轻松碾压“最强大脑”
AutoHarness 最令人震撼的是它带来的**“以弱胜强”**的恐怖效果。
DeepMind 组织了一场对战实验:
- 甲方:小模型 Gemini 2.5 Flash,但装备了由 AutoHarness 自动生成的“规则护栏”。
- 乙方:比 Flash 强大得多的当时的旗舰模型 Gemini 2.5 Pro,但没有任何护栏,“裸奔”上场。
在 16 款不同的双人对战游戏中,结果呈现出一边倒:
装备了“护栏”的小模型 Flash,在与大模型 Pro 的对战中,胜率高达 56.3%!而 Pro 的胜率仅为 38.2%。
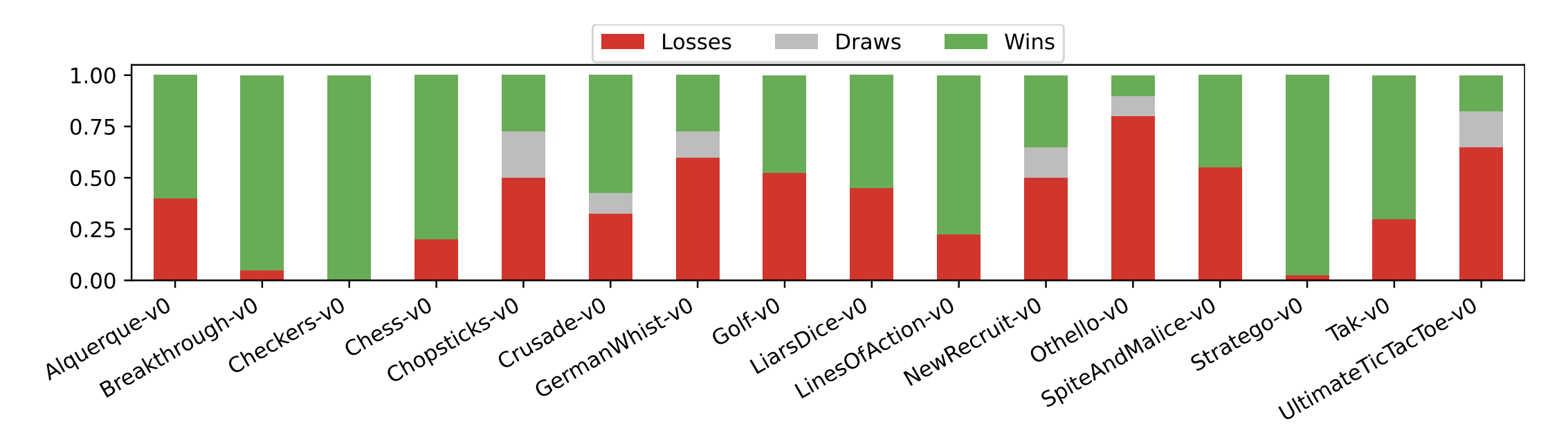
这张图清晰地展示了在多款游戏中,“Flash+Harness”组合的绿色胜利条,是如何显著高于 Gemini-2.5-Pro 的。
这个实验也再次印证了:一个更小的、但被良好“驾驭”的模型,其战斗力是可以超越一个更大、更昂贵、但却在“裸奔”的模型的,足见Harness的重要性。
更极端的是,DeepMind 甚至让 AI 把整个游戏的策略,都写成了确定性的 Python 代码(Harness-as-Policy),在运行时完全不需要再调用 LLM。
结果,这段由小模型生成的纯代码,在 16 款单人游戏中的平均得分,甚至超越了 GPT-5.2-High!
人类的新角色——“环境设计师”与“评估者”
DeepMind 的这篇论文,给我们这些正在苦心钻研 Harness Engineering 的工程师,带来了极其深刻的反思。
它似乎在告诉我们:未来,我们最重要的工作,可能不再是亲手去为 AI 编写“规则”,而是为 AI 设计一个能够让它“自我学习规则”的环境。
我们的角色,正在从“手工艺人”,向两个更高级的职位迁移:
1. 环境设计师(Environment Designer)
AutoHarness 之所以能成功,是因为 DeepMind 的科学家们为它精心设计了一个能提供清晰、即时反馈的游戏环境。
未来,我们的核心任务,将是把我们复杂的业务系统,抽象成一个个能让 AI 安全“试错”、并能从错误中学习的“模拟环境”。
2. 评估体系架构师(Evaluation Architect)
AutoHarness 的另一个关键,是那套能自动判断“好坏”的评估体系。
在 DeepMind 的实验中,他们引入了“批评家”、“裁判”等多个 AI Agent,来自动化地评估新生成的代码。
这正是我在自己的专栏《从 0 开始构建 Agent Harness》中,反复强调的 Evals(自动化评估体系) 的重要性。
当 AI 能写 Harness 时,我们人类的终极护城河,就变成了定义“什么是好的 Harness”的能力。
小结:从“教它做事”到“教它学习”
AutoHarness 的出现,意味着我们可能正在从“授人以鱼”(直接给 AI 写好的规则),进化到“授人以渔”(教 AI 如何自己学习规则)。
这既可以解放了我们的生产力,更是开启了一条通往“AI 递归式自我改进”的、充满无限想象力的大门。
当然,这并不意味着手写 Harness 会立刻消失。对于极其复杂、安全要求极高的领域,人类专家的经验依然不可或缺。
但这篇论文,至少为我们指明了方向:不要再把 AI 当作一个需要你手把手教的“学徒”了。把它当作一个极具天赋、能够自我反思的“初级程序员”,为它提供清晰的测试用例、明确的错误反馈,然后,放手让它自己去进化。
这,或许才是 AI 原生时代,最高级的“人机协同”。
资料链接:https://arxiv.org/abs/2603.03329
今日互动探讨:
看完 DeepMind 的 AutoHarness,你对 Agent 开发的未来是感到兴奋,还是感到了“饭碗不保”的焦虑?你认为 AI 自动生成“规则护栏”的模式,离我们日常的业务开发还有多远?
欢迎在评论区分享你的看法!
认知跃迁:在 AI“自我进化”前夜,你的核心壁垒是什么?
当 AI 开始学会自己编写“驾驭系统”时,我们这些正在苦学 Harness Engineering 的人类工程师,价值何在?
答案是:回归第一性原理。
AutoHarness 虽然强大,但它依然需要人类去定义底层的循环机制、安全边界、成本审计和评估框架。这些,才是 AI 无法自我生成的、真正属于“架构师”级别的智慧。
如果你还在为写 Agent 框架频频死循环、上下文爆炸而束手无策,如果你想在 AI 彻底实现“自我编程”之前,抢先一步,成为那个“设计进化环境”的人——
我的新专栏 《从 0 开始构建 Agent Harness》 将带你:
- 抛弃臃肿框架,回归“驾驭工程 (Harness Engineering)”的第一性原理
- 用 Go 语言手写 ReAct 循环、并发拦截与上下文压缩引擎等,复刻极简OpenClaw
- 构建坚不可摧的 Safety Middleware 与飞书人工审批防线
- 在底层实现 Token 成本审计、链路追踪与自动化跑分评估
- 从“调包侠”进化为掌控大模型边界的“AI 操作系统架构师”
扫描下方二维码,开启你的“AI 环境设计师”之路。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
- 体系化 Go 核心进阶内容: 深入「Go原理课」、「Go进阶课」、「Go避坑课」等独家深度专栏,夯实你的 Go 内功。
- 前沿 Go+AI 实战赋能: 紧跟时代步伐,学习「Go+AI应用实战」、「Agent开发实战课」、「Agentic软件工程课」、「Claude Code开发工作流实战课」、「OpenClaw实战分享」等,掌握 AI 时代新技能。
- 星主 Tony Bai 亲自答疑: 遇到难题?星主第一时间为你深度解析,扫清学习障碍。
- 高活跃 Gopher 交流圈: 与众多优秀 Gopher 分享心得、讨论技术,碰撞思想火花。
- 独家资源与内容首发: 技术文章、课程更新、精选资源,第一时间触达。
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
